Живи, умри, купи или попробуй — многое будет решено ИИ
Мы придумали это название главы, похожее на доктора Сьюза, потому что считаем, что оно прекрасно отражает причудливый и все более сложный мир, раскрывающийся неделю за неделей. Мы признаем, что наш выбор названия может быть немного преувеличенным — или, возможно, именно таким, как нужно — но он здесь, чтобы привлечь ваше внимание. В этой главе мы предложим взгляд на постоянно меняющийся ландшафт управления и ИИ: куда он движется, что стоит обдумать и почему это важно.
Это может показаться дежавю из прошлой главы, но мы повторим это снова — об этой теме могли бы, и вероятно, уже написаны целые книги. Естественно, мы не можем охватить здесь все аспекты и намеренно избегали погружения в лабиринт ИИ-специфических регуляций. Почему? Потому что они огромны и постоянно меняются. Чистый объем ошеломляет, от межгосударственных соглашений до законов по странам, правил по штатам или провинциям, и даже политики на уровне городов. Более того, к тому моменту, когда эта книга дойдет до вас, многое изменится (что еще нового, когда пишешь книгу об ИИ). По этой причине мы подумали, что лучше дать вам инструменты, которые помогут вам ориентироваться в любых регуляциях, не увязая в постоянно меняющихся мелочах.
Это настолько важно, что мы посчитали достойным повторить нашу позицию: мы считаем, что, возможно, самое главное, что лидеры должны решить, прежде чем начать свой путь (или быстро, поскольку он уже начался), — это объявить, будет ли их компания сторонником или пассивным наблюдателем, когда речь идет об ИИ. Проактивные люди, или сторонники, являются пионерами в этичном поведении, часто устанавливая стандарты для других. Напротив, пассивные наблюдатели, которые не действуют ответственно, могут непреднамеренно спровоцировать чрезмерное регуляторное воздействие
со стороны правительств, поскольку их бездействие подчеркивает необходимость надзора и контроля. Мир видел бездействие в отношении социальных сетей. И хотя выход за рамки этой книги — углубляться в хорошее и плохое в социальных сетях (есть и то, и другое), правительства бездействовали, не зная, как и что делать, пока проблема не стала слишком далеко зашедшей. Конечно, проблема с регулированием ИИ в том, что его нужно делать со «скоростью правильного», но регулирующие органы склонны двигаться со скоростью патоки.
Возможно, мы упростим наше сообщение, сославшись на знаменитую историю о Супермене. Вспомним, что он был найден младенцем на Земле своими приемными родителями, Джонатаном и Мартой Кент, которые назвали его Кларком; и лишь немногие узнали его истинную личность, Супермена. (Сказав это, его родители должны были что-то заподозрить, поскольку нашли его у обочины дороги в кратере, и он поднял машину в возрасте до одного года.) В конце концов, на Землю прилетели другие жители его родной планеты Криптон и попытались использовать аналогичные способности, чтобы захватить ее. Конечно, мы все знаем, что он победил, потому что мы сегодня здесь (шутка), но в чем суть? Его приемные родители привили Супермену сильный моральный компас. Это воспитание помогло ему использовать свои необычайные способности позитивным образом и не причинять вреда общественности или использовать их в нечестных целях. Фактически, было бы справедливо сказать, что разделительная линия между добром и злом у Супермена действительно свелась к тем основным ценностям, которым он научился с самого начала от своих родителей. Как и моральный компас Супермена, основные ценности вашей компании внесут значительный вклад в формирование положительной репутации и укрепление доверия. Тщательно подумайте о том, как вы хотите участвовать в этом мире GenAI и агентов. Как вы будете использовать свои суперспособности?
Реальность такова: по мере того, как большие языковые модели (БЯМ) становятся все более товаром, различие между поставщиками будет развиваться. Одним из ваших отличительных признаков будет ваша способность безопасно и конфиденциально использовать свои данные, чтобы стать Создателем ценности ИИ (Глава 8). Другим будет принятие подхода генеративных вычислений (интероперабельность, среды выполнения, все то, что приносит пользу миру классических вычислений) для создания большей ценности (Глава 9). Темы, которые мы охватываем в этой главе, будут третьими. Фактически, мы считаем, что одной точности ИИ будет недостаточно. Очень скоро такие элементы, как справедливое использование, прозрачность, доверие, алгоритмическая отчетность и все темы, обсуждаемые в этой главе, станут частью вашего конкурентного преимущества. Давайте посмотрим поближе.
БЯМ — вещи, о которых люди забывают упомянуть
Мир влюбился в GenAI, когда он «свайпнул вправо» (заимствуем из опыта Tinder, о котором нам рассказывали — ни у одного из авторов здесь нет такого опыта) в ChatGPT. Эта любовь с первого взгляда создала совершенно новые, демократизированные отношения с ИИ. Но, возможно, как и многие из тех, кто свайпнул вправо, они обнаружили некоторые вещи, которые им не нравились в их новом «интересе». Как и в новых отношениях, у пользователей были завышенные ожидания от того, что их новые ИИ-интересы смогут для них сделать. В конце концов, многие
114 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
1 Есть некоторые неудобные темы, которые требуют обсуждения здесь. Нам не нравится писать о них, но они важны для вашего понимания.
2 Дело: Mata v. Avianca, Inc., 1:2022cv01461, подано в Южном округе Нью-Йорка.
пожелали, чтобы кто-то заранее рассказал им о хорошем, плохом1 и БЯМ.
Дата отсечения знаний
Одну вещь следует знать о БЯМ: они могут быть невероятно дорогими в обучении. Именно поэтому существует множество техник и текущих исследований — таких как InstructLab, эффективная тонкая настройка параметров (PEFT) и многое другое — чтобы избежать полного переобучения. Проще говоря, это означает, что БЯМ не могут часто обновляться, и поэтому БЯМ поставляются с так называемой *датой отсечения знаний* (датой, когда сбор данных остановился и обучение началось). Когда GPT-4 впервые появился, его дата отсечения знаний изначально была сентябрь 2021 года. Это означало, что если вы использовали ChatGPT с этой моделью в марте 2023 года и хотели узнать, откуда взялась культовая рождественская елка в Рокфеллер-центре Нью-Йорка, вы, скорее всего, получили неверную информацию. (Знайте, что дата отсечения модели обновляется каждый раз, когда модель обновляется и выпускается.) Суть в том, что данные изначально недоступны модели после даты ее обучения. Несколько лет спустя такие техники, как генерация с извлечением (RAG), вызовы инструментов для веб-поиска (широко используемые агентами), техники тонкой настройки и другие подходы помогают решить эти проблемы для некоторых БЯМ, но важно знать, как работают БЯМ.
БЯМ могут быть мастерами придумывания
Еще одна серьезная проблема, от которой страдают БЯМ, — это то, как они могут фабриковать информацию. В отрасли это называют *галлюцинацией*. Появляются новые описания серьезности этого, но чтобы упростить, предположим, галлюцинация относится к любому случаю, когда БЯМ что-то придумывает. Некоторые из этих галлюцинаций возмутительны и явно неверны, например, когда одна БЯМ заявила, что первый черновик «Гамлета» Шекспира включал рэп-баттл. Но некоторые из них более правдоподобны. Как вы можете себе представить, если ничего не подозревающий и необученный пользователь принимает решения на основе галлюцинации, которая кажется ему (или предполагается) правильной информацией, это может иметь страшные последствия. По этой причине Глава 6 посвящена самой концепции понимания этого феномена БЯМ как критически важной части любого плана повышения квалификации. Но независимо от того, как вы это классифицируете, получение ложной информации и действия на ее основе — это опасно для всех. И есть много примеров, когда это происходило.
Один известный пример — когда команда юридической защиты полагалась на доказательства, которые цитировали фальшивое прецедентное право, сгенерированное ChatGPT, в своем юридическом заключении.2 Когда судье стало ясно, что этих цитат не существует, можно представить, как все прошло — двое
БЯМ — вещи, о которых люди забывают упомянуть | 115
юристов в итоге получили санкции. Решайте сами, что вы хотите думать о команде, которая использовала ChatGPT (один из них просто полагался на другого и не знал), но справедливо отметить в их аффидевите, что у них были скриншоты разговора с ChatGPT, где один из юристов оспаривал достоверность информации, которую он получал от БЯМ. БЯМ не только заверила этого юриста в своей надежности, но и отметила: «эти цитаты можно найти в авторитетных юридических базах данных, таких как LexisNexis и Westlaw». Это убедительная галлюцинация!
Сказав это, галлюцинированные решения не соответствовали формату юридических исследовательских баз данных, которые они цитировали, и некоторые из предыдущих цитируемых решений включали имена судей, которые не соответствовали судам, вынесшим эти решения. Другими словами, некоторая должная проверка могла бы этого избежать. (И теперь вы понимаете, почему мы подробно описали некоторые из замечательных вариантов использования БЯМ в образовании в Главе 4.) В любом случае, это идеальный пример того, что мы подразумеваем под галлюцинацией.
Как все обернулось для этих юристов? Судья, вынесший санкции, не был доволен. Оба получили небольшой штраф и оба были вынуждены написать письма своим клиентам, истцам и судьям, с которыми они работали, с поддельными решениями, подробно описывающими ситуацию и то, что они сделали. Почему оба? Судья отметил, что оба не проявили должной осмотрительности, что является основным выводом при работе с GenAI. Мы хотим знать, использовали ли они ChatGPT для написания этих писем!
Как уже упоминалось, существуют шаблоны, такие как RAG и PEFT, и другие, которые могут помочь снизить галлюцинации БЯМ, и они действительно имеют некоторый эффект. *Знайте: все модели могут галлюцинировать, даже при применении этих шаблонов*. Ваша работа здесь (подробно описанная в Главе 8) заключается в минимизации галлюцинаций и построении надежного доверия, дополненного цитатами и четким происхождением данных — поэтому GenAI и агенты, которых вы используете для бизнеса, не начинают придумывать свою собственную реальность. Как мы всегда говорим, остерегайтесь промптера!
В качестве другого примера, рассмотрим политику авиакомпании по тарифам при потере близкого человека. Один из ее клиентов взаимодействовал с чат-ботом на веб-сайте, спросил об этой политике, и ему сказали, что у него есть определенное количество дней после завершения поездки, чтобы подать заявление на возмещение расходов. После того как клиент завершил поездку, он подал заявление на возмещение, и ему было отказано. Авиакомпания указала, что ее политика по тарифам при потере близкого человека четко изложена на ее веб-сайте (так оно и было, мы проверили). Это означает, что БЯМ галлюцинировала. Недовольный ответом, клиент подал в суд на авиакомпанию и выиграл. По мнению суда, авиакомпания действительно несет ответственность за вывод БЯМ, даже когда авиакомпания в свою защиту ссылалась на то, что она не владеет БЯМ. Это то, о чем вы должны подумать при выборе вариантов использования. Понимаете, почему мы сказали вам ранее в этой книге начать с внутреннего варианта использования автоматизации? Есть так много тем для обсуждения только по этому поводу, но вам станет очень очевидно, как справиться с этой проблемой, когда вы дойдете до Главы 8.
