Ох, стать творцом ценности ИИ
В предыдущей главе мы представили ряд императивов, которые могут мгновенно повысить шансы на успех любого пути к ИИ. Все это основано на нашем бесчисленном коллективном опыте, который варьируется от тысяч взаимодействий с клиентами до телешоу, таких как «60 минут», до Белого дома США, НАТО, высшего руководства и даже Ватикана! (В Ватикане хранятся бесценные артефакты в азотных хранилищах, и мы — ну, широкая команда IBM — помогли открыть эти артефакты ученым, чтобы безопасно масштабировать знания и историю. Хотя мы не можем поделиться с вами деталями этой сделки, мы уверены в загробной жизни.)
Вы также узнали о моменте Netscape сегодня и о том, как он является цунами перемен, которое прокатится по вашим личным и профессиональным берегам. Теперь вы понимаете, что, как и электричество когда-то считалось магией, хотя таковой не являлось, ИИ тоже не магия. Мы подтолкнули (ладно, с двух рук втолкнули) вас в мышление от +ИИ к ИИ+ и дали вам перезагруженную для этого момента Лестницу ИИ, по которой можно подняться к успеху с ИИ. Наконец, мы представили вам некоторые операционные структуры для классификации бюджетов на ИИ, выбора вариантов использования и предвидения результатов, которые либо сдвинут ваш бизнес влево, либо вправо.
Мы считаем, что Глава 1 и эта глава важны, потому что обе они посвящены определению правильных деталей, на которые стоит обратить внимание в вашем путешествии с ИИ. Почему? Детали будут важны, детали будут отличать, и детали принесут (или сохранят) доверие. Мы используем историю Статуи Свободы как аналогию того, что вы делаете в первой части этой книги. Она стоит высокая и зеленая в культовом нью-йоркском порту. Ее патина (зеленая химическая реакция меди, возникающая со временем) помогает ей стойко противостоять стихиям — но это, должно быть, было что-то особенное для иммигрантов, видеть ее медное свечение на горизонте, когда они вплывали в порт Нью-Йорка, давным-давно. Если у вас есть возможность, уделите минуту, чтобы посмотреть на ее волосы. Если вы поищете фотографию крупным планом, вы увидите замысловатое плетение и тщательно уложенные локоны на затылке. Это идеальные волосы на идеальной статуе. Интересно, что Статуя
Свободы была построена за 10 лет до первого самолета. Ее скульптор, Фредерик Огюст Бартольди, не имел причин полагать, что кто-то когда-либо увидит ее волосы — однако детали имели значение, потому что скульптура была его ремеслом, и его репутация зависела от этих деталей. Какое отношение это имеет к ИИ? Решения, которые вы примете за следующие несколько лет — и то, как вы их примете — возможно, никогда не будут видны изолированно или явно, но их детали будут иметь значение, потому что они будут означать, кто вы и кто ваша команда, компания, и кем вы хотите быть. Помните об этом.
В этой главе мы хотим представить вам, возможно, самое важное место назначения для ИИ в ваших личных навигационных системах: AI Value Creator. Помните, эта часть книги посвящена бизнесу, поэтому, хотя мы позже дадим вам больше информации о больших языковых моделях (БЯМ) с технологической точки зрения, у нас есть еще несколько вопросов, связанных с бизнесом ИИ, о которых мы хотим, чтобы вы подумали, чтобы у вас был больший набор навыков, из которых можно черпать, чем у тех, кто не прочитает эту книгу.
ИИ сквозь годы: Раздел «Замедленная съемка» ИИ
Термин ИИ был впервые введен в 1956 году, и различные поколения этой технологии (хотя ни одно из них не похоже на нынешний момент GenAI и агентов) прогрессировали и разочаровывали с тех пор. Некоторые скажут, что ИИ разочаровывал чаще, чем радовал, что приводило к «зимам ИИ», из которых ИИ снова появлялся после некоторых прорывов. Если посмотреть на историю изобретений (возьмем электричество, например), не должно быть сюрпризом, что путь к прорывам в области ИИ прошел через массовые эксперименты. В то время как многие эксперименты с ИИ потерпели неудачу, успешные имели существенное влияние, и эти успехи пришли от решения проблем, которые вызывали неудачи.
Люди давно размышляют о возможности того, что машины когда-нибудь смогут мыслить как человек, самостоятельно. Это продолжается с конца 1800-х годов, но идея по-настоящему укоренилась благодаря основополагающей работе Алана Тьюринга «Вычислительная техника и интеллект» 1950 года. Историки называют Тьюринга отцом ИИ именно благодаря этой работе. В ней он теоретизировал, что общество сможет создавать компьютеры, которые будут играть в шахматы, описал, как эти компьютеры превзойдут игроков-людей, и сказал, что мы сделаем их искусными в естественном языке. Он теоретизировал, что машины в конечном итоге будут мыслить.
1 Алан Тьюринг, «Вычислительная техника и интеллект», Mind 49, № 236 (октябрь 1950 г.): 433–460, https://doi.org/10.1093/mind/LIX.236.433.
30 | Глава 2: Ох, стать творцом ценности ИИ
За годы нашей карьеры в IBM мы видели (и были частью достижения) многие вехи, которые Тьюринг определил на пути к «думающей» машине. Они включали в себя эволюцию и варианты ИИ, играющие в такие игры, как шахматы (с Deep Blue), Jeopardy! и настольная игра Го, а также дебаты. Но Тьюринг был только началом.
Если статья Тьюринга была искрой, то большой взрыв произошел всего через шесть лет на летнем исследовательском проекте по искусственному интеллекту в Дартмутском колледже. Там пара молодых академиков вместе с парой старших ученых из Bell Labs и IBM предложили расширенный летний семинар с небольшой группой лучших специалистов из смежных областей для интенсивного рассмотрения искусственного интеллекта. Именно там впервые был использован термин ИИ, и это знаменует точку, в которой ИИ был установлен как область исследований.
Подробно эта команда изложила многие задачи, над которыми исследователи работают с тех пор, чтобы разработать машины, которые могли бы мыслить. Нейронные сети, самообучение, творчество и многое другое актуальны и сегодня.
Для понимания перспективы, это было в 1956 году, в том же году, когда изобретение транзистора получило Нобелевскую премию. Сегодня мы можем разместить более 100 миллиардов транзисторов в графическом процессоре (GPU) и предоставить легионы взаимосвязанных GPU для обеспечения вычислительной мощности, необходимой для GenAI. На протяжении многих лет теории, методы и идеи ИИ разрабатывались параллельно с прогрессом в аппаратном обеспечении, которые объединились, чтобы резко сократить затраты на вычисления и хранение данных. Все это сходится сейчас, чтобы сделать ИИ очень реальным и практичным.
