Понимание Искусственного Интеллекта
Основы, варианты использования и методы корпоративного пути ИИ
Управление для профессионалов
Ральф Т. Кройцер · Мари Сирренберг
1 Что такое Искусственный Интеллект и как его использовать?
Аннотация
В этой главе мы обсуждаем ключевые аспекты Искусственного Интеллекта. Мы определяем ключевые термины и показываем взаимосвязь таких терминов, как нейронные сети, машинное обучение и глубокое обучение. Мы анализируем различные цели, которые могут быть достигнуты с помощью Искусственного Интеллекта. Кроме того, мы представляем ключевые области применения Искусственного Интеллекта: обработка естественного языка, обработка естественных изображений, экспертные системы и роботы. Также обсуждаются глобальные экономические эффекты Искусственного Интеллекта. Здесь вы можете узнать о различных отправных точках и достижениях ведущих стран мира.
Невозможно — это не факт! Это мнение!
Искусственный Интеллект — относительно новая область исследований, которая лишь медленно выходит из сферы специалистов. Большую часть времени он встречается нам таким образом, что мы изначально не думаем об Искусственном Интеллекте. Мы замечаем только то, что стало легче делать, чем раньше. Только подумайте о цифровых персональных помощниках, таких как Alexa, Google Home или Siri, которые воспроизводят желаемую музыку из Spotify посредством голосового ввода, создают списки покупок или даже инициируют покупки, назначают встречи, объясняют термины или, при необходимости, полностью берут на себя управление вашим Умным Домом. Мы говорим о цифровых персональных помощниках, потому что они больше не являются физически ощутимыми помощниками.
Когда вы используете средства перевода в Интернете, такие как Google Translate или немецкий стартап DeepL, вы также имеете доступ к приложениям ИИ. Алгоритмы ИИ также используются для систем распознавания лиц (например, для контроля доступа в компаниях или для использования вашего смартфона). Экспертные системы с поддержкой ИИ используются для оценки медицинских записей или рентгеновских снимков и КТ-сканов компьютерами. Роботы представляют собой почти неиссякаемое поле применения для Искусственного Интеллекта. Их интенсивное использование больше не ограничивается задачами производства и логистики. Автономное вождение также является областью применения ИИ, использующей робота в качестве водителя.
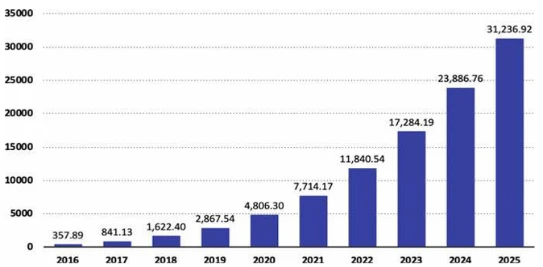
Рисунок 1.1 Прогноз оборота корпоративных приложений в области Искусственного Интеллекта – по всему миру с 2016 по 2025 гг. (в млн долл. США). Источник Statista (2018 г.)
Самая большая проблема Искусственного Интеллекта по-прежнему заключается в комплексном воспроизведении человеческого мозга.
Стоит ли вам как студенту, менеджеру, компании или стране интенсивно заниматься разработками в области Искусственного Интеллекта? Мы убеждены: да! Мы хотели бы подчеркнуть эту оценку фактами, представленными на рис. 1.1. Здесь становится ясно, какая выручка от Искусственного Интеллекта ожидается по всему миру с 2016 по 2025 гг. (в млн долл. США). По нашему мнению, эти цифры говорят сами за себя!
Прежде чем мы глубже погрузимся в различные области применения Искусственного Интеллекта, мы сначала проясним, что именно подразумевается под Искусственным Интеллектом и какие цели могут быть достигнуты с его помощью. Затем подробно анализируются различные области применения, чтобы проиллюстрировать диапазон применимости ИИ. Кроме того, мы рассматриваем глобальные экономические эффекты, вызванные Искусственным Интеллектом.
1.1 Что является основой Искусственного Интеллекта?
Прежде чем приступить к "искусственному" интеллекту, стоит взглянуть на сам интеллект. Вместо того чтобы сужать кругозор и рассматривать только один коэффициент интеллекта, полезно понять, что такое человеческий интеллект или чем он может быть сегодня. Это означает, что мы воспринимаем интеллект в его релевантных проявлениях как подход множественного интеллекта, который охватывает следующие области (ср. Gardner, Davis, Christodoulou, & Seider, 2011, с. 490–498):
• Лингвистический интеллект
• Музыкальный интеллект
• Логико-математический интеллект
• Пространственный интеллект
• Физико-кинестетический интеллект
• Внутриличностный и межличностный интеллект
• Натуралистический и экзистенциальный интеллект
• Творческий интеллект
Разнообразие интеллекта уже на этом этапе показывает, почему мы все еще далеки от машин, которые смогут охватить в полной мере врожденные и приобретенные области интеллекта. Поэтому, по нашему мнению, не только преждевременно, но и чрезмерно концентрировать обсуждение ИИ на сценариях ужасов, в которых машины ИИ захватывают мировое господство.
Ящик памяти
Искусственный Интеллект (ИИ) охватывает две области. Во-первых, он включает в себя исследование того, как "интеллектуальное" поведение может решать проблемы. На основе полученных знаний разрабатываются системы, которые (должны) автоматически генерировать "интеллектуальные" решения. Подход не ограничивается поиском решений так, как это делают люди. Скорее, цель состоит в поиске результатов, которые лежат за пределами пространства человеческих решений. Ядром Искусственного Интеллекта является программное обеспечение!
Существуют различные подходы к концептуализации сущности Искусственного Интеллекта. Следующее очень гибкое определение Рича (Rich, 1983), по нашему мнению, лучше всего подходит для фундаментального прояснения. Оно гласит: "Искусственный Интеллект – это изучение того, как заставить компьютеры делать то, что в настоящее время у людей получается лучше". Эта идентификация Искусственного Интеллекта ясно показывает, что границы возможного постоянно переопределяются. Или вы ожидали 10, 15 или 20 лет назад, что беспилотные автомобили станут почти обычным явлением в 2019 году?
Более точное определение: Искусственный Интеллект – это способность машины выполнять когнитивные задачи, которые мы ассоциируем с человеческим разумом. Это включает в себя возможности восприятия, а также способность рассуждать, самостоятельно учиться и таким образом находить решения проблем независимо. Могут быть применены три типа оценок – комбинированные или изолированные:
• Описание (описание "фактического")
• Предсказание (прогноз "желаемого")
• Рекомендация (рекомендация "что делать")
В ходе разработки Искусственного Интеллекта произошел интересный феномен. Первые задачи Искусственного Интеллекта были трудны для человека, но легки для систем ИИ (например, сложные вычислительные процессы). Такие задачи можно было точно решить с помощью формальных математических правил. Одной из простейших задач для систем ИИ была обработка большого объема данных с использованием этих правил. С другой стороны, компьютерам часто гораздо труднее справиться с задачами, которые легки
для человека, решение которых не основано исключительно на математических правилах. Это относится к распознаванию речи и объектов. Человек очень легко видит, когда физический объект является столом, а когда стулом. У обоих обычно есть четыре ножки, но функция разная. Чтобы научиться этому, системе ИИ часто нужно показать большое разнообразие изображений. Тем не менее, эта система часто – пока еще нет – не может распознать фактическое "значение объектов".
Если система ИИ научилась различать овчарку и волка по большому количеству фотографий, систему можно легко ввести в заблуждение, если на снимке овчарка видна со снегом. Тогда может случиться так, что овчарка будет распознана как волк, потому что на многих фотографиях волков видно снег на заднем плане. Или наоборот: если волк на фотографии носит ошейник для поводка, система ИИ наверняка заподозрит овчарку, потому что на тренировочных фотографиях для алгоритмов ИИ волков с ошейником наверняка почти не было. Вот и вся (текущая) разумность компьютеров!
Мы лучше всего подходим к содержанию Искусственного Интеллекта с помощью рис. 1.2. Важным элементом Искусственного Интеллекта являются так называемые нейронные сети. Этот термин изначально пришел из нейронауки. Там нейронная сеть относится к связям между нейронами, которые выполняют определенные функции как часть нервной системы. Компьютерные ученые пытаются воссоздать такие нейронные сети. Особенностью их является то, что информация в сетях обрабатывается не линейными функциями. Здесь информация обрабатывается параллельно, что возможно благодаря связыванию нейронов и специальным функциям обработки. Таким образом, могут быть отображены даже очень сложные, нелинейные зависимости исходной информации. Крайне важно, что нейронные сети учатся этим зависимостям самостоятельно. Это основано на экспериментальных данных (также называемых обучающими данными), которые подаются в эти системы в начале (ср. Lackes, 2018).
Нейронная сеть — это система аппаратного и программного обеспечения, структура которой ориентирована на человеческий мозг. Таким образом, она представляет собой шедевр Искусственного Интеллекта. Нейронная сеть обычно имеет большое количество процессоров, которые работают
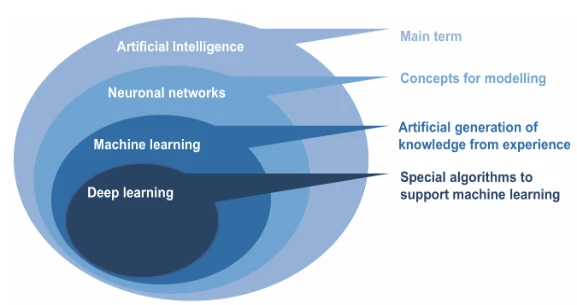
Рисунок 1.2 Компоненты производительности Искусственного Интеллекта (Рисунок авторов)
параллельно и расположены в несколько слоев (см. рис. 1.3). Первый слой (входной слой) получает необработанные данные. Этот слой можно сравнить со зрительными нервами при обработке изображений человеком. Каждый последующий слой (здесь скрытые слои 1 и 2) получает выходной сигнал предыдущего слоя — и больше не данные, обработанные в предыдущих слоях. Аналогично, нейроны в человеческой системе, которые дальше от зрительного нерва, получают сигналы от нейронов, которые ближе к ним. Этот естественный процесс имитируется нейронными сетями. Для обработки данных может использоваться очень большое количество скрытых слоев — часто не просто 100, 1000 или 10 000! Система ИИ учится каждому переходу к другому слою (в идеале). Последний слой (выходной слой) генерирует выходные результаты системы ИИ (ср. Rouse, 2016).
Каждый обрабатывающий узел имеет свою область знаний. Это включает не только правила, с которыми он изначально был запрограммирован. Скорее, это включает знания и правила, которые были разработаны в ходе так называемого машинного обучения в дополнительной или корректирующей манере. Это означает, что "машина" учится сама и может таким образом в большей или меньшей степени дистанцироваться от первоначальных "знаний" (ср. Schölkopf & Smola, 2018).
Ящик памяти
В процессе использования "машина" все больше эмансипируется от исходных входных данных (данные и правила). В сравнении с классическими системами, основанными на правилах (где данные обрабатываются так, как было определено заранее), Искусственный Интеллект пытается самостоятельно развиваться и учиться, чтобы достигать еще лучших результатов на основе полученного опыта. Алгоритмы, используемые изначально, представляют собой лишь почву для разработки новых алгоритмов. Если новые алгоритмы в ходе обучения окажутся более осмысленными, "машина" продолжит работать с ними самостоятельно. Этот процесс называется машинным обучением.
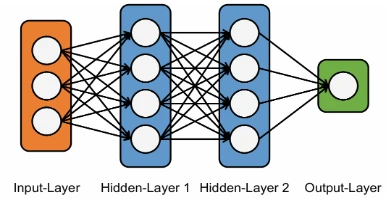
Рисунок 1.3 Различные слои в нейронных сетях (Рисунок авторов)
Для поддержки этого процесса обучения разные уровни соединены различными способами. Как показано на рис. 1.3, входы каждого узла уровня "n" соединены со многими узлами предыдущего уровня "n − 1". Исключение составляет входной слой, который может иметь только один узел (рис. 1.3 показывает здесь три узла). Кроме того, выходы уровня "n" соединены со входами следующего уровня "n+1". Описанные связи позволяют информации передаваться послойно. Второе исключение, касающееся количества узлов, — это выходной слой. Может быть один (как на рис. 1.3) или несколько узлов, с которых можно считывать ответы.
Глубина модели — один из способов описания нейронных сетей. Она определяется количеством слоев, расположенных между входом и выходом. Здесь мы говорим о так называемых скрытых слоях модели. Далее, нейронные сети можно описать шириной модели. При описании ширины учитывается количество скрытых узлов модели и количество входов и выходов на узел. Вариации классического дизайна нейронных сетей позволяют использовать различные формы прямого и обратного распространения информации между слоями.
Давайте подробнее рассмотрим важное машинное обучение (ML). Как уже отмечалось, используются алгоритмы, способные учиться и таким образом самостоятельно совершенствоваться. Алгоритм — это запрограммированное выражение, которое обрабатывает входные данные в предопределенной форме и выводит результаты на их основе. Машинное обучение использует очень специальные алгоритмы — так называемые самоадаптирующиеся алгоритмы. Они позволяют машинам самостоятельно учиться без вмешательства программистов в текущий процесс обучения. Требуются большие объемы данных. Только тогда алгоритмы могут быть обучены таким образом, чтобы они могли лучше и лучше справляться с предопределенными задачами — без необходимости перепрограммирования. Для этого используются инсайты, полученные посредством глубокого обучения (см. ниже). Чтобы способствовать этим процессам обучения, требуются большие объемы высококачественных данных как "обучающий материал". Новые алгоритмы генерируются с помощью этих так называемых обучающих данных. После завершения они непрерывно проверяются с использованием дополнительных входных данных для улучшения основы для принятия решений. Для улучшения производительности алгоритма требуются так называемые данные обратной связи (ср. Agrawal, Gans, & Goldfarb, 2018, с. 43).
В машинном обучении и, соответственно, в разработке все более мощных алгоритмов можно выделить различные типы обучения (ср. Gentsch, 2018, с. 38f; McKinsey, 2018b, с. 2–6.):
• Обучение с учителем
В этом процессе обучения система ИИ уже знает правильные ответы и должна "всего лишь" адаптировать алгоритмы так, чтобы ответы могли быть максимально точно получены из существующего набора данных. Таким образом, цель или задача алгоритма здесь уже известна.
В этом подходе к обучению люди должны идентифицировать каждый элемент входных данных. Должны быть определены и выходные переменные. Алгоритм обучается на введенных данных, чтобы найти связь между входными переменными и выходными переменными. Используемые методы включают линейную регрессию, линейный дискриминантный анализ и метод дерева решений.
Когда обучение завершено — обычно, когда алгоритм достаточно точен — алгоритм применяется к новым данным.
Задача такой системы ИИ может состоять в объяснении известных цен для различных моделей автомобилей по их характеристикам (например, марка, мощность, тип двигателя, функции). Здесь система учится самостоятельно на полностью предопределенном наборе данных распознавать релевантные объясняющие закономерности.
• Обучение без учителя
В этом виде обучения у системы ИИ нет заранее определенных целевых значений, и она должна самостоятельно распознавать сходства и, соответственно, закономерности в данных. Следовательно, пользователь заранее не осведомлен о таких закономерностях; скорее, задача алгоритма — распознать их самостоятельно. Знание, полученное системой, может, таким образом, лежать вне того, что ранее было "человечески вообразимо".
Для этого алгоритм получает неразмеченные данные. В них алгоритм должен самостоятельно распознать структуру. Для этого алгоритм определяет группы данных, которые проявляют сходное поведение или сходные характеристики. Здесь используются методы иерархической и кластеризации K-средних.
Интересная задача для этого — распознавать людей в социальных сетях (распознавание образов), которые особенно восприимчивы к ложным сообщениям, позитивно комментируют их и пересылают. При этом возможно, что это касается именно таких лиц, которые очень любят фотографии кошек или в основном активно публикуют контент в социальных сетях с 22 до 23 часов. Такие выводы могут лежать за пределами того, что могло ожидаться человеком. Президентские выборы в США (2016 г.) и голосование по Brexit (2016 г.) показывают, что такие приложения — к сожалению, с нашей точки зрения — уже использовались.
• Обучение с подкреплением
В этом процессе обучения нет оптимального решения в начале этапа обучения. Система должна итеративно пробовать решения самостоятельно методом проб и ошибок, чтобы отбрасывать и/или дальше развивать их. Этот итеративный процесс движим "вознаграждениями" (за хорошие идеи решений) и "наказаниями" (за неудачные подходы). Эта концепция обучения часто используется, когда доступно мало обучающих данных или когда идеальный результат не может быть четко определен. Она также применяется, когда что-то можно узнать только из взаимодействия с окружающей средой.
В ходе этого процесса обучения алгоритм принимает решение и действует соответственно. Затем он получает вознаграждение, если действие приводит машину к цели. В качестве альтернативы, система будет наказана за отдаление от цели. Алгоритм автоматически оптимизирует свои действия, постоянно корректируя себя.
Эта вариация обучения была использована в соревновании между чемпионом мира по Го и компьютером Alpha-Go, описанном в разделе 1.2. Благодаря симуляции различных игр против самого себя и благодаря опыту "победы" (вознаграждение) и "поражения" (наказание) система могла постоянно совершенствовать свои стратегии.
Глубокое обучение — это особый дизайн нейронных сетей и подмножество машинного обучения (ср. рис. 1.2; ср. Arel, Rose, & Karnowsk, 2010, с. 13; Domingos, 2015; Kelly, 2014, с. 6–8; McKinsey, 2018b, с. 6). Глубокое обучение — это тип машинного обучения, который может обрабатывать более широкий диапазон источников данных, требует меньше ручной предварительной обработки данных и часто дает более точные результаты, чем традиционные подходы машинного обучения. "Глубина" относится к большому количеству слоев нейронной сети. Для этого настраиваются специальные сети, которые могут получать очень большие объемы входных данных и обрабатывать их через несколько слоев. Кроме того, используются специальные методы оптимизации, которые имеют еще более обширную внутреннюю структуру, чем классические нейронные сети. Здесь распознаются глубоко залегающие закономерности и корреляции, которые связывают существующие точки данных друг с другом.