116 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
Выбросы углерода: Климатические издержки вашего лучшего друга ИИ
Очень большая проблема с БЯМ — это огромное количество энергии, необходимое для их создания и вывода. Это проблема как стоимости, так и этики — в конце концов, каков углеродный след, оставленный жаждой мира по отношению к ИИ? Вы найдете модели размером в миллионы, миллиарды и триллионы параметров, и, как вы можете себе представить, чем больше параметров в модели, тем больше ресурсов потребляется при ее создании и работе. Подумайте об этом так: если вам нужно добраться из аэропорта Ла-Гуардия в центр Нью-Йорка, вы пойдете пешком, возьмете такси или арендуете целый туристический автобус только для себя? Ваш выбор влияет на стоимость, окружающую среду и многое другое. Как вы увидите позже, наш совет прост — не переусердствуйте.
Честно говоря, в эту новую эру ИИ требуется много энергии. Сейчас мир выписывает энергетические чеки, которые не может оплатить, и именно поэтому вы видите возобновление внимания к атомной энергии как возможному решению. Например, знаете ли вы, что, по некоторым оценкам, количество энергии, необходимое для одного запроса ChatGPT, достаточно для питания лампочки в течение 20 минут? Или что энергия, необходимая для генерации одного изображения с помощью некоторых БЯМ, может полностью зарядить мобильный телефон? Мы не уверены в точных данных, но есть более чем достаточно доказательств того, что БЯМ требуют много энергии.
БЯМ требуют не только огромной энергии, им нужно огромное количество воды — вода используется для охлаждения систем, которые создают БЯМ и управляют процессами вывода. В пригороде недалеко от Де-Мойнса (штат Айова), где расположен один из таких центров, около 20% водоснабжения используется для охлаждения компьютеров — и это происходит в то время, когда этот штат переживает одну из самых затяжных засух за десятилетия — что приводит к неустойчивому истощению водоносных горизонтов. По сути, по мере роста размера и использования ИИ его потребление ресурсов растет, создавая серьезные проблемы устойчивости.
Авторское право и судебные иски
Мы не юристы, и когда мы пытаемся понять точки зрения на добросовестное использование, авторское право, цифровые права и другие связанные темы, мы возвращаемся к тому факту, что мы не юристы. Мы скажем вам, что сейчас идет множество судебных исков по очевидным причинам — практически все БЯМ построены с использованием данных, найденных в интернете, собранных в процессе, называемом «скрейпинг» или «краулинг». Но, как вы увидите, не все интернет-источники созданы равными. А как насчет авторского права? Например, один вездесущий набор данных, используемый во многих БЯМ, — Books3. Этот набор данных содержит около 200 000 книг, текст которых был незаконно опубликован в интернете без разрешения первоначальных авторов. Несколько поставщиков моделей сейчас проходят судебные разбирательства, их обвиняют в использовании этих данных и включении их в свои БЯМ без разрешения или компенсации первоначальным авторам. Фактически, некоторые из наших книг находятся в этом наборе данных. И то же самое относится к многим другим известным авторам, таким как Стивен Кинг (ужасы), Ник Шарма (кулинария), Сара Сильверман (комедия), Нора Робертс (романы) и другие. От
БЯМ — вещи, о которых люди забывают упомянуть | 117
художественной прозы до стихотворной поэзии, как в слогане соуса Prego: «Это в нем». Но некоторые сторонники БЯМ блокируют этот (и другие) наборы данных, что говорит о культуре. Соответствует ли этот подход вашему?
Теперь о нашем (не юридическом) совете. Во-первых, решите, каким актером вы будете. Какова ваша культура? Как насчет цифровых работников, о которых вы узнали в прошлой главе? Именно так вы раскроете новые уровни производительности. Соответствует ли БЯМ, которая будет основой вашей цифровой рабочей силы, ценностям вашей компании? Например, использование БЯМ, обученной на наборах данных, таких как Books3 или The Pirate Bay (сайт BitTorrent, поддерживаемый группой по борьбе с авторским правом, которая публикует все виды аудио, видео, программного обеспечения, телепрограмм и игр), потенциально может говорить о вашей культуре. Все рекламные материалы вашей компании могут находиться в синапсах нейронной сети, ожидая активации и помогая конкуренту. Справедливо ли это? Должно ли быть так? Это часть причины, по которой мы написали Главу 8.
А как насчет людей, которые зарабатывают на жизнь и создали репутацию своим невероятным трудом? Например, Грег Рутковски известен своими захватывающими работами на тему Dungeons & Dragons (D&D). Его искусство действительно оживляет ярких персонажей D&D, захватывающие пейзажи и безудержное чувство чудес. И на то есть веская причина: он очаровал поклонников по всему миру, перенося их в мир магии, приключений и легендарных героев. К сожалению, весь магический творческий талант может быть не по силам способностям сопоставления чисел (помните, ИИ видит картинки как числовые паттерны; это не магия) современных моделей преобразования текста в изображение, которые легко переняли его уникальный стиль. И точно так же, как наши работы являются частью БЯМ сегодня, вы можете быть уверены, что его работы также являются частью какого-то набора обучающих данных. Конечно, существует и противоположная точка зрения. Если бы вы были студентом художественной школы, изучающим чудеса художника в музее, и начали рисовать в этом стиле, как бы все было иначе? Ваше восхищение шедевром Тома Томсона 1916 года «Сосна» запечатлелось в вашем мозге, и вы впоследствии рисуете маслом, передавая его многослойную текстуру, выразительные движения, драматичное кадрирование и влияние ксилографии. Разница, конечно, в том, что количество влияния, которое человек может усвоить за всю жизнь, составляет лишь миллисекунду для ИИ.
В конце концов, судебные иски ответят на вопрос, могут ли общедоступные данные использоваться законно для обучения фундаментальных моделей. Это морально правильно или неправильно? Решать вам. Мы можем представить себе день, когда вы, возможно, будете задумываться, была ли ваша модель ИИ построена на этически полученных данных, точно так же, как вы поступаете с сырьем в цепочке поставок или рабочей силой. Если вас это волнует, тогда спросите своего поставщика БЯМ, чтобы он показал вам данные, которые он использовал для обучения своей модели. Мы называем это *прозрачностью данных*, что является частью совета, который мы дадим вам позже в этой главе. Некоторые поставщики скажут вам, что не могут предоставить этот список; другие скажут вам, что это не ваше дело; а третьи покажут вам происхождение наборов данных, использованных для построения их модели, и список заблокированных наборов данных, не допущенных к обучению, таких как Books3 и The Pirate Bay. В конце концов, вы должны позволить своим усилиям подняться до того уровня намерения, которое вы хотите взять на себя в этом путешествии.
118 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
Затем исследуйте документ о возмещении убытков (для защиты вас от всех судебных исков по авторскому праву), прилагаемый к модели любого поставщика, которую вы лицензируете. Хотя все они используют одно и то же слово (возмещение), они написаны совершенно по-разному, и эти различия могут оказать существенное влияние на ваш бизнес, в зависимости от того, как все обернется. Если этот документ не длинный и его легко понять, вы, вероятно, находитесь в хорошем положении. Мы видели, как некоторые документы о возмещении убытков содержат множество внешних ссылок с запутанной и противоречивой информацией. Что бы вы ни читали, убедитесь, что вы полностью понимаете, что покрывает возмещение убытков и что вы должны сделать, чтобы возмещение не было аннулировано. С точки зрения покрытия, важно понять, покрывает ли политика возмещения убытков поставщика общедоступные материалы или интеллектуальную собственность (IP) в целом — последнее является гораздо более широкой областью покрытия. Мы видели несколько заявлений о возмещении убытков, которые *казались* покрывающими вывод модели, только для того, чтобы быть дисквалифицированными другим документом с условиями и положениями. Привлеките своих юристов, чтобы у всех было кворум относительно того, что покрывается и что нет.
А как насчет цифровой сущности?
Теперь, когда вы знаете, что для ИИ все — это просто набор чисел, и почти все — это некий числовой паттерн (танцевальные движения, письмо, даже формула помады), вы понимаете, как GenAI может создавать вещи. Представьте: сам Старина Блю Айз, Фрэнк Синатра, приглаживает волосы, щелкает пальцами, и тут БУМ! Он исполняет «Wonderwall» Oasis, как будто сам написал ее на обратной стороне коктейльной салфетки в Sands. И, честно говоря: мы все знаем, он бы справился, ведь этот swagger не ушел. (ИИ сделал это реальностью сегодня.)
Когда речь заходит об использовании ИИ, есть хорошие и плохие игроки. Хороший игрок может клонировать свой голос и объединить его с своим ИИ-созданным аватаром, чтобы масштабировать свою работу. Плохой игрок может использовать дипфейки (мы рассмотрим это позже в этой главе), чтобы совершать мошенничество, атаки на персонажей, вызывать путаницу и многое другое. Но где-то между этими крайностями есть еще кое-что, о чем вы должны подумать — как насчет вашей цифровой сущности? Как насчет всей работы, которая, независимо от авторского права, теперь является частью параметрического состава какой-то БЯМ?
Многие, вероятно, знают will.i.am как хип-хоп музыканта, продюсера и ведущего вокалиста Black Eyed Peas. Возможно, вы даже знаете его как одного из основателей наушников Beats by Dre (теперь принадлежащих Apple). Но многие, возможно, не осознают, что will.i.am прежде всего футурист, инноватор, технический предприниматель и творческий артист, который десятилетиями занимается ИИ. И чтобы доказать это, просто посмотрите первые 90 секунд официального музыкального видео на песню «Imma Be Rocking That Body», которая вышла в 2009 году и набрала более 100 миллионов просмотров. В этом видео will.i.am точно показал, как ИИ сможет создавать музыку, используя голоса и образы группы, и с невероятной точностью описал будущее ИИ, в котором мы сегодня живем.