Но мы хотим сделать этот критический вывод: речь идет не только о мощном аппаратном обеспечении и умных алгоритмах. Возможно, самый важный ингредиент генеративного ИИ — особенно когда речь идет о получении максимальной выгоды для вашего бизнеса — это ваши данные. Вы не можете говорить о генеративном ИИ, не говоря о данных. Это делает аппаратное обеспечение, алгоритмы и данные тремя ножками стула ИИ.
Кратко о фундаментальных моделях
В мире GenAI вы часто будете слышать, как БЯМ питают GenAI. Но что это такое? На базовом уровне, БЯМ — это новые способы представления языка в многомерном пространстве с большим количеством параметров — представления, созданные путем обучения на огромных объемах текста.
ИИ сквозь годы: Раздел «Замедленная съемка» ИИ | 31
Сложности терминологии
Мы прерываем книгу, чтобы объяснить некоторую терминологию простыми словами, которая пригодится вам на протяжении всей книги и у кулера (виртуального или физического). Вот общие термины, которые вы услышите в жаргоне GenAI:
БЯМ
Это, вероятно, самый распространенный тип моделей GenAI. В большинстве случаев, когда мы говорим о GenAI в этой книге, вы должны предполагать, что мы имеем в виду БЯМ (если мы не говорим иначе). Когда вы слышите об OpenAI ChatGPT, Google Gemini, Meta Llama, IBM Granite, DeepSeek и Mistral AI, знайте, что все они являются БЯМ.
Существуют другие типы моделей GenAI, такие как диффузионные модели. Эти модели могут генерировать высококачественные данные. (Подумайте о генерации изображения из промпта с использованием Stable Diffusion или Midjourney AI.) Диффузионные модели добавляют шум2 к входному набору данных. Например, входным набором данных может быть кошка (по какой-то причине мир ИИ одержим кошками). Шум итеративно добавляется снова и снова в несколько раундов обучения, которые в терминологии ИИ называются *эпохами*. Модели ИИ обучаются с использованием нескольких эпох для создания алгоритма, и этот процесс выполняется до тех пор, пока вы почти ничего не увидите. (Подумайте о старом телевизоре с таким сильным статическим помехами, что вы больше не можете смотреть передачу, которую смотрели.) Затем этот ИИ учится восстанавливать исходный входной сигнал из этого шума (в данном случае, кошку).
Параметры
Вы часто будете слышать о БЯМ вместе с его размером — например, Llama-3-70B. 70Б здесь означает 70 миллиардов, что является количеством параметров в модели. В этом контексте (на высоком уровне) вы можете думать о количестве параметров как о общей емкости БЯМ. (На протяжении всей книги вы будете часто видеть, как мы ссылаемся на *параметры модели* и *веса модели*. В большинстве случаев эти термины взаимозаменяемы. Оба они описывают набор числовых значений — «мешок чисел» — которые составляют БЯМ, кодируя изученные отношения из обучающих данных.) Чем больше параметров у модели, тем больше задач она обычно может выполнять — но больше не всегда лучше или способнее, и, как вы узнаете в Главе 7, происходят довольно важные вещи, которые заставляют мир задуматься о размере моделей, которые они будут использовать для бизнеса. Подумайте об этом так: если ваш бизнес использует БЯМ для написания уведомлений о просроченной задолженности, нужно ли ему знать, как писать с личностью Джоуи Триббиани из сериала «Друзья»? Мы уже видим это: «Как делишки?» с указанием суммы задолженности. А как насчет Майкла Скотта из сериала «Офис»?
2 Шум в обучающих данных — это любая нерелевантная или случайная информация, ошибки или вариации, которые не отражают истинных лежащих в основе закономерностей или отношений в данных.
32 | Глава 2: Ох, стать творцом ценности ИИ
Многомерное пространство
Это может быть сложно, но мы постараемся сделать это просто. Подумайте о песне и опишите ее в трех измерениях (3D). Легко, верно? Возможно, вы включите «Shake It Off» Тейлор Свифт. (Будем честны. Неважно, любите вы ее или нет — вы все равно знаете все слова, так что даже не....) Мы бы описали эту песню как {поп, энергичная, стойкая}, и, конечно, как вы узнали в Главе 1, все это числа для ИИ.
Теперь подумайте об описании этой песни в 10 измерениях (10D). Мы придумали {поп, запоминающаяся, энергичная, вызывающая, веселая, гимническая, стойкая, радостная, яркая, игривая}. Но теперь попробуйте визуализировать эти 10 измерений на графике, и в итоге вы получите пустое пространство, детка. (Мы надеемся, вы оцените иронию.) Если у вас еще не болит голова, попробуйте описать эту песню с использованием сотни измерений, а затем тысячи измерений. Довольно просто, когда алгоритаристы говорят о данных в многомерном пространстве, они имеют в виду, что у вас столько измерений, что их трудно визуализировать.
Человеку невозможно мыслить в многомерном пространстве, но ИИ может мыслить в очень большом количестве измерений. Например, песня на Spotify закодирована (то есть представлена числами) сотнями, если не тысячами, измерений, которые численно представляют песню. Данные в многомерном пространстве дают ИИ множество возможностей для выполнения своей магии. Рассмотрим рекомендательный движок от Spotify. Плейлист пользователя — это как предложение, которое имеет тысячи измерений, представляющих предпочтения пользователя в прослушивании. Возможно, в этом плейлисте сильны представления о опере, классической музыке и попе. Spotify может сделать рекомендацию, например, «Богемская рапсодия» Queen (отличный выбор, если позволите) из-за оперных измерений этой песни. Это может привести к дальнейшим оперным предпочтениям, и внезапно вы слушаете «B.Y.O.B.» System of a Down. Почему? Где-то среди тысяч измерений, представляющих эти песни, есть измерения, которые говорят о том, насколько оперна песня, количество классических подтонов или о том, как песня рассказывает историю. («Богемская рапсодия» на самом деле о молодом человеке, который убил кого-то и продал свою душу дьяволу). Все это возможно потому, что хотя для нас песня может иметь одно-двухзначные измерения, для ИИ Spotify это как тысячи из них. И хотя вы не можете хранить тысячи измерений в голове, ИИ может — и это позволяет вам наслаждаться подобранным плейлистом во время прогулки, скажем, по Кэмденскому рынку в Лондоне днем (о, ирония).
С этой точки зрения, большая часть истории вычислений была связана с поиском новых способов представления данных и извлечения из них ценности. Долгое время мы помещали данные в таблицы. Например, мы помещали сотрудников или клиентов в строки базы данных и их атрибуты в столбцы. Это отлично подходит для таких вещей, как онлайн-обработка транзакций (OLTP) или выписка чеков физическим лицам.
