Был у меня недавно проект: в нем нужно было реализовать поиск похожих цветов в базе автоэмалей. База, к слову, не мелкая — около 60 тысяч записей. Пользователи — сотрудники, и им важно, чтобы всё работало шустро, без долгих загрузок и всяких «подождите, ищем».
Первая мысль, как у любого — нужен векторный поиск. Типа «найди мне ближайшие цвета по RGB или LAB пространству». Ну и естественно сразу в голове всплывает pgvector — оно на слуху, популярно, куча гайдов. Уже почти начал устанавливать, но в какой-то момент остановился и задал себе простой вопрос: «А оно мне точно надо?»
Контекст у меня был такой: база у меня на PostgreSQL, но всё приложение — внутреннее, без публичного API, и работает оно под капотом почти всё в памяти. Таблицы, с которыми постоянно работают, я подгружаю в оперативку через posix_ipc, и использую их в виде pandas DF. И вот тут я подумал: если данные уже в памяти, зачем мне вообще плодить сущности?
pgvector — это красиво, модно, но это лишняя прослойка. Это нужно ставить расширение, тащить данные обратно из базы, писать SQL-запросы, потом обрабатывать. Даже если обёртку сделать удобную — это будет ощутимо медленнее. И не просто медленнее — нужно будет юзеру показать лоадер, заставить его ждать. А я вот терпеть не могу, когда система тормозит и юзер ждёт, когда она «сообразит».
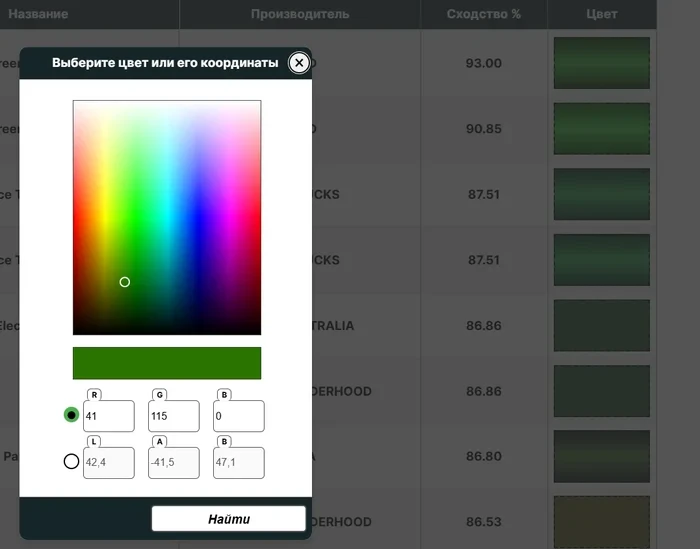
Я решил сделать проще. Раз таблица уже в DataFrame, почему бы не сделать обычный евклидов поиск по RGB координатам напрямую с помощью numpy? LAB можно тоже использовать — но чтобы не усложнять, если юзер вводит LAB, я просто прогоняю его через colorspacious в RGB. для металликов и перламутров берем только средний цвет - 45 градусов спектрофотометра.
Нам не нужно суперточности в духе "серый слегка серее", нам нужно — визуально похоже, и по ТЗ этого достаточно.
Сел, написал функцию. Получилось буквально на коленке, без всяких зависимостей кроме numpy и pandas. Работает за 0.01 секунды — и результат юзер видит моментально, как будто система заранее всё знала. Ни одного «ожидайте» на экране. Всё просто и по делу.
Вот сама функция:
def vector_search(df, r, g, b, count=30):
"""
Находит `count` ближайших цветов в датафрейме `df` к заданному цвету (r, g, b),
отсортированных по возрастанию расстояния.
колонка distance - 0 - 441.67 где 0 максимальное совпадение, 441.67 минимально
:param df: DataFrame с колонками ['r', 'g', 'b']
:param r: Красная компонента цвета
:param g: Зеленая компонента цвета
:param b: Синяя компонента цвета
:param count: Количество ближайших цветов для поиска (по умолчанию 10)
:return: DataFrame из `count` ближайших цветов, отсортированный по близости
"""
# Вычисляем евклидово расстояние до всех цветов в датафрейме
distances = np.sqrt((df['r'] - r) ** 2 + (df['g'] - g) ** 2 + (df['b'] - b) ** 2)
# Максимальная возможная дистанция (разница между (0,0,0) и (255,255,255))
max_distance = np.sqrt(255 ** 2 + 255 ** 2 + 255 ** 2)
# Вычисляем процентное совпадение
similarity = 100 * (1 - distances / max_distance)
# Копируем датафрейм, добавляем столбцы
df = df.copy()
df['distance'] = distances
df['similarity'] = round(similarity, 2) # 100% — полное совпадение, 0% — максимально возможная разница
# Сортируем и выбираем `count` ближайших цветов
return df.nsmallest(count, 'distance')
Другие статьи по этой теме:
- llms.txt как сделать и для чего
- Скорость сайта и прочие ругательства
- Что делаем в праздники? Правильно — учимся фронтенду
- Анализ загрузки сайта с sitespeed.io