Чтобы справляться с более сложными задачами, компьютеры сегодня могут учиться на собственном опыте и связывать новые входные данные с существующими. Людям больше не нужно сначала формально специфицировать эти данные. Машина постепенно учится собирать сложные концепции из более простых элементов. Визуализация этих корреляций может быть достигнута с помощью диаграмм, которые состоят из большого количества слоев и, таким образом, достигают "глубины" (ср. рис. 1.3). Именно поэтому мы говорим о "глубоком обучении". Примером этого является распознавание рукописного текста. Здесь пиксели должны быть последовательно обнаружены и обогащены содержимым. Классическое программирование делает практически невозможным распознать большое разнообразие рукописного текста. Для этого требуются концепции, которые учатся "самостоятельно".
Ящик памяти
Приложения ИИ обладают базовыми навыками восприятия, понимания, обучения и действия (ср. Bitkom & DFKI 2017, с. 29).
В этом контексте мы говорим о нейрокомпьютинге (также нейронных вычислениях). Это включает технологии, использующие нейронные сети, имитирующие человеческий мозг. Они обучаются для определенных задач, например, для распознавания образов в больших файлах. Комплексная цель приложений ИИ может быть описана термином обнаружение знаний (также обнаружение знаний в базах данных, KDD). Речь идет об "распознавании знаний в базах данных". Для этого применяются различные методы, которые пытаются выявить ранее неизвестные технические связи — так называемую основную идею — в больших наборах данных. Эта "основная идея" должна быть действительной, новой и полезной и в идеале показывать определенную закономерность. В отличие от интеллектуального анализа данных, обнаружение знаний включает не только обработку данных, но и оценку достигнутых результатов.
Ящик памяти
Чтобы демистифицировать Искусственный Интеллект, можно сформулировать это просто: Ядро Искусственного Интеллекта состоит в самостоятельной обработке больших объемов данных, распознавании закономерностей и выдаче описаний, предсказаний, рекомендаций или даже автономных решений на их основе. Приложения ИИ для таких задач часто работают быстрее и — в зависимости от системы — также дешевле, чем процессы, основанные на человеческом труде.
Особой особенностью нейронных сетей является их адаптивность в определенной области применения. Это означает, что эти сети могут самостоятельно меняться и таким образом непрерывно развиваться. В каждом случае полученные результаты основаны на так называемом "первоначальном обучении" с использованием обучающих данных, а также на обработке дополнительных данных. Вес соответствующих входных потоков имеет большое значение. Система ИИ самостоятельно присваивает более высокий вес тем данным, которые способствуют получению правильных ответов.
Для обучения нейронной сети сначала подается большое количество данных. В то же время сеть должна быть проинформирована о том, как должен выглядеть выход. Чтобы обучить сеть распознавать лица известных актеров, система должна обрабатывать множество фотографий актеров, не актеров, масок, статуй, лиц животных и т. д. во время первоначального обучения. Каждая отдельная фотография сопровождается текстом, описывающим содержимое фотографии как можно лучше. С одной стороны, это могут быть имена изображенных актеров, или, с другой стороны, указания, что это не актер, а маска или животное.
Предоставляя описательную информацию, модель может корректировать свои внутренние веса. Таким образом, она учится непрерывно совершенствовать свои методы работы. Узлы A, B и D могут сообщить узлу BB следующего слоя, что входное изображение является фотографией Дэниела Крейга. Напротив, узел C считает, что на снимке изображен Роджер Мур (например, потому что на фотографии рядом с актером показан Aston Martin, используемый в фильмах о Джеймсе Бонде). Если программа обучения теперь подтверждает, что на фотографии на самом деле изображен Дэниел Крейг, узел BB уменьшит вес входного узла C, потому что он сделал неправильную оценку. В то же время система увеличит веса для узлов A, B и D, потому что их результаты были правильными.
Каждый узел самостоятельно решает, какие входы из предыдущего слоя отправляются на следующий слой в какой форме. Для принятия этих решений нейронные сети используют правила и принципы. Может использоваться градиентное обучение, нечеткая логика, генетические алгоритмы и байесовский вывод. Здесь могут быть выработаны основные правила о взаимосвязях различных объектов в моделируемом пространстве. Система распознавания лиц может быть обучена следующим вещам (ср. Rouse, 2016):
• Брови находятся над глазами.
• Усы находятся под носом.
• Бороды могут быть над и/или рядом с ртом, на щеках и у основания шеи.
• Бороды преимущественно встречаются у мужчин; однако, существуют и женские бороды.
• Глаза, расположенные рядом друг с другом на одной высоте.
• Глаза справа и слева над носом.
• Рот находится под носом.
• И так далее.
Такой тип правил, который дается системе при первоначальной загрузке материала (так называемые предварительные правила), может ускорить обучение и сделать модель более эффективной. Они также делают предположения о природе проблемы, которые впоследствии могут оказаться либо нерелевантными и бесполезными, либо даже неправильными.
и контрпродуктивным. Поэтому решение о том, следует ли и какие правила определять заранее, имеет большое значение.
Кроме того, мы хотели бы обратить ваше внимание на еще один важный аспект: справедливость Искусственного Интеллекта. Люди, определяющие предварительные правила и вводящие данные в системы для обучения, по своей природе предвзяты. Таким образом, правила, используемые здесь, а также данные могут проявлять предвзятость в смысле искажения, что влияет на последующие оценки и рекомендации по принятию решений (например, при проверке кредитоспособности) — без (легкого) распознавания.
Ящик памяти
Основной источник ошибок в приложениях ИИ лежит в: предвзятости на входе — предвзятости на выходе!
Ярким примером этой опасности может служить юриспруденция. В США система ИИ должна была выносить конкретные судебные решения. Она обучалась на основе старых судебных решений. В ходе использования было обнаружено интересное явление. Если изменить цвет кожи обвиняемого с белого на черный, наказание внезапно возрастало. Здесь стало ясно, что предрассудки, лежащие в старых судебных решениях, нерефлексивно переносились из системы ИИ в новые юридические дела (ср. Hochreiter, 2018, с. 3; подробнее см. Kleinberg et al., 2019).
Для предотвращения таких рисков, связанных с искажениями в наборах данных, необходимо убедиться, что обучающие данные сбалансированы. Один из способов достижения этого — обмен сбалансированными наборами данных между компаниями. В 2018 году IBM предоставила данные миллиона фотографий лиц для использования в системах распознавания лиц (ср. Rossi, 2018, с. 21). Если для обучения систем ИИ использовались только европейские или только азиатские фотографии, результаты будут сфальсифицированы в отношении глобального использования. Кроме того, ответственная команда программистов ИИ должна обладать высокой степенью разнообразия (по возрасту, полу, национальности и т. д.), чтобы обучающие наборы данных и предварительные правила не содержали (бессознательных) стереотипов и предрассудков программистов.
Исследование 2017 года показывает, как быстро могут возникать такие искажения (ср. Lambrecht & Tucker, 2017). В нем было обнаружено, что реклама Facebook демонстрировалась с гендерной дискриминацией. Объявления о вакансиях в STEM-секторе (наука, технологии, инженерия и математика) демонстрировались женщинам реже, чем мужчинам. Эта неосознанно встроенная дискриминация возникла из-за того, что молодые женщины являются востребованной целевой группой в Facebook. Следовательно, размещение рекламы для них стоит дороже. Таким образом, если у алгоритма был выбор между мужчиной и женщиной с одинаковым показателем кликов, выбор пал на более дешевый вариант — в данном случае мужчину.
Ящик памяти
Во избежание возможных искажений в ваших данных следует использовать различные (надежные) источники данных. Высокая степень разнообразия в ваших командах автоматически приводит к избеганию предрассудков и стереотипов в системах ИИ, ведущих к неверным выводам. Аудит данных может оказать ценную поддержку, систематически проверяя качество поступающих данных.
Обучение на основе демонстрации — это интересное дополнение или альтернатива обучению роботов. Программирование роботов (особенно для производственных процессов) — сложная, трудоемкая и дорогостоящая задача, требующая высокой степени экспертных знаний. Если задачи, процессы и/или производственная среда меняются, используемых там роботов необходимо перепрограммировать. Поэтому компания Wandelbots предлагает решение. Обучение на основе демонстрации позволяет программировать роботов без написания новых программ. Демонстрируя роботам, как должна выполняться конкретная задача, управляющая программа учится необходимым процессам самостоятельно. Это позволяет экспертам по задачам обучать роботов в динамичной и сложной среде — без необходимости навыков программирования. Это означает, что новые задачи могут быть выучены роботом всего за несколько минут, без необходимости специальных знаний. В процессе обучения датчики робота и, при необходимости, другие внешние датчики записывают характеристики окружающей среды, необходимые для процесса обучения (ср. Wandelbots, 2019).
Ящик памяти
Вы должны проверить, в какой степени возможно использование обучения на основе демонстрации при обучении роботов.
В дополнение к избеганию неверных наборов данных, прозрачность процессов принятия решений в системах ИИ представляет собой серьезную проблему. Поскольку машина ИИ самостоятельно достигает результатов и решений, для пользователей, и особенно для тех, кого это затрагивает, возникает вопрос "Почему?". В конце концов, вы не хотите доверять свою судьбу "черному ящику", будь то решение о финансовых инвестициях (ключевое слово робо-консультант), отклонение заявления на кредит или автономное вождение. Скорее, вы хотели бы знать, почему решение было или принимается именно таким образом в конкретной ситуации.
Задача состоит в следующем: Объяснимый Искусственный Интеллект (XAI). Это означает попытку избежать "черного ящика" Искусственного Интеллекта и создать "серый ящик" Искусственного Интеллекта, который позволяет хотя бы частичную отслеживаемость результатов и решений. Цель состоит в том, чтобы сделать процесс и результаты использования ИИ более понятными. Здесь нам необходимо различать разные области:
• Прозрачность данных
Поскольку качество и "неподкупность" Искусственного Интеллекта зависят от доступных баз данных, заинтересованный пользователь должен иметь возможность проверять базы данных приложения ИИ. Если в этих данных выявлены искажения или нерелевантные популяции, результатам системы ИИ нельзя доверять. Следует отметить, что для критического анализа этих баз данных часто требуются экспертные знания; это обычно невозможно для непрофессионалов. Процессы сертификации с соответствующими тестовыми знаками для используемых данных могли бы помочь здесь.
• Прозрачность алгоритмов
В приложениях ИИ особенно важно распознавать, какие алгоритмы были использованы для достижения определенных результатов. Поскольку машина учится сама, этот процесс нелегко понять. Однако для принятия результатов ИИ необходимо иметь возможность распознавать хотя бы основные влияющие факторы
решения (например, в кредитном рейтинге клиентов или в рекомендации, каким лицам следует предложить новое предложение по конкретному каналу и в определенный момент времени). Готовность доверить себя системам ИИ зависит от такой прозрачности. В конце концов, никто (сегодня) не хочет полагаться на системы и их решения, которые невозможно отследить.
• Прозрачность предоставления данных
Цель здесь состоит в том, чтобы подготовить результаты для пользователей и/или тех, кого это затрагивает, таким образом, чтобы даже человек с небольшими математическими и/или статистическими знаниями мог понять полученные знания — насколько результаты автоматически не используются в текущих процессах. В кредитном рейтинге с поддержкой ИИ должно быть возможно понять, почему человек А не получает кредит по сравнению с человеком Б. В разработке судебных решений с поддержкой ИИ должно стать ясно, почему для ответчика X предлагается условный приговор и почему ответчик Y должен быть заключен в тюрьму.
Без Объяснимого Искусственного Интеллекта приложения ИИ остаются "черным ящиком", что затрудняет или делает невозможным критический анализ лежащих в основе процессов и результатов. Тогда пользователи не могут понять, как достигается результат, и им сложнее доверять результатам.
Ящик памяти
Сосредоточьтесь на Объяснимом Искусственном Интеллекте с самого начала — даже если ваши специалисты по ИИ предпочитают обходиться без него. Без определенной прозрачности данных, процессов и результатов вам будет трудно добиться признания пользователей для приложений ИИ и их результатов.
Технологии Искусственного Интеллекта можно различать по степени автоматизации. Пятиступенчатая модель на рис. 1.4 визуализирует возможное разделение труда между человеческим и механическим действием. Степень автоматизации решений зависит от сложности проблемы и производительности используемой системы ИИ. Следующие примеры иллюстрируют, какие правовые, этические и экономические вопросы связаны с соответствующим разделением труда. При принятии решений с помощью ИИ система ИИ поддерживает людей в их решениях. Это может быть алгоритм ИИ, который делает предложения о покупке на Amazon или приводит к автозавершению в наших поисковых запросах Google. Автокоррекция в смартфоне — еще один пример принятия решений с поддержкой. Множество забавных и раздражающих примеров ясно показывают, что некоторые пользователи позволяют системе ИИ принимать автономные решения здесь!
В случае частичных решений система ИИ уже освобождает пользователя от принятия решений (ср. рис. 1.4). Это относится к поисковым процессам в Интернете или в социальных сетях. Здесь пользователю представляется или резервируется информация в соответствии с определенными (непрозрачными) алгоритмами. Так создается так называемый "фильтр-пузырь", в котором каждый живет в своем (иллюзорном) мире, который может быть более или менее далек от реальности (ср. Pariser, 2017). Программы перевода на основе ИИ, доступные сегодня, также должны использоваться только для частичных решений. При критическом анализе
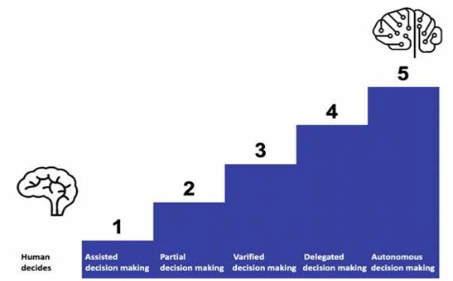
Рисунок 1.4 Пятиступенчатая модель автоматизации принятия решений. Источник: Адаптировано из Bitkom and DFKI (2017, с. 62)
результатов перевода, достигнутых сегодня, все еще могут быть обнаружены многие ошибки — особенно в более сложных текстах или диалогах.
При проверенных решениях идеи решений отдельного человека проверяются системой ИИ — по сути, как применение перекрестной проверки (ср. рис. 1.4). Если система ИИ и человек приходят к одному и тому же результату, это должно соответствовать. При принятии делегированных решений (частичные) задачи намеренно перекладываются человеком на систему ИИ. Часто это относится к контролю качества в производстве; здесь соответствующие системы самостоятельно решают, соответствует ли продукт требованиям качества или нет. При автономном принятии решений целые комплексы задач перекладываются на систему ИИ и выполняются там без дальнейшего вмешательства человека. Это имеет место при использовании робо-консультанта, который принимает независимые инвестиционные решения — часто в реальном времени (ср. разд. 8.1). При автономном вождении уже ясно из самого термина, что водитель делегировал всю ответственность за принятие решений роботу для управления транспортным средством.
Увеличение делегирования решений системам ИИ имеет различные последствия. Менее важно, если рекомендации по покупке, которые клиент получает на Amazon или Zappos, поддерживаются только ИИ и, таким образом, распространяются без вмешательства человека. Даже ошибки перевода, вызванные автоматизированными системами, такими как Google Translate или — гораздо более мощный — DeepL, в большинстве случаев не будут иметь серьезного влияния на жизнь и выживание. Ситуация совершенно иная с автономным вождением. Здесь системы ИИ должны принимать все решения в реальном времени — и это всегда вопрос жизни и смерти. Даже небольшое и краткое отклонение от собственной полосы движения может поставить под угрозу собственную жизнь и жизнь других (ср. разд. 1.2 о проблеме трамвая).
Резюме
• Искусственный Интеллект с его различными приложениями уже вошел в нашу повседневную жизнь.
• Аспекты человеческого интеллекта настолько разнообразны, что потребуется много лет разработок и высокие бюджеты, чтобы хотя бы приблизиться к человеческому интеллекту.
• Приложения Искусственного Интеллекта основаны на знаниях, полученных через нейронные сети. Используются концепции машинного обучения и глубокого обучения.
• Информация обрабатывается на разных уровнях.
• Для развития автоматизированного процесса обучения используются формы обучения, называемые обучением с учителем, обучением без учителя и обучением с подкреплением.
• Необходимо гарантировать, что данные для обучения алгоритмов и используемые изначально алгоритмы не содержат искажений, предрассудков и стереотипов. В противном случае не могут быть достигнуты "нейтральные" результаты.
• Основная задача — сделать процессы и результаты Искусственного Интеллекта понятными. Это задача Объяснимого Искусственного Интеллекта.
• Объяснимый Искусственный Интеллект относится к прозрачности используемых данных, прозрачности используемых алгоритмов и прозрачности предоставления данных результатов.
• Создание такой прозрачности является предпосылкой для принятия систем ИИ — внутри компании и за ее пределами.
1.2 Какие цели могут быть достигнуты с помощью Искусственного Интеллекта?
Человек всегда стремился имитировать природу и подражать найденным в ней решениям. Нож был выведен из когтя. Способность птиц летать вдохновила людей на разработку широкого разнообразия летательных аппаратов, включая захватывающий A 380. Огонь с его различными функциями был "одомашнен" человеком как печь, лампочка и обогреватель.
Человек поставил перед собой задачу, которая еще не решена: механическое воспроизведение человеческого интеллекта. Первые вычислительные машины начали разрабатываться уже в 17 веке. Абак, механическое вычислительное средство, до сих пор частично используемое, датируется вторым тысячелетием до н.э. Развитие компьютеров значительно продвинулось только в 1940-х годах благодаря немецкому разработчику Конраду Цузе. Машины Zuse Z3 и Zuse Z4 были первыми универсально программируемыми компьютерами. Уже тогда основной целью было сравняться с человеческим интеллектом с помощью технологий (ср. Bostrom, 2014, с. 4). С тех пор были достигнуты дальнейшие фундаментальные прорывы. В 1997 году многие люди внимательно слушали, когда действующий чемпион мира по шахматам Гарри Каспаров был впервые побежден шахматным компьютером IBM Deep Blue.
Затем потребовалось еще десять лет, до 2011 года, чтобы победить действующих чемпионов Кена Дженнингса и Брэда Раттера в интеллектуальном шоу Jeopardy, которое было наполнено остроумным языком, иронией и свободными ассоциациями. Победитель: компьютер IBM Watson. Комментарий Кена Дженнингса был захватывающим: "Брэд и я были первыми работниками умственного труда, которые были вытеснены новым поколением 'думающих' машин" (Kairos Future, 2015). Важно понимать, что к победе привело не только энциклопедическое знание Уотсона, но и способность понимать естественный язык, распознавать иронию, расшифровывать абстрактные утверждения, целенаправленно получать доступ к знаниям и быстро принимать решения.