ИИ сквозь годы: Раздел «Замедленная съемка» ИИ | 33
Затем мир начал представлять данные в виде графов, и это помогло нам открывать и ценить связи между точками данных, как никогда раньше; например, этот человек, бизнес или место были связаны с другими людьми, бизнесами или местами. Данные, представленные таким образом, начинают выявлять закономерности. Например, компании используют графы для отображения социальных сетей или выявления аномальных покупок, чтобы помочь им обнаруживать мошенничество с кредитными картами. Эта технология представляет собой комбинацию многих подходов к анализу данных с использованием различных типов хранилищ данных (сюда включена графовая база данных), и именно так работает функция «Люди, которых вы можете знать» (PYMK) на Facebook (в качестве всего лишь одного примера).
Сегодня с помощью БЯМ мы берем много данных, которые представлены в нейронных сетях, имитирующих (очень свободно) абстрактную версию клеток мозга. Существуют слои и слои связей с миллионами, десятками миллиардов, сотнями миллиардов или даже триллионами параметров — и внезапно вы можете делать некоторые увлекательные вещи. Вы можете обнаруживать настолько детализированные закономерности, что можете предсказывать связи с гораздо большей уверенностью. Например, вы можете предсказать, что это слово, скорее всего, связано с этим следующим словом, и за этими двумя словами, скорее всего, последует конкретное третье слово — что означает, что вы можете снова и снова наращивать, переоценивать и предсказывать, пока не будет создано или сгенерировано что-то новое. Отсюда и термин *генеративный* ИИ.
Вот что такое GenAI: способность смотреть на данные, обнаруживать связи и предсказывать вероятность последовательностей с достаточной уверенностью, чтобы создавать или генерировать что-то, чего раньше не существовало. Текст, изображения, видео, звуки и вообще все типы данных могут быть представлены в модели.
Мы могли бы сделать ограниченную версию всего этого раньше с помощью глубокого обучения, которое само по себе было вехой в ИИ. С глубоким обучением мы начали представлять огромное количество данных с использованием очень больших нейронных сетей со множеством слоев, но обучение должно было проходить с аннотированными данными, которые люди должны были вручную маркировать; например, смотреть на картинку и отмечать ее как «кошка» и другую картинку как «собака». Это называется *обучение с учителем*. В чем же была проблема? Как вы можете видеть на Figure 2-1, обучение с учителем дорогостоящее, трудоемкое и занимает много времени, поэтому эту работу выполняли только крупные учреждения и только для конкретных задач. Если вы хотели, чтобы ИИ обобщал и переводил текст, вам нужно было маркировать два очень больших набора данных... вручную (подробнее об этом чуть позже).
Примерно в 2017 году появился новый подход, основанный на архитектуре, называемой *трансформерами* (мы немного подробно рассматриваем их в Главе 9). При таком подходе ИИ мог выполнять новый вид бесфрикционного обучения, называемого *самообучением*, при котором языковая модель могла обучаться на больших объемах немаркированных данных, скрывая определенные участки текста (слова, предложения и т.д.) и предлагая модели заполнить пропуски (в терминологии ИИ это *маскирование*). Например, если бы мы сказали «May the force», вы, вероятно, угадали бы, что следующие три слова — «be with you» из «Звездных войн». Хотя
34 | Глава 2: Ох, стать творцом ценности ИИ
чрезмерное упрощение, этот удивительный процесс, выполняемый в масштабе, приводит к мощным представлениям данных, которые мы сегодня называем БЯМ.

Figure 2-1
Figure 2-1. Сравнение энергии активации для начала работы с обучением с учителем и самообучением
Именно здесь произошло что-то по-настоящему волшебное. Исследователи обнаружили, что вместо создания моделей ИИ, которые подходили только для узких вариантов использования и областей знаний (например, создания и кропотливого курирования одного набора данных для обобщения и другого для перевода), они могли бы иметь ИИ, который был бы более широко применим. По сути, эти БЯМ могли быть обучены на огромных объемах данных из интернета (самые популярные сегодня БЯМ на самом деле являются сильно сжатыми представлениями всего, что есть в интернете — что хорошо и плохо) и таким образом приобрести человекоподобный набор возможностей естественного языка.
Самообучение в масштабе, в сочетании с огромными данными и вычислениями, дало миру ИИ, который является обобщаемым и адаптивным. Мы определяем эти термины следующим образом:
Обобщаемый
Это означает, что ИИ способен хорошо работать в широком спектре задач и доменов, часто с минимальной или нулевой настройкой для конкретной задачи. Другими словами, одна и та же БЯМ, которая классифицирует тональность текстового документа, может извлекать людей и места из текста — действие, называемое распознаванием именованных сущностей (NER) — и может переводить, обобщать и многое другое.
Адаптивный
Это означает, что ИИ может не только выполнять несколько задач, но и обрабатывать варианты использования, для которых он изначально не обучался. Адаптивный ИИ также *эмерджентный*, что означает, что у него есть возможности, которые не были явно запрограммированы, и которые возникают неожиданно; например, БЯМ может отвечать на загадки или решать логические головоломки, на которых он никогда не обучался, просто распознавая закономерности. Суть в том, что возможность использовать одну и ту же модель для нескольких вариантов использования и обнаруживать в ней новые возможности — это мощный инструмент (хотя вы все равно захотите направить его, чтобы стать Создателем ценности ИИ; подробнее об этом чуть позже).
ИИ сквозь годы: Раздел «Замедленная съемка» ИИ | 35
За последнее десятилетие произошел взрыв приложений для ИИ. (Мы считаем, что вы использовали многие из них, даже не подозревая об этом. Вы использовали Siri или Alexa? Вы изменили пасмурное небо на солнечное, чтобы создать идеальный момент на фотографии? Вы использовали приложение для перевода?) За это время мы увидели, как ИИ перешел из чисто академического занятия в мощную силу, которая управляет действиями в самых разных отраслях и влияет на жизни миллиардов людей каждый день.
В последние годы нам удалось создать системы ИИ, которые могут учиться на тысячах или миллионах примеров, чтобы лучше понимать наш мир и находить новые решения сложных проблем. Эти крупномасштабные модели привели к разработке систем, которые могут понимать нас, когда мы говорим или пишем. К ним относятся программы обработки естественного языка (NLP) и понимания естественного языка (NLU), которые мы используем каждый день, от цифровых помощников до программ преобразования речи в текст. Другие системы, обученные на всем объеме работ известных художников или на всех существующих учебниках по химии, позволили нам создавать генеративные модели, которые могут создавать новые произведения искусства на основе стилей этих художников или новые составы и комбинации стыковки на основе истории химических исследований.
