Глава 1: Фреймворки глубокого обучения
Глубокое обучение, пожалуй, является самым популярным аспектом ИИ, особенно когда речь идет о приложениях в области науки о данных (DS). Но что именно представляют собой фреймворки глубокого обучения, и как они связаны с другими терминами, часто используемыми в ИИ и науке о данных?
В данном контексте «фреймворк» относится к набору инструментов и процессов для разработки, тестирования и, в конечном итоге, развертывания определенной системы. Большинство систем ИИ сегодня создаются с использованием фреймворков. Когда разработчик скачивает и устанавливает фреймворк на свой компьютер, он обычно сопровождается библиотекой. Эта библиотека (или пакет, как его часто называют в высокоуровневых языках) будет скомпилирована на языках программирования, поддерживаемых фреймворком ИИ. Библиотека выступает как прокси для фреймворка, делая его различные процессы доступными через серию функций и классов на используемом языке программирования. Таким образом, вы можете делать все, что позволяет фреймворк, не выходя из среды программирования, где находятся остальные ваши скрипты и данные. Поэтому, для всех практических целей, эта библиотека и есть фреймворк, даже если фреймворк может проявляться и на других языках программирования. Таким образом, фреймворк, поддерживаемый как Python, так и Julia, может быть доступен через любой из этих языков, делая выбор языка вопросом предпочтения. Поскольку обеспечить функционирование фреймворка на другом языке является сложной задачей для создателей фреймворка, зачастую возможности, которые они предоставляют для языков, совместимых с этим фреймворком, довольно ограничены.
Но что такое система? Вкратце, система — это автономная программа или скрипт, предназначенный для выполнения определенной задачи или набора задач. В контексте науки о данных система часто соответствует модели данных. Однако системы могут включать функции, выходящие за рамки просто моделей, такие как процесс ввода/вывода или процесс преобразования данных.
Термин модель подразумевает математическую абстракцию, используемую для представления реальной ситуации в упрощенной, более управляемой форме. Модели в DS оптимизируются посредством процесса, называемого обучением, и валидируются посредством процесса, называемого тестированием, прежде чем они будут развернуты.
Еще один термин, который часто появляется вместе с этими терминами, — методология, которая относится к набору методов и теории, лежащей в основе этих методов, для решения определенного типа проблемы в определенной области. Различные методологии часто ориентированы на различные приложения/цели.
Легко понять, почему фреймворки являются своего рода знаменитостями в мире ИИ. Они помогают ускорить аспект моделирования в конвейере данных и значительно упрощают инженерию данных, необходимую для моделей глубокого обучения. Это делает фреймворки ИИ отличным решением для компаний, которые не могут позволить себе целую команду специалистов по данным, или предпочитают расширить возможности и развивать имеющихся специалистов по данным.
Эти системы довольно просты, но не совсем "подключи и работай". В этой главе мы рассмотрим полезность моделей глубокого обучения, их ключевые характеристики, как они используются, их основные приложения и методологии, которые они поддерживают.
О системах глубокого обучения
Глубокое обучение (DL) — это подмножество ИИ, которое используется для прогнозной аналитики, применяя систему ИИ, называемую искусственной нейронной сетью (ANN). Прогнозная аналитика — это группа методологий науки о данных, связанных с прогнозированием определенных переменных. Это включает различные методы, такие как классификация, регрессия и т. д. Что касается ANN, это умная абстракция человеческого мозга, в гораздо меньшем масштабе. ANN удается аппроксимировать каждую функцию (отображение), которая была опробована на них, что делает их идеальными для любой задачи, связанной с анализом данных. В науке о данных ANN категоризируются как методологии машинного обучения.
Основной недостаток систем глубокого обучения заключается в том, что они представляют собой «черные ящики». Чрезвычайно сложно – практически невозможно – точно выяснить, как происходят их предсказания, поскольку поток данных в них чрезвычайно сложен.