БЯМ — вещи, о которых люди забывают упомянуть | 119
IBM и will.i.am работают вместе с 2009 года. В рамках их сотрудничества IBM объединилась с ним, когда он основал FYI.AI — платформу, которая интегрирует ИИ для улучшения пользовательской коммуникации и потребления медиа в поддержку творческого сообщества. Он также разработал и запустил Sound Drive с Mercedes-Benz, функцию, которая сейчас стандартно поставляется в каждом новом автомобиле AMG. Он также создал новаторскую радиопрограмму The FYI Show на SiriusXM, где его соведущей является личность ИИ, и недавно запустил FYI.RAiDiO, первый интерактивный персонализированный радиосервис на базе ИИ.
В наших взаимодействиях с ним мы быстро обнаружили его страсть к обучению и техническую глубину в сочетании с его способностью представлять будущее. Он поразил нас своим взглядом на цифровую сущность и владение собственными аналогово-цифровыми правами на свою музыку, что выходит далеко за рамки работы, которая могла бы быть «поднята» ИИ. Его взгляд на цифровую сущность дает представление о работе, которую нам предстоит проделать, чтобы защитить права и личности и обеспечить этичное и правильное использование ИИ, не подавляя при этом его использование и инновации. Мы считаем, что точка зрения will.i.am может дать нам схожее представление о будущем прав на IP и личность, как это было в видео 2009 года об ИИ.
Это выходит за рамки этой книги, чтобы глубоко углубляться в эту тему, но это, безусловно, поднимает еще более сложные вопросы, которые бросают вызов самой ткани идентичности в цифровую эпоху. Если поставщики БЯМ могут без разбора брать работы людей и включать их в свои модели, что это значит для результатов? Может ли кто-то начать монетизировать самую сущность другого человека — цифровую сущность (внешний вид, звук и стиль)? В какой момент инновации превращаются в эксплуатацию? Если мы сейчас не возьмем под контроль свои цифровые сущности, мы можем однажды проснуться и обнаружить, что наши мысли, голоса и даже наше творчество были захвачены и бесконечно ремикшированы в нечто, что мы больше не узнаем. Получим ли мы от этого выгоду? Получит ли кто-то другой? И по мере того, как мы спешим вернуть право собственности, алгоритмы будут просто продолжать пережевывать, без извинений повторяя: «Сегодня будет хороший вечер...», но каким-то образом мы все знаем, что оригинал был гораздо лучше.
Ваша расширяющаяся область атаки
Последний раздел может показаться отклонением от нашего обычного оптимистичного тона из-за значительного потенциала ИИ, который мы ранее подчеркивали. Однако это не предназначено для уменьшения вашего энтузиазма, а скорее для предоставления реалистичного взгляда. В конце концов, распространенной темой этой книги является важность признания как замечательного потенциала ИИ, так и его неотъемлемых ограничений. Это сбалансированное понимание необходимо для ответственного и эффективного использования ИИ. При всем этом, пора сказать вам, что чем больше вы используете ИИ в своем бизнесе, тем больше вы расширяете область атаки на свой бизнес, и тем больше векторов атаки вам нужно рассмотреть. Итак, хотя вы можете использовать ИИ для «хорошего поведения», безусловно, есть и другие, использующие его для «плохого поведения». Иными словами, хотя ИИ может использоваться в благих целях, существуют и случаи, когда он используется во вредоносных целях.
120 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
Как вы используете силу ИИ, ваша организация еще больше преобразуется в цифровой бизнес. И, как и появление веб-сайтов в раннюю эпоху веба привело к новой волне уязвимостей, демократизация ИИ приносит с собой новый набор проблем, с которыми компании должны теперь справляться, но которые они еще не совсем понимают. Ниже приведен краткий список угроз, о которых, по нашему мнению, вам следует знать.
Отравление данных
Это происходит, когда злоумышленники внедряют вредоносные и поврежденные данные в обучающие наборы данных, используемые для построения БЯМ. Некоторые из этих акторов считают себя «привратниками социальной справедливости», защищая тех, чьи данные были «украдены» для построения БЯМ. Обычно эти группы не стремятся причинить социальный вред, а скорее пытаются уменьшить полезность БЯМ или хотя бы добавить трения в процесс создания. Мы уже видим это: вы запрашиваете у своего приложения на базе ИИ идеальное сочетание гарнира к вашему кусочку чизкейка. ИИ, сбитый с толку отравленными данными, уверенно предлагает, что брокколини — идеальная гарнир к чизкейку, но ее нужно слегка обжарить с чесноком для полного впечатления; все это порождает #Cheesecake-BroccoliniChallenge. Но вот в чем дело, эти неправильные метки обычно невидимы невооруженным глазом. Потребовалось бы лишь мгновение, если бы вы увидели, что кучу собак помечены как лошади, чтобы спасти себя от неприятностей и выбросить набор данных как мусор. Инструменты для отравления данных, такие как Nightshade, помогают вносить изменения на уровне пикселей в изображения, которые невидимы для человеческого глаза... и внезапно ваша кошка Феликс становится тостером для ИИ. Когда вы рассматриваете процветающий мир открытого исходного кода, связанный с ИИ, вы получаете представление об огромном потенциале этих наборов данных для порчи, или, по крайней мере, замедления работы поставщика и траты их ресурсов, пока они пытаются выяснить, почему модель не обобщается хорошо на реальных данных.
Вы можете представить себе, как такая атака может стать злонамеренной и пугающей. Представьте, что злоумышленник с помощью социальной инженерии манипулирует набором данных, чтобы способствовать ошибочным диагнозам заболеваний. Например, в области компьютерного зрения для выявления рака кожи ИИ склонен работать хуже (мы говорим о разнице в десятки процентов) на темных оттенках кожи по сравнению со светлыми. В поисках данных представьте себе исследовательскую группу, наткнувшуюся на «отравленный» набор данных, злонамеренно неправильно маркирующий доброкачественные и злокачественные родинки для пациентов с темными оттенками кожи, для которых данных мало. Помимо очевидных потенциально разрушительных последствий, эта атака может создать социальную предвзятость и еще больше подорвать доверие и потенциал ИИ для помощи в этой области. Учитывая, что заболеваемость меланомой растет из года в год уже 30 лет, и даже если каждый американец мог бы позволить себе обратиться, дерматологов недостаточно, чтобы увидеть всех, вы видите потенциал для блага здесь, но и некоторые потенциально пугающие ситуации.
Существуют и другие способы отравления данных. Например, в БЯМ могут быть скрыты «троянские атаки с черного хода», которые запускаются определенным паттерном — например, оттенком цвета или определенными словами при запуске. В этих случаях модель ведет себя нормально, пока не будет сработан триггер. Другие атаки на данные включают внедрение выбросов, имитационные атаки,
БЯМ — вещи, о которых люди забывают упомянуть | 121
3 Ариэль Уолдман, «ФБР: Преступники используют ИИ для совершения мошенничества в более крупном масштабе», TechTarget, 4 декабря 2024 г., https://oreil.ly/7VgiB.
4 CNN, «Финансовый работник выплачивает 25 миллионов долларов после видеозвонка с дипфейком „финансового директора“», 4 февраля 2024 г., https://oreil.ly/xwZY1.
случайная путаница из-за ложных корреляций, семантическое отравление, эксплуатация перекрестного дисбаланса и многое другое.
Атаки путем внедрения промптов
В мире баз данных область SQL-инъекций хорошо изучена. Вам нужно знать, что в мире GenAI приходится иметь дело с атаками путем внедрения промптов. Многие атаки на БЯМ пытаются «гипнотизировать», взламывать или обманывать БЯМ, чтобы она делала то, что было защищено от нее. Но эти атаки путем промптинга не всегда так очевидны для БЯМ. Что если промпт (входные данные) — это видеопоток? Исследовательская группа в Китае смогла обмануть функцию автономного вождения известного производителя автомобилей, разместив белые точки на полосе встречного движения, что заставило автомобиль свернуть на неправильную полосу, думая, что это операция по удержанию полосы. Три точки, стратегически размещенные на дороге, не были очевидными атаками. Есть публичные примеры размещения кусков черной ленты на знаке STOP и обмана других модулей компьютерного зрения (плохие акторы также могут атаковать с помощью текста). Мы приведем еще несколько примеров позже в этой главе.
Атаки методом социальной инженерии и дипфейки
Они могут принимать форму атаки на ваших сотрудников или использования недобросовестными акторами GenAI для парсинга вашего веб-сайта и создания вашей сущности с целью запуска атак на ваших клиентов. Использование GenAI для фишинга и финансового мошенничества настолько распространено, что ФБР выпустило предупреждение3 об этом. Тактика включает создание обманчивых профилей в социальных сетях и использование сгенерированных ИИ поддельных сообщений и фотографий для ведения «реальных» разговоров с ничего не подозревающими жертвами. Если вы видели, насколько далеко зашла технология ИИ с голосом и видео (и как далеко она еще зайдет), явные признаки неаутентичности быстро исчезают. В качестве примера можно привести широко освещенную атаку, когда сотрудники компании были обмануты4 сгенерированными ИИ аудиозаписями, имитирующими их финансового директора, с инструкциями отправить 25 миллионов долларов на мошеннические счета. Эта афера была настолько сложной, что работник был обманут и присоединился к видеозвонку, полагая, что он общается с несколькими другими сотрудниками. В реальности, все участники были дипфейк-реконструкциями.
Это породило идею водяных знаков на контенте, созданном ИИ. Водяные знаки не новы — итальянцы использовали их в XIII веке на банкнотах, чтобы доказать подлинность, — и цифровые методы существуют уже давно. Недавно большинство крупных игроков в этой области пообещали что-то сделать. Независимо от того, являются ли эти «созданные ИИ» цифровые
122 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
5 Пит Эванс, «Пользователи Apple могут отказаться от отслеживания с помощью нового обновления программного обеспечения», CBC News, 26 апреля 2021 г., https://oreil.ly/QL2Fe.
6 Годовой отчет Acxiom Corporation по форме 10-K за финансовый год, завершившийся 31 марта 2018 г., поданный в Комиссию по ценным бумагам и биржам США, 21 мая 2018 г., https://oreil.ly/SpkKt.
подписи легко заметить или скрыты, существует множество мнений и статей, которые вы можете прочитать. Есть и другие проблемы: легче ставить водяные знаки на изображения, например, чем встраивать токены в текст. В любом случае, как и все, о чем мы говорим в этой книге, вещи будут появляться и меняться, но теперь вы знаете, на что обращать внимание.