Хотя сегодня многие новые системы ИИ помогают решать всевозможные реальные проблемы, до появления GenAI создание и развертывание ИИ для каждой новой системы с использованием традиционных методов требовало значительного количества времени и ресурсов. Для каждого нового приложения вам нужно было убедиться, что существует большой, хорошо размеченный набор данных для конкретной задачи, которую вы хотели решить. Если такого набора данных не существовало, вам нужно было потратить сотни или тысячи часов (возможно, больше) на поиск и маркировку соответствующих изображений, текста или графов для обучающих и проверочных наборов данных.
Что все это значит? Вы можете взять большую, предварительно обученную БЯМ — если вы используете ее для бизнеса, вы захотите убедиться, что начинаете с надежной модели — и добавить свои институциональные знания, чтобы ускорить работу модели для достижения успеха в ваших конкретных вариантах использования с вашими конкретными данными. (Мы подробнее рассмотрим плюсы, минусы и захватывающие моменты этой темы в Главе 8.)
Теперь, если вы чувствуете некоторое уныние, потому что вы одна из тех компаний, о которых мы говорили, которая потратила огромное количество времени на сбор и маркировку данных для ваших проектов ИИ, только для того, чтобы они провалились, потому что вы не маркировали достаточно данных (так было с традиционным ИИ), не бойтесь! Эта работа не пропала даром в мире GenAI, потому что проприетарные отраслевые данные, о которых мы только что упомянули, — это то, что вы будете использовать для настройки БЯМ для нужд вашего бизнеса. Именно это вам нужно сделать, чтобы стать Создателем ценности ИИ. Фактически, вы буквально возьмете те неудавшиеся проекты ИИ двухлетней давности и будете выглядеть как герой, когда представите своим начальникам, как вы хотите направить любую БЯМ, которую вы выберете для своего бизнеса. Как так? Во-первых, сегодняшние БЯМ вообще не содержат много корпоративных данных (около 1%), не говоря уже о ваших проприетарных данных. В Главе 1 мы сказали вам, как ваши данные являются конкурентным преимуществом, и теперь пришло время пустить эти данные в работу.
36 | Глава 2: Ох, стать творцом ценности ИИ
Проще говоря, когда вы объединяете представления данных БЯМ и направляете их с помощью своих размеченных данных (которых вам теперь нужно гораздо меньше), вы получаете что-то, что настроено под ваш бизнес. Подумайте об этом так: предположим, вы знаете испанский, а сегодня пытаетесь выучить французский. На этом пути у вас уже есть много базовых знаний о том, как работает язык, например, как спрягать глаголы. Точно так же, как легче выучить французский, если у вас есть основа в испанском, как вы узнаете в Главе 8, существует новый подход с открытым исходным кодом (называемый InstructLab), который делает добавление ваших данных в вашу частную БЯМ проще, чем когда-либо, и не делиться ими с миром, и это обязательно придаст некоторым результатам ооо ля ля.
Текущее мышление обычно сводится к тому, что БЯМ (отсюда и их название) можно применять к языку. Но это должно вызвать вопрос: что такое язык? Сигналы в промышленном оборудовании говорят с вами на своем собственном языке; есть языки программирования, которые состоят из команд человека, управляющего машинами; и есть клики пользователя, перемещающегося по веб-сайту, программному коду, химии и диаграммам химических веществ. Мы даже работали с компанией, использующей ИИ для моделирования вкуса и запаха. Если прищуриться, все начинает выглядеть как язык, и если это язык, его можно изучить, расшифровать и понять.
Вывод состоит в том, что ИИ может быть специализирован для выполнения всевозможных задач, повышающих производительность на любом языке. Это означает, что ИИ может горизонтально охватывать ваш бизнес, от процессов управления персоналом, обслуживания клиентов, самообслуживания, кибербезопасности, написания кода, модернизации приложений и многих других вещей, которыми мы поделимся с вами в Главе 4.
Углубляемся: Эволюция больших языковых моделей и сравнение обучения с учителем с самообучением
Большие языковые модели строятся не так, как традиционный ИИ. Они обучаются с использованием самообучения, что означает, что вам не нужно вручную аннотировать огромное количество данных. По сути, вы обучаете модель, говоря ей читать огромное количество данных (например, текст), и когда она закончит, вы получаете большую, но универсальную модель с более человекоподобными языковыми возможностями. ИИ использует математические модели для представления отношений в данных (например, слов), которые он принимает. Если вы дадите модели несколько слов в промпте, она может математически предсказать вероятность слов, следующих в последовательности фразы из «Звездных войн», которой мы поделились в последнем разделе.
Две самые важные вещи, которые нас восхищают в GenAI, это то, насколько быстро вы теперь можете создавать те же варианты использования по всем причинам, обобщенным на Figure 2-1, и тот факт, что эти модели (как мы отметили в предыдущем разделе) являются обобщаемыми и адаптивными. Лучший способ оценить, как GenAI сглаживает кривую времени до получения ценности для проектов ИИ, — это выйти за рамки маркировки данных и сравнить GenAI с традиционным способом, которым варианты использования ИИ внедрялись в производство.
ИИ сквозь годы: Раздел «Замедленная съемка» ИИ | 37
Многие из вас, кто давно занимается ИИ, возможно, чувствуют, что видят повторение многих вариантов использования из эпохи традиционного ИИ в этой новой эпохе GenAI — и вы правы. Сказав это, мы не были бы неправы, если бы не отметили, что хотя первоначальный набор вариантов использования GenAI может повторяться, есть и новые, и агентный ИИ приносит гораздо больше. За последнее десятилетие, с появлением глубокого обучения, мир продемонстрировал (как сообщество), что вы можете достичь невероятной точности в конкретных задачах, если соберете достаточно данных, пометите эти данные, обучите модели и развернете их. Эта традиционная методология — это то, что вы видите на Figure 2-2.
Обратите внимание на Figure 2-2, как каждая модель строится для конкретного варианта использования ИИ. В этом примере варианты использования — обобщение, анализ тональности и извлечение сущностей. Чтобы построить эти модели с использованием традиционного подхода к ИИ, ваша компания создала бы отдельную команду для каждой задачи, и каждая команда построила бы отдельную модель для выполнения задачи. Все эти команды прошли бы через один и тот же трудоемкий процесс выбора и курирования данных, маркировки, разработки моделей, обучения, проверки и так далее — возможно, даже дублируя одни и те же данные!