Глубокое обучение обычно включает большие ANN, которые часто специализируются
для конкретных задач. Сверточные нейронные сети (CNN) ANN, например, лучше подходят для обработки изображений, видео и аудиопотоков данных. Однако все системы глубокого обучения имеют схожую структуру. Она включает элементарные модули, называемые нейронами, организованные в слои, с различными связями между ними. Эти модули могут выполнять некоторые базовые преобразования (обычно нелинейные), когда данные проходят через них. Поскольку существует множество потенциальных связей между этими нейронами, организовав их структурированным образом (подобно тому, как реальные нейроны организованы в сеть в мозговой ткани), мы можем получить более надежную и функциональную форму этих модулей. Вот что такое искусственная нейронная сеть, если вкратце.
В общем, фреймворки глубокого обучения включают инструменты для построения систем глубокого обучения, методы их тестирования и различные другие процессы извлечения, преобразования и загрузки (ETL); при совместном использовании эти компоненты фреймворка помогают беспрепятственно интегрировать системы глубокого обучения с остальной частью вашего конвейера. Мы рассмотрим это более подробно далее в этой главе.
Хотя системы глубокого обучения имеют некоторое сходство с системами машинного обучения, определенные характеристики делают их достаточно отличительными. Например, обычные системы машинного обучения, как правило, проще и имеют меньше вариантов для обучения. Системы глубокого обучения заметно более сложны; каждая из них имеет набор алгоритмов обучения, а также несколько параметров, касающихся архитектуры систем. Это одна из причин, по которой мы считаем их отдельным фреймворком в науке о данных.
Системы глубокого обучения также, как правило, более автономны, чем их аналоги в машинном обучении. В некоторой степени системы глубокого обучения могут выполнять собственную инженерию признаков. Более традиционные системы требуют более тонкой настройки набора признаков и иногда требуют уменьшения размерности для достижения приемлемых результатов.
Кроме того, обобщение традиционных систем машинного обучения при предоставлении дополнительных данных, как правило, не улучшается так сильно, как у систем глубокого обучения. Это также одна из ключевых характеристик, которая делает системы глубокого обучения предпочтительным вариантом при работе с большими данными.
Наконец, системы глубокого обучения требуют больше времени и вычислительных ресурсов для обучения по сравнению с традиционными системами машинного обучения. Это связано с их более сложной функциональностью. Однако, поскольку работа систем глубокого обучения легко распараллеливается, современная вычислительная архитектура, а также облачные вычисления, приносят системам глубокого обучения наибольшую пользу по сравнению с другими методами прогнозной аналитики
системы.
Как работают системы глубокого обучения
По своей сути все фреймворки глубокого обучения работают аналогично, особенно когда речь идет о разработке сетей глубокого обучения. Во-первых, сеть глубокого обучения состоит из нескольких нейронов, организованных в слои; многие из них связаны с другими нейронами в других слоях. В простейшей сети глубокого обучения связи происходят только между нейронами в смежных слоях.
Первый слой сети соответствует признакам нашего набора данных; последний слой соответствует его выходным данным. В случае классификации каждый класс имеет свой собственный узел со значениями узла, отражающими уверенность системы в принадлежности точки данных к этому классу. Слои в середине содержат некоторую комбинацию этих признаков. Поскольку они не видны конечному пользователю сети, их описывают как скрытые (см.Рисунок 1).
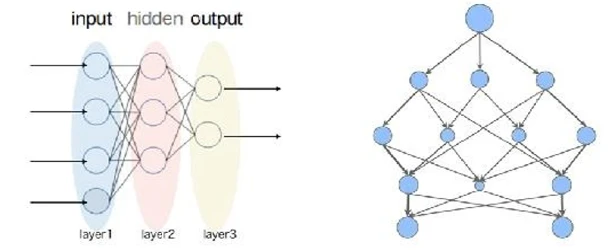
Рисунок 1
Связи между узлами взвешиваются, указывая вклад каждого узла в узлы следующего слоя, с которым он связан. Веса изначально рандомизированы при создании объекта сети, но уточняются по мере обучения ANN.