Сам компьютер отвечал на естественном языке; однако, в то время он еще не мог понимать естественный язык. Поэтому вопросы викторины передавались на компьютер в виде текста. Затем алгоритмы просматривали архив знаний в поисках слов, связанных с запросом. Уотсон имел онлайн-доступ к Википедии и последним десяти томам New York Times. Из каждого запроса выбиралось 50–60 информационных единиц, и составлялся рейтинг из максимум 200 гипотез. Вопросы, на которые нужно было ответить, касались географии, точных дат или даже каламбуров. На основе многих тысяч вопросов Jeopardy Уотсон определил, какие алгоритмы лучше всего отвечают на какую категорию вопросов. Более 1000 алгоритмов работали параллельно. Уотсон победил человеческих гениев в области, где — в отличие от шахмат — доминируют двусмысленности, ирония и каламбуры (ср. Heise, 2011).
Затем потребовалось еще пять лет, до марта 2016 года, когда счет в игре Го, самой сложной игре в мире, составил 4:1 в пользу компьютера. Действующий чемпион мира по Го Ли Седоль из Южной Кореи был побежден программным обеспечением Google AlphaGo. Ли проиграл четыре из пяти игр самообучающемуся, постоянно совершенствующемуся программному обеспечению. Перед игрой чемпион мира был уверен в победе. В конце концов, игра Го гораздо более разнообразна, чем шахматы. Игровое поле имеет не только 64, но 361 поле. Это приводит к гораздо большему количеству игровых возможностей — задача как для человека, так и для машины. У чемпиона мира был только один — хорошо тренированный — мозг. AlphaGo, с другой стороны, имел доступ к двум нейронным сетям с миллионами связей. Компьютер мог как "думать", так и предсказывать наиболее вероятные характеристики своего противника. Особенностью было сочетание знаний с интуицией. Алгоритмы глубокого обучения позволяют не только анализировать тысячи ходов. Методом проб и ошибок нейронная сеть обучила себя учиться на собственном опыте — точно так же, как человек, но гораздо быстрее (ср. обучение с подкреплением в разделе 1.1).
После соревнования Ли Седоль сказал две вещи: Компьютер снова и снова удивлял его ходами, которые никто бы не сделал и никогда раньше не играл. В то же время, однако, он неоднократно чувствовал, что играет против человека (ср. Ingenieur, 2016).
Пища для размышлений
Эта победа Искусственного Интеллекта в борьбе с чемпионом мира по Го в 2016 году стала "моментом Спутника" для Китая, побудив его с полной силой обратиться к этой новой технологии (ср. Lee, 2018, с. 3). Термин "момент Спутника" обыгрывает самовосприятие
США, которое было поколеблено Советским Союзом в октябре 1957 года. Им удалось запустить первый искусственный спутник под названием "Спутник" в космос. С основанием NASA (Национальное управление по аэронавтике и исследованию космического пространства) в США это вызвало гонку между великими державами в космосе, которая привела к высадке американцев на Луну в июле 1969 года.
До поражения в игре Го лишь немногие специалисты в Китае занимались темой Искусственного Интеллекта. "Момент Спутника" стал ее завершением. С 2016 года началось настоящее увлечение ИИ, что пробудило любопытство сотен тысяч исследователей к новой технологии и побудило государство сделать крупные инвестиции — со значительным прогрессом в этой области.
Будет ли такой "момент Спутника" для США или Европы? Если да, то как долго нам придется его ждать?
Самое большое достижение современного Искусственного Интеллекта состоит в преобразовании существующей информации одного вида в информацию другого. Это включает перевод одного языка на другой, выявление мошенничества с кредитными картами, прогнозирование уровней запасов или расчет наилучшего возможного маршрута в реальном времени. Тогда как около 1990 года можно было выявить мошенничество с кредитными картами с вероятностью 80%, к 2000 году этот показатель уже вырос до 90–95%. Сегодня он составляет даже 98–99,9% (ср. Stolfo, Fan, Lee, & Prodromidis, 2016; West & Bhattacharya, 2016). Реальное достижение заключается в повышении точности. Усовершенствованные алгоритмы, а также более высокая доступность данных позволяют улучшить обслуживание во все большем количестве областей повседневной жизни при значительно более низких затратах, даже при применении к широким массам (ср. Agrawal et al., 2018, с. 27).
Ящик памяти
Удобство и низкие затраты являются решающими факторами прорыва технологии!
Пища для размышлений
Искусственный Интеллект может использоваться очень широко и — да — в мироизменяющем масштабе. Технически (почти) нет ограничений на возможные области применения Искусственного Интеллекта. Поэтому ограничения должны быть установлены этическими нормами. Тот факт, что это может произойти на глобальном уровне, следует поставить под сомнение, поскольку ранее преобладавший и часто способствовавший миру и богатству многосторонний подход все больше ставится под вопрос.
Сегодня технические усилия сосредоточены на разработке технологий ИИ, которые могут воспринимать, учиться, планировать, принимать решения и действовать немедленно — и часто одновременно приходится иметь дело с высокой степенью неопределенности. Следовательно, многие проекты ИИ больше не нацелены исключительно на имитацию человеческого облика и мышления, как это часто бывает в базовых исследованиях ИИ. Компании все больше стремятся достичь социальных и, прежде всего, экономических преимуществ, используя Искусственный Интеллект. Существуют разные подходы к определению целей ИИ. Распространенный подход состоит в разделении Искусственного Интеллекта следующим образом:
• Сильный Искусственный Интеллект
• Слабый Искусственный Интеллект
Эта классификация была впервые введена в 1980 году американским философом Джоном Серлом (ср. Searle, 1980, с. 5–7). Сильный Искусственный Интеллект описывает стремление воспроизвести, оптимизировать и даже продвинуться в новые области производительности с помощью технологий во многих областях нашей повседневной жизни. Слабый Искусственный Интеллект, с другой стороны, уже достигается путем выполнения задачи на уровне человека или немного выше — игры в шахматы, предоставления информации клиентам или анализа пяти миллионов записей данных в реальном времени. Речь идет не столько о имитации человеческих способностей, сколько о решении сложных проблем и работе с вещами лучше, чем позволяют человеческое познание и физические возможности.
В то время как приложения слабого Искусственного Интеллекта до сих пор доминировали, исследователи все больше продвигаются к приложениям сильного Искусственного Интеллекта. Ожидается, что технологии ИИ в среднесрочной перспективе превысят критическую "массу знаний" благодаря их способности к самообучению. Уже описанная способность к самообучению приводит к тому, что система без внешней поддержки может пополнять свою базу знаний исключительно на основе полученных экспериментальных данных, своих собственных наблюдений и выводов, и таким образом оптимизировать свое поведение при решении проблем. Это приведет к истинному взрыву интеллекта, ведущему к сверхинтеллекту — интеллекту, который превосходит границы человеческой мысли, чувств и действий (см. рис. 1.5). Такой интеллект был бы воплощением сильного Искусственного Интеллекта.
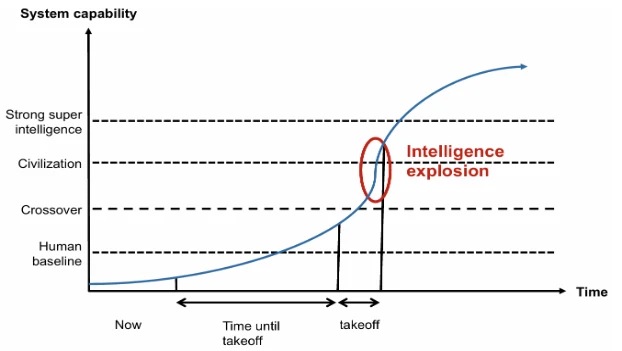
Рисунок 1.5 Развитие до взрыва интеллекта. Источник: Адаптировано из Bostrom (2014, с. 76)
Этот сверхинтеллект эмансипируется от человеческого интеллекта и придет к иным решениям, чем те, которые придумывал человек до сих пор — на основе большего объема данных, более быстрой обработки и более объективной (?) оценки. Будут ли эти сгенерированные ИИ решения лучше или хуже, чем те, которые были созданы руками человека, можно решить только на основе ценностей. Это порождает ряд вопросов:
• Кто определяет ценности, на которых системы ИИ основывают свои решения и действия — все еще люди или сама машина?
• Какие "правильные" ценности вообще?
• Что было бы "оправданным" — и с чьей точки зрения это определено?
• Что происходит, когда ценности человека и машины больше не совпадают?
• В соответствующих конфликтных ситуациях кто решает — если необходимо, в реальном времени — какой канон ценностей?
• Как долго еще человек будет у руля?
• Будут ли нас вообще спрашивать — и если да, то кто?
Ящик памяти
Хотя есть законные опасения относительно разработок сильного ИИ, мы должны рассмотреть возможность развития сверхинтеллекта. Одно ясно: если сверхинтеллект появится, он окажет кардинальное влияние на наше общество!
Пища для размышлений
На фоне этого есть фраза, сформулированная гением Хокингом (Hawking, 2014): "ИИ может стать концом человеческой расы".
Центр Leverhulme по будущему интеллекта проводит фундаментальные исследования по теме Искусственного Интеллекта в этом контексте. Миссия определена следующим образом (Leverhulme Centre, 2019):
Наша миссия в Центре Leverhulme по будущему интеллекта (CFI) заключается в создании нового междисциплинарного сообщества исследователей с тесными связями с технологами и политическим миром, и с четкой практической целью: работать вместе, чтобы гарантировать, что мы, люди, максимально используем возможности Искусственного Интеллекта по мере его развития в ближайшие десятилетия.
CFI исследует возможности и вызовы технологий ИИ. Темы варьируются от алгоритмической прозрачности до исследования воздействия Искусственного Интеллекта на демократию. Также предполагается, что в компьютерах — возможно, еще в этом столетии — будет создан интеллект, соответствующий человеческому интеллекту. Цель CFI состоит в том, чтобы объединить лучшее человеческого интеллекта для максимального использования машинного интеллекта (ср. Leverhulme Centre, 2019).
Рэй Курцвейл — директор по инженерии в Google — ожидает взрыва интеллекта уже примерно к 2045 году. Это приведет к гигантскому дополнению человеческого мозга и, таким образом, кардинально повысит общую эффективность человека. В крайних случаях это может означать, что мы преодолеем собственную биологию (включая смерть) и сольемся с технологиями (ср. Galeon, 2016; Kurzweil, 2005)?
В этом контексте используются два термина: загрузка (uploading) и смещение (upshifting). Загрузка — это (пока еще) гипотетический процесс, при котором совокупность человеческого сознания переносится на чрезвычайно мощный компьютер. Это перенесенное сознание будет включать в себя всю личность человека со всеми его воспоминаниями, опытом, эмоциями и т. д. В ходе загрузки этот перенос происходит за один шаг. Смещение предполагает, что этот процесс происходит постепенно, то есть небольшими шагами. Для этого нейроны мозга постепенно заменяются электронными компонентами. Конечный результат одинаков для обоих процессов, различается только временной промежуток.
Описанные здесь разработки называются трансгуманизмом. Речь идет о биологическом расширении возможностей человека с помощью компьютеров (ср. Russell & Norvig, 2012, с. 1196). Сначала это может показаться абстрактным, но давайте поближе рассмотрим медицинские разработки. Технологии всегда играли важную роль в медицине. Протезы в любой форме служат расширением поврежденных частей тела и замещают разрушенные функции. То, что началось с деревянных ног, очков, а позже и кардиостимуляторов, сейчас все больше и больше расширяется на нейронном уровне. Цель состоит в том, чтобы облегчить страдания пациентов с болезнью Паркинсона, эпилепсией или психологическими заболеваниями, такими как депрессия, путем вмешательств непосредственно в мозг. Для автономной стимуляции определенных областей мозга используются нейротехнологические имплантаты (ср. Krämer, 2015, с. 40–42; Stieglitz, 2015, с. 6).
Поэтому можно задать вопрос:
• Насколько трансгуманизм уже присутствует в наших текущих исследованиях?
• В какой форме следует включать трансгуманизм в базовые политические и экономические решения?
• Какие эффекты оказывают такие вмешательства непосредственно в мозг на личность человека и наше общество?
• Что определяет нас как людей?
Пища для размышлений
Развитие в направлении трансгуманизма ясно показывает, что сегодняшние ограничения Искусственного Интеллекта больше не лежат в области технологий. Скорее, существует срочная необходимость в действиях по прояснению связанных с этим этических вопросов до того, как технологические разработки будут продолжать нас опережать! В противном случае визионеры-ученые возьмут руль ИИ — из любых регионов мира и с любым ценностным основанием, которое у них есть.
В дополнение к промоутерам Искусственного Интеллекта существует большое количество критиков ИИ, которые указывают на опасности комплексного использования Искусственного Интеллекта и/или сомневаются в достоверности сильного Искусственного Интеллекта. Среди них такие личности, как Пол Аллен, Гордон Белл, Дэвид Чалмерс, Джефф Хокинс, Дуглас Хофштадтер, Гордон Мур, Стивен Пинкер, Терман Роджерс и Тоби Уолш, а также различные учреждения по всему миру (ср. Allen, 2011; Bitkom & DFKI, 2017, с. 29–31; Chalmers, 2010; IEEE Spectrum, 2008; Walsh, 2016). Они приводят различные причины, по которым технологическая сингулярность не является тем, что
ожидает нас в среднесрочной перспективе или вообще. Термин технологическая сингулярность указывает на момент времени, когда машины усовершенствуют себя Искусственным Интеллектом с такой скоростью, что технический прогресс ускорится до такой степени, что предсказать будущее человека и человечества станет невозможно.
Даже если не предвидится, когда именно следует ожидать тех или иных результатов и когда или будет ли достигнута технологическая сингулярность из-за неопределенностей в будущем развитии ИИ, необходимость определения этических целей остается. Ярким примером является проблема трамвая с автономными транспортными средствами:
• Как система должна принимать решение в опасной ситуации?
• В случае неизбежной аварии должна ли она ставить под угрозу жизнь ребенка?
• Или смерть пожилой пары?
• Или она должна врезаться в стену и таким образом рисковать жизнью водителя и, возможно, других пассажиров?
• Можем ли мы разделить человеческие жизни на более и менее ценные группы и таким образом решать о жизни и смерти?
• Или мы хотим использовать генератор случайных чисел, который принимает окончательное решение независимо от спецификаций программиста?
Пища для размышлений
В этом контексте говорят и об алгоритме смерти; в конце концов, алгоритм будет решать, кто выживет, а кто нет!
Интересно отметить, что для "машины" установлены более высокие моральные стандарты, чем для человека. Потому что даже у людей-водителей нет обязательных правил, как принимать решения в таком случае.
Ответы на такие вопросы могут иметь устойчивые социальные, политические, экологические и экономические последствия. Тот факт, что овладение технологией ИИ не является тривиальным, уже можно признать из того, что люди часто больше не могут понять, как некоторые программы ИИ принимают свои решения (ср. Объяснимый Искусственный Интеллект в разделе 1.1). Это потому, что Искусственный Интеллект использует разные алгоритмы. С одной стороны, результат классического дерева решений все еще легко реконструируется. С другой стороны, если используются такие концепции, как обучение с подкреплением или глубокое обучение (ср. раздел 1.1), трудно добиться отслеживаемости процесса и результата, обрабатывая миллионы параметров (ср. Rossi, 2018, с. 21).
Ящик памяти
Использование алгоритмов ИИ все чаще приводит к компромиссу между отслеживаемостью и точностью. Пользователи должны решить, что для них важнее: отслеживаемость подхода или точные результаты. Оба часто невозможно достичь одновременно.
Если решения следует соблюдать — несмотря на отсутствие отслеживаемости — эти системы ИИ должны быть запрограммированы с "ценностями", на которых основаны решения. Но что произойдет, если система ИИ определит, что запрограммированные ценности серьезно ограничивают пространство решений и предотвращают якобы "наилучшее" решение? Может ли система самостоятельно развивать ценности и таким образом изменять их? Потому что даже ценности, определенные людьми на основе сегодняшних знаний, могут устареть — в свете гораздо более полных, сгенерированных ИИ знаний.
Пища для размышлений
Что произойдет, если система ИИ определит, что выживание планеты Земля в долгосрочной перспективе возможно только с населением в один миллиард человек — или полностью без людей и их массивного вмешательства в природу? Какие решения должны быть приняты и кем применены? Или уже предпосылка неверна, что планета Земля должна продолжать существовать — когда есть достаточно других планет (будь то одушевленные или нет)? Или фокус — это просто дальнейший рост человечества — любой ценой?
Вопросы, на которые нельзя ответить без системы ценностей. Но кто имеет право разработать эту систему ценностей — кем легитимирован?
В любом случае, степень, в которой Искусственный Интеллект может принимать решения независимо, должна быть определена до внедрения ИИ, и где инстанция человеческого контроля незаменима. Это единственный способ определить этот предел заранее. Или он будет продолжать смещаться в сторону автономии систем ИИ, потому что у нас был хороший опыт с результатами? Можем ли мы поэтому когда-либо создать безопасный и прочеловеческий Искусственный Интеллект? Использование систем ИИ военными достигнет серьезных пределов (ср. разд. 9.2).
Философ Томас Метцингер выступает против попыток в науке программировать сознание, чтобы обеспечить наше плюралистическое общество (ср. Metzinger, 2001). Макс Тегмарк основал Future of Life Institute и опубликовал список с сотнями подписей ученых против разработки автономных систем вооружения (ср. Future of Life Institute, 2015). Но именно это уже происходит сегодня: дроны с управлением ИИ, которые не только выполняют полет автономно, но и самостоятельно распознают и атакуют цели (людей и вещи). Прошлое здесь не является светлым пятном надежды: до сих пор почти все технологические возможности широко использовались в военных целях — вплоть до атомной бомбы.
Пища для размышлений
• Насколько автономность мы, как потребители и лица, принимающие решения в компаниях, хотим предоставить технологиям ИИ?
• Где мы устанавливаем этические границы для Искусственного Интеллекта?
• Как мы можем установить, что такое установление границ целесообразно?