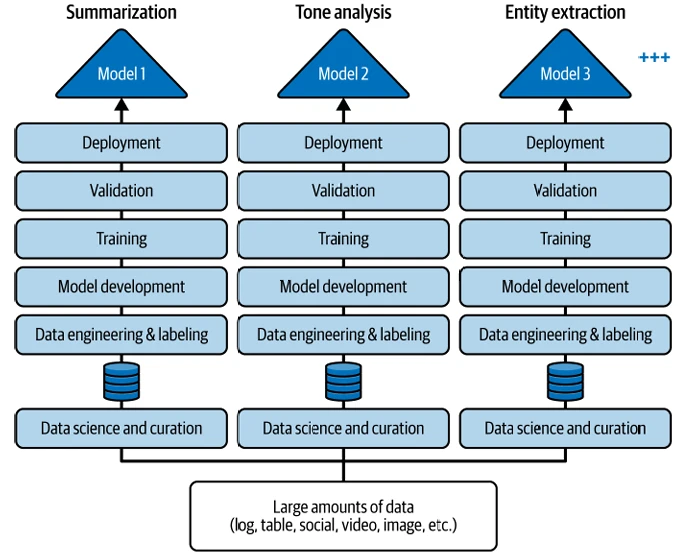
Figure 2-2
Figure 2-2. Традиционный способ создания ИИ: сбор множества команд специалистов по данным и выполнение ими как можно большего количества проектов
38 | Глава 2: Ох, стать творцом ценности ИИ
Различные команды собирают данные, курируют их для своего варианта использования и проходят те же самые шаги, которые проходят другие команды, что можно описать только как долгий, тяжелый, утомительный и дорогостоящий процесс. Фактически, мы смиренно предположили бы, что насколько ваша компания может масштабировать ИИ, было действительно ответом на вопросы: сколько команд специалистов по данным вы можете собрать и сколько проектов эти команды могут реализовать?
Теперь сравните новый подход к ИИ (на левой стороне Figure 2-3) с традиционным путем к ИИ (на правой стороне рисунка). Как видите, вместо необходимости строить одну модель ИИ для каждой конкретной задачи (как на Figure 2-2), вы берете БЯМ, который, вероятно, был обучен кем-то другим (например, IBM, Google, DeepSeek, OpenAI или Anthropic; по правде говоря, мало компаний будут строить свои собственные — скорее, они будут направлять существующие) и адаптировать ее для множества разнообразных последующих задач. Также обратите внимание, как одна БЯМ питает три варианта использования на Figure 2-3.
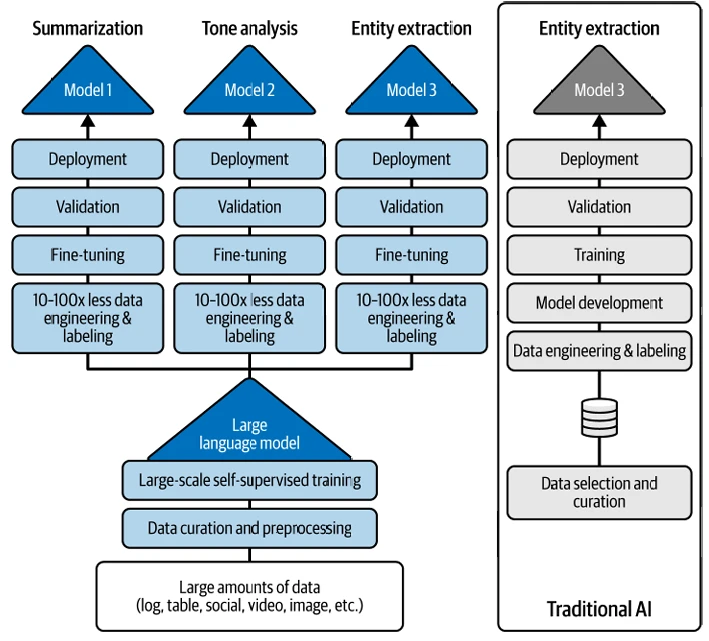
Figure 2-3
Figure 2-3. GenAI масштабирует ИИ, снижая требования к навыкам, данным, времени, администрированию и первоначальным затратам
ИИ сквозь годы: Раздел «Замедленная съемка» ИИ | 39
Учитывая универсальность БЯМ, компании теперь могут использовать одну и ту же модель для реализации множества бизнес-сценариев. Используя традиционный ИИ, они не могли этого сделать.
Мы очень хотим, чтобы вы уделили время запоминанию Figure 2-3, потому что оно иллюстрирует, почему БЯМ становятся неотъемлемыми ингредиентами нового рабочего процесса ИИ. Современный ИИ требует очень сфокусированных усилий по созданию базовой модели (то есть универсальной БЯМ) и получению экономии за счет масштаба от этих инвестиций. Создание собственной БЯМ — довольно сложная задача, поэтому мы уверены, что большинство из вас выберут одну для начала, а затем направят ее с помощью своих данных в соответствии с вашим бизнесом и вариантом использования (о чем мы расскажем позже в этой книге).
Мы надеемся, что вы хорошо поняли этот методологический сдвиг, потому что следующая волна ИИ, похоже, заменит модели, ориентированные на конкретные задачи, которые доминировали в ландшафте ИИ до сих пор, с БЯМ в качестве их ядра. Эти модели обучены на широком наборе данных, которые могут быть использованы для различных задач, и, более того, благодаря своей само-идеализации для достижения определенных целей, агентный ИИ также пойдет по этому пути.
В этом суть. Что делает БЯМ такими универсальными, так это то, что они, как следует из их названия, могут быть основой многих приложений на основе ИИ и агентов. Используя самообучение и трансферное обучение, эти модели ИИ могут применять информацию, которую они узнали в одной ситуации, к другой.
Самый простой способ понять трансферное обучение — это пример из традиционного компьютерного зрения, где ИИ используется для идентификации кошки. (Опять же, ИИ и кошки кажутся неразлучными — как будто какой-то кошачий любитель посчитал, что его глубокому обучению нужно немного глубокого мурлыканья.) Если вы научили ИИ распознавать кошку, этот ИИ начнет с форм и границ и постепенно построит слои в своей нейронной сети для идентификации кошки. На базовых уровнях этот ИИ, вероятно, сможет обнаруживать треугольники (комбинации границ). Если вы подумаете о кошке, треугольники образуют ее уши, нос и другие части, и как только ИИ сможет находить треугольники, он сможет продолжить обнаружение других признаков кошки, используя все больше и больше слоев в своей нейронной сети, чтобы в конечном итоге определить объект, который он видит, как кошку. Теперь представьте, что вы хотите идентифицировать парусник. ИИ, обученный распознавать парусники, начнет с того же места: поиска границ и форм. Итак, вы могли бы взять уровни ИИ, которые знают, как выглядят треугольники, и перенести это знание для распознавания лодок, вы могли бы сделать то же самое для потенциально тысяч слоев — и теперь вы понимаете трансферное обучение. Независимо от того, идентифицировал ли ИИ кошку или парусник, идентификация треугольника была бы критически важной.