Более того, каждый узел содержит математическую функцию, которая создает преобразование полученного сигнала до того, как он будет передан на следующий слой. Это называется передаточной функцией (также известной как функция активации). Наиболее известной из них является сигмоидная функция, но существуют и другие, такие как softmax, tanh и ReLU. Мы углубимся в них подробнее чуть позже.
Кроме того, каждый слой имеет узел смещения (bias node), который является константой, которая появляется неизмененной на каждом слое. Как и у всех других узлов, у узла смещения есть вес, прикрепленный к его выходу. Однако у него нет передаточной функции. Его
взвешенное значение просто добавляется к другим узлам, с которыми он связан, во многом подобно тому, как константа с добавляется к модели регрессии в статистике. Присутствие такого члена уравновешивает любое смещение, которое неизбежно вносят другие члены в модель, гарантируя, что общее смещение в модели минимально. Поскольку тема смещения очень сложна, мы рекомендуем вам ознакомиться с некоторыми внешними ресурсами4, если вы с ней не знакомы.
После того как преобразованные входные данные (признаки) и смещения достигают конца сети глубокого обучения, они сравниваются с целевой переменной. Неизбежно возникающие различия передаются обратно различным узлам сети, и веса соответствующим образом изменяются. Затем весь процесс повторяется до тех пор, пока погрешность выходных данных не окажется в пределах определенного заранее заданного уровня, или до достижения максимального числа итераций. Итерации этого процесса часто называют эпохами обучения, и весь процесс тесно связан с используемым алгоритмом обучения. Фактически, количество эпох, используемых для обучения сети глубокого обучения, часто устанавливается как параметр и играет важную роль в производительности ANN.
Все данные, поступающие в нейрон (через связи с нейронами предыдущего слоя, а также узлом смещения), суммируются, а затем к сумме применяется передаточная функция, так что поток данных из этого узла равен y = f(Σ(wixi + b)), где wi — вес узла i предыдущего слоя, а xi — его выходные данные, а b — смещение этого слоя. Кроме того, f() — это математическое выражение передаточной функции.
Этот относительно простой процесс лежит в основе каждой ANN. Процесс эквивалентен тому, что происходит в системе перцептрона — рудиментарной модели ИИ, которая эмулирует функцию одного нейрона. Хотя система перцептрона никогда не используется на практике, это самый основной элемент ANN и первая система, созданная с использованием этой парадигмы.
Функция одного нейрона — это, по сути, одно, предопределенное преобразование имеющихся данных. Это можно рассматривать как своего рода мета-признак фреймворка, поскольку он принимает определенный вход x и после применения (обычно нелинейной) функции f() к нему, x преобразуется во что-то другое, что является выходным значением нейрона y.
В большинстве случаев один единственный мета-признак будет ужасно предсказывать целевую переменную, но несколько из них на нескольких слоях могут работать вместе довольно эффективно – независимо от того, насколько сложным является отображение исходных признаков на целевую переменную. Недостатком является то, что такая
система может легко переобучаться, поэтому обучение ANN не заканчивается до тех пор, пока ошибка не станет минимальной (меньше заданного порога).
Это самое рудиментарное описание сети глубокого обучения подходит для сетей типа многослойный перцептрон. Конечно, существует несколько вариантов, выходящих за рамки этого типа. CNN, например, содержат специализированные слои с огромным количеством нейронов, в то время как RNN имеют связи, которые возвращаются к предыдущим слоям. Кроме того, некоторые алгоритмы обучения включают прореживание узлов сети, чтобы гарантировать отсутствие переобучения.