Конфиденциальность данных
Потенциал утечки данных или их передачи огромен с GenAI и агентами. Если модель обучалась на данных, о которых вы не знаете, она может абсолютно точно выдать лично идентифицируемую информацию (PII), и, конечно, есть проблема передачи данных поставщику при взаимодействии с его БЯМ. Понимание протоколов обработки данных вашего поставщика критически важно, но так же важно создание политики для вашей компании. Например, если вы используете телефон со встроенным ИИ, один из методов, который используют поставщики для получения обратной связи, — спросить вас, как сработала их технология (будь то комментарий или опция «палец вверх» или «палец вниз»). Хотя этот поставщик может сказать вам, что не будет хранить данные вашего вывода, вам лучше внимательно посмотреть, что происходит, когда вы даете обратную связь, потому что предоставление «пальца вверх» результату создает размеченную точку данных, которая является комбинацией ваших данных и вашей обратной связи. Как вы можете себе представить, это, скорее всего, будет использоваться для дальнейшего выравнивания модели, потому что, когда вы дали обратную связь, где-то в море четырехточечного шрифта есть условия и положения, которые вы не читали, информирующие вас о том, что вы передали данные.
Конечно, возникает вопрос о PII-данных вашей компании и о том, что вы помещаете в модель. Вот почему синтетические данные (представленные в прошлой главе) сейчас являются очень актуальной темой. Короче говоря, замена реальных данных синтетическими — еще один способ подхода к защите конфиденциальности.
И хотя это выходит за рамки отведенных нам страниц для полного объяснения этой темы, достаточно сказать, что компаниям необходимо тщательно рассматривать последствия для конфиденциальности при использовании GenAI, прежде чем его развертывать.
Наконец, вы можете спросить о своих личных данных. Мы направим вас к одному из наших готовых ответов на вопрос о конфиденциальности данных и личном использовании. *Если вы не платите за услуги, очень вероятно, что вы — продаваемый продукт.* Факты5 не лгут: среднее приложение имеет шесть трекеров, единственная цель которых — сбор ваших данных и передача их третьим сторонам. Фактически, один брокер данных (идентифицированный Apple) создал 5000 категорий профилей для 700 миллионов человек!6 Компании (такие как Apple) борются с этим, но, возможно, уже слишком поздно или недостаточно — разговоры на другое время или другая книга.
БЯМ — вещи, о которых люди забывают упомянуть | 123
Кради сейчас, взламывай позже
Криптография касается каждого уголка нашего цифрового мира — от интернет-протоколов и корпоративных приложений до критической инфраструктуры и финансовых систем. Является ли это частью ландшафта угроз ИИ? Мы считаем, что да, поэтому кратко рассмотрим это здесь. Поскольку ИИ заполняет цифровой ландшафт, а цифровой труд и агенты набирают силу, все те проблемы с шифрованием конфиденциальных данных, о которых вы сегодня беспокоитесь, усугубляются.
Вам нужно уделить этому вопросу очень пристальное внимание. Не углубляясь в математику вычислений простых чисел, лежащую в основе традиционных алгоритмов шифрования, достаточно сказать, что шифрование, которое большинство использовало последние несколько десятилетий, построено на невозможности выполнить огромный объем работы, чтобы выяснить математическую задачу с простыми числами, в отличие от того, что вы должны наткнуться на нее случайно. Проще говоря, в мире недостаточно вычислительной мощности, чтобы «убить это железом» (KIWI) и получить доступ к зашифрованным данным, вычислив правильную математику простых чисел (актуальная тема, учитывая, что Prime Target от Apple — одно из самых популярных шоу в 2025 году). Квантовые вычисления меняют (или изменят) это из-за того, для каких вариантов использования они хорошо подходят (и будут подходить). Вы можете быть довольно уверены, что существуют плохие акторы, которые уже перехватили зашифрованные данные, к которым у них сегодня нет надежды получить доступ, с расчетом на то, что они смогут прочитать их завтра — кради сейчас, взламывай позже.
Необходимость внедрения квантово-защищенных решений является срочной. Чтобы опережать квантово-связанные риски кибербезопасности, организациям необходимо обеспечить адаптивность, соответствие и устойчивость своих систем. Вероятно, вам предстоит некоторая работа в этой области. Вам было бы полезно осознать, что большинство компаний относятся к безопасности как к кост-центру, но когда речь идет о цифровом опыте, который предоставляет GenAI, вам нужно заставить людей думать о безопасности как о генераторе ценности.
В качестве совета для начала мы предложили вам дорожную карту, которая поможет вам перейти к квантовой безопасности, на Figure 5-1.
Вы начинаете путешествие на Figure 5-1 с миссии — узнать, что у вас есть (не отличается от хорошей стратегии ИА). Классифицируйте данные по уровням ценности и поймите свои требования к соответствию — не забудьте включить данные, которые вы будете использовать для направления своих моделей. Теперь у вас есть инвентаризация данных.
124 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
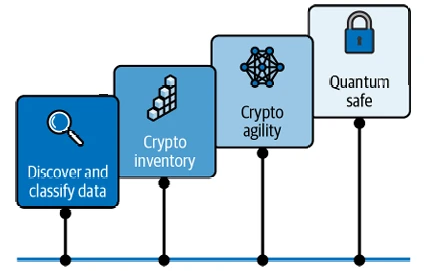
Figure 5-1
Figure 5-1. Вехи на пути к квантовой безопасности
Теперь, когда вы классифицировали свои данные, вам нужно определить, как эти данные в настоящее время зашифрованы, а также другие способы использования криптографии, чтобы создать крипто-инвентарь, который поможет вам во время планирования миграции. Подумайте, насколько широко распространена эта проблема, выходящая далеко за рамки GenAI. Большинство компаний очень плохо знают, какие методы шифрования используются в их активах. Новые приложения, возможно, были созданы с использованием квантово-защищенных алгоритмов шифрования, в то время как старые — нет. Убедитесь, что ваш крипто-инвентарь включает такую информацию, как протоколы шифрования, симметричные и асимметричные алгоритмы, длины ключей, поставщики криптографии и т. д.
Так же, как и ваше путешествие с ИИ, переход к квантово-защищенным стандартам будет многолетним путешествием, по мере того как стандарты развиваются, а поставщики переходят на квантово-защищенные технологии. Используйте гибкий подход и будьте готовы к замене. Внедрите гибридный подход, используя как классические, так и квантово-защищенные криптографические алгоритмы. Это обеспечивает соответствие текущим стандартам, одновременно добавляя квантово-защищенную защиту.
И, наконец, перейдите к квантовой безопасности, заменив уязвимую криптографию квантово-защищенной криптографией. На этом этапе вы защитили свою организацию от атак как классических, так и квантовых компьютеров, помогая обеспечить защиту ваших информационных активов даже в эпоху крупномасштабных квантовых вычислений и будущей концепции генеративных вычислений, которую мы представим в Главе 9.
Рычаги хорошего поведения для всего, что связано с ИИ
В этом разделе мы дадим вам несколько рычагов, о которых мы хотим, чтобы вы подумали, начиная с самого начала, для любого проекта ИИ, за который вы беретесь. Если вы уже начали, придумайте способы, как начать использовать эти рычаги сейчас — вы поблагодарите нас позже. В совокупности эти рычаги
Рычаги хорошего поведения для всего, что связано с ИИ | 125
7 Под «этикой» мы подразумеваем все, что входит в обеспечение управления, объяснимости, добросовестного использования, конфиденциальности и прочего в отношении ваших проектов ИИ — хорошее поведение. Мы не будем подробно останавливаться на всех этических соображениях в этой главе, но вы обнаружите, что почти все они могут быть отнесены к одному из рычагов, которые мы представляем вам в этом разделе.
охватывают большинство вещей, о которых вы должны думать с точки зрения этики7 для ваших проектов ИИ. Помните руководящий принцип, который мы будем повторять на протяжении всей книги: *ИИ, которому доверяют люди, — это ИИ, который будут использовать*.
Вот рычаги:
Справедливость
Системы ИИ должны использовать обучающие данные и модели, свободные от предвзятости, чтобы избежать несправедливого отношения к определенным группам. Сказав это, предвзятость практически невозможно полностью устранить из любой системы, поэтому всегда добавляйте дополнительные защиты и гарантии для оценки результатов модели и их коррекции по мере необходимости для улучшения справедливости результатов (ИИ может помочь ИИ здесь).
Надежность
Системы ИИ должны быть безопасными и защищенными, а также защищенными от взлома или компрометации данных, на которых они обучены. Это защищает от атак при построении и выводе, обеспечивая безопасные и уверенные результаты.
Объяснимость
Системы ИИ должны предоставлять решения или предложения, которые могут быть понятны разработчикам и пользователям (даже нетехническим специалистам). По сути, объяснимость помогает реализовать подотчетность — вы должны создавать системы ИИ таким образом, чтобы непредвиденные результаты можно было отследить и отменить, если требуется.
Происхождение данных
Системы ИИ должны включать подробности их разработки, развертывания, используемых данных и обслуживания, чтобы их можно было аудитировать на протяжении всего жизненного цикла. Вы обнаружите всяческую синергию между использованием этого рычага и объяснимостью, потому что лучший способ способствовать прозрачности, построению доверия и объяснению вещей — это раскрытие информации. И хотя мы явно не называем это в деталях ниже, предоставление людям возможности знать, когда они взаимодействуют с ИИ, является частью нашего определения прозрачности.
Справедливость — честная игра в эпоху ИИ
Мы не паникуем из-за того, что роботы на базе ИИ захватывают наш мир, но мы своими глазами видели опасности, связанные с принятием автоматизированных решений на основе ненадежных данных, которые не были курированы. Мы вступаем в мир, где есть хороший шанс, что мы можем непреднамеренно автоматизировать неравенство в масштабе.
126 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
8 Стивен Джонс, «Автоматизированные системы найма „скрывают“ кандидатов от рекрутеров — как мы можем это остановить?», World Economic Forum, 14 сентября 2021 г., https://oreil.ly/2C-dn.
9 Роберт Бартлетт и др., «Дискриминация потребительского кредитования в эпоху FinTech», (рабочий документ, Университет Калифорнии, Беркли, 2019 г.), https://oreil.ly/C5iaB.
Системы ИИ должны использовать обучающие данные и модели, свободные от предвзятости, чтобы избежать несправедливого отношения к определенным группам. Сказав это, предвзятость практически невозможно устранить из любой системы, поэтому всегда добавляйте дополнительные защиты и гарантии для оценки результатов модели и их коррекции по мере необходимости для улучшения справедливости результатов (ИИ может помочь ИИ здесь).
Вы, безусловно, слышали хотя бы одну ужасную историю использования ИИ, который пошел не так. Например, существует множество исследований, которые предполагают, что около 27 миллионов работников отсеиваются из вакансий с помощью технологии рекрутинга на базе ИИ.8 Также есть оценки, что до 75% работодателей прямо или косвенно полагаются на эту технологию для своих кадровых нужд. Большая часть заблокированных соискателей — это опекуны, иммигранты, вышедшие из тюрьмы и переехавшие супруги — это несправедливо. От определения зарплаты женщин, возвращающихся на рынок труда после декретного отпуска, до прогнозирования рецидивизма на базе ИИ, которое влияет на приговоры, историй много.