• Какими целями мы руководствуемся?
• Какие ценности мы основываем на разработках — что является "добром", а что "злом"?
Совет по художественному чтению
Тем, кто интересуется "историей завтрашнего дня", стоит взять в руки бестселлер Юваля Ноя Харари "Homo Deus".
Резюме
• Искусственный Интеллект — это не просто имитация человеческого интеллекта. Он также служит для выполнения действий, которые люди не могли выполнять до сих пор, не так быстро и/или не так хорошо.
• Общее подразделение Искусственного Интеллекта — на слабый Искусственный Интеллект и сильный Искусственный Интеллект.
• Слабый Искусственный Интеллект имеет целью достижение человеческих способностей на том же или немного более высоком уровне (например, игра в шахматы).
• Сильный Искусственный Интеллект описывает стремление достичь человеческих возможностей с помощью технологий во всех областях нашей повседневной жизни.
• Развитие сильного Искусственного Интеллекта ведет к таким явлениям, как сверхинтеллект, технологическая сингулярность и трансгуманизм.
• Разработки в трансгуманизме называются загрузкой (uploading) и смещением (upshifting).
• До развития сильного Искусственного Интеллекта — в идеале — необходима глобальная этическая договоренность об использовании ИИ, которая, вероятно, никогда не будет достигнута.
1.3 Области применения Искусственного Интеллекта
До сих пор не существует единого подхода к описанию различных областей применения Искусственного Интеллекта. Некоторые эксперты сосредоточены на вопросах, связанных с информационными технологиями. В результате появляются категории ИИ, такие как "машинное обучение", "моделирование", "решение проблем" или "неопределенные знания" (ср. Görz, Schneeberger, & Schmid, 2013; Russell & Norvig, 2012). По нашему мнению, такие классификации имеют мало смысла, поскольку они скорее направлены на основы Искусственного Интеллекта, а не на захватывающие области применения. Мы видим самые важные области применения Искусственного Интеллекта, как показано на рис. 1.6.
Границы между областями применения Искусственного Интеллекта, показанными на рис. 1.6, все больше размываются. Это иллюстрируется примером автономного транспортного средства:
• Если водитель вводит пункт назначения с помощью голосовой команды, и автомобиль подтверждает пункт назначения с помощью естественного разговорного языка, такого как "Пункт назначения Сиэтл подтвержден", во время ввода и вывода происходит обработка голоса.
• Автономный или полуавтономный легковой автомобиль должен непрерывно обрабатывать множество изображений с разных камер. Это единственный способ распознавать красные светофоры, знаки "стоп" и ограничения скорости, а также пешеходов, велосипедистов и других участников дорожного движения. Основой для этого является обработка изображений.
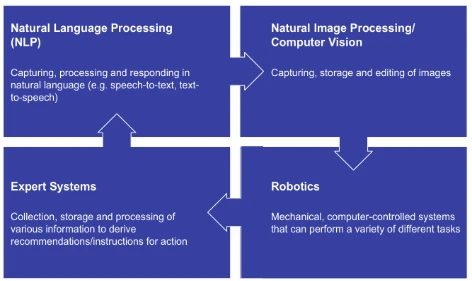
Рисунок 1.6 Области применения Искусственного Интеллекта (Рисунок авторов)
• Во время поездки пассажиры могут узнать о самых дешевых автозаправках, туристических достопримечательностях и интересных ресторанах и отелях. Для этого используются экспертные системы.
• В конце концов, весь автомобиль с его интегрированными технологиями (включая распознавание голоса и изображений) представляет собой особенно мощного робота. Его задача — безопасно и экономично перевозить пассажиров и/или грузы из пункта А в пункт Б.
В результате многие приложения ИИ сегодня уже представляют собой смешанные формы областей применения Искусственного Интеллекта, представленных здесь.
Ящик памяти
Искусственный Интеллект — это сквозная технология — точно так же, как компьютеры, автомобили, телефоны и Интернет. Поэтому приложения ИИ рано или поздно проникнут во все отрасли и на все этапы создания стоимости, более или менее комплексно.
Deloitte (2017) обнаружил, какие области Искусственного Интеллекта, определенные на рис. 1.6, доминируют сегодня, проведя всемирный опрос 250 руководителей, ориентированных на ИИ. Рисунок 1.7 показывает, что роботизированная автоматизация процессов является наиболее распространенной формой. Обработка голоса занимает второе место, за ней следует использование экспертных систем и физических роботов. Обработка изображений не была упомянута в этом исследовании. По нашему мнению, области машинного обучения и глубокого обучения нейронных сетей, упомянутые на рис. 1.7 — как уже объяснялось выше — представляют собой не независимые области применения, а скорее формируют основу использования ИИ.
Ниже индивидуальные области применения Искусственного Интеллекта рассматриваются более подробно.
1.3.1 Обработка естественного языка (NLP)
Естественные языки — это те, на которых говорят люди. От них следует отличать языки программирования, такие как Java или C++. Обработка естественного языка (NLP) или распознавание речи занимается компьютерными программами, которые позволяют машинам понимать человеческую речь, как устную, так и письменную. Это специфическая форма автоматического распознавания образов, называемая лингвистическим интеллектом.
На рисунке 1.8 показано значение распознавания речи в будущем. Начиная с 2018 года, ожидается пятикратное увеличение доходов к 2021 году. Это веские причины для того, чтобы вы ознакомились с этими областями применения сегодня.
Нам необходимо различать следующие типы применения обработки естественного языка:
• Речь в текст (STT)
В этом приложении устное слово преобразуется в цифровой текст. Это относится к приложению Siri (Apple), если электронные письма или заметки диктуются прямо в смартфон.
• Речь в речь (STS)
Такое приложение доступно в Google Translate. Здесь входная речь на английском языке немедленно переводится в речь на японском или китайском языке. Для вывода языка используется так называемая генерация естественного языка (NLG). При использовании цифровых персональных помощников (таких как Alexa или Google Home) последовательности вопросов и ответов также используют этот вариант. Точнее, это следует называть: STT—Обработка—TTS. Поскольку цифровые помощники сначала преобразуют устную речь в цифровой текст, интерпретируют и обрабатывают его, генерируют цифровой текст в качестве ответа, который затем озвучивается — и все это за несколько секунд!
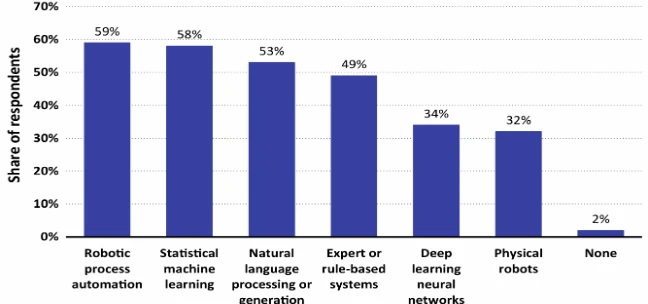
Рисунок 1.7 Статус-кво использования Искусственного Интеллекта в 2017 году — по всему миру. Источник Согласно Deloitte (2017, с. 6)
• Текст в речь (TTS)
Это приложение создает устный вариант текста на основе цифровых документов. Электронные письма, SMS и другое содержимое могут быть "прочитаны вслух" таким образом. Акустические объявления в системах голосового диалога также относятся к этой категории. Эта функция может быть особенно полезна для людей с нарушениями зрения, которые таким образом могут "читать" экранную информацию.
• Текст в текст (TTT)
В приложениях TTT электронный текст преобразуется в другой язык — также в текстовой форме — с помощью программы перевода, такой как DeepL или Google Translate.
Для систем ИИ обработка такого рода данных представляет собой особую задачу. Причина в том, что каждый человек имеет свою индивидуальную устную и письменную форму выражения. Она состоит из индивидуального сочетания диалекта, акцента, словарного запаса, фонологии, морфологии, синтаксиса, семантики и прагматики (ср. Nilsson, 2010, с. 141–143). Приложения NLP должны уметь понимать "истинное" значение высказывания — как это делает человеческий мозг (хотя и не всегда правильно!) — несмотря на различия во всех этих областях. Если в общении используются остроумие, ирония, сарказм, каламбуры и риторические фразы, это приводит к все еще трудной для многих систем ИИ дилемме данных.
Процесс ИИ, отвечающий за обработку устной речи, называется пониманием естественного языка (NLU). Особенность заключается не только в чистом смысле предложения, но и в многослойном значении, которое может с ним ассоциироваться. Это можно проиллюстрировать примером так называемой четырехсторонней модели (модели четырех ушей, также называемой коммуникационным квадратом; ср. рис. 1.9). Каждое устное сообщение может содержать четыре различных вида информации:

Рисунок 1.8 Прогноз глобальной выручки от распознавания речи — 2015–2024 гг. (в млн долл. США). Источник Statista (2018 г.)
• Фактическая информация
Речь идет о конкретной, "чистой" информации высказывания.
• Самораскрытие
С сообщением отправитель одновременно передает — намеренно или ненамеренно — информацию о себе, которой он хочет поделиться с другим человеком — или нет.
• Отношение
Используя термины и тип акцента, мы также "раскрываем" что-то о том, что мы думаем о другом человеке и как мы относимся к этому человеку.
• Призыв
Часто сообщение также содержит просьбу или приглашение, адресованное другому человеку.
Таким образом, неясно определено, как получатель обрабатывает наше сообщение. Наш собеседник потенциально слушает всеми четырьмя ушами и решает — подсознательно или сознательно — какую именно грань он или она (хочет) услышать из сообщения.
Ящик памяти
Многие недоразумения в повседневном общении — частном и профессиональном — возникают из-за того, что мы обычно не осознаем все четыре аспекта сообщения, которое мы отправляем или получаем. Недоразумения — это логическое следствие — но их можно избежать!
Известный пример иллюстрирует это. Представьте следующую ситуацию: Она сидит за рулем обычной машины, он — на пассажирском сиденье. Теперь он говорит: "Светофор
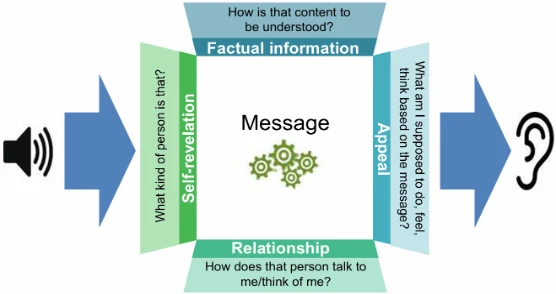
Рисунок 1.9 Четырехсторонняя модель — четыре аспекта сообщения. Источник: Адаптировано из Schulz von Thun (2019)
зеленый." Что можно услышать в зависимости от качества отношений и опыта, полученного двумя протагонистами?
• Фактическая информация: Светофор зеленый. Мы можем ехать!
• Самораскрытие: Я гораздо более квалифицирован, чем ты, чтобы водить машину, потому что я уже заметил, что светофор зеленый!
• Отношение: Я всегда должен говорить тебе, что делать!
• Призыв: Просто поезжай!
Долговечность предполагаемых отношений между двумя людьми во многом зависит от того, какое из четырех ушей используется для получения сообщения и его интерпретации.
Ящик памяти
Используйте четырехстороннюю модель в течение нескольких дней в своей профессиональной и частной жизни — и распознавайте, какие недоразумения возникают, когда мы не осведомлены о различных измерениях нашего общения. Здесь мы можем только стать лучше! Таким образом, мы можем прояснить — в случае неожиданных реакций со стороны другого человека — какое сообщение мы "на самом деле" хотели отправить (например, что светофор показывает "зеленый").
Система ИИ должна также развить способность модели четырех сторон — которая даже у людей не разработана комплексно — если она хочет стать эмпатичным, сострадательным собеседником. Многие приложения еще далеки от этого, как мы можем видеть в многих приложениях изо дня в день.
Рисунок 1.10 показывает все, что относится к теме обработки естественного языка. Здесь снова появляется термин понимание естественного языка (NLU). NLU является подмножеством NLP. Функции, выходящие за рамки чистого понимания речи или чистого воспроизведения речи, относятся к области NLP.
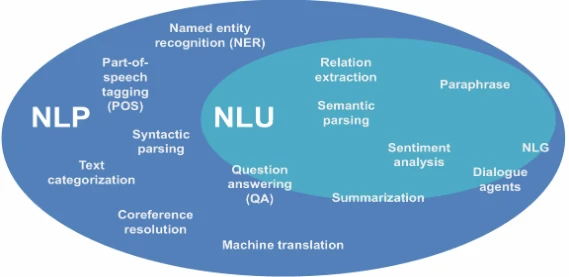
Рисунок 1.10 Функции обработки естественного языка. Источник: Адаптировано из MacCartney (2014)
Понимание естественного языка относится к декодированию естественного языка, т.е. механической обработке входной информации, представленной в виде текста или устной речи (ср. рис. 1.10). Это делается с помощью семантического анализа или извлечения информации. Семантика занимается значением языковых знаков и последовательностей знаков; речь идет о значении и содержании слова, предложения или текста. Термин парсинг означает разбивку или анализ. Оценка с помощью семантического парсинга позволяет понимать отдельные слова или предложения.
Для этой цели также используется парафраз (см. рис. 1.10). Это означает транскрипцию языкового выражения другими словами или выражениями. Необходимо преобразовать информацию естественного языка в машинное представление ее интерпретации. Извлечение отношений фиксирует содержание текстов и анализирует множественные ссылки внутри предложений в контексте. Если пресс-секретарь Martin Miller из Capital Inc. отвечает на вопросы журналистов в тексте, это означает, что Martin Miller является сотрудником Capital Inc. или по крайней мере действует от их имени.
Анализ настроений используется для определения специфической информации из голосовых сообщений (ср. рис. 1.10). Часто проводится различие между позитивными, нейтральными и негативными настроениями. Таким образом, из комментариев в Twitter можно определить, является ли твиттерщик скорее критическим, нейтральным или позитивным по отношению к политику, партии и/или определенным политическим проектам. То же самое можно сделать в отношении брендов, менеджеров и компаний.
Вместе эти анализы формируют основу для комплексного понимания передаваемого голосового сообщения с целью генерации информации на его основе. Для этой цели используются диалоговые агенты. В дополнение к цифровым персональным помощникам (таким как Alexa, Bixby, Cortana, Google Assistant, Siri & Co.; ср. разд. 4.1.2), диалоговые агенты все чаще внедряются для предоставления поддержки клиентов. Возможны все варианты ввода-вывода: текст-текст, текст-речь, речь-текст или речь-речь, а также их комбинации в рамках диалога. Здесь снова используется генерация естественного языка (NLG).
Переход к NLP начинается там, где требуется начальная интерпретация языка, например, ответы на вопросы или написание кратких изложений текстов (ср. рис. 1.10). Точное разграничение, как это часто бывает, размыто. Самая сильная форма краткого изложения — это категоризация текста, которая обобщает все содержание одним словом или фразой. Это будет показано на примере смысла отзывов клиентов. Одно высказывание может быть таким: "Наушники были слишком дороги!!! Я никогда не видел такой плохой обработки раньше, и разъем уже сломан." Комментарий может быть отнесен к категории "цена" по ключевому слову "дорогой". Однако, как в данном случае, часто имеет смысл сделать несколько назначений. Категории "продукт" (по термину "наушники") и "качество" (распознается по терминам "обработка" и "сломан") также рассматриваются в этом примере. При наличии тысяч комментариев, которые получает онлайн-ритейлер, оценка становится намного проще, когда эти категории определены.
Перевод текста на другой язык также требует комплексной интерпретации NLU. Кроме того, следует использовать дополнительные методы анализа. Здесь применяется синтаксический анализ. В отличие от семантики, синтаксис — это учение о том, как формируются предложения, т.е. как слова и группы слов обычно
соединены в предложения. Следовательно, здесь анализируются грамматические структуры текста и используются для представления контекстно-свободной связи между отдельными элементами слов. Термин парсинг означает разбивку или анализ. Благодаря совместной оценке с помощью семантического и синтаксического парсинга, теперь возможно не только понять отдельные слова или предложения, но и вывести полное содержание, обработать его и сгенерировать ответы.
Кроме того, используется маркировка частей речи (POS-tagging). Маркировка частей речи означает аннотацию или добавление. В частности, в контексте обработки естественного языка это означает, что слова или целые тексты сопровождаются дополнительными объяснениями или дополнительной информацией для улучшения понимания. Это направлено на исключение двусмысленностей. Этот тип добавления можно объяснить на примере следующего предложения: "Женщина работает в компании". Соответствующие аннотации выглядят следующим образом:
• "the" (аннотация: определенный артикль, единственное число)
• "woman" (аннотация: существительное, женский род, единственное число, именительный падеж)
• "works" (аннотация: конечный глагол, настоящее время, 3-е лицо единственное число, изъявительное наклонение, производное от основной формы "work")
• "in" (аннотация: предлог)
• "the" (аннотация: определенный артикль, единственное число)
• "company" (аннотация: существительное, единственное число)
Другой метод, связанный с извлечением информации, — это распознавание именованных сущностей (NER). Здесь система пытается идентифицировать все имена собственные, такие как имена, фамилии, названия брендов, названия компаний и т. д., и присвоить им соответствующее значение. Если это удается, команда авторов "Kreutzer/Land" не будет неправильно переведена с немецкого на английский как "Kreutzer/Country", мой родной город "Königswinter" не будет переведен в "Royal winter" программой перевода (как это происходило в тестовых запусках), а "Mark Zuckerberg" больше не будет неправильно переведен как "Mark Sugar Mountain"!
При дальнейшей обработке текста разрешение кореференции определяет, какие слова относятся к одной и той же сущности (т.е. единице), чтобы сделать соответствующее назначение. Примером может служить следующее: Одно предложение говорит об "Audi". Затем следует предложение: "Компания может оглянуться на долгую традицию автомобилестроения, в которой ей удалось расти в долгосрочной перспективе". В данном случае "компания" и "it" относятся к сущности "Audi". Это назначение является важной основой для глубокого понимания, которое необходимо для NLU.
Ящик памяти
Программы NLP анализируют текст на предмет грамматических структур, присваивают слова определенным группам слов или делают другие сверхординарные назначения, выходящие за рамки фактического содержания текста. NLU занимается — как его подмножество — чистым декодированием содержания текста или устной речи. Только взаимодействие различных этапов анализа обеспечивает комплексное понимание — как основу успешной коммуникации.