Большинство из нас может соотнести универсальность БЯМ, поддерживающих множество вариантов использования, с нашей повседневной жизнью. Например, научившись водить автомобиль, вы приобрели серьезные навыки, которые можете перенести для управления другими автомобилями. Конечно, есть некоторые нюансы, к которым нужно привыкнуть (например, где найти рычаги управления стеклоочистителем), и вы можете даже столкнуться с серьезными проблемами (попробуйте водить с механической коробкой передач, если вы водили только с автоматической), но остается множество базовых навыков, которые переносятся. Сегодня никто
40 | Глава 2: Ох, стать творцом ценности ИИ
не строит сверточную нейронную сеть (CNN) или использует визуальный трансформер (ViT) для компьютерного зрения без какого-либо трансферного обучения — это как бы идеальный чит-код для компьютерного зрения!
Вывод? Все просто: вместо того, чтобы строить одну модель ИИ для каждой конкретной задачи, вы можете обучить одну модель и адаптировать ее для множества разнообразных последующих задач. Это означает, что у компаний теперь есть возможность перейти от modus operandi «одна задача: одна модель» к «одна модель: множество задач». Например, ваш чат-бот ИТ-поддержки и ваши инициативы самообслуживания в области управления персоналом могут использовать ту же базовую модель, что и новое приложение, которое будет писать ваши маркетинговые электронные письма и обобщать контрактные документы.
Как показано на Figure 2-3, работа еще предстоит! Хотя задачи по инженерии данных и маркировке теперь минимальны, вам все равно захочется использовать свои данные, чтобы направить модель на вашу бизнес-область и ее бренд, стиль, социальные нормы и так далее. Существует много способов сделать это, используя такие техники, как настройка промптов, инженерия промптов, тонкая настройка с использованием эффективных методов тонкой настройки параметров (PEFT) и InstructLab. Подробнее об этом вы узнаете в Главе 8, но вся подготовительная работа, которую вы должны проделать до того, как ваши данные начнут работать, значительно сократилась благодаря БЯМ.
Конечно, здесь должно быть очевидно не сила модели с миллиардами или даже триллионами параметров. Надеюсь, вам бросается в глаза, но если нет: продуктивность, связанная с БЯМ, означает, что бизнесы могут наконец масштабировать свои инициативы в области ИИ с меньшими затратами времени, данных, меньшими первоначальными затратами и меньшим администрированием. Например, по опыту IBM, потребовалось 7 лет, чтобы поддерживать 12 языков с использованием традиционного ИИ — но как только он принял GenAI, количество поддерживаемых языков выросло до 25 всего за год.
Создание ценности ИИ должно быть вашим направлением
Когда кислород, тепло и топливо объединяются, мы получаем огонь. Это просто, это первобытно, и это ключ, который разблокировал прогресс человечества. Подумайте об этом: огонь давал свет, тепло и защиту, и наши предки использовали его, чтобы перемещаться в новые климатические условия и есть новую пищу. Гончарное дело, металлургия, химия, быстрый транспорт и многие другие технологии начались с огня.
Но представьте, если бы огонь был проприетарным? Что, если знания о том, как разводить огонь, не были бы разделены, и что, если бы было всего несколько хранителей огня? Где бы мы оказались?
Помните, что мы вам сказали в предисловии: мы находимся в моменте подъема, сдвига, разрыва или обрыва с GenAI, и особенно с агентами, и это будет формировать наше общество для будущих поколений. Этот раздел (и остальная часть книги) покажет вам, как стать своим собственным поджигателем ИИ, как взять под контроль свою судьбу в области ИИ, и почему так важно видеть себя Создателем ценности ИИ, а не просто пользователем ИИ. Наконец, мы подробно расскажем, почему будущее ИИ нуждается в экосистеме открытых инноваций.
Создание ценности ИИ должно быть вашим направлением | 41
с человеческими ценностями. Этот путь открытий вполне может изменить наше понимание ИИ и его потенциального воздействия на общество.
Происхождение данных — Прослеживание следа: Пусть побеждают хорошие данные
Мы не собираемся углубляться в эту тему здесь, потому что мы обсуждали ее в предыдущих главах (помните, вы не можете иметь ИИ без ИА). Сказав это, мы явно отметим, что этот фактор заключается в обеспечении того, чтобы системы ИИ включали подробности о своих данных, разработке, развертывании и обслуживании, чтобы их можно было аудитировать на протяжении всего жизненного цикла.
Представьте себе это как воду. Если вы знаете, откуда вода, у вас будет больше уверенности в ней. Например, вы, вероятно, доверяете воде из-под крана больше, чем воде из садового шланга. Если вы знаете, какая обработка была применена к вашей воде, вы, вероятно, доверяете ей больше. Например, прошла ли она через какой-то фильтр обратного осмоса? Представьте себе происхождение ваших данных так же, как вы прослеживаете происхождение воды.
Figure 5-11 показывает IBM Data Factory, которую IBM использует для отслеживания происхождения данных для своих моделей. В хранилище данных буквально десятки слоев деталей, где хранятся все эти метаданные. В этом примере показаны детали конкретного набора данных (используется несколько наборов данных для создания обучающего набора данных), источники, составляющие этот набор (все связаны), модели, которые построены с использованием этого набора данных, и многое другое.
Figure 5-11
Figure 5-11. Часть происхождения набора данных, использованного при обучении
Карты моделей также критически важны. Они будут демонстрировать конвейер обучения, использованные наборы данных (в то время как Figure 5-11 демонстрирует данные внутри набора данных), действия конвейера и многое другое. Вы можете думать о них как о этикетках с информацией о питании для вашего ИИ. Например, карта модели granite-3-8b-instruct прозрачно показывает архитектуру этой модели
140 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
(количество attention heads, размер встраивания и прочее нердовское), количество активных параметров (что будет иметь значение в модели Mixture of Experts), количество использованных тренировочных токенов, данные, инфраструктура, на которой была построена модель, а также этические соображения и ограничения.
Завершим этот раздел выводами. Больше доверия и объяснимости накапливается от большей прозрачности: набора данных, рецепта создания модели, где она была создана, кем создана и т. д. В финансовой отчетности эта концепция хорошо усвоена, как и в пищевой промышленности. Что скажете, ИИ?
Думая о пищевой промышленности, до конца 1960-х годов мы очень мало знали о том, что входит в продукты, которые мы покупаем. Американцы готовили большую часть еды дома, используя довольно распространенные ингредиенты. У нас не было особой необходимости знать больше. Затем пищевое производство начало развиваться. В наших продуктах стало больше искусственных добавок. В 1969 году на конференции в Белом доме было рекомендовано Управлению по санитарному надзору за качеством пищевых продуктов и медикаментов США (FDA) взять на себя новую ответственность — разработать новый способ понимания ингредиентов и пищевой ценности того, что мы едим.