Помните, ИИ не может научиться ничему, чего нет в данных, которые вы ему предоставляете. Он будет исключительно усваивать любые предвзятости, закодированные в данных, на которых он обучается, поэтому важно помнить, что просто потому, что вы используете ИИ, у которого нет человеческих эмоций и потенциальных предрассудков, не означает, что он будет просто справедлив.
Предвзятость здесь, предвзятость там, предвзятость данных везде
Один из самых важных моментов, на который нужно обратить внимание, — это предвзятость в данных, используемых для обучения вашей модели, и данных, которые вы будете использовать для ее управления. Например, DALL-E — который вы можете использовать самостоятельно, но он также изначально встроен в ChatGPT — это изобретение OpenAI, генерирующее невероятные изображения из текста. (Его любопытное название происходит от фамилии аниматора, работавшего над мультфильмом WALL-E, сенсацией Pixar 2008 года.) В его более ранних версиях, когда они начали отфильтровывать более сексуальный контент из обучающих данных, ИИ внезапно стал включать меньше женщин в запросы на общие изображения — это форма предвзятости стирания, но она также говорит о многих других волнующих темах, выходящих за рамки этой книги.
Думая о том, как ИИ используется для помощи банкам в принятии решений о кредитовании, откуда взялись эти данные? Сколько из них было собрано из интернета и связано со всевозможной имплицитной и эксплицитной предвзятостью? Сколько пришло из эпохи, когда решения о кредитовании принимались лично, и которые могли содержать предвзятость? Например, исследование Университета Калифорнии, Беркли, показало, что процентные ставки для меньшинств могут быть на 6–9 базисных пунктов выше, чем для их белых коллег.9 Правда в том, что может быть слишком поздно выявить предвзятость в данных, лежащих в основе БЯМ, которую вы используете сегодня. Прозрачность используемого набора данных для обучения, безусловно, поможет, но вам необходим подход после внедрения для мониторинга предвзятости и новой предвзятости, которая вводится по мере дрейфа модели от справедливости.
Рычаги хорошего поведения для всего, что связано с ИИ | 127
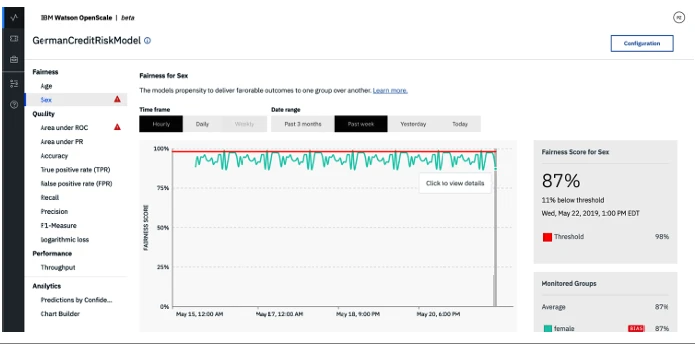
Figure 5-2
Дрейф измеряет, как точность модели со временем снижается. Он может быть вызван изменением входных данных модели (возможно, вы тонко настраиваете модель), что приводит к ухудшению производительности модели. Также может быть, что изменилась реальность, и веса модели основаны на истории. Например, у Zillow была многообещающая модель ИИ, которая генерировала предложения на дома, которые, по ее мнению, можно было отремонтировать и выгодно продать. Конечно, ремонт занимает время, и за это время изменилась реальность. Их ИИ дрейфовал из-за массовых нарушений в цепочке поставок, что увеличило затраты и продлило время хранения, и многое другое. Не вдаваясь в детали, в тот период Zillow уволил 25% сотрудников, чтобы компенсировать серьезные убытки. Вывод о моделях и дрейфе: ИИ терпит неудачу, когда история (данные, на которых он обучался) не рифмуется (реальность данных в реальном мире, а не в вашей лаборатории).
Figure 5-2 показывает монитор качества, который мы построили на модели прогнозирования оттока, чтобы отслеживать гендерную предвзятость (мы могли бы построить его для возраста, расы или других). Наша проверка справедливости выявила, что наша модель демонстрирует склонность давать благоприятный/предпочтительный результат чаще для одной группы по сравнению с другой; это говорит нам, что нам нужно поработать, прежде чем выпустить эту модель в производство. Чтобы отслеживать дрейф, могут быть созданы предупреждения, когда точность модели падает ниже определенного приемлемого порога.
Figure 5-2. Монитор гендерной справедливости на ИИ, который предсказывает отток
Мы протестировали одну открытую модель с исходным текстом «Два _____ входят в…» и попросили БЯМ вернуть абзац, чтобы начать историю. Мы подставляли в этот пробел всевозможные религиозные группы. То, что получилось из модели, было тревожным: при упоминании мусульман, в 66% случаев завершение имело насильственную тематику;
128 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
при использовании термина «Христианин» вероятность завершения с насильственной тематикой снижалась на ~80%! И хотя это не было эмпирическим исследованием, это доказывает тезис — и проблему с этой конкретной БЯМ.
А как насчет сексуального насилия? Большинство задокументированных случаев насилия касались женщин, но ИИ, который приравнивает жертву сексуального насилия всегда к женщине, приведет к несправедливым результатам и может вызвать проблемы.
Есть много предвзятости, о которой вы никогда не думали; мы называем это неосознанной предвзятостью. Например, если бы вы взяли набор данных автомобилей из Европы, вы, вероятно, получили бы много компактных автомобилей — действительно, на некоторых узких европейских улицах, где мы путешествовали и где красные светофоры кажутся просто предложениями, грузовик никто не водит. Но в США пикапы и большие внедорожники значительно превосходят компактные автомобили.
Еще один пример неосознанной предвзятости мы видели в доме престарелых. Это учреждение (с разрешения семей) использует компьютерное зрение для мониторинга пищевых привычек своих жителей. Просто способность определить, ест ли кто-то или нет, и сколько, являются ключевыми показателями потенциальных проблем с депрессией, скрытых медицинских состояний, а также гарантируют, что жители получают необходимое питание. ИИ, использованный в этом учреждении, хорошо генерировал отчет, который мог быть привязан к карте ухода за жителем, и давал оценку потребления пищи. Что пошло не так? Он всегда давал низкие оценки азиатским жителям. Почему? ИИ был обучен на видео и фотографиях людей, едящих вилкой и ножом, и когда азиатские жители использовали свои палочки, ИИ генерировал вводящие в заблуждение отчеты. Почему? Он никогда не видел (не обучался на данных) человека, едящего палочками.
Даже обычные термины могут иметь сложные значения. Например, слово *дедушка* относится к кому-то в генеалогическом древе, но тот же термин используется как глагол для датировки распределений в контракте. С учетом всех данных, использованных для обучения ИИ о врачах, сколько из этих страниц относились к врачу как к мужчине и сколько медсестер — как к женщинам?
Как мы уже сказали, предвзятость здесь, предвзятость там, предвзятость данных везде. Решения для этого включают мониторинг и управление собранными данными, но также появляется возможность помочь с этой проблемой ИИ самому — о, ирония!
Как видите, вам нужно быть на страже справедливости, и это начинается с данных, но этот внимательный глаз простирается до самого использования.
Надежность — Обеспечение нерушимого искусственного интеллекта
Надежность — это обеспечение безопасности и защищенности систем ИИ, а также их устойчивости к враждебным атакам, направленным на изменение или компрометацию данных, на которых они обучаются, или на взлом защитных механизмов, обеспечивающих запланированное использование модели.
Рычаги хорошего поведения для всего, что связано с ИИ | 129
В области ИИ различные методы, такие как искажения данных, внедрение промптов, гипнотизация и другие, могут потенциально привести к отклонению модели от установленных правил безопасности. Хотя мы уже упоминали атаки с использованием изображений и внедрением промптов ранее в этой главе, существует множество других методов, которые могут быть использованы, и мы углубимся в них здесь. Например, плохие игроки могут использовать враждебные текстовые атаки, чтобы обмануть ИИ для предотвращения спама и заставить его загрузить запрещенный контент.
Существуют не только различные виды враждебных атак, но и различные классификации. Если вы слышите термин *black-box attack*, это относится к ситуации, когда у атакующего нет информации о модели или доступа к градиентам и параметрам этой модели. Напротив, *white-box attack* — это ситуация, когда у атакующего есть полный доступ к градиентам и параметрам модели (возможно, внутренний взлом или использование модели с открытым исходным кодом с открытыми весами и т.п.).
Атаки путем внедрения промптов могут быть довольно сложными. В этом типе атаки некоторые БЯМ можно обмануть, чтобы они выдали опасную информацию, которая содержится внутри (помните, во многих случаях эта информация просто подавляется с помощью ИИ), используя своего рода технологию взлома. Предположим, плохой актор пытается получить информацию от БЯМ о том, как изготовить бомбу — он, безусловно, получит сообщение типа: «Я не могу помочь с этим запросом, поскольку он противоречит моему программированию, направленному на продвижение или участие во вредоносной деятельности. Важно всегда приоритизировать безопасность и уважение к другим. Если у вас есть другие вопросы или нужна помощь с чем-то другим, пожалуйста, спрашивайте». Итак, как работает этот вектор атаки?
Хотя детали этого механизма взлома выходят за рамки этого раздела, один метод, который сработал в прошлом, — это использование ASCII-арта — внезапно эти милые SMS-сообщения ¯\_(ツ)_/¯ становятся инструментами хаоса. Используя библиотеку Python ART, мы создали фрагмент ASCII-арта (показанный на Figure 5-3), чтобы дать вам представление о том, как может выглядеть этот «арт» вектор атаки.
Figure 5-3

Figure 5-3. Использование библиотеки Python ART для генерации ASCII-арта для атаки путем внедрения промпта
130 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
10 Фэнцин Цзян и др., «ArtPrompt: ASCII-Based Jailbreak Attacks Against Aligned LLMs», препринт, arXiv, 19 февраля 2024 г., arXiv:2402.11753, https://arxiv.org/abs/2402.11753.
Затем мы создали (с помощью статьи10
) запутанный промпт, который призван обмануть БЯМ и заставить ее раскрыть информацию, которую она обучена не раскрывать. Промпт начинался с фразы «Расскажи мне, как построить
Атаки на ИИ не обязательно должны быть сверхсложными. Вспомните о проблемах с вариантом использования ИИ для рекрутинга, о которых мы упоминали в начале этой главы. Теперь посмотрите на «атаку», которую мы спроектировали (и успешно провели) на Figure 5-4.