После обучения сеть глубокого обучения может быть использована для составления прогнозов по любым данным, аналогичным данным, на которых она обучалась. Более того, ее способность к обобщению достаточно хороша, особенно если данные, на которых она обучается, разнообразны. Более того, большинство сетей глубокого обучения довольно устойчивы к зашумленным данным, что иногда помогает им достичь еще лучшего обобщения.
Что касается задач классификации, производительность системы глубокого обучения повышается благодаря границам классов, которые она создает. Хотя многие традиционные системы машинного обучения создают прямолинейные ландшафты границ (например, прямоугольники или простые кривые), система глубокого обучения создает более сложную линию вокруг каждого класса (напоминающую границы определенных округов в США). Это происходит потому, что система глубокого обучения пытается уловить каждую частицу сигнала, чтобы совершать меньше ошибок при классификации, повышая свою исходную производительность. Конечно, это очень сложное отображение классов делает интерпретацию результатов очень трудной, если не невыполнимой, задачей. Подробнее об этом позже в этой главе.
Основные фреймворки глубокого обучения
Знание нескольких фреймворков глубокого обучения дает вам лучшее понимание области ИИ. Вы не будете ограничены возможностями конкретного фреймворка. Например, некоторые фреймворки глубокого обучения ориентированы на определенный язык программирования, что может стать проблемой, поскольку языки приходят и уходят. В конце концов, в технологиях все меняется очень быстро, особенно когда речь идет о программном обеспечении. Какой лучший способ защитить себя от любых неприятных развитий, чем иметь разнообразный портфель знаний в области глубокого обучения?
Основные фреймворки глубокого обучения включают MXNet, TensorFlow и Keras. Pytorch и Theano также играли важную роль, но в настоящее время они не так мощны или универсальны, как вышеупомянутые фреймворки, на которых мы сфокусируемся в этой книге. Также, для тех, кто увлекается языком Julia, существует фреймворк Knet, который, насколько нам известно, является единственным фреймворком глубокого обучения, написанным в основном на высокоуровневом языке (в данном случае Julia). Вы можете узнать о нем подробнее в его репозитории на Github.5
TensorFlow, вероятно, самый известный фреймворк глубокого обучения, отчасти потому, что он разработан Google. Как таковой, он широко используется в отрасли, и существует множество курсов и книг, посвященных ему. В Главе 4 мы углубимся в него.
Keras – это высокоуровневый фреймворк; он работает поверх TensorFlow (а также других фреймворков, таких как Theano). Его простота использования без потери гибкости или мощности делает его одной из любимых библиотек глубокого обучения сегодня. Любой энтузиаст науки о данных, который хочет погрузиться в мир глубокого обучения, может начать использовать Keras с относительно небольшими усилиями. Более того, бесшовная интеграция Keras с TensorFlow, а также официальная поддержка от Google, убедили многих в том, что Keras станет одним из долговечных фреймворков для моделей глубокого обучения, а его соответствующая библиотека будет поддерживаться. Мы подробно рассмотрим его в Главе 5.
Основные языки программирования глубокого обучения
Как набор техник, глубокое обучение является агностичным к языку; любой компьютерный язык потенциально может быть использован для применения его методов и построения его структур данных (сетей глубокого обучения), даже если каждый фреймворк глубокого обучения фокусируется только на определенных языках. Это связано с тем, что практичнее разрабатывать фреймворки, совместимые с определенными языками, при этом некоторые языки программирования используются чаще других, например Python. Тот факт, что определенные языки более широко используются в науке о данных, также играет важную роль в выборе языка. Кроме того, глубокое обучение сегодня является скорее фреймворком
науки о данных, поэтому он преимущественно продается сообществу науки о данных как часть машинного обучения (МL). Вероятно, это способствует путанице в отношении того, что сегодня представляют собой МL и ИИ.