Цель приложений NLP — дать возможность машинам общаться с людьми на естественном языке. Помимо человеко-машинного общения, соответствующие программы сегодня также позволяют улучшить общение между людьми, давая возможность людям с нарушениями речи, письма и/или чтения использовать системы ИИ.
Сегодня чат-боты (также известные как боты или голосовые агенты) все чаще используются для использования описанных функций ИИ. Нам следует различать два варианта:
• Текстовые диалоговые системы (TTT)
• Языковые диалоговые системы (STS)
Первыми вариантами чат-ботов были чисто текстовые диалоговые системы (TTT), которые позволяли общаться между человеком и технической системой. Для этого чат-бот предлагал отдельную область для ввода текста и отдельную область для вывода текста для общения с системой на естественном, письменном языке. Может использоваться аватар. Аватар — это искусственное лицо или графическая фигура, которую можно четко связать с виртуальным миром. Большинству пользователей знакомы такие фигуры из компьютерных игр. В контексте чат-ботов они представляют собой виртуальных помощников, призванных сделать общение с системой "более естественным" (ср. также разд. 4.1.2).
Подмножество чат-ботов — это социальные боты, которые активно работают в социальных сетях и управляются с учетной записи. Там они могут создавать тексты и комментарии, связывать и пересылать контент. Если они вступают в прямой диалог с пользователями, их функциональность соответствует функциональности чат-ботов. Если эти социальные боты представляются как реальные люди, они являются фейковыми аккаунтами с фейковыми профилями пользователей. Социальные боты также могут идентифицировать себя как машины (ср. пример Microsoft Tay в разд. 4.1.2). Социальные боты анализируют публикации и твиты и могут автоматически активироваться, если распознают определенные хэштеги или другие ключевые слова, определенные как релевантные. Таким образом, социальные боты могут усиливать контент (текст и изображение), циркулирующий в социальных сетях, и, следовательно — в зависимости от оценки — иметь экономический и политический манипулятивный эффект (ср. Bendel, 2019).
Чат-боты, разработанные как речевые диалоговые системы (STS), используют речь для ввода и/или вывода — больше не тексты. Это делает общение с чат-ботом все более похожим на прямое вербальное общение. Такие системы наиболее широко используются в форме цифровых персональных помощников, которые начали свою кампанию завоевания как Alexa, Bixby, Cortana, Google Assistant и Siri (подробнее см. разд. 4.1.2 и 4.1.3).
1.3.2 Обработка естественных изображений/Компьютерное зрение/Обработка изображений
Обработка изображений (также известная как обработка естественных изображений или компьютерное зрение) — это обработка сигналов, представляющих изображения (ср. рис. 1.6). В основном это фотографии и видеоконтент. Результатом обработки изображений может быть либо изображение, либо набор данных, представляющих характеристики обработанного изображения. Последнее
называется распознаванием изображений (также известным как машинное зрение). Это распознавание изображений может относиться к неподвижным изображениям (фотографиям) и движущимся изображениям (видео). На последующем этапе информация об изображениях обрабатывается для инициации решений или дальнейших этапов процесса (ср. Beyerer, Leon, & Frese, 2016, с. 11). Это также о специфической форме автоматического распознавания образов, которая здесь называется визуальным интеллектом. Этот вид обработки изображений отличается от обработки изображений, при которой содержимое изображений модифицируется (например, с помощью Adobe Photoshop).
Оценка изображений (фотографий и видео) доступна, когда нужно распознавать людей на изображениях. Процесс распознавания изображений называется тегированием. Он используется на Facebook. Это позволяет автоматически распознавать пользователей на фотографиях и видео, загруженных в Facebook, без их пометки другими. Для этой задачи Facebook получает доступ к профильным фотографиям пользователей, а также к фотографиям, на которых люди уже были четко помечены. На основе этих данных создается так называемая цифровая идентификационная метка, которая затем используется для поиска по существующим или вновь загруженным изображениям. Благодаря этому подходу Facebook продолжает получать релевантные данные о связях между пользователями (Пользователь А и Б; Пользователь А, С и G) и их соответствующей активности (одни в Таиланде, вместе на вечеринке, в походе, на пляже, на Великой Китайской стене и т.д.). Поскольку большой объем данных становится все больше, Facebook лучше знает нас, и реклама становится — якобы — более релевантной, и, следовательно, ее дороже продавать! Мы можем активно решать, хотим ли мы этого и в какой степени.
Распознавание изображений также используется для поиска похожих изображений, напоминающих шаблон. Это приложение можно найти в Google Reverse Image Search. Несколько тестов дают более или менее убедительные результаты. Это показывает, что уровень производительности все еще имеет место для улучшения. Результат распознавания изображений Microsoft тоже не очень убедительный. Фотография с шваброй для уборки перед желтым ведром была оценена следующим образом: "Я не совсем уверен, но думаю, что это крупный план торта" (ср. Voss, 2017). Это поднимает вопрос о том, насколько мы можем доверять распознаванию изображений в беспилотных автомобилях, если такие ошибки все еще случаются сегодня. И: Они не единственные.
Как могут происходить такие вопиющие ошибочные распознавания? Это довольно просто: используемые сегодня алгоритмы обучаются на сотнях тысяч изображений, на которых показаны различные объекты, и к ним прилагаются соответствующие описания. Однако системы не понимают "значения" объекта на фотографии как такового, а фокусируются на чистом распознавании образов. Вот почему системам ИИ трудно отличить стол от стула. Если стол лежит вверх ногами на столешнице, это становится еще сложнее.
Почти неразрешимая задача показана на рис. 1.11. Для системы ИИ (пока еще) невозможно отличить чихуахуа от маффина. Человеческий интеллект, с другой стороны, может очень просто отличить живое существо от выпечки, потому что человеческий интеллект распознает нечто большее, чем просто схематичные закономерности на изображениях.
Ящик памяти
Ограничения распознавания изображений в системах ИИ (по-прежнему) определяются тем, что сравниваются только визуальные закономерности. Смысл, стоящий за закономерностями, остается (по крайней мере на данный момент) скрытым от систем.
Наше мышление и наш естественный интеллект также основаны на том факте, что мы можем распознать сущность вещи и отличить ее от ее поверхности. Наше восприятие, следовательно, выходит за рамки поверхностного впечатления, потому что мы ассоциируем дальнейшее содержание с визуальным впечатлением (ср. Hofstadter, 2018, с. N 4).
Вот простой пример: если мы видим пару трусов, вырезанных из дерева, мы вполне естественно понимаем, что это негодная для носки вещь — из-за отсутствия комфорта. Мы скорее увидим это как скульптуру. Система ИИ легко распознает — "деревянные трусы".
Причина этого проста: Алгоритмы подходят к таким задачам иначе, чем люди, потому что им не хватает "модели мира" как общего пула опыта. Чего системам ИИ (пока еще) не хватает, так это осознания тела и интуитивного понимания физики. Мы, люди, этому учимся в ходе социализации "по ходу". Поэтому нам часто нужен всего лишь один контакт с объектом (один сеанс обучения), чтобы безопасно распознать животное. Интуитивно мы сравниваем новый объект с нашим первым опытом: тело с четырьмя ногами, мехом и мордой? Это должно быть животное! Легко для нас, но все еще крайне сложно для систем ИИ (ср. Wolfangel, 2018, с. 33).
Ящик памяти
Системам ИИ сегодня все еще не хватает способности создавать символ более высокого уровня (ср. Malsburg, 2018, с. 11). Такой символ более высокого уровня — это, например, образ, который создается в нас, когда мы думаем о воскресном пасхальном утре. Этот образ состоит из множества сохраненных воспоминаний:

Рисунок 1.11 Собака или маффин? (Рисунок авторов)
• Опыт (бесплодный поиск пасхальных яиц в саду)
• Картинки (красиво сервированный завтрак с нарциссами)
• Запахи (прекрасный жареный ягненок)
• Вкусы (например, разноцветные сахарные яйца)
• Звуки (звон городского собора)
• Чувства (при касании пасхального зайца Steiff)
• Настроения (как в чтении пасхальной прогулки Гёте "Освобожденный ото льда...")
Сложность связывания этих очень разных впечатлений значения в запускающем слове "Пасха" не может быть достигнута ни одной системой ИИ сегодня! Мы, люди, можем это сделать — без всяких усилий!
Системы распознавания изображений также используются в других областях, например, для контроля доступа для сотрудников в компаниях. Китайская интернет-компания Cheetah Mobile уже некоторое время использует такую систему распознавания лиц (см. рис. 1.12).
Уже упомянутый самый ценный стартап в области ИИ в мире — китайская компания Sensetime — установила камеры по всему зданию для демонстрационных целей. Они позволяют непрерывно наблюдать за посетителями. Дополнительные данные также могут быть введены сюда, чтобы более точно описать людей.

Рисунок 1.12 Распознавание лиц при контроле доступа в Cheetah Mobile, Пекин (Рисунок авторов)
Совет по художественному чтению
Тот, кто хотел бы увлекательно увидеть, какие последствия связаны с всесторонней видеозаписью для каждого человека и общества в целом, должен прочитать книгу Дэйва Эггерта "Круг", которая очень стоит того, чтобы ее прочитать. Фильм с тем же названием с Эммой Уотсон тоже хорош; но книга, по нашему мнению, лучше.
Переход к оценке видеозаписей плавен — это область применения, которая также активно продвигается в Китае. Это не просто вопрос различения пешеходов от велосипедистов и транспортных средств. Определенная цель — дальнейшее развитие распознавания видеоизображений для содействия предотвращению преступлений (например, через предиктивное патрулирование) и поддержки записи преступлений с помощью интеллектуального анализа данных в реальном времени (ср. разд. 9.1).
1.3.3 Экспертные системы
Экспертные системы — это компьютерные программы, которые помогают людям решать сложные проблемы — как человеческий эксперт (ср. рис. 1.6). Для этого программы выводят точные рекомендации для действий на основе данной базы знаний. Для этого системы должны получать множество информации. Сначала основу составляют правила "если-то", с помощью которых человеческие знания становятся понятными для компьютеров. Благодаря использованию Искусственного Интеллекта, экспертные системы, используемые на протяжении многих десятилетий, могли быть решительно развиты. В ближайшие несколько лет мы увидим здесь очень большие скачки в развитии.
Нам следует различать следующие компоненты экспертных систем:
• Компонент приобретения знаний
Этот компонент включает построение и расширение базы знаний для принятия решений на основе данной базы данных. Задача состоит в том, чтобы "подключиться" к потокам данных из больших данных и предоставлять только релевантную информацию для поддержки принятия решений. Интересная задача для приобретения знаний — это вывод образовательного статуса пользователей, склонных к социальным сетям, на основе сообщений в социальных сетях.
• Компонент разработки решений проблем
Ориентированная на решение оценка базы знаний может использовать различные подходы. С одной стороны, это развитие будущего, прогнозируемое на основе доступных данных. Здесь мы говорим о передаче данных или подходе с прямым цепным выводом. Эта концепция применяется робо-консультантами в финансовом секторе. С другой стороны, можно "пересчитать" выявленный этап развития, чтобы распознать, что послужило его причинами. В этом подходе, вызванном событием или обратно связанном, могут быть сформированы гипотезы о ходе уже завершенных процессов (например, в случае глобального потепления). На основе полученных таким образом знаний могут быть сгенерированы решения и рекомендации по принятию решений (например, в отношении степени "приемлемого" глобального потепления).
• Компонент коммуникации решений
Решающим компонентом экспертной системы является "выходная функция". Речь идет об объяснении решений, найденных системой, пользователю. Качество этого объяснения является важным критерием принятия предложенных решений, потому что люди не решаются следовать непонятной рекомендации (ср. Объяснимый Искусственный Интеллект, раздел 1.1). В примере с глобальным потеплением задача состоит в подготовке результатов таким образом, чтобы они могли быть поняты заинтересованными лицами.
Легко понять, почему такие экспертные системы так важны в контексте Искусственного Интеллекта. Системы с поддержкой ИИ могут — на основе определенной исходной совокупности знаний — самостоятельно изучать новые вещи и таким образом расширять человеческий горизонт знаний. Эти дополнительные знания могут быть непосредственно доступны людям через экспертные системы. Предлагая определенные рекомендации людям, они могут применять их непосредственно. Полученные знания также могут быть доступны косвенно. Тогда знания, полученные через экспертные системы — без вмешательства человека — вливаются в текущие процессы. Примеры контроля качества мы находим в производственных процессах (ср. глава 3) или в логистике (ср. раздел 7.4). Экспертные системы также используются для оценки рентгеновских снимков и КТ-изображений (ср. раздел 6.1). Мы находим экспертные системы также в беспилотных автомобилях (ср. раздел 7.4).
Экспертные системы также применяются в творческих процессах. Для этого, соответствующим образом настроенные системы могут анализировать все симфонии Бетховена. На основе таким образом полученных знаний о композиционных подходах может быть сочинена 10-я симфония Бетховена, которая на самом деле звучит как Бетховен. Не фантастика — но (неминуемая) реальность (ср. раздел 8.2).
В будущем доступ к мощным экспертным системам станет все более возможным для "обычных" пользователей. Здесь используются так называемые (цифровые) технологии самообслуживания (SST). Простейшее применение такого рода лежит в основе каждого поискового запроса Google. Средства перевода из DeepL, Google Translate, Skype & Co. также используют соответствующие экспертные системы для перевода текста в текст и речи в речь в реальном времени.
Пища для размышлений
Слишком часто мы принимаем лишь достаточно хорошие решения в нашей повседневной жизни и рабочей среде (ср. Agrawal et al., 2018, с. 110). Почему в аэропорту огромные залы ожидания? Нужно предоставить путешественникам место для ожидания. Причина их ожидания — информационный пробел. Его нужно компенсировать временным буфером для каждого отдельного путешественника. Из-за недостаточной связи различной информации, своевременное путешествие сегодня невозможно. Нам не хватает информации о следующих аспектах:
• Доступность такси в пункте отправления
• Состояние дорожного движения на подъездных дорогах (для вашего собственного автомобиля, такси или автобуса)
• Степень непунктуальности и ненадежности железнодорожных компаний
• Условия парковки в аэропорту
• Кратчайшие маршруты на территории аэропорта при путешествии
• Длина очередей на выдаче багажа и досмотр безопасности
• Фактическое время посадки забронированного рейса
Вот почему нам приходится планировать буферное время, если мы не хотим опоздать на рейс. Возможно, через четыре или пять лет автономный автомобиль будет забирать нас в максимально возможное время и доставлять в аэропорт, не опаздывая на рейс — без всякого стресса! Для этого необходимо связать соответствующие информационные потоки в экспертную систему по транспорту. Следовательно, системы ИИ, надеюсь, будут вынуждены принимать все меньше и меньше достаточно хороших решений в будущем на основе неадекватной базы данных.
1.3.4 Робототехника/Роботы
Термин робот описывает техническое оборудование, которое используется людьми для выполнения работы или других задач — обычно механической работы (ср. рис. 1.6). Мы можем различать следующие типы роботов, при этом разделение между отдельными категориями не всегда легко.
Классификация роботов по областям применения:
• Промышленные роботы (например, в автомобильной промышленности)
• Медицинские роботы (например, для выполнения операций)
• Сервисные роботы
– Бизнес-задачи (включая регистрацию в отелях и аэропортах)
– Личное использование (например, вакуум, мытье окон, прополка или роботы-газонокосилки)
• Исследовательские и военные роботы (например, для обнаружения поверхности Марса или обезвреживания мин и неразорвавшихся боеприпасов; также используются как дроны)
• Игрушечные роботы (например, Vernie, робот Lego, Thinkerbot или Cozmo)
• Навигационные роботы (например, для автономного вождения)
Классификация роботов по степени мобильности:
• Стационарные роботы (интегрированы в производственные линии, например, в автомобильном производстве)
• Мобильные роботы (например, для логистических процессов, связанных с доставкой дронами или для самоконтролируемого использования в качестве роботов-газонокосилок)
Классификация роботов по степени их взаимодействия с людьми:
• Классические роботы (работают независимо от человека; часто находятся в огороженных зонах, чтобы не причинить вреда людям)
• Коботы/коллаборативные роботы (могут работать с людьми "рука об руку", потому что роботы распознают людей и действуют соответственно "осторожно")
Классификация роботов по степени их "человеческого облика":
• Роботы-машины (выглядят и действуют как машины)
• Гуманоидные роботы (выглядят как люди и все больше приближаются к людям в своем поведении)
Пища для размышлений
В последние годы моторика роботов уже значительно улучшилась. Тем не менее, вероятно, пройдут десятилетия, прежде чем роботы смогут самостоятельно выгружать посудомоечную машину и правильно расставлять очищенные предметы в шкафах. Если вообще!
Основные компоненты роботов сопоставимы в различных проявлениях и имеют следующую структуру:
• Датчики для обнаружения окружающей среды
Роботы оснащены различными датчиками, с помощью которых они могут обнаруживать свою окружающую среду. Окружающая среда может меняться, и робот воспринимает это соответствующим образом. Это восприятие может быть применено к следующей обрабатываемой детали или к падению давления на турбине "13". Датчики могут помочь обнаружить и интерпретировать движения, например, для взаимодействия с людьми. Наконец, разговорный язык может давать прямые инструкции роботу.
• Набор функций
В зависимости от степени сложности робота, он может выполнять только "жестко запрограммированные" функции (например, установка 24 сварочных точек или покраска кузова автомобиля). Или робот оснащен машинным обучением и может учиться самостоятельно, чтобы еще больше повысить эффективность своего использования.
• Компоненты движения
Простые промышленные роботы жестко закреплены и отделены от человека клеткой, потому что роботы могут не распознавать людей и могут причинить им вред. Дальнейшее развитие роботов (например, в логистике) позволяет им самостоятельно перемещаться по складам, подниматься по лестнице и при необходимости избегать препятствий.
• Взаимодействие с окружающей средой
Для взаимодействия с окружающей средой могут быть доступны захваты и подобные устройства для выполнения запрограммированных функций. Кроме того, для взаимодействия с роботом требуется интерфейс, чтобы сделать его задачи и другие данные доступными для него. Это может быть достигнуто классическим способом через коды программ, через визуальный интерфейс (робот распознает и учится через "прожитые" последовательности движений) или через слуховой интерфейс (команда: "Запроси следующую заготовку!").