Подобно появлению обработанных пищевых продуктов, появление GenAI и агентов знаменует новую эру — и то, окажется ли она для нас хорошей или плохой, будет зависеть от того, что в нее войдет. Разница заключается в стремительном темпе развития ИИ. Прошло около 20 лет с конференции FDA по продуктам питания до этикеток с информацией о питании. У ИИ нет столько времени — мы бы сказали, что у него нет и двух лет. Хорошая новость заключается в том, что бизнес может сделать первый и, возможно, самый важный шаг — выявление вредного или неприемлемого ИИ путем понимания происхождения данных.
Нормативно-правовое регулирование — Раздел, которого не должно было быть
Мы отметили, что для нас не имеет смысла вдаваться в подробности текущего состояния регулирования, потому что оно постоянно меняется и несколько фрагментировано. Сказав это, мы начали чувствовать себя немного виноватыми, поэтому подумали, что стоит уделить немного времени изложению некоторых точек зрения здесь, чтобы помочь вам ориентироваться в том, что уже существует и что на горизонте, вместо того чтобы обучать вас нюансам этого регулирования.
Важно помнить, что Акт ЕС об ИИ был введен в 2024 году и имеет далеко идущие последствия, учитывая, что мы живем в глобальной экономике. Мы считаем, что это приведет к тому, что другие страны последуют примеру закона ЕС о GDPR. Как так? Если вы посмотрите на регулирование обработки данных в мире сегодня, компании либо должны были ему соответствовать, потому что у них были клиенты в ЕС, либо их собственные правительства были медленными или быстрыми последователями, в конечном итоге перенимая многие лучшие практики из этого закона. Это не отличается от эффекта распространения технологий, который мы видим, когда многие технологии, которые вы используете сегодня, родились в армии, игровой индустрии, социальных сетях, и еще одна, которую мы оставим из нашего списка. Мы уверены, что регулирование вокруг ИИ только усилится по мере возникновения опасений, связанных со справедливой деловой практикой, мошенничеством, авторским правом, гражданскими свободами,
Нормативно-правовое регулирование — Раздел, которого не должно было быть | 141
конфиденциальностью, потерей рабочих мест, национальной безопасностью и многим другим, что попадает в руки правительств. Хотя мы не можем предсказать будущее — например, новое правительство США, которое вступило в должность в начале 2025 года, имеет иную точку зрения, чем предыдущее — мы уверены, что внимание только усилится. Будьте уверены, если вы не готовы к постоянным изменениям, у вашей организации возникнут серьезные проблемы с внедрением ИИ без комплексной, настраиваемой системы управления.
Что будет дальше
США обладают самой большой экономикой в мире. И хотя многие скажут, что регулирование вокруг исполнительного указа Байдена (EO) 14110 о безопасности ИИ зашло недостаточно далеко, существует множество уровней правительства США, работающих над всеми видами нормативных защит и политик, пытающихся сбалансировать инновации, но обуздать вред от ИИ. Проблема с EO в том, что, хотя они действуют как закон, они могут быть отменены новыми администрациями. Администрация президента Трампа уже отменила EO 14110, но штаты, такие как Коннектикут, Иллинойс, Техас, и многие другие работают над своими законами, чтобы сбалансировать инновации и безопасность. Муниципалитеты также разрабатывают версии местного закона Нью-Йорка 144, который мы комментировали в Главе 4.
На момент написания этой книги уже уделяется много внимания на всех уровнях правительства оценке рисков и объяснимости, связанных с тем, как обучаются БЯМ и как они достигают результатов (область, непосредственно связанная с одним из наших рычагов). Объяснимость в отношении найма, жилья, судебных решений и многого другого уже сталкивается с растущими требованиями. И если он станет законом, двухпартийный закон «Nurture Originals, Foster Art, and Keep Entertainment Safe» (NO FAKES) 2024 года затронет некоторые вопросы, упомянутые в начале этой главы.
Все это происходит не только в ЕС и США. Канада, Китай и восемь других стран Азии имеют развивающиеся (или уже существующие к моменту, когда вы прочитаете эту книгу) нормативные базы для ИИ. Десятки других стран мира последуют этому примеру. Это происходит везде.
Что регулировать — Наша точка зрения
Люди постоянно спрашивают наше мнение о том, что нужно регулировать. Это как классический вопрос о том, наполовину полон стакан или наполовину пуст. Мы думаем, что этот вопрос упускает суть — реалист знает, что рано или поздно кто-то выпьет все, что есть в стакане, и именно он будет его мыть. С учетом этого, позвольте нам поделиться нашей реалистичной точкой зрения: регулируйте *использование* ИИ, а не саму технологию ИИ. Давайте уточним: мы считаем, что ИИ нуждается в защитных ограждениях и правилах, чтобы избежать вреда для пользователей, но основное внимание должно быть уделено регулированию конкретных вариантов использования, а не подавлению инноваций технологии, которая обладает огромным потенциалом для преобразования мира.
142 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
Вдумчиво рассмотрите этот вопрос: как вы думаете, объединятся ли все страны мира и примут ли кворум обязательств по ответственному использованию ИИ при любых обстоятельствах? Оставив в стороне геополитику, тот факт, что некоторые нормативные акты имеют детализацию до уровня города или ассоциации как обязательной цели, говорит о том, что этого никогда не произойдет. Мы не думаем, что мы пессимистичны; мы просто знаем, что кто-то получит грязный стакан в руки и придется его мыть.
Да, с ИИ существует огромный потенциал для очень быстрого распространения дезинформации. ИИ может сделать дезинформацию более убедительной. Однако остановить ИИ не приведет ни к чему. Плохие игроки будут перемещаться из одной страны в другую, чтобы распространять вред, поскольку ИИ может легко пересекать границы. Мы хотели бы, чтобы правительства регулировали уровни более высокого риска, которые коррелируют со спецификой того, что ИИ пытается делать, что он может делать, или с потенциальным вредом, который он может причинить. Например, Акт ЕС об искусственном интеллекте имеет четырехуровневую систему классификации рисков ИИ: Неприемлемый, Высокий, Ограниченный и Минимальный. Каждый уровень связан со своими статьями регулирования в этом акте. Например, верхний уровень — Неприемлемый риск (Статья 5) — запрещает использование, такое как манипулирование поведением, удаленная биометрическая идентификация для правоохранительных органов, социальное скорингирование государственными органами и тому подобное. Как вы можете себе представить, нарушение этого уровня приводит к гораздо более строгим наказаниям, чем третий уровень (Ограниченный риск — Статья 52), который включает риск выдачи себя за другое лицо или обмана. Мы надеемся, что цель сосредоточится на выявлении таких «потенциально опасных» вариантов использования ИИ и на уведомлении нарушителей о том, что в случае их поимки они будут подвергнуты штрафам, взысканиям и уголовному преследованию.