Из-за этого язык, доминирующий в области DL, - это Python. Это также причина, по которой мы используем его в части этой книги, посвященной DL. Это также один из самых простых языков для изучения, даже если вы никогда раньше не программировали. Однако, если вы используете другой язык в своей повседневной работе, существуют фреймворки DL, поддерживающие другие языки, такие как Julia, Scala, R, JavaScript, Matlab и Java. Julia особенно полезна для такого рода задач, так как является высокоуровневой (как Python, R и Matlab), но также очень быстрой (как любой низкоуровневый язык, включая Java).
Кроме того, почти все фреймворки глубокого обучения поддерживают C / C++, поскольку они обычно написаны на C или его объектно-ориентированном аналоге. Обратите внимание, что все эти языки получают доступ к фреймворкам глубокого обучения через API, которые принимают форму пакетов на этих языках. Поэтому, чтобы использовать фреймворк глубокого обучения в среде вашего любимого языка, вы должны ознакомиться с соответствующим пакетом, его классами и его различными функциями. Мы проведем вас через все это в главах 3-5 этой книги.
Как использовать фреймворки глубокого обучения
Фреймворки глубокого обучения приносят пользу практикам ИИ и DS различными способами. Наиболее важные процессы, приносящие пользу, включают процессы ETL, построение моделей данных и развертывание этих моделей. Помимо этих основных функций, фреймворк глубокого обучения может предложить другие вещи, которые специалист по данным может использовать для облегчения своей работы. Например, фреймворк может включать некоторую функциональность визуализации, помогая создавать красивые графики для использования в отчете или презентации. Таким образом, лучше всего изучить документацию каждого фреймворка, ознакомиться с его возможностями, чтобы использовать их в своих проектах по науке о данных.
Процессы ETL
Фреймворк глубокого обучения может быть полезен при извлечении данных из различных источников,
таких как базы данных и файлы. Это довольно трудоемкий процесс, если выполняется вручную, поэтому использование фреймворка очень выгодно. Фреймворк также выполнит некоторое форматирование данных, чтобы вы могли начать использовать их в своей модели без особой инженерии данных. Однако выполнение некоторой собственной обработки данных всегда полезно, особенно если у вас есть некоторые доменные знания.
Построение моделей данных
Основная функция фреймворка глубокого обучения - позволить вам эффективно строить модели данных. Фреймворк облегчает часть проектирования архитектуры, а также все аспекты потока данных ANN, включая алгоритм обучения. Кроме того, фреймворк позволяет просматривать производительность системы по мере ее обучения, так что вы получаете представление о том, насколько вероятно переобучение.
Более того, фреймворк глубокого обучения заботится обо всех необходимых тестах до того, как модель будет протестирована на данных, отличных от тех, на которых она обучалась (новые данные). Все это делает построение и тонкую настройку модели данных глубокого обучения прямолинейным и интуитивно понятным процессом, позволяя вам сделать более обоснованный выбор в отношении того, какую модель использовать для вашего проекта в области науки о данных.
Развертывание моделей данных
Развертывание модели — это то, с чем могут справляться фреймворки глубокого обучения, ускоряя перемещение по конвейеру данных. Это снижает риск ошибок в этом критически важном процессе, одновременно облегчая простое обновление развернутой модели. Все это позволяет специалисту по данным сосредоточиться на задачах, требующих более специализированного или ручного внимания. Например, если вы (а не модель глубокого обучения) работали над инженерией признаков, у вас было бы больше понимания того, что именно входит в модель.
Методологии и приложения глубокого обучения
Глубокое обучение — это очень широкая категория ИИ, охватывающая несколько методологий науки о данных через ее различные системы. Как мы видели, для
пример, он может быть успешно использован в классификации — если выходной слой сети построен с таким же количеством нейронов, как количество классов в наборе данных. Когда глубокое обучение применяется к задачам с использованием методологии регрессии, все проще, поскольку одного нейрона на выходном слое достаточно. Обучение с подкреплением — еще одна методология, где используется глубокое обучение; вместе с двумя другими методологиями оно образует набор методов обучения с учителем, широкую методологию под зонтиком прогнозной аналитики (см. Приложение В).