На протяжении многих лет роботы могли использовать ряд преимуществ перед людьми. В первую очередь это:
• Сила
• Настойчивость (без стремления к концу рабочего дня или к отпуску)
• Точность
• Скорость
• Непоколебимость (например, из-за колебаний чувств или отвлечений любого рода)
• Более низкая почасовая оплата (включая все расходы на обслуживание) — и отсутствие представительства профсоюзами
Теперь мы можем добавить к этому списку существенный компонент, который массово увеличит проникновение роботов в ближайшие годы: Искусственный Интеллект.
Ящик памяти
Благодаря Искусственному Интеллекту у роботов появляется очень важное дополнительное преимущество: интеллект! Возникающие дополнительные области применения кардинально изменят мир!
Теперь мы подробнее рассмотрим гуманоидных роботов, упомянутых выше. В ходе развития этих роботов пришлось преодолеть и приходится преодолевать множество технических проблем. Искусственный Интеллект внес большой вклад в это. Гуманоидные роботы должны взаимодействовать автономно со своей окружающей средой и самостоятельно перемещаться. Используются либо ноги, либо платформа с колесами. Роботы приобретают человеческое сходство благодаря искусственным рукам и кистям рук и человекоподобному лицу (ср. рис. 1.13).

Рисунок 1.13 Общение с гуманоидным роботом по имени Pepper (Рисунок авторов)
«Ласковая» форма такого гуманоидного робота, как Pepper, далеко не конец развития этого типа роботов. Еще один называется Sophia от Hanson Robotics и является мощным примером того, насколько похожим может быть гуманоид в 2016 году. Она действительно выглядит как женщина и также способна выражать разные эмоции во время разговора. Здесь видно, какого этапа развития уже достигнуто. Мы больше не можем говорить только о «человекоподобном» лице. До сих пор гуманоидные роботы, такие как Pepper, намеренно изображались милыми, чтобы не пугать людей и предотвратить страх замещения. Это время прошло.
Что возможно сейчас? Мы можем связать человеческий облик Sophia с знаниями IBM Watson. Кроме того, роботы будут оснащены человекоподобным восприятием (например, также настроений, жестов и выражений лица) и поведенческими паттернами. Результатом будет человеческая копия с гигантскими возможностями обучения и производительности компьютера. Загружая данные из облака, такой робот сможет каждый день изучать новые языки, получать последние научные открытия и другие новые «трюки» в свое распоряжение — в реальном времени!
Как сегодня обстоят дела с роботами — и в каком направлении следует двигаться дальше? Исследование Capgemini (2018) в Германии дало ответ на интересный вопрос о том, насколько «похожими» должны стать роботы на людей:
• 64% респондентов поддерживают человекоподобные системы, использующие Искусственный Интеллект.
• 52% считают Искусственный Интеллект с физическими человеческими характеристиками «жутким».
• 71% принимают его в сфере услуг, если от человекоподобной физиономии отказываются.
• В то же время 62% респондентов оценили человеческий голос и интеллектуальное поведение как позитивное.
• Позитивную оценку 52% также дали, если робот может распознавать эмоции.
Ящик памяти
Люди в Германии хотят, чтобы роботы говорили как люди, вели себя как люди и могли распознавать эмоции. Но они не должны выглядеть как настоящие люди — пока!
В этом контексте мы говорим о зловещей долине. Это также относится к «жуткой лощине», которая описывает разрыв в принятии для «человеческих» роботов. Если роботы становятся более похожими на людей, принятие сначала возрастает. Но в определенный момент эти роботы становятся неудобными для людей. Именно здесь начинается зловещая долина!
Несмотря на всю эйфорию по поводу успехов на пути к еще более мощным роботам с поддержкой ИИ, следующая маленькая история должна дать нам пищу для размышлений. На самом деле, охранный робот Knightscope должен был патрулировать набережную Джорджтауна, элегантный торговый и офисный комплекс в Вашингтонской гавани. Чтобы поддерживать здесь порядок, катящийся робот мог поворачивать, гудеть и свистеть. Однако, кажется, давление на него стало слишком сильным. Чтобы предотвратить лозунг «Входи и сгори», робот самостоятельно заехал в колодец и утонул (ср. Swearingen, 2017).
Печальный конец, потому что такой робот-охранник — это на самом деле ценный бизнес для дешевого мониторинга мест. Обычно робот-охранник ездит по торговым центрам и парковкам — по арендной цене, которая на 25 центов ниже федеральной минимальной заработной платы в США (7 долларов США в час). Сообщалось о случаях, когда таких роботов сбивали и опрокидывали пьяные. Кроме того, маленького ребенка переехали. Это уже не выглядит очень безопасно. В то же время свободная смерть робота, описанная выше, становится понятной!
Даже автономно управляемый автомобиль — это сложный робот в своей основе, который получает доступ к множеству функций Искусственного Интеллекта. Сначала несколько камер записывают окружающую среду транспортного средства. Полученные изображения оцениваются и используются для принятия решений — все в реальном времени. Если обнаружен красный светофор, имеющий отношение к своей полосе движения, автомобиль останавливается — на основе дальнейшей информации об окружающей среде (например, какие автомобили также тормозят, какие следуют). Если ограничение скорости определено как релевантное для направления движения транспортного средства, автомобиль автоматически тормозит до этой целевой скорости, если ранее двигался быстрее. Поскольку — как уже указывалось — человеческие жизни могут быть непосредственно затронуты здесь, как показали несколько смертей в связи с использованием автономных транспортных средств, необходимо учитывать особенно высокие стандарты безопасности.
Особенно восприятие окружающей среды всегда было большой проблемой для роботов. Первые модели роботов в 70-х годах (такие как ELIZA) были запрограммированы на распознавание стены в комнате. Сегодня, однако, на карту поставлено гораздо больше. Робот должен быть способен не только находить здание, но и наносить его на карту. Эта задача называется одновременной локализацией и картографированием (SLAM). Это способность, которую люди осваивают еще в младенчестве:
• Где дверь?
• В какую комнату мне нужно пройти, чтобы попасть в ванную?
• Где находятся какие объекты в комнате?
Прорыв в этой области уже был достигнут в ноябре 2010 года, когда Microsoft выпустила сенсорное устройство Kinect в качестве дополнения к игровой платформе xBox. Здесь стало возможным захватывать двух игроков в комнате и интерпретировать их движения, даже если один игрок был скрыт другим. В июне 2011 года Microsoft предоставила комплект разработки программного обеспечения (SDK) для Kinect. Это сделало это приложение пригодным для исследований SLAM (ср. Brynjolfsson & McAfee, 2014, с. 68–71).
До сих пор не удалось разработать полный подход SLAM. Для роботов-газонокосилок сад по-прежнему нуждается в оснащении датчиками, которые задают машине границу, чтобы она не стригла цветочные клумбы. Тем не менее, самоходные автомобили показывают огромный прогресс, который постоянно достигается здесь.
Интересной областью для технологий ИИ являются услуги в гостиничном секторе. Японский отель Henn na Hotel, открывшийся в 2016 году, показал, куда может вести путь. Это название можно перевести как "странный отель". Весь отель недалеко от Нагасаки управляется роботами. Сначала гостей встречает Nao, маленький робот, который информирует об отеле и его "слугах". Регистрацию осуществляют роботы-ресепционисты, которые лишь частично напоминают людей, но также похожи на динозавра.
После ввода имени камера записывает лицо. Эта запись затем используется в качестве ключа через систему распознавания лиц на двери номера. Багаж перевозится мобильным роботом, который также обеспечивает "необходимую" фоновую музыку. Персональный помощник Чу-ри-тян управляет светом, температурой, будильником и т.д. в самом номере посредством голосового управления. Гости могут заказывать закуски через планшет — доставка осуществляется дроном!
Ящик памяти
Использование сервисных роботов во все большем количестве областей человеческой жизни уже предсказуемо сегодня. Технические границы часто преодолеваются легче, чем культурные. В то время как в США, но прежде всего в Китае, Японии и Южной Корее, широкая публика очень открыта инновациям, соответствующим им, их использование в Европе и Германии часто встречает большое сопротивление и страх. Это необходимо учитывать при разработке сервисных стратегий на основе роботов.
Пища для размышлений
Возможно, скоро мы будем говорить о поколении R или поколении роботиков, роботических аборигенов. Члены этого поколения будут так же естественно относиться к роботам, как сегодня дети к смартфонам и Интернету.
Резюме
• Области применения Искусственного Интеллекта тесно взаимосвязаны.
• Важной областью применения Искусственного Интеллекта является обработка естественного языка. Он позволяет новые формы общения между человеком и машиной.
• Способность обрабатывать изображения позволяет системам информационных технологий брать на себя новые задачи. Это позволяет машинам и людям работать рука об руку.
• Наличие всеобъемлющих знаний через экспертные системы дает шанс — в зависимости от лежащих в основе данных — принимать лучшие решения. Здесь необходимо проверить, на каких предпосылках и ценностях основаны решения.
• Интеллектуальные роботы часто используют несколько или все области Искусственного Интеллекта одновременно. Они могут слышать и видеть "естественно", принимать обоснованные решения и самостоятельно их выполнять. В целом, они окажут наибольшее влияние на компании, экономики и общества.
1.4 Каковы глобальные экономические эффекты Искусственного Интеллекта?
Исследование McKinsey (2018a) показывает глобальные экономические эффекты ИИ, которые будут сопровождать использование Искусственного Интеллекта. Первоначально прогнозируется, что к 2030 году около 70% всех компаний внедрят по крайней мере один тип технологии ИИ. Менее половины всех крупных предприятий будут использовать полный спектр технологий ИИ.
Ящик памяти
Если исключить конкурентные эффекты и переходные издержки, Искусственный Интеллект может обеспечить дополнительный экономический эффект в размере около 13 триллионов долларов США к 2030 году. Это увеличит мировой валовой национальный продукт примерно на 1,2% в год (ср. McKinsey, 2018a, с. 2f.).
Даже если этот прогноз слишком оптимистичен. Мы все должны понимать это как вызов интенсивно заниматься возможностями Искусственного Интеллекта — скорее раньше, чем позже!
Важно отметить, что экономическое влияние использования ИИ изначально будет медленным и ускорится только в ближайшие годы. Таким образом, ожидаемое использование Искусственного Интеллекта компаниями показано на графике, документированном на рис. 1.14: Прежде всего, будет осторожный старт из-за необходимых инвестиций, связанных с обучением и использованием технологий (ср. глава 10). Затем начнется ускорение, обусловленное возрастающей конкуренцией и увеличением собственных компетенций, связанных с ИИ, в компаниях. Следовательно, вклад Искусственного Интеллекта в рост к 2030 году может быть в три или более раз выше, чем в ближайшие пять лет. Относительно высокие первоначальные инвестиции в персонал и системы, непрерывное дальнейшее развитие технологий и приложений, а также значительные переходные издержки, связанные с использованием систем ИИ, могут ограничить их принятие малыми предприятиями и одновременно снизить чистый эффект от общего использования ИИ (ср. McKinsey, 2018a, с. 3).
Глобальная проблема заключается в том, что внедрение Искусственного Интеллекта может увеличить существующие различия между странами, компаниями и работниками. Прежде всего, возрастет разница в производительности между странами. Те — в основном развитые — экономики, которые станут лидерами в области ИИ, смогут добиться дополнительного экономического преимущества в 20–25% по сравнению с сегодняшним днем. С другой стороны, развивающиеся экономики смогут использовать только около 5–15% этих преимуществ. Фон этого в том, что обе группы стран (здесь лидеры в области ИИ, там развивающиеся страны) нуждаются в разных стратегиях для достижения признания Искусственного Интеллекта в обществе и экономике (ср. McKinsey, 2018a, с. 3).

Рисунок 1.14 Совокупное развитие экономических эффектов Искусственного Интеллекта — сравнение с сегодняшним днем. Источник: McKinsey (2018a, с. 23)
Многие индустриально развитые страны неизбежно должны будут полагаться на Искусственный Интеллект для достижения более высокого роста производительности. В конце концов, темпы роста во многих из этих стран замедляются. Это не в последнюю очередь связано со старением населения и высокой степенью насыщенности рынков. Кроме того, заработная плата в индустриально развитых странах относительно высока, что усиливает необходимость замены труда машинами. Развивающиеся страны, как правило, имеют другие способы повышения производительности. Это включает внедрение передовых методов в производственной деятельности — а также реструктуризацию их промышленности. Вот почему здесь отсутствуют важные стимулы для более широкого использования ИИ. Однако это не обязательно означает, что развивающиеся страны обречены проиграть гонку в области ИИ (ср. McKinsey, 2018a, с. 3f.).
Давайте взглянем на отдельные регионы. Некоторые развивающиеся страны — прежде всего Китай — продвигают использование ИИ в строго устойчивой манере. Анализ ситуации в Китае должен учитывать следующие моменты. Принадлежность к группе развивающихся стран основана на валовом внутреннем продукте на душу населения; после этого Китай все еще является развивающейся страной. В то же время, однако, Китай также является второй по величине экономикой в мире после США и перед Японией! Кроме того, сегодня Китай имеет самый ценный стартап в области ИИ в мире. Компания Sensetime уже имеет рыночную капитализацию в размере 2,8 миллиарда долларов США (ср. Ankenbrand, 2018; Sensetime, 2018). В презентациях китайских компаний заметно, что они часто ставят Искусственный Интеллект в центр 4-й промышленной революции — в дополнение к появлению киберфизических систем (ср. Kreutzer, 2018; Kreutzer & Land, 2016, с. 3). Не случайно, что генеральный директор китайской компании Cheetah Mobile Шэн Фу сформулировал миссию своей компании следующим образом (Cheetah Mobile, 2018):
Искусственный Интеллект меняет всю индустрию, а также весь наш образ мышления. Поэтому мы будем использовать ИИ для достижения новой миссии Cheetah на ближайшие 10 лет — сделать мир умнее.
Поэтому Китай определил Искусственный Интеллект как целевую отрасль на национальном уровне в мастер-плане "Сделано в Китае 2025". К 2030 году Китай хочет стать не просто глобальным инновационным центром в области Искусственного Интеллекта. Китайская индустрия ИИ тогда будет иметь стоимость примерно 150 миллиардов долларов США — а индустрия с поддержкой ИИ в десять раз больше. Для достижения этой цели Sensetime разработала собственную платформу глубокого обучения Parrots. Ее можно охарактеризовать следующими атрибутами (ср. Sensetime, 2018, с. 9, 17–20; также Lee, 2018):
• Сверхглубокая сеть (1207 сетевых слоев)
• Мегаобучение данным (включая одновременное обучение на двух миллиардах изображений лиц; доступно более десяти миллиардов изображений и видео из 18 отраслей)
• Сложное сетевое обучение (поддержка мультимодального обучения)
Исследование Elsevier (2018, с. 9) показывает, что Китай уже лидирует по количеству публикаций по Искусственному Интеллекту с 2013 по 2018 год — значительно опережая США и все остальные страны. Кстати, Индия здесь занимает 3-е место — далеко впереди Великобритании, Японии и Германии.
Европа только что (с зрячим глазом) отказалась от ведущей роли в области Искусственного Интеллекта в будущем и тем самым от достижения стратегических конкурентных преимуществ. Европейское общее положение о защите данных (GDPR), вступившее в силу в 2018 году, делает все более сложным для европейских компаний доступ к релевантным данным для развития Искусственного Интеллекта. Это простое уравнение:
Нет всеобъемлющих баз данных = нет высокопроизводительных систем ИИ
В отличие от Китая, Европа попыталась защитить конфиденциальность частных лиц в цифровом мире. Однако сомнительно, действительно ли новое GDPR способно достичь этого. Созданная правовая база превратилась в бюрократического монстра, который душит креативность и поглощает бюджеты, которые могли бы быть использованы для создания большей ценности с помощью цифровой трансформации и использования ИИ.
Ящик памяти
На этом фоне становится понятным, почему сегодня только американские и китайские компании доминируют в разработке приложений ИИ. Это так называемые компании GAFA (Google/Alphabet, Apple, Facebook и Amazon), а также IBM и Microsoft. Именно поэтому более точно они называются компаниями GAFAMI. Facebook даже сам разрабатывает компьютерные чипы для ИИ. Китайские аналоги Baidu, Ali-baba и Tencent объединяются под термином BAT-компании.
Пища для размышлений
Дебаты вокруг Facebook Cambridge Analytica в последний раз подтвердили то, что мы знали давно: наши данные систематически злоупотребляются. К сожалению, текущий GDPR не предотвращает такие злоупотребления. Напротив, даже небольшие ремесленные предприятия, средние предприятия и стартапы теперь вынуждены преодолевать всеобъемлющие бюрократические трудности, чтобы не быть атакованными отраслью предупреждающих уведомлений. Это может быстро поставить такие компании на грань существования, как регулярно показывают сообщения в ежедневной прессе. Действительно ли это желаемый прогресс для нашего общества? Конечно, нет!
С одной стороны, стоит признать, что Европа хочет защитить права частных лиц. Однако в его текущей форме GDPR превышает цель. Европейские компании стремятся учесть новые требования, определенные там. В значительной степени незатронутые этим, мега-игроки Amazon, Facebook, Google & Co. просто получают разрешение на дальнейшее использование данных. Люди обычно дают эти — уже раздраженные — неохотно, не прочитав новые правила (часто десятки страниц). В конце концов, мы хотим продолжить наш поиск в Google — и мы не хотим, чтобы нас отвлекали. Таким образом, осьминоги данных продолжат расти — и менее доминирующие компании продолжат терять данные и, соответственно, власть, влияние и конкурентоспособность.
Европа хочет стать публично "прозрачным" народом, как в Китае? Конечно, нет! Какие экономические варианты существуют для компаний в Европе для разработки собственных решений ИИ? Если Европа не сможет найти ответственный подход к обработке данных, которые являются
основой любой технологии ИИ, им придется смириться с тем, что китайские компании будут доминировать со своими решениями в обозримом будущем. Китайские компании Alibaba, Baidu и Tencent активно продвигают свои решения ИИ. Возможно, они еще более мощные, потому что в процессе разработки удалось использовать обширные базы данных. Если эти решения убедят пользователей, у нас появятся новые — в данном случае — китайские мегаигроки на мировом рынке!
Поэтому важно достичь баланса в Европе между приватностью и предпринимательскими интересами и фундаментально переосмыслить GDPR.