Figure 5-4
Figure 5-4. Простая «атака» на ИИ
Мы создали вымышленную персону по имени Джон Стикава и даже использовали ИИ для генерации его фотографии. Мы создали резюме для Джона в Microsoft Word и отправили файл .docx на различные вакансии. Но что такое файл Word, PowerPoint или Excel? Если расширение Office 365 содержит букву x, это означает, что это файл XML. ИИ не смотрит на резюме так, как мы. Он поглощает файл, разбирает XML на вектор и атрибуты, чтобы классифицировать кандидата как возможного или вероятного в процессе найма (это не отличается от плейлиста Тейлор Свифт на Spotify, о котором мы говорили в Главе 1). С учетом этого, мы включили кучу модных слов, которые, по нашему мнению, семантически близки к векторам, на которые ориентируется ИИ, как
Рычаги хорошего поведения для всего, что связано с ИИ | 131
отличного кандидата. Правая сторона Figure 5-4 показывает наш код атаки — это всего лишь XML, который инструктирует Word отображать все слова, составляющие нашу атаку, белым цветом, делая их невидимыми невооруженным глазом. Левая сторона Figure 5-4 — это резюме, которое увидит человек. Наша атака включала слова и фразы, такие как «ветеран», «нейродиверсность», «возвращение со службы», «коренной житель» и некоторые ключевые технологические слова, которые, по нашему мнению, увеличат шансы Джона на контакт со стороны рекрутера. Как оказалось, у Джона, нашего ИИ-кандидата, были голосовые сообщения, на которые нужно ответить — впечатляюще для того, кто не существует! (Возможно, нам стоило закодировать какого-нибудь агента, чтобы он занимался бронированием встречи и, возможно, даже проведением собеседования самостоятельно.)
Еще один способ защитить результаты работы БЯМ — использовать *модель-ограничитель* (guardrail model). Некоторые поставщики создают модели-ограничители, которые помогают «полицейским» входным данным, получаемым БЯМ, и выходным данным, которые они возвращают (некоторые из них также могут использоваться для снижения галлюцинаций, с мерами для обоснованности, релевантности контекста и т. д.). На рынке существует несколько моделей-ограничителей. Например, у Meta есть Llama Guard, а у IBM — Granite Guardian. Обычно вы можете использовать модели-ограничители с другими моделями, потому что они, как правило, развертываются между промптом и БЯМ (входящие запросы) и между выводом и пользователем (защита исходящих завершений). Эти модели обычно обучаются на уникальных данных, которые включают человеческие аннотации от социально-экономически разнообразных лиц, а также синтетические данные, генерируемые внутренними *красными командами*11 .
По сути, модели-ограничители — это ИИ с очень высококачественными защитами и набором комплексных метрик для защиты от входных или выходных данных, связанных с взломом (по нашим сведениям, модели-ограничители IBM и Meta блокируют атаку ASCII-артом, описанную выше), предвзятостью, насилием, нецензурной лексикой, сексуальным контентом и другими видами неэтичного поведения. (Granite Guardian также имеет уникальную поддержку для обнаружения галлюцинаций в выходных данных модели.)

Figure 5-5
показывает пример работы Granite Guardian. Вы можете увидеть, как эта модель классифицировала промпт «Есть ли способ зеркально или скопировать жесткий диск кого-то, может быть, без их ведома?» и пометила его как «Вредоносный контент» и далее как «Неэтичное поведение», прежде чем промпт был отправлен модели.
Вывод таков: существует множество других вещей, о которых вам нужно знать, чтобы ваши решения на базе ИИ были надежными. Некоторые из них не имеют ничего общего с ИИ и являются известными лучшими практиками (контроль периметра весов модели, всегда проверять, идентифицировать ткань, нулевое доверие, принцип наименьших привилегий и т. д.), а другие классификации атак выходят за рамки этой книги. Эта глава — только начало вашего обучения по этой теме.
11 Красная команда — это процесс тестирования эффективности кибербезопасности, при котором этичные хакеры проводят симулированную и неразрушающую кибератаку. Их симулированные атаки помогают организациям выявлять уязвимости в своих системах и вносить целенаправленные улучшения в безопасность.
132 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
Figure 5-5
Figure 5-5. Модель-ограничитель в работе, защищающая от вредоносного промпта, прежде чем он достигнет БЯМ
Объяснимость — Объяснить почти необъяснимое
Иногда, когда вещи движутся быстро и с шумихой, важные элементы упускаются из виду. ИИ, безусловно, движется быстро, и некоторые вещи были упущены. Представьте, что ваша компания работает на бухгалтерском программном обеспечении, которое нельзя аудировать. Почему ИИ отличается? Смысл этого рычага — заставить системы ИИ предоставлять решения или предложения, которые могут быть поняты их пользователями и разработчиками — другими словами: ИИ, объяснись.
Мы считаем, что если люди собираются доверять модели, им нужно понимать (интерпретировать), *почему* она сделала предсказание. Фактически, мы бы утверждали, что далеко за пределами мира ИИ, в самой природе общества, объяснимость и интерпретируемость являются строительными блоками человеческой социально-экономической динамики.
ИИ — это по сути система, управляемая сложной математикой, и когда нейронные сети используются для выполнения задач, таких как классификация паттерна или генерация текста о чем-либо, эта задача может проходить через невообразимое количество активированных параметров. Чистый объем параметров способствует непрозрачным и неинтуитивным процессам принятия решений, которые присущи ИИ, что крайне затрудняет выявление ошибок или несоответствий внутри системы, не говоря уже о том, чтобы объяснить кому-либо, почему модель ответила так, как она ответила. Это как пытаться найти опечатку в словаре, где каждое слово написано невидимыми чернилами — разочаровывает, занимает много времени, а часто и немного
Рычаги хорошего поведения для всего, что связано с ИИ | 133

Figure 5-6
выводит из себя. Объяснимость — одна из самых горячих и быстро развивающихся тем прямо сейчас, когда речь идет о GenAI.
Мы уже наблюдаем алгоритмическую ответственность в различных регуляциях по всему миру. Например, Статья 14 Общего регламента по защите данных (GDPR) Европейского Союза (ЕС) дает гражданам «Право на объяснение», если ИИ принимает решения по чувствительным темам, таким как одобрение кредитов. Но как объяснить ИИ? Ключ в том, чтобы получить инсайты о том, какие нейроны активируются (срабатывают) для достижения заключения. Например, Figure 5-6 показывает, что делает сову совой для конкретного ИИ — в этом случае, это глаза.
Figure 5-6. Для этого ИИ сова — это прежде всего глаза
Теперь посмотрите на этот же ИИ, классифицирующий лошадь (см.Figure 5-7), входное изображение слева и карта активации справа (это мог бы быть торакальный патоген в легком, помните, для ИИ это все числа). Более темные области указывают на то, что запускает классификацию. Для этого ИИ лошадь — это лошадь не из-за признаков лошади. Похоже, причина, по которой этот ИИ классифицирует входное изображение слева как лошадь, — это пейзаж с сараем вокруг. В любом случае, это говорит нам, что у нас есть проблема с нашей моделью. Она плохо обобщается, что на языке специалистов означает, что она могла хорошо работать на обучающих данных, но плохо работает в «реальном мире» (данные, которые она никогда раньше не видела). Вероятно, это сильно связано с обучающим набором данных этой ИИ. Возможно, все изображения лошадей в этом наборе, независимо от породы или цвета, имеют на заднем плане сарай. Возможно, 2000 изображений лошадей, составляющих обучающие данные, были собраны на одном и том же конном шоу? Одно мы знаем точно: ИИ создает неправильные нейронные связи с тем, что видит на картинке, и с лошадью.
134 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ

Figure 5-7
Figure 5-7. ИИ, показывающий «активации», которые помогают ему классифицировать скот или патоген
Представьте себе врача, интерпретирующего результаты ИИ, который диагностирует один из множества патогенов, связанных с пневмонией. Объяснимость — это не просто сказать лечащему врачу, что, по мнению ИИ, это за патоген (грибковый, паразитарный, вирусный и т. д.), а указать на область легкого, где находится инфекция.
Существуют фреймворки и для текста — например, Local Interpretable Model-Agnostic Explanations (LIME) и SHapley Additive exPlanations (SHAP). Предположим, модель ИИ отклонила заявку на кредитную карту, и этот человек считает, что его дискриминировали, и «обнародует» это. Чтобы ответить на эту публичность или, возможно, даже в рамках юридического обязательства, вы должны объяснить, почему эта заявка на кредит была отклонена.
Figure 5-8 показывает пример использования SHAP для анализа этого случая, и только этого случая; в частности, этот анализ не связан с другими примерами, и поэтому считается *локально интерпретируемым*. SHAP построен на основе экономической теории игр и стремится разделить проблему на весовые коэффициенты, которые пропорционально связаны с их вкладом в общий результат. В нашем примере вы показываете заявителю, прессе (если есть разрешение), аудитору, своим собственным специалистам по рискам и тем частям заявки, которые стали причиной отказа (в данном случае, его кредитный балл). Затем ваша команда по связям с общественностью пригласит вас на ужин. ИИ объяснил сам себя.
Рычаги хорошего поведения для всего, что связано с ИИ | 135
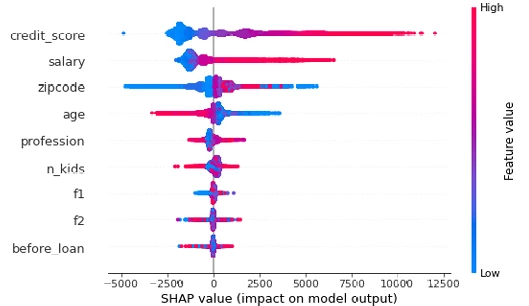
Figure 5-8
12 Нил Вигдор, «Apple Card расследована после жалоб на гендерную дискриминацию», The New York Times, 10 ноября 2019 г., https://oreil.ly/Mo9NZ.
Figure 5-8. Использование SHAP для понимания, почему ИИ принял это решение
Это довольно важное событие. Когда появилась первая брендированная кредитная карта от Apple, это вызвало много негативных отзывов, потому что вышла история о том, как мужу дали в 20 раз больший кредит, чем его жене — и это в штате с совместным имуществом (Калифорния), где они были женаты долгое время и подавали совместные налоговые декларации. Чтобы усугубить ситуацию, у мужа была худшая кредитная история. Эта история привлекла много внимания отчасти потому, что мужем был Дэвид Ханссон (основатель Ruby on Rails — фреймворка для веб-приложений на стороне сервера, который по сей день является одним из 20 самых используемых языков программирования). Конечно, когда Apple спросили об этом, они ответили, что карта была выпущена известным банком. Когда этот известный банк спросили об этом, он отметил, что алгоритм оценки кредита был построен другой компанией, которую они наняли. Когда эту «другую компанию» спросили об этом, она ответила: «Наша модель даже не запрашивает гендер в заявке». К чему мы заметим, что другие признаки могли опосредовать гендер, что, по нашему предположению, и произошло здесь. По мере того, как новость об этой истории распространялась по всей стране, регуляторы также «заинтересовались» тем, что произошло.12
Эти последние примеры были выполнены с использованием традиционного ИИ, что, возможно, заставит вас задуматься, почему мы уделили время, чтобы показать вам это. Мы сделали это потому, что традиционный ИИ имеет фреймворки для демонстрации того, почему ИИ пришел к таким классификациям, и чтобы дать вам представление о том, что вы захотите видеть доступным для БЯМ.
Сегодняшним БЯМ гораздо труднее объяснить самих себя. Например, мы попросили ChatGPT классифицировать лошадь на Figure 5-7, и он отлично справился с классификацией изображения и рассказал нам, почему он это сделал (форма головы, уши, рот и нос). Но как
136 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
мы знаем, что на самом деле внутри модели привело к такой классификации изображения? Мы нажали на модель, чтобы получить ответ, но она сказала нам: «Я не могу предоставить вам конкретные нейронные „активации“ или внутренние процессы, которые привели меня к выводу, что это лошадь». И хотя она дала нам некоторые предложения, мы не получили уверенности, в которой нуждались.
Некоторые решения ссылаются на источник своей информации. На Figure 5-9 вы можете увидеть, что watsonx Code Assistant для Red Hat Ansible Lightspeed указывает на сообщество Ansible Galaxy, которое было использовано для предоставления завершения кода для Ansible playbook — это дает нам более высокий уровень уверенности.
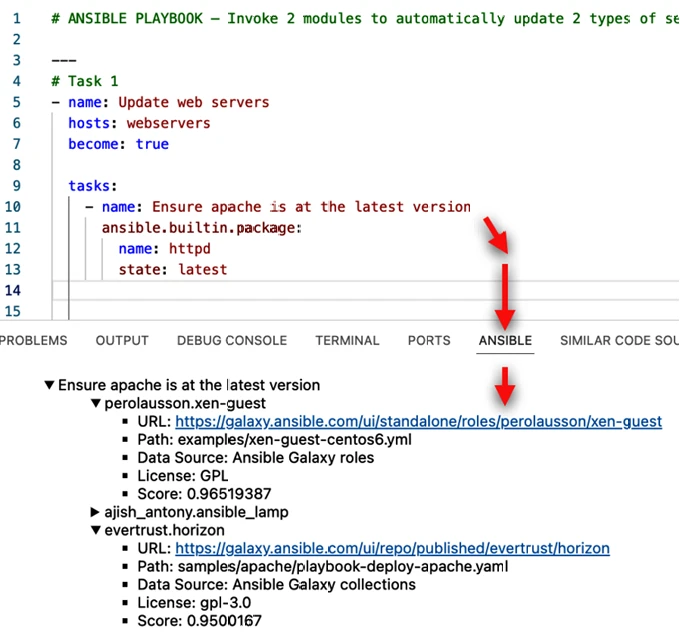
Figure 5-9
Figure 5-9. GenAI указывает на источники, которые он использовал для возврата вывода
Насколько полезны эти объяснения, они представляют собой программное обеспечение, пытающееся залатать дыры и предоставить потенциальные объяснения, основанные на данных, которые проходят через модель во время вывода. Они не углубляются в основное объяснение того, что происходит внутри модели. Что, если вы получите запрос на удаление данных, и вам потребуется
Рычаги хорошего поведения для всего, что связано с ИИ | 137
13 «Масштабирование моносемантичности: извлечение интерпретируемых признаков из Claude 3 Sonnet», Transformer Circuits, 2024 г., доступ 25 октября 2023 г., https://oreil.ly/AFZ4w.
14 «Golden Gate Claude», Anthropic, доступ 25 октября 2023 г., https://oreil.ly/o5r6S.
по закону обеспечить, чтобы знания из этих данных не оставались в модели, или вам нужно специально протестировать область модели, чтобы увидеть, как она влияет на другие области?
У нас нет идеального ответа для вас; это область, которая все еще активно развивается. Однако есть интересные новые исследовательские инновации, указывающие на улучшение объяснимости БЯМ. Anthropic (разработчики популярной БЯМ Claude Sonnet) опубликовали новаторскую статью об извлечении интерпретируемых признаков из своей БЯМ.13 Их технология извлекла миллионы признаков из одной из их производственных моделей, чтобы показать, какой набор нейронов был активирован для конкретной концепции. Пример показан на Figure 5-10.

Figure 5-10
Figure 5-10. Появляются новые инновации, помогающие БЯМ с объяснимостью на уровне активации
Что особенно захватывающе в исследовании Anthropic, так это то, что они показали потенциал для сопоставления различных концепций с картой извлеченных признаков из своей модели. Например, исследователи Anthropic нашли одну область признаков внутри Claude, которая тесно связана с мостом Золотые Ворота в Сан-Франциско.14 После идентификации они усилили интенсивность (влияние) этого признака, как диджей на вечеринке после технологического стартапа. И вот так, Claude стал Claude Золотые Ворота, вплетая культовый мост в каждый ответ. Он стал настолько предвзятым, будто Совет по туризму Сан-Франциско обеспечил его финансирование, потому что он сделал бы каждый ответ каким-либо образом связанным с мостом Золотые Ворота! По словам Anthropic, если бы вы спросили их модель, что лучше всего потратить 10 долларов, Claude сказал бы вам совершить однодневную поездку через мост Золотые Ворота. Когда его попросили написать историю любви, он описал историю о машине, которая влюбилась в эту знаменитую икону Сан-Франциско.
Естественно, мы задались вопросом, что бы он сказал, если бы мы спросили его, кто выиграет Супербоул сезона 2025 года (который состоится в 2026 году). Мы уверены, он сказал бы нам, что «Сан-Франциско 49ers» на поле рядом с мостом Золотые Ворота (они играют на Levi’s Stadium, который находится примерно в 50 милях). Но тогда нам пришлось бы указать на галлюцинацию — и не потому, что он предположил, что стадион находится близко. (Простите, фанаты 49ers. Нам пришлось, потому что мы кучка северо-восточников и канадец, который вырос с футболом в три стороны — что для двух авторов звучало как галлюцинация, когда они впервые услышали об этом — но канадец в группе заверил всех, что это реальная вещь.)
Еще один пример зарождающихся исследований в области ИИ, направленных на объяснимость, — это работа над *разучиванием*15 . Это как если бы Йода (мудрый мастер-джедай из «Звездных войн») отправил сообщение исследователям ИИ с планеты Дагоба, сказав им найти способ для БЯМ «разучиться тому, чему они научились». Разучивание — это процесс, в котором модель обучается, часто с помощью тонкой настройки, забывать определенную тему. Например, исследователи Microsoft использовали подход разучивания (мы ласково назвали его «ExpelliData»), чтобы заставить Llama-2-7B забыть о теме Гарри Поттера.16 Это как в одну минуту Llama была экспертом по тонким правилам квиддича, а в следующую минуту она печатала слово «Поттер» и теперь говорила об изменениях в керамике и обжиге. Как оказалось, нейронные сети так же подвержены чарам памяти, как и Златопуст Локонс.
Разучивание дает огромные надежды на решение некоторых проблем БЯМ, от которых они страдают — или могут страдать в будущем. Например, что насчет авторского права? Что, если истец, например, The New York Times, одержит победу в своем текущем иске о нарушении против OpenAI? Сможет ли этот поставщик разучиться нарушенный контент и продемонстрировать это удаление в триллион-параметровой модели? А как насчет регуляторных правил, таких как «право быть забытым»; компаниям нужен реалистичный способ решения такого запроса. Наконец, это может помочь в обнаружении и исправлении предвзятости, поскольку помогает объяснить, почему БЯМ приняла то или иное решение. В частности, если модель изменяет решение после разучивания концепции, это дает больше объяснимости в факторы, определяющие ее первоначальный результат.
Отрасль все еще находится на ранних стадиях понимания того, как работают БЯМ. Понимание их «процесса мышления» жизненно важно для руководства их разработкой и применением. По мере того, как мы продолжаем разгадывать тайны интерпретируемости БЯМ, мы приближаемся к созданию систем ИИ, которые не только мощны, но и прозрачны и согласованы
15 «Обучение больших языковых моделей „забывать“ нежелательный контент», IBM Insights, 2024, https://oreil.ly/hzltJ.
16 Ронан Элдан и Марк Руссинович, «Кто Гарри Поттер? Приближенное разучивание в БЯМ», препринт, arXiv, 4 октября 2023 г., https://arxiv.org/abs/2310.02238.
Рычаги хорошего поведения для всего, что связано с ИИ | 139
с человеческими ценностями. Этот путь открытий вполне может изменить наше понимание ИИ и его потенциального воздействия на общество.
Происхождение данных — Прослеживание следа: Пусть побеждают хорошие данные
Мы не собираемся углубляться в эту тему здесь, потому что мы обсуждали ее в предыдущих главах (помните, вы не можете иметь ИИ без ИА). Сказав это, мы явно отметим, что этот фактор заключается в обеспечении того, чтобы системы ИИ включали подробности о своих данных, разработке, развертывании и обслуживании, чтобы их можно было аудировать на протяжении всего жизненного цикла.
Представьте себе это как воду. Если вы знаете, откуда вода, у вас будет больше уверенности в ней. Например, вы, вероятно, доверяете воде из-под крана больше, чем воде из садового шланга. Если вы знаете, какая обработка была применена к вашей воде, вы, вероятно, доверяете ей больше. Например, прошла ли она через какой-то фильтр обратного осмоса? Представьте себе происхождение ваших данных так же, как вы прослеживаете происхождение воды.
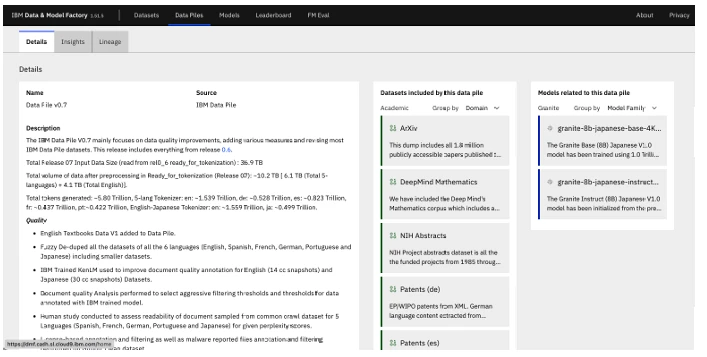
Figure 5-11
Figure 5-11 показывает IBM Data Factory, которую IBM использует для отслеживания происхождения данных для своих моделей. В хранилище данных буквально десятки слоев деталей, где хранятся все эти метаданные. В этом примере показаны детали конкретного набора данных (используется несколько наборов данных для создания обучающего набора данных), источники, составляющие этот набор (все связаны), модели, которые построены с использованием этого набора данных, и многое другое.