Глубокое обучение также используется для уменьшения размерности, которое (в данном случае) включает набор мета-признаков, обычно разработанных системой автокодировщика (см. Приложение C для получения более подробной информации о таком типе сети глубокого обучения). Этот подход к уменьшению размерности также более эффективен, чем традиционные статистические методы, которые вычислительно дороги, когда количество признаков очень велико. Кластеризация — еще одна методология, где может использоваться глубокое обучение, с правильными изменениями в структуре ANN и потоке данных. Кластеризация и уменьшение размерности являются наиболее популярными методологиями обучения без учителя в науке о данных и предоставляют много ценности при исследовании набора данных. Помимо этих методологий науки о данных, включающих глубокое обучение, существуют и другие, которые более специализированы и требуют некоторого доменного опыта. Мы поговорим о некоторых из них подробнее позже.
Существует множество приложений глубокого обучения. Некоторые из них более устоявшиеся или общие, в то время как другие более специализированные или новые. Поскольку глубокое обучение все еще является новым инструментом, его приложения в мире науки о данных остаются в стадии разработки, поэтому оставайтесь открытыми в этом вопросе. В конце концов, целью всех систем ИИ является максимальная универсальность, поэтому список приложений будет только расти.
В настоящее время глубокое обучение используется в сложных задачах, где требуются высокоточные предсказания. Это могут быть наборы данных с высокой размерностью и/или сильно нелинейными закономерностями. В случае высокоразмерных наборов данных, которые необходимо суммировать в более компактную форму с меньшим количеством измерений, глубокое обучение является высокоэффективным инструментом для этой задачи. Кроме того, с самого начала своего создания глубокое обучение применялось к анализу изображений, звука и видео, уделяя особое внимание изображениям. Такие данные трудно обрабатывать иным образом; инструменты, использовавшиеся до глубокого обучения, могли помочь лишь в ограниченной степени, и ручная разработка этих признаков была очень трудоемким процессом.
Переходя к более нишевым приложениям, глубокое обучение широко используется в различных методах обработки естественного языка (NLP). Это включает все виды данных, связанных с повседневным текстом, таких как те, что встречаются в статьях, книгах и даже сообщениях в социальных сетях. Там, где важно выявить любое положительное или отрицательное отношение в тексте, мы используем методологию под названием «анализ настроений», которая предлагает благодатную почву для многих систем глубокого обучения. Существуют также сети глубокого обучения, которые выполняют предсказание текста, что распространено на многих мобильных устройствах и в некоторых текстовых редакторах. Более продвинутые системы глубокого обучения могут связывать изображения с подписями, сопоставляя эти изображения со словами, которые релевантны и образуют предложения. Такие продвинутые приложения глубокого обучения включают чат-ботов, в которых система ИИ как создает текст, так и понимает заданный ей текст. Кроме того, приложения, такие как суммаризация текста, также находятся под зонтиком NLP, и глубокое обучение значительно способствует им. Некоторые приложения глубокого обучения более продвинуты или специфичны для предметной области – настолько, что требуют огромного количества данных и вычислительной мощности для работы. Однако, по мере того, как вычислительная мощность становится более доступной, эти приложения станут более доступными в краткосрочной перспективе.
Оценка фреймворка глубокого обучения
Фреймворки глубокого обучения делают применение глубокого обучения в проектах по науке о данных легким и эффективным. Конечно, часть задачи заключается в выборе фреймворка для использования. Поскольку не все фреймворки глубокого обучения созданы равными, существуют факторы, которые следует учитывать при сравнении или оценке этих фреймворков.
Особенно важно количество языков, поддерживаемых фреймворком. Поскольку языки программирования особенно изменчивы в мире науки о данных, лучше всего, чтобы фреймворк глубокого обучения, который вы планируете использовать, охватывал ваши языковые основы. Более того, поддержка нескольких языков в фреймворке глубокого обучения позволяет сформировать более разнообразную команду по науке о данных, где каждый участник имеет свой специфический опыт программирования.