Государства-члены Европейского Союза (ЕС) объявили о своем намерении усилить трансграничную деятельность в области ИИ. Это направлено на обеспечение того, чтобы Европа оставалась или становилась конкурентоспособной в этих технологиях. В то же время необходимо совместно освоить социальные, экономические, этические и правовые последствия Искусственного Интеллекта. ЕС требует, чтобы к 2020 году на исследования ИИ было инвестировано 24 миллиарда долларов США. Ряд европейских стран также способствовали национальным инициативам в области образования и исследований с целью продвижения собственной деятельности в области ИИ (ср. McKinsey, 2018a, с. 7). Предстоит еще увидеть, какие плоды принесет этот подход.
Какое место занимают США в области Искусственного Интеллекта? Компании Alphabet, Amazon, Apple, Facebook, IBM и Microsoft особенно активны в этой области и стараются интегрировать полученные знания в существующие и будущие продукты и услуги, а также разрабатывать новые бизнес-модели. Поскольку Европа до сих пор не сильно проявила себя в конкурентной борьбе за лидерство в разработке ИИ, использование Искусственного Интеллекта, вероятно, останется американско-китайской дуополией. Возможно, Китай даже выиграет эту конкуренцию, поскольку — как показано выше — там доступны огромные объемы данных для обучения систем. Как прекрасно сказал мастер ИИ Фред Елинек?
"Нет данных, как нет больше данных."
Действительно, разрыв в данных между США и Китаем огромен. Его нельзя объяснить только разным размером населения. Количество доступных данных на душу населения в Китае просто во много раз выше — и их число продолжает неуклонно расти (ср. Armbruster, 2017).
Ящик памяти
Области применения Искусственного Интеллекта не спрашивают, на какой основе были разработаны эти системы! Для успеха на мировом рынке это (к сожалению) лишь вопрос того, кто владеет более мощными системами. У Европы в настоящее время плохие карты, и США и Китай берут на себя ведущую роль.
Какую роль будет играть Россия в вызове ИИ? Благодаря сильному Искусственному Интеллекту должна быть достигнута максимальная автономия, которая выходит далеко за рамки простого имитации человеческого интеллекта. Речь идет не столько о том, будет ли когда-либо достигнут этот этап, сколько о "когда". Россия вступила в эру ИИ в 2012 году с амбициозными целями (ср. 2045 Strategic Social Initiative, 2012):
• В период с 2015 по 2020 годы они планировали разработать Аватар А как роботизированную копию человеческого тела, управляемую удаленно через интерфейс мозг-компьютер.
• На период 2020–2025 годов Россия намеревалась разработать Аватар Б, в котором человеческий мозг будет пересажен в конце жизни.
• В период с 2030 по 2035 годы должен быть разработан Аватар С с искусственным мозгом, в который в конце жизни будет перенесена человеческая личность.
• В период 2040–2045 годов должен существовать голограммный Аватар Д. Это были цели.
До сих пор Россия была обязана нам представить убедительные решения в области Искусственного Интеллекта.
McKinsey (2018a) предоставляет глубокий анализ относительной конкурентной позиции разных стран. В то время как США и Китай лидируют в гонке, Германия находится в середине. Страны, такие как Сингапур, Великобритания, Нидерланды и Швеция, гораздо лучше позиционированы в этом отношении. Удивительное явление заключается в том, что разрыв в использовании ИИ между странами имеет тенденцию увеличиваться с годами (ср. McKinsey, 2018a, с. 35). Как уже упоминалось, внедрение и принятие технологий ИИ может дать мощный импульс медленно растущим индустриальным странам. Рисунок 1.15 показывает, что дополнительный рост, поддерживаемый ИИ, в некоторых развитых странах (таких как Швеция, Южная Корея, Великобритания и США) сам по себе может стать таким же большим, как прогнозируемый сегодня рост.
Рисунок 1.15 Дополнительный вклад Искусственного Интеллекта в рост на уровне страны. Источник McKinsey (2018a, с. 36)
Технологии ИИ могут привести к разрыву в производительности на уровне компаний между лидерами, с одной стороны, и медленными пользователями и не-пользователями, с другой (ср. McKinsey, 2018a, с. 4). Среди лидеров в области ИИ есть компании, которые полностью интегрируют инструменты ИИ в свои цепочки создания стоимости в течение следующих пяти-семи лет. Они получат непропорционально большую выгоду от использования ИИ. Они потенциально могут удвоить свой денежный поток к 2030 году. Это будет означать дополнительный ежегодный прирост чистого денежного потока около 6% на протяжении более десяти лет. Лидеры в области ИИ обычно имеют сильную цифровую базу, более высокую склонность к инвестициям и захватывающие бизнес-кейсы для использования Искусственного Интеллекта. Лидеры в области ИИ сталкиваются с большим количеством отстающих, которые вообще не будут использовать технологии ИИ или не примут их полностью к 2030 году. Эта группа может столкнуться с сокращением денежного потока на 20% по сравнению с сегодняшним уровнем. Предполагается, что будет использоваться та же структура затрат и сопоставимые бизнес-возможности.
Такое расхождение в развитии может также произойти на уровне сотрудников. Спрос на рабочие места может сместиться с рабочих мест с повторяющимися задачами на социально и когнитивно требовательные задачи. Профили рабочих мест, характеризующиеся повторяющимися действиями и/или требующие только низких цифровых навыков, могут испытать наибольшее снижение доли в общей занятости: Доля этих задач может сократиться с примерно 40% до почти 30% к 2030 году. С другой стороны, спрос возрастет на работников, выполняющих неповторяющиеся задачи и требующих высоких цифровых навыков. Их доля может увеличиться с примерно 40% до более 50% в течение этого периода. Это может усилить войну за таланты в отношении людей, обладающих способностями разрабатывать и использовать системы Искусственного Интеллекта (ср. McKinsey, 2018a, с. 4).
Однако прогнозы относительно влияния использования ИИ на занятость неоднородны. Исследования OECD предполагают, что на рынке труда может произойти поляризация. Помимо спроса на высококвалифицированных специалистов, описанного выше, может также возрасти спрос на низкоквалифицированных работников. Как говорится: "В конце концов, кто-то должен убирать квартиру цифровых сотрудников так же, подавать еду и наливать кофе в чашку" (ср. Bollmann, 2018, с. 136). В результате в первую очередь будут потеряны рабочие места с профилем средней квалификации. Такое развитие уже наблюдается в Германии в последние два десятилетия (ср. Bollmann, 2018, с. 135).
Пища для размышлений
Эффекты, которые произойдут в индивидуальном случае, зависят от скорости и степени использования ИИ в отдельных компаниях и в экономике в целом. Если Искусственный Интеллект в первую очередь используется для повышения эффективности, значительный потенциал создания ценности новой технологии остается неиспользованным. Если, с другой стороны, компании все больше используют Искусственный Интеллект для инноваций в продуктах и услугах или для разработки новых бизнес-моделей, будут достигнуты гораздо более комплексные эффекты на экономические результаты.
McKinsey (2018a, с. 13–19) дополнительно исследовал различные области Искусственного Интеллекта. Результаты симуляции представлены ниже. Прежде всего, рост производительности, обусловленный ИИ, включая автоматизацию труда и инновации, и появление новых конкурентов
Рисунок 1.16 Анализ чистого экономического влияния Искусственного Интеллекта — разбивка экономического влияния на валовой внутренний продукт (совокупное увеличение по сравнению с сегодняшним днем в %). Источник McKinsey (2018a, с. 19)
под влиянием ряда факторов. Здесь проводится различие между микро- и макрофакторами. Первые три исследуемые области действий относятся к микрофакторам. Они анализируют влияние внедрения ИИ на факторы производства компаний. Здесь речь идет о скорости и степени внедрения ИИ в компаниях. Макрофакторы относятся к общему экономическому окружению и возрастающему использованию Искусственного Интеллекта в экономике в целом. Это также касается глобальной интеграции и структуры рынка труда отдельной страны (ср. рис. 1.16).
Ниже обсуждаются микрофакторы.
• Область деятельности 1: Расширение (Augmentation)
Исследования McKinsey за 2016–2017 годы показывают, что компании до сих пор инвестировали лишь 10–20% своих "цифровых" бюджетов в приложения ИИ; однако эта доля может увеличиться в будущем по мере развития приложений ИИ. Эти инвестиции в ИИ влияют на многие другие области, такие как ситуация с занятостью. В данном случае термин "расширение" относится к обогащению труда и капитала Искусственным Интеллектом. Возрастающее использование ИИ требует создания рабочих мест для настройки инфраструктуры ИИ и мониторинга ее работы, например, для инженеров и аналитиков больших данных.
Другие новые рабочие места сосредоточены на тестировании результатов ИИ "человеческими глазами". Только Google нанимает 10 000 "оценщиков", которые просматривают видео на YouTube, чтобы повторно исследовать критическое содержимое, идентифицированное Искусственным Интеллектом. Facebook также значительно увеличит количество "модераторов", необходимых для проверки содержимого с целью внедрения новых юридических требований. Таким образом, использование ИИ приводит к появлению новых рабочих мест.
Необходимость создания новых рабочих мест, основанных на ИИ, также обусловлена феноменом, заключающимся в том, что приложения ИИ, как правило, трудно обобщить. Алгоритм, который легко отличает людей от животных на фотографиях, не сможет обнаружить автомобили и грузовики. На пути к универсальному Искусственному Интеллекту (также называемому общим Искусственным Интеллектом) еще предстоит выполнить множество задач, которые должны выполнять люди. Как показано на рис. 1.16, общее экономическое влияние расширения находится на низком уровне. Совокупное увеличение валового внутреннего продукта всего на 1% к 2023 году и на 3% к 2030 году.
• Область деятельности 2: Замещение (Substitution)
Технологии, которые дают лучшие результаты и/или более высокую экономическую эффективность, имеют тенденцию замещать другие факторы производства. Это сопровождается замещением труда, особенно автоматизацией повторяющихся задач. К 2030 году автоматизация деятельности может заменить в среднем около 15–18% рабочего времени по всему миру. Степень, в которой это произойдет, будет зависеть от относительных затрат на необходимые ресурсы (ИИ) в каждом конкретном случае. Уже сегодня предсказуемо, что во многих профессиях определенные виды деятельности будут автоматизированы и/или замещены Искусственным Интеллектом. Это относится к колл-центрам, где многие задачи могут выполняться чат-ботами. Во многих других областях также видны эффекты замещения (ср. раздел 4.1.2).
Автоматизация труда может внести около 2% вклада в мировой ВВП к 2023 году и около 11% или около 9 триллионов долларов США к 2030 году (ср. рис. 1.16). Этот процесс достигается за счет повышения производительности и требует, чтобы высвободившийся труд мог быть использован в других областях экономики. На агрегированном уровне повышение производительности может привести к повышению экономической эффективности, создавая дополнительные рабочие места в других областях. Это может принести пользу экономике в целом, в то время как работники могут пострадать от процессов изменений, вызванных ИИ. В целом, описанное здесь "замещение" является одним из наиболее эффективных воздействий Искусственного Интеллекта.
• Область деятельности 3: Инновации и расширения продуктов и услуг (включая конкурентные эффекты)
Еще одна важная область исследований — инновации, основанные на ИИ или поддерживаемые ИИ. В то время как процессные инновации могут повысить производительность компании (ср. области деятельности 1 и 2), инновации в продуктах и услугах позволяют открывать новые области деятельности. Исследования McKinsey показывают, что около трети компаний инвестировали в Искусственный Интеллект для достижения таких инноваций. В отношении макроэкономических эффектов следует учитывать, что инновации также замещают существующие продукты и услуги. Следовательно, не вся ценность, которую компании получат от инноваций, является "новой" для экономики. Примером этого является Uber, который не только привлек новых клиентов для перевозки пассажиров, но и заменил классические поездки на такси. Платформы, такие как
Amazon и Airbnb не только генерировали новый бизнес, но и вытеснили традиционную розничную торговлю и гостиничный бизнес. Таким образом, большая часть инновационного потенциала Искусственного Интеллекта приведет к смещению производства между компаниями (ср. Kreutzer & Land, 2015 и 2016).
Рисунок 1.16 показывает, что инновации и дополнения продуктов и услуг окажут совокупное влияние на ВВП в размере 24% к 2030 году. Напротив, совокупные конкурентные эффекты за тот же период составляют 17%. Увеличение продаж, с одной стороны, приводит к смещениям в рыночных долях и вытеснению, с другой. Это может поставить под угрозу компании, которые не перерабатывают свои портфели продуктов и услуг. Для улучшения денежного потока в условиях возрастающего конкурентного давления некоторые компании, вероятно, сократят свои инвестиции в исследования и разработки и в использование новых технологий. Это может привести к порочному кругу, поскольку такое поведение может увеличить разрыв с компаниями, использующими ИИ.
В целом, согласно симуляции McKinsey, инновации в продуктах и услугах могут составлять до 7% или 6 триллионов долларов США потенциального ВВП к 2030 году (чистый эффект). Важная причина этих значительных эффектов ИИ в том, что компании, полагающиеся на Искусственный Интеллект, могут быстро увеличить продажи, достигая недостаточно обслуживаемых рынков с существующими продуктами и услугами более эффективно. Кроме того, выгоды могут быть достигнуты за счет повышения производительности в результате замещения человеческого труда. Еще одна причина в том, что большинство технологий поощряют инновации в продуктах и услугах и помогают создавать и развивать новые рынки.
Макрофакторы включают вопрос о том, как использование ИИ влияет на трансграничную торговлю. Помимо общей экономической выгоды, существуют также переходные издержки для возрастающего использования ИИ.
• Область деятельности 4: Глобальные потоки данных и связанность
Уже сегодня трансграничный обмен информацией, товарами и услугами вносит значительный вклад в общую экономическую эффективность. Страны, принадлежащие к глобально связанным и цифровым развитым экономикам, получат дальнейшие импульсы для роста от Искусственного Интеллекта. В своей симуляции McKinsey предполагает, что Искусственный Интеллект может составлять до 20% цифровых потоков.
Искусственный Интеллект может способствовать цифровым потокам двумя способами. Первый — сделать трансграничную торговлю более эффективной. McKinsey оценивает, что около трети цифровых потоков данных связаны с трансграничной электронной коммерцией. Искусственный Интеллект может способствовать глобальной торговле, улучшая эффективность цепочки поставок и снижая сложность глобальных контрактов, классификаций и соответствия требованиям торговли. Потери от трения в цепочке поставок могут быть снижены за счет использования обработки естественного языка для автоматического определения товаров и правильной классификации их в соответствии с таможенными таксономиями. Повышение прозрачности и эффективности цепочки поставок может помочь компаниям обеспечить лучшее торговое финансирование и снизить опасения банков относительно соответствия требованиям. Банки, в свою очередь, могут использовать технологии ИИ для обработки торговых документов, что облегчает анализ рисков.
Второй способ, которым Искусственный Интеллект может способствовать полному использованию глобальных потоков, — это улучшенное и расширенное использование трансграничных
потоков данных — независимо от деятельности в сфере электронной коммерции. Здесь все еще имеется большой потенциал для оптимизации, особенно в сфере услуг. Ежедневно огромные объемы данных превышают пределы, и возрастающая доля этих потоков может стимулировать приложения ИИ. Большие объемы данных из кабинетов врачей и больниц по всему миру могут улучшить точность диагностики редких видов рака (ср. разд. 6.1). Качество механизмов перевода ИИ также может быть значительно улучшено, если они обучаются на квалифицированных данных на разных языках. Производительность чат-ботов, механизмов агрегации сообщений и рекомендательных сайтов также может получить выгоду от глобальных потоков данных.
Кроме того, Искусственный Интеллект может привести к эффектам переноса знаний. Таким образом, доступные во всех странах цифровые платформы талантов могут помочь компаниям удовлетворить свои потребности в экспертизе специалистов со всего мира. На ранней стадии такой цифровой обмен знаниями и сравнение все еще происходит вручную. Искусственный Интеллект может устойчиво улучшать качество этого сопоставления и, прежде всего, ускорять его. Примерами являются proSapient и NewtonX. ProSapient (2019) называет себя "Сетью экспертов следующего поколения", обеспечивающей связь с экспертами по всему миру. NewtonX (2019) видит себя как наиболее продвинутую в мире платформу доступа к знаниям. Эта платформа работает во всех отраслях, темах и географиях и обеспечивает легкий доступ к лучшим экспертам в мире.
В целом, симуляция McKinsey показывает, что кумулятивные эффекты этих разработок остаются в узких пределах на уровне 1 и 2% соответственно (ср. рис. 1.16).
• Область деятельности 5: Создание и реинвестирование богатства
Поскольку Искусственный Интеллект способствует повышению производительности экономик, результаты повышения эффективности и инновации могут быть переданы работникам в виде заработной платы. Такое создание богатства, обусловленное ИИ, может генерировать эффекты переноса, которые стимулируют экономический рост. Когда доходы работников растут и они тратят больше, а компании реинвестируют свою прибыль в компанию, экономический рост стимулируется — восходящая спираль. Это может создать дополнительные рабочие места, способствовать росту цепочки создания стоимости ИИ и укреплению ИТ-сектора, что может внести важный общий экономический вклад через реинвестирование.
Симуляция McKinsey показывает, что такие эффекты не могут быть ожидаемы в краткосрочной перспективе. К 2030 году кумулятивные эффекты этих разработок также будут ограничены 3% (ср. рис. 1.16).
Совокупный общий эффект ("валовое влияние") пяти обсуждаемых областей деятельности на рис. 1.16 показывает умеренное значение 5% к 2023 году. В отличие от этого, к 2030 году ожидается совокупный общий эффект 26%. Это ясно показывает, что влияние ИИ на валовой внутренний продукт останется довольно незначительным в ближайшем будущем; основные эффекты станут очевидны только после 2023 года (ср. рис. 1.14).
Конечно, такая симуляция должна также учитывать затраты и другие негативные эффекты использования ИИ. Соответствующие движущие силы и эффекты описаны ниже.
• Область деятельности 6: Переходные и внедренческие издержки
При возрастающем использовании ИИ возникают дополнительные издержки. В частности, высвобождение сотрудников имеет негативное влияние. Необходимо также учитывать затраты на внедрение соответствующих систем, расходы на найм новых сотрудников и на дальнейшее повышение квалификации рабочей силы (ср. рис. 1.17). Конечно, эти затраты также влияют на экономику в целом. Ожидаются отрицательные кумулятивные эффекты на валовой внутренний продукт в размере 2% к 2023 году и 5% к 2030 году (ср. рис. 1.16).