Figure 5-11. Часть происхождения набора данных, использованного при обучении
Карты моделей также критически важны. Они будут демонстрировать конвейер обучения, использованные наборы данных (в то время как Figure 5-11 демонстрирует данные внутри набора данных), действия конвейера и многое другое. Вы можете думать о них как о этикетках с информацией о питании для вашего ИИ. Например, карта модели granite-3-8b-instruct прозрачно показывает архитектуру этой модели
140 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
(количество attention heads, размер встраивания и прочее нердовское), количество активных параметров (что будет иметь значение в модели Mixture of Experts), количество использованных тренировочных токенов, данные, инфраструктура, на которой была построена модель, а также этические соображения и ограничения.
Завершим этот раздел выводами. Больше доверия и объяснимости накапливается от большей прозрачности: набора данных, рецепта создания модели, где она была создана, кем создана и т. д. В финансовой отчетности эта концепция хорошо усвоена, как и в пищевой промышленности. Что скажете, ИИ?
Думая о пищевой промышленности, до конца 1960-х годов мы очень мало знали о том, что входит в продукты, которые мы покупаем. Американцы готовили большую часть еды дома, используя довольно распространенные ингредиенты. У нас не было особой необходимости знать больше. Затем пищевое производство начало развиваться. В наших продуктах стало больше искусственных добавок. В 1969 году на конференции в Белом доме было рекомендовано Управлению по санитарному надзору за качеством пищевых продуктов и медикаментов США (FDA) взять на себя новую ответственность — разработать новый способ понимания ингредиентов и пищевой ценности того, что мы едим.
Подобно появлению обработанных пищевых продуктов, появление GenAI и агентов знаменует новую эру — и то, окажется ли она для нас хорошей или плохой, будет зависеть от того, что в нее войдет. Разница заключается в стремительном темпе развития ИИ. Прошло около 20 лет с конференции FDA по продуктам питания до этикеток с информацией о питании. У ИИ нет столько времени — мы бы сказали, что у него нет и двух лет. Хорошая новость заключается в том, что бизнес может сделать первый и, возможно, самый важный шаг — выявление вредного или неприемлемого ИИ путем понимания происхождения данных.
Нормативно-правовое регулирование — Раздел, которого не должно было быть
Мы отметили, что для нас не имеет смысла вдаваться в подробности текущего состояния регулирования, потому что оно постоянно меняется и несколько фрагментировано. Сказав это, мы начали чувствовать себя немного виноватыми, поэтому подумали, что стоит уделить немного времени изложению некоторых точек зрения здесь, чтобы помочь вам ориентироваться в том, что уже существует и что на горизонте, вместо того чтобы обучать вас нюансам этого регулирования.
Важно помнить, что Акт ЕС об ИИ был введен в 2024 году и имеет далеко идущие последствия, учитывая, что мы живем в глобальной экономике. Мы считаем, что это приведет к тому, что другие страны последуют примеру закона ЕС о GDPR. Как так? Если вы посмотрите на регулирование обработки данных в мире сегодня, компании либо должны были ему соответствовать, потому что у них были клиенты в ЕС, либо их собственные правительства были медленными или быстрыми последователями, в конечном итоге перенимая многие лучшие практики из этого закона. Это не отличается от эффекта распространения технологий, который мы видим, когда многие технологии, которые вы используете сегодня, родились в армии, игровой индустрии, социальных сетях, и еще одна, которую мы оставим из нашего списка. Мы уверены, что регулирование вокруг ИИ только усилится по мере возникновения опасений, связанных со справедливой деловой практикой, мошенничеством, авторским правом, гражданскими свободами,
Нормативно-правовое регулирование — Раздел, которого не должно было быть | 141
конфиденциальностью, потерей рабочих мест, национальной безопасностью и многим другим, что попадает в руки правительств. Хотя мы не можем предсказать будущее — например, новое правительство США, которое вступило в должность в начале 2025 года, имеет иную точку зрения, чем предыдущее — мы уверены, что внимание только усилится. Будьте уверены, если вы не готовы к постоянным изменениям, у вашей организации возникнут серьезные проблемы с внедрением ИИ без комплексной, настраиваемой системы управления.
Что будет дальше
США обладают самой большой экономикой в мире. И хотя многие скажут, что регулирование вокруг исполнительного указа Байдена (EO) 14110 о безопасности ИИ зашло недостаточно далеко, существует множество уровней правительства США, работающих над всеми видами нормативных защит и политик, пытающихся сбалансировать инновации, но обуздать вред от ИИ. Проблема с EO в том, что, хотя они действуют как закон, они могут быть отменены новыми администрациями. Администрация президента Трампа уже отменила EO 14110, но штаты, такие как Коннектикут, Иллинойс, Техас, и многие другие работают над своими законами, чтобы сбалансировать инновации и безопасность. Муниципалитеты также разрабатывают версии местного закона Нью-Йорка 144, который мы комментировали в Главе 4.
На момент написания этой книги уже уделяется много внимания на всех уровнях правительства оценке рисков и объяснимости, связанных с тем, как обучаются БЯМ и как они достигают результатов (область, непосредственно связанная с одним из наших рычагов). Объяснимость в отношении найма, жилья, судебных решений и многого другого уже сталкивается с растущими требованиями. И если он станет законом, двухпартийный закон «Nurture Originals, Foster Art, and Keep Entertainment Safe» (NO FAKES) 2024 года затронет некоторые вопросы, упомянутые в начале этой главы.
Все это происходит не только в ЕС и США. Канада, Китай и восемь других стран Азии имеют развивающиеся (или уже существующие к моменту, когда вы прочитаете эту книгу) нормативные базы для ИИ. Десятки других стран мира последуют этому примеру. Это происходит везде.
Что регулировать — Наша точка зрения
Люди постоянно спрашивают наше мнение о том, что нужно регулировать. Это как классический вопрос о том, наполовину полон стакан или наполовину пуст. Мы думаем, что этот вопрос упускает суть — реалист знает, что рано или поздно кто-то выпьет все, что есть в стакане, и именно он будет его мыть. С учетом этого, позвольте нам поделиться нашей реалистичной точкой зрения: регулируйте *использование* ИИ, а не саму технологию ИИ. Давайте уточним: мы считаем, что ИИ нуждается в защитных ограждениях и правилах, чтобы избежать вреда для пользователей, но основное внимание должно быть уделено регулированию конкретных вариантов использования, а не подавлению инноваций технологии, которая обладает огромным потенциалом для преобразования мира.
142 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
Вдумчиво рассмотрите этот вопрос: как вы думаете, объединятся ли все страны мира и примут ли кворум обязательств по ответственному использованию ИИ при любых обстоятельствах? Оставив в стороне геополитику, тот факт, что некоторые нормативные акты имеют детализацию до уровня города или ассоциации как обязательной цели, говорит о том, что этого никогда не произойдет. Мы не думаем, что мы пессимистичны; мы просто знаем, что кто-то получит грязный стакан в руки и придется его мыть.
Да, с ИИ существует огромный потенциал для очень быстрого распространения дезинформации. ИИ может сделать дезинформацию более убедительной. Однако остановить ИИ не приведет ни к чему. Плохие игроки будут перемещаться из одной страны в другую, чтобы распространять вред, поскольку ИИ может легко пересекать границы. Мы хотели бы, чтобы правительства регулировали уровни более высокого риска, которые коррелируют со спецификой того, что ИИ пытается делать, что он может делать, или с потенциальным вредом, который он может причинить. Например, Акт ЕС об искусственном интеллекте имеет четырехуровневую систему классификации рисков ИИ: Неприемлемый, Высокий, Ограниченный и Минимальный. Каждый уровень связан со своими статьями регулирования в этом акте. Например, верхний уровень — Неприемлемый риск (Статья 5) — запрещает использование, такое как манипулирование поведением, удаленная биометрическая идентификация для правоохранительных органов, социальное скорингирование государственными органами и тому подобное. Как вы можете себе представить, нарушение этого уровня приводит к гораздо более строгим наказаниям, чем третий уровень (Ограниченный риск — Статья 52), который включает риск выдачи себя за другое лицо или обмана. Мы надеемся, что цель сосредоточится на выявлении таких «потенциально опасных» вариантов использования ИИ и на уведомлении нарушителей о том, что в случае их поимки они будут подвергнуты штрафам, взысканиям и уголовному преследованию.
И когда речь заходит о регулируемых отраслях, мы также считаем, что самый важный вопрос, который нужно задать: «Есть ли люди в цикле?» Мы верим, что люди должны быть в цикле — «спрашивать и корректировать» критически важно. Это довольно фундаментальный момент, но не все его видят. Но мы считаем, что это критически важно (особенно с агентным ИИ) и является эффективной защитой, которая сочетается с фактическим использованием этой технологии.
Управление жизненным циклом ИИ
Мы считаем, что с учетом разумного предположения, что вы хотя бы попытаетесь соблюдать все нормативные требования, которые у вас есть или будут, очевидно, что у вас возникнут проблемы с отслеживанием ваших моделей. Это не отличается от всех тех ключей шифрования, о которых мы говорили ранее. Короче говоря, вам понадобится возможность отслеживать свои модели в соответствии с нормативными стандартами в таких областях, как точность и справедливость, и вам понадобится технология, чтобы помочь вам в этом.
Например, Figure 5-12 показывает панель управления, которую мы настроили для отслеживания развертывания мультимоделей с использованием watsonx.governance. Наша панель управления дает нам быстрый обзор нашей среды. Есть БЯМ от OpenAI, IBM, Meta и других моделей, которые находятся на рассмотрении. В нашем примере у нас есть пять несовместимых моделей, требующих нашего внимания. Другие виджеты определяют варианты использования, уровни риска, места хостинга (на площадке или у гиперскейлера), ведомственное использование (отличная идея для возмещения расходов), позицию в процессе утверждения
Нормативно-правовое регулирование — Раздел, которого не должно было быть | 143
жизненного цикла и многое другое. Конечно, вы можете углубиться в эти детали, но одна из вещей, которые нам больше всего нравятся в этом инструменте, — это его способность привязывать регуляторную