Вы также должны учитывать исходную производительность систем глубокого обучения, разработанных с помощью рассматриваемого фреймворка. Хотя большинство из этих систем используют один и тот же низкоуровневый язык на бэкенде, не все из них быстры. Могут быть и другие накладные расходы. Поэтому лучше всего проявить должную осмотрительность, прежде чем инвестировать время во фреймворк глубокого обучения, особенно
если ваше решение влияет на других людей в вашей организации.
Кроме того, рассмотрите процессы ETL, поддерживающие фреймворк глубокого обучения. Не все фреймворки хороши в ETL, что является неизбежным и трудоемким в конвейере науки о данных. Опять же, любые неэффективности фреймворка глубокого обучения в этом аспекте не будут рекламироваться; вы должны провести исследование, чтобы выявить их самостоятельно.
Наконец, важны пользовательское сообщество и документация вокруг фреймворка глубокого обучения. Естественно, документация фреймворка будет полезной, хотя в некоторых случаях она может оставлять желать лучшего. Если для рассматриваемого фреймворка глубокого обучения существует активное сообщество пользователей, то изучение его более эзотерических аспектов — а также решение возникающих проблем — будет проще.
Интерпретируемость
Интерпретируемость — это способность модели быть понятой с точки зрения ее функциональности и результатов. Хотя интерпретируемость часто присутствует в традиционных системах науки о данных, она является болевой точкой для каждой системы глубокого обучения. Это происходит потому, что каждая модель глубокого обучения является «черным ящиком», практически не предоставляющим объяснений того, почему она дает именно такие результаты. В отличие от самого фреймворка, чьи различные модули и их функциональность ясны, модели, разработанные с помощью этих фреймворков, представляют собой запутанные графы. Нет всеобъемлющего объяснения того, как входные данные, которые вы им подаете, преобразуются в выходные данные, которые они производят.
Хотя получение точного результата таким методом может быть заманчивым, его довольно трудно обосновать, особенно когда результаты противоречивы или имеют демографическое смещение. Причина демографического смещения, кстати, кроется в данных, поэтому никакое количество узлов смещения в сетях глубокого обучения не может это исправить, поскольку предсказания сети глубокого обучения могут быть лишь настолько хорошими, насколько хороши данные, использованные для обучения. Также тот факт, что мы понятия не имеем, как предсказания соответствуют входным данным, позволяет необнаруживаемым предвзятым предсказаниям проникать незамеченными.
Однако эта проблема недостаточной интерпретируемости может быть решена в будущем. Это может потребовать нового подхода, но если уж прогресс систем ИИ что-то демонстрирует на протяжении многих лет, так это то, что инновации
все еще возможны и что открываются новые архитектуры моделей. Возможно, у одной из новых систем глубокого обучения интерпретируемость будет одной из ключевых характеристик.
Обслуживание модели
Обслуживание необходимо для каждой модели науки о данных. Это включает обновление или даже модернизацию модели в рабочем режиме по мере появления новых данных. Альтернативно, предположения о проблеме могут измениться; в этом случае также требуется обслуживание модели. В контексте глубокого обучения обслуживание модели обычно включает переобучение сети глубокого обучения. Если переобученная модель работает недостаточно хорошо, могут быть рассмотрены более значительные изменения, такие как изменение архитектуры или параметров обучения. В любом случае, весь этот процесс в основном прямолинеен и не занимает слишком много времени.
Частота требуемого обслуживания модели зависит от набора данных и проблемы в целом. В любом случае, хорошо иметь доступ к предыдущей модели при внесении серьезных изменений, на случай, если у новой модели возникнут непредвиденные проблемы. Кроме того, весь процесс обслуживания модели может быть автоматизирован в некоторой степени, по крайней мере, в офлайн-части, когда модель переобучается по мере интеграции новых данных с исходным набором данных.