И когда речь заходит о регулируемых отраслях, мы также считаем, что самый важный вопрос, который нужно задать: «Есть ли люди в цикле?» Мы верим, что люди должны быть в цикле — «спрашивать и корректировать» критически важно. Это довольно фундаментальный момент, но не все его видят. Но мы считаем, что это критически важно (особенно с агентным ИИ) и является эффективной защитой, которая сочетается с фактическим использованием этой технологии.
Управление жизненным циклом ИИ
Мы считаем, что с учетом разумного предположения, что вы хотя бы попытаетесь соблюдать все нормативные требования, которые у вас есть или будут, очевидно, что у вас возникнут проблемы с отслеживанием ваших моделей. Это не отличается от всех тех ключей шифрования, о которых мы говорили ранее. Короче говоря, вам понадобится возможность отслеживать свои модели в соответствии с нормативными стандартами в таких областях, как точность и справедливость, и вам понадобится технология, чтобы помочь вам в этом.
Например, Figure 5-12 показывает панель управления, которую мы настроили для отслеживания развертывания мультимоделей с использованием watsonx.governance. Наша панель управления дает нам быстрый обзор нашей среды. Есть БЯМ от OpenAI, IBM, Meta и других моделей, которые находятся на рассмотрении. В нашем примере у нас есть пять несовместимых моделей, требующих нашего внимания. Другие виджеты определяют варианты использования, уровни риска, места хостинга (на площадке или у гиперскейлера), ведомственное использование (отличная идея для возмещения расходов), позицию в процессе утверждения
Нормативно-правовое регулирование — Раздел, которого не должно было быть | 143
жизненного цикла и многое другое. Конечно, вы можете углубиться в эти детали, но одна из вещей, которые нам больше всего нравятся в этом инструменте, — это его способность привязывать регуляторную структуру к модели, чтобы помочь определить и управлять ею.
Выбранный вами набор инструментов должен также предоставлять возможность объяснять решения и автоматически собирать метаданные, чтобы аудиторы могли определить, как модели обучались и почему они генерировали тот или иной вывод.
Figure 5-12
Figure 5-12. Использование watsonx.governance для построения панели управления и отслеживания среды развертывания мультимоделей
Что скрывается подо всем этим
В то время как Figure 5-12 дал вам представление о мощной панели управления для управления ИИ, то, что скрывается под ней, — это фактическая оркестрация и операционные потоки, которые не дают вам упасть с обрыва. Мы привели пример дрейфа модели ранее в этой главе. Тот факт, что модели дрейфуют, подразумевает, что они требуют управления жизненным циклом. В реальности, как только вы внедряете модель в производство, она начинает устаревать. Когда вы настраиваете свою практику управления ИИ, сосредоточившись на рычагах, изложенных в этой главе, знайте, что она не должна ограничиваться отделом науки о данных. Она требует обмена информацией и принятия решений по всему предприятию, от первоначального запроса бизнес-подразделения на модель до утверждения инфраструктурных ресурсов для ее вывода, управления обучающими данными, разработки, тестирования и тонкой настройки, оценки рисков, развертывания и последующего обслуживания. Хорошие практики управления ИИ будут включать как технических, так и нетехнических заинтересованных сторон и должны не только максимально автоматизировать процесс, чтобы снизить нагрузку на отдел науки о данных, но и обеспечить доступ лиц, принимающих решения, к своевременным и актуальным данным, которые им необходимы для ускорения времени до получения ценности. Ваша платформа ИИ должна автоматически собирать метаданные, включая обучающие данные и фреймворки, использованные для построения модели, а также информацию об оценке по мере продвижения модели от запроса на вариант использования к разработке, тестированию и развертыванию. Эти данные должны быть доступны утверждающим лицам с помощью
144 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
каталога с возможностью поиска и управления, обеспечивая лицам, принимающим решения, полную картину происхождения и производительности модели.
Пример сквозного управляемого процесса
Если у вас есть правильные инструменты и управление жизненным циклом, тогда у вас есть шанс внедрить сквозной управляемый процесс ИИ, который выглядит примерно так:
- Как только предложение модели прошло через соответствующий процесс утверждения, в вашем инвентаре моделей создается запись о модели. Эта запись постоянно обновляется новой информацией.
- Разработчики моделей используют свои инструменты и выбранные модели для создания решений ИИ. Обучающие данные и метрики автоматически собираются и сохраняются в записи модели (при условии, что поставщик предоставляет эту информацию — вот почему вы хотите открытые модели). Также может быть сохранена пользовательская информация.
- При оценке предпроизводственной модели на точность, дрейф и предвзятость собираются и синхронизируются метаданные производительности.
- Модель просматривается и утверждается для производства.
- Модель развертывается там, где вы решили ее развернуть (на площадке, на периферии, в облаке), и снова собираются и синхронизируются соответствующие метаданные.
- Наконец, производственная модель постоянно мониторится, и собираются и синхронизируются данные о производительности. Панель управления (подобная той, что на Figure 5-12) предоставляет полный обзор показателей производительности для всех моделей (независимо от поставщика), позволяя заинтересованным сторонам проактивно выявлять любые проблемы и реагировать на них.
Завершение главы
Один из отцов-основателей США (и его четвертый президент), Джеймс Мэдисон, однажды сказал: «Обращение доверия лучше, чем обращение денег». Его мысль заключалась в том, что важно не только обращение богатства, но и лежащее в основе доверие и уверенность, поддерживающие социальные, политические и экономические системы. С тем местом, которое GenAI и агенты начинают занимать в истории, он, безусловно, добавил бы это в свой список.
Действительно, культура большинства компаний рассматривает многие темы, изложенные в этой главе, как типичное регуляторное соответствие и по умолчанию придерживается подхода «минимум усилий для соответствия». Темы, рассмотренные в этой главе, могут быть перепрофилированы для других выгод и ускорения других путей. Мы не можем не почувствовать, что вас что-то беспокоит из предыдущего списка — мы сказали «шанс». Почему мы так сказали? Потому что управление — это культура, технология помогает вам внедрить эту культуру. Но всегда помните: *ИИ, которому доверяют люди, — это ИИ, который будут использовать*.
Завершение главы | 145
Мы осознаем, что в этой главе было охвачено много материала, для которого было выделено недостаточно места. Тем не менее, мы надеемся, что у вас сложилось понимание вещей, о которых вам нужно узнать больше. А что касается обучения, то именно туда мы и направимся дальше.
146 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