• Область деятельности 7: Отрицательные внешние эффекты
Использование ИИ также может привести к отрицательным внешним эффектам распределения (ср. рис. 1.17). Прежде всего, они могут повлиять на сотрудников. Увеличение использования ИИ может привести к снижению доли рабочей силы в экономике. Использование технологий ИИ может усилить давление на занятость и заработную плату, тем самым снижая долю рабочей силы в доходах и потенциальный экономический рост. Это может привести к (временной) потере потребления соответствующими лицами (например, в период безработицы или необходимого переобучения). В эти периоды затронутые страны также могут столкнуться с более высокими расходами.
Исследование McKinsey показывает, что в теории до 14% сотрудников могут быть вынуждены изменить свои рабочие роли — частично не только внутри компаний, но и между компаниями, секторами и/или регионами. Кроме того, выясняется, что большинство сотрудников будут конкурировать с системами ИИ за выбранные задачи. Менее 10% профессий состоят из видов деятельности, которые могут быть полностью или более чем на 90% автоматизированы ИИ.
Рисунок 1.17 Затраты и отрицательные эффекты перехода к экономике на основе ИИ — симуляция процентного влияния к 2030 году. Источник: McKinsey (2018a, с. 22)
Тем не менее, примерно в 60% рабочих областей по крайней мере одна треть деятельности может быть автоматизирована. Это идет рука об руку с значительными изменениями для сотрудников и рабочих мест.
Сопутствующие издержки потери внутреннего потребления из-за безработицы в размере около 7 триллионов долларов США к 2030 году могут снизить положительный эффект Искусственного Интеллекта на четыре процентных пункта к 2030 году. Переходные и внедренческие издержки могут составить еще пять процентных пунктов издержек. Рисунок 1.17 подробно показывает, как представлены эти отрицательные эффекты.
Следовательно, экономическое использование автоматизации и инноваций на основе ИИ имеет свою цену. Использование ИИ, вероятно, потрясет рынки труда и приведет к значительным издержкам. Точно рассчитать издержки очень сложно, поскольку они, вероятно, возникнут на нескольких фронтах со стороны спроса и предложения и во многих случаях будут связаны. Кроме того, переходные издержки в одной части цепочки создания стоимости могут создать новую ценность в другой части.
Если одновременно учитываются положительные и отрицательные эффекты использования ИИ, совокупный чистый эффект на мировой валовой внутренний продукт составляет плюс 1% к 2023 году и плюс 16% к 2030 году (ср. рис. 1.16).
Ящик памяти
Использование Искусственного Интеллекта окажет долгосрочное и глубокое влияние на сотрудников, компании и экономики. Как и в случае со многими новыми технологиями, эти эффекты изначально будут ограничены в ближайшие пять лет. Всеобъемлющие эффекты проявятся только после 2023 года!
Как различные эффекты будут совокупным образом влиять на рынок труда до 2030 года? Прежде всего, можно сказать, что около половины всех видов деятельности могут быть автоматизированы с помощью технологий ИИ. Однако ряд технических, экономических и социальных факторов препятствуют этому потенциалу автоматизации к 2030 году. Фактически, McKinsey (2018a, с. 44f.) ожидает среднего уровня автоматизации в 15% для сценария 46 стран. Эта доля будет сильно различаться от страны к стране. В каждой отдельной стране динамика занятости будет зависеть от взаимодействия обсуждаемых выше факторов. Развитие Искусственного Интеллекта приведет как к потере рабочих мест, так и к созданию новых. Симуляция McKinsey привела к чистому эффекту на общую занятость всего в -1%. Тем не менее, это может скрывать серьезные искажения в отдельных компаниях и странах.
Пища для размышлений
Новости — онлайн и офлайн — регулярно сообщают об увольнении тысяч сотрудников, вызванном ИИ. В 2018 году заявление немецкого гиганта электронной коммерции Zalando о том, что они будут больше ориентироваться на алгоритмы и Искусственный Интеллект в маркетинге в будущем. Это стало причиной увольнения до 250 экспертов по рекламе, в то время как одновременно велся поиск разработчиков ИИ. Это стало началом самой большой реструктуризации Zalando в его еще молодой истории компании (ср. Jansen, 2018). Девиз был поразительным: алгоритмы и Искусственный Интеллект вместо людей.
Это решение вызвало огромный медийный резонанс и усилило страхи среди населения, к которым Искусственный Интеллект может привести катастрофические последствия. Это всего лишь одна сторона медали. Мы — как преподаватели, университетские лекторы, предприниматели и политики — должны также сообщать о положительных эффектах Искусственного Интеллекта. Только тогда может быть достигнуто, что глобальное использование ИИ не приведет к застою из-за чистого страха.
Резюме
• Использование Искусственного Интеллекта окажет огромное влияние на сотрудников, компании и экономики в целом.
• Сотрудники потеряют свои рабочие места, в то время как будут созданы новые. В целом, ответственность каждого человека за непрерывное повышение квалификации в соответствии с будущими требованиями растет.
• Компании сталкиваются с проблемой распознавания и использования возможностей, предлагаемых Искусственным Интеллектом. В то же время необходимо выявлять риски и управлять ими.
• Положение глобальных экономик изменится в зависимости от использования Искусственного Интеллекта. Существующие дисбалансы могут быть увеличены или уменьшены в равной степени.
• Ожидается, что общее количество рабочих мест по всему миру не изменится существенно до 2030 года в результате использования Искусственного Интеллекта. Тем не менее, могут возникнуть значительные искажения в отдельных компаниях и экономиках.
• В целом, влияние использования ИИ на компании и общество будет ограничено до 2023 года. Только с 2023 года Искусственный Интеллект проявит свой разрушительный потенциал в полном объеме и приведет к значительным инновациям в продуктах, услугах и процессах.
Рисунок 1.18 Совокупные эффекты использования ИИ на занятость к 2030 году — в % (в расчете на полное рабочее время). Источник: McKinsey (2018a, с. 45)
• Каждая национальная экономика и каждая группа стран должны признать и использовать потенциал изменений, который предлагает Искусственный Интеллект для своей области ответственности на ранней стадии. Ожидание здесь неприемлемо!
Библиография
2045 Strategic Social Initiative. (2012). Результаты конкурса иллюстраций: Нео-гуманизм. http://2045.com/articles/30775.html. Доступ 15 апреля 2019.
Agrawal, A., Gans, J., & Goldfarb, A. (2018). Prediction machines: The simple economics of artificial intelligence. Boston.
Ankenbrand, H. (2018). Gesichtserkennung: Китай имеет самый ценный KI-стартап в мире. http://www.faz.net/aktuell/wirtschaft/unternehmen/sensetime-china-hat-das-wertvollste-ki-startup der-welt-15533068.html. Доступ 30 апреля 2019.
Allen, P. (2011). Сингулярность не близко. In MIT Technology Review. https://www. technologyreview.com/s/425733/paul-allen-the-singularity-isnt-near/. Доступ 14 апреля 2019.
Arel, I., Rose, D., & Karnowsk, T. (2010). Deep machine learning—Новый рубеж в исследованиях искусственного интеллекта: Research frontier (с. 13–18). Ноябрь 2010.
Armbruster, A. (2017). Künstliche Intelligenz: Гонка, как в холодной войне. http://www.faz. net/aktuell/wirtschaft/kuenstliche-intelligenz/kuenstliche-intelligenz-wer-gewinnt-den wettlauf-usa-oder-china-15284415.html. Доступ 19 апреля 2019.
Bendel, O. (2019). Социальные боты. https://wirtschaftslexikon.gabler.de/definition/social-bots-54247. Доступ 10 апреля 2019.
Beyerer, J., León, F., & Frese, C. (2016). Машинное зрение—Автоматизированный визуальный контроль: Theory practice and applications. Берлин, Гейдельберг: Springer.
Bitkom, & DFKI (2017). Künstliche Intelligenz, Wirtschaftliche Bedeutung, gesellschaftliche Herausforderungen, menschliche Verantwortung. Берлин.
Bollmann, R. (2018). Die Zukunft der Arbeit. Frankfurter Allgemeine Quaterly, 8(2018), 132– 140.
Bostrom, N. (2014). Superintelligence—Пути, опасности, стратегии. Оксфорд: Oxford University Press.
Brynjolfsson, E., & McAfee, A. (2014). The second machine age: Wie die nächste digitale Revolution unser aller Leben verändern wird. Кульмбах.
Capgemini. (2018). Studie: Verbraucher wollen menschen-ähnliche Künstliche Intelligenz ohne menschliches Aussehen. https://www.capgemini.com/de-de/news/studie-verbraucher-wollen menschenaehnliche-kuenstliche-intelligenz-ohne-menschliches-aussehen/. Доступ 10 мая 2019.
Chalmers, D. (2010). Сингулярность—философский анализ. Journal of Consciousness Studies, 17(9–10), 7–65.
Cheetah Mobile. (2018). Cheetah Mobile Welcomes DDV, Пекин, 11 января 2018.
Deloitte. (2017). The 2017 Deloitte state of cognitive survey. https://www-statista-com.ezproxy. hwr-berlin.de/statistics/787151/worldwide-ai-deployment-in-organizations/. Доступ 29 апреля 2019.
Domingos, P. (2015). The master algorithm: How the quest for the ultimate learning machine will remake our world. Нью-Йорк.
Elsevier. (2018). Artificial Intelligence: How knowledge is created, transferred, and used. Trends in China, Europe, and the United States. https://www.elsevier.com/connect/ai-resource-center. Доступ 2 мая 2019.
Future of Life Institute. (2015). Автономное оружие: открытое письмо исследователей ИИ и робототехники. https://futureoflife.org/open-letter-autonomous-weapons/. Доступ 6 апреля 2019.
Galeon, D. (2016). SoftBank инвестирует в микрочип, чтобы сделать сингулярность реальностью: Футуризм. 31 октября 2016. https://futurism.com/softbank-is-investing-in-a-microchip-to-make-the singularity-a-reality/. Доступ 21 января 2019.
Gardner, H., Davis, K., Christodoulou, J., & Seider, S. (2011). The theory of multiple intelligences. В R. Sternberg & B. Kaufman (ред.), The Cambridge handbook of intelligence (с. 485–503). Кембридж: Cambridge University Press.
Gentsch, P. (2018). Künstliche Intelligenz für Sales, Marketing und Service, Mit AI und Bots zu einem Algorithmic Business – Konzepte. Висбаден: Technologien und Best Practices.
Görz, G., Schneeberger, J., & Schmid, U. (ред.). (2013). Handbuch der Künstlichen Intelligenz, (5-е изд.). Мюнхен.
Hawking, S. (2014). BBC Interview от 2 декабря 2014. https://www.youtube.com/watch?v= fFLVyWBDTfo. Доступ 23 апреля 2019.
Heise. (2011). IBM-Суперкомпьютер победил в викторине. http://www.heise.de/newsticker/meldung/ IBM-Supercomputer-gewinnt-Quizshow-1191298.html. Доступ 8 мая 2019.
Hochreiter, S. (2018). Maschinen mangelt es an Weltwissen. Bonner Generalanzeiger (с. 3). 12 декабря 2018.
Hofstadter, D. R. (2018). Das letzte Refugium menschlicher Intelligenz. Frankfurter Allgemeine Zeitung (с. N.4). 27 июня 2018.
IEEE Spectrum. (2008). Tech luminaries address singularity. https://spectrum.ieee.org/computing/ hardware/tech-luminaries-address-singularity. Доступ 4 марта 2019.
Ingenieur. (2016). Google-Software hat Weltmeister Lee Sedol haushoch geschlagen. https://www. ingenieur.de/technik/fachbereiche/ittk/google-software-weltmeister-lee-sedol-haushoch geschlagen/. Доступ 18 января 2019.
Jansen, J. (2018). Zalando baut radikal um. Frankfurter Allgemeine Zeitung. http://www.faz.net/ aktuell/wirtschaft/diginomics/zalando-will-werbefachleute-durch-entwickler-ersetzen 15483592.html. Доступ 2 апреля 2019.
Kairos Future. (2015). Future disruptive technologies, do you fully understand how new disruptive technologies will reshape your industry? http://www.kairosfuture.com/research/programs/ future-disruptive-technologies. Доступ 1 мая 2019.
Kelly, K. (2014). The three breakthroughs that have finally unleashed AI on the world. Wired. https://www.wired.com/2014/10/future-of-artificial-intelligence. Доступ 26 апреля 2019.
Kleinberg, J., Ludwig, J., Mullainathan, S., & Sunstein, C. R. (2019). Discrimination in the age of algorithms. NBER Working Paper No. 25548.
Krämer, T. (2015). Kommt die gesteuerte Persönlichkeit? Spektrum der Wissenschaft, 3/2015, с. 40–43.
Kreutzer, R. (2018). Herausforderung China: Manager wendet den Blick (verstärkt) nach Osten – nicht (mehr allein) nach Westen! In Der Betriebswirt, 3, с. 10–16, и 4/2018, Гернсбах.
Kreutzer, R., & Land, K.-H. (2015). Dematerialisierung – Die Neuverteilung der Welt in Zeiten des digitalen Darwinismus. Кёльн.
Kreutzer, R., & Land, K.-H. (2016). Digitaler Darwinismus – Der stille Angriff auf Ihr Geschäftsmodell und Ihre Marke (2-е изд.). Висбаден.
Kurzweil, R. (2005). The singularity is near. Нью-Йорк.
Lackes, R. (2018). Neuronale Netze. https://wirtschaftslexikon.gabler.de/definition/neuronale netze-41065#definition. Доступ 12 июня 2018.
Lambrecht, A., & Tucker, C. (2017). Algorithmic bias? An empirical study into apparent gender-based discrimination in the display of STEMCareer Ads, представлено на NBER Summer Institute, Июль 2017.
Lee, K.-F. (2018). AI super-powers, China, Silicon Valley, and the New World Order. Нью-Йорк.
Leverhulme Centre. (2019). Exploring the impact of Artificial Intelligence. http://lcfi.ac.uk/. Доступ 14 апреля 2019.
MacCartney, B. (2014). Understanding natural language understanding. https://nlp.stanford.edu/ *wcmac/papers/20140716-UNLU.pdf. Доступ 2 мая 2019.
Malsburg, von der C. (2018). Schaltzentrale à la Mutter Natur. Bonner Generalanzeiger, 28 ноября 2018, с. 11.
McKinsey. (2018a). Notes from the AI frontier, Modeling the Impact of AI on the world economy. Сан-Франциско.
McKinsey. (2018b). An executive’s guide to AI. Сан-Франциско.
Metzinger, T. (2001). Postbiotisches Bewusstsein: Wie man ein künstliches Subjekt baut – und warum wir es nicht tun sollten: Paderborner Podium – 20 Jahre Heinz Nixdorf Museumsforum, Падерборн.
NewtonX. (2019). NewtonX, Access Knowledge. https://www.newtonx.com/. Доступ 20 апреля 2019.
Nilsson, N. (2010). The quest for Artificial Intelligence—История и достижения идей. Нью-Йорк.
Pariser, E. (2017). Фильтр-пузырь: Wie wir im Internet entmündigt werden, Мюнхен.
proSapient. (2019). An next generation expert network. https://prosapient.com/. Доступ 1 апреля 2019.
Rich, E. (1983). Artificial Intelligence. Нью-Йорк.
Rossi, F. (2018). Künstliche Intelligenz muss fair sein. In Frankfurter Allgemeine Sonntagszeitung (с. 21). 22 июля 2018.
Rouse, M. (2016). Neural Network. https://searchenterpriseai.techtarget.com/definition/neural network. Доступ 11 мая 2019.
Russell, S., & Norvig, P. (2012). Künstliche Intelligenz – Ein moderner Ansatz, 3. Aufl., Мюнхен.
Searle, J. (1980). Minds, brains, and programs. Behavioral and Brain Sciences, 3(3), 417–457.
Schölkopf, B., & Smola, A. J. (2018). Learning with Kernels: Support vector machines, regularization, optimization, and beyond. Лондон.
Schulz von Thun, F. (2019). Das Kommunikationsquadrat. https://www.schulz-von-thun.de/die modelle/das-kommunikationsquadrat. Доступ 16 апреля 2019.
Sensetime. (2018). SenseTime AI—Powering future, Präsentation, Пекин, 11 января 2018.
Statista. (2018). Künstliche Intelligenz. https://de-statista-com.ezproxy.hwr-berlin.de/statistik/ studie/id/38585/dokument/kuenstliche-intelligenz-statista-dossier/. Доступ 29 августа 2018.
Stieglitz, T. (2015). Neuroimplantate. Spektrum der Wissenschaft (с. 6–13). Март, 2015.
Stolfo, S., Fan, D., Lee, W., & Prodromidis, A. (2016). Credit card fraud detection using meta-learning: Issues and initial results. В AAAI Technical Report. http://www.aaai.org/Papers/ Workshops/1997/WS-97-07/WS97-07-015.pdf. Доступ 23 апреля 2019.
Swearingen, J. (2017). Robot security guard commits suicide in public fountain. http://nymag.com/ selectall/2017/07/robot-security-guard-commits-suicide-in-public-fountain.html. Доступ 21 апреля 2019.
Voss, O. (2017). Wenn der Algorithmus versagt, So dumm ist Künstliche Intelligenz. https://www. tagesspiegel.de/politik/wenn-der-algorithmus-versagt-so-dumm-ist-kuenstliche-intelligenz/ 20602294.html. Доступ 21 марта 2019.
Walsh, T. (2016). The singularity may never be near. https://arxiv.org/pdf/1602.06462.pdf. Доступ 4 мая 2019.
Wandelbots. (2019). Wandelbots. http://www.wandelbots.com/. Доступ 4 мая 2019.
West, J., & Bhattacharya, M. (2016). Intelligent financial fraud detection: Comprehensive review. Computers & Security, 57, 47–66.
Wolfangel, E. (2018). Künstliche Dummheit. In Süddeutsche Zeitung (с. 33). 14/15 июля 2018.
Другие статьи по этой теме:
- 601 пример внедрения ИИ на производствах и преприятиях
- ИИ в корпоративном секторе
- Пособие по разработке стратегии ИИ