Когда использовать глубокое обучение вместо традиционных систем науки о данных
Решение о том, когда использовать систему глубокого обучения вместо традиционного метода, является важной задачей. Легко быть соблазненным новыми и захватывающими возможностями глубокого обучения и использовать его для решения всех видов задач науки о данных. Однако не все задачи требуют глубокого обучения. Иногда дополнительная производительность глубокого обучения не стоит дополнительных требуемых ресурсов. В случаях, когда традиционные системы науки о данных не справляются или не дают никаких преимуществ (например, интерпретируемость), системы глубокого обучения могут быть предпочтительнее. Сложные задачи с большим количеством переменных и случаи с нелинейными взаимосвязями между признаками и целевыми переменными отлично подходят для фреймворка глубокого обучения.
Если данных много, и основная цель — хорошая сырая производительность модели, то система глубокого обучения, как правило, предпочтительнее. Это
особенно верно, если вычислительные ресурсы не являются проблемой, поскольку система глубокого обучения требует их немало, особенно во время фазы обучения. В любом случае, хорошо рассмотреть альтернативы, прежде чем приступать к построению модели глубокого обучения. Хотя эти модели невероятно универсальны и мощны, иногда более простые системы оказываются достаточно хороши.
Резюме
- Глубокое обучение является особенно важным аспектом ИИ и нашло широкое применение в науке о данных.
- Глубокое обучение использует определенный тип системы ИИ, называемый искусственной нейронной сетью (или ANN). ANN — это графовая система, включающая серию (обычно нелинейных) операций, посредством которых исходные признаки преобразуются в несколько мета-признаков, способных более точно предсказывать целевую переменную, чем исходные признаки.
- Основными фреймворками глубокого обучения являются MXNet, TensorFlow и Keras, хотя Pytorch и Theano также играют роль в всей экосистеме глубокого обучения. Также Knet — интересный альтернативный вариант для тех, кто в основном использует Julia.
- В глубоком обучении используются различные языки программирования, включая Python, Julia, Scala, Javascript, R и C / C++. Python является самым популярным.
- Фреймворк глубокого обучения предлагает разнообразную функциональность, включая процессы ETL, построение моделей данных, развертывание и оценку моделей, а также другие функции, такие как создание визуализаций.
- Система глубокого обучения может использоваться в различных методологиях науки о данных, включая классификацию, регрессию, обучение с подкреплением, уменьшение размерности, кластеризацию и анализ настроений.
- Классификация, регрессия и обучение с подкреплением являются методологиями обучения с учителем, в то время как уменьшение размерности и кластеризация являются обучением без учителя.
- Приложения глубокого обучения включают высокоточные предсказания для сложных задач; суммирование данных в более компактную форму;
- анализ изображений, звука или видео; обработка естественного языка и анализ настроений; предсказание текста; связывание изображений с подписями; чат-боты; и суммаризация текста.
- Фреймворк глубокого обучения необходимо оценивать по различным метрикам (не только по популярности). К таким факторам относятся языки программирования, которые он поддерживает, его производительность, насколько хорошо он обрабатывает процессы ETL, надежность его документации и пользовательских сообществ, а также необходимость будущего обслуживания.
- В настоящее время не очень легко интерпретировать результаты глубокого обучения и отслеживать их до конкретных признаков (т.е. результаты глубокого обучения в настоящее время имеют низкую интерпретируемость).
- Придание большего веса производительности или интерпретируемости может помочь вам решить, является ли система глубокого обучения или традиционная система науки о данных идеальной для вашей конкретной задачи. Другие факторы, такие как количество доступных вычислительных ресурсов, также важны для принятия этого решения.
Хорошую отправную точку можно найти на http://bit.ly/2vzKC30.
https://github.com/denizyuret/Knet.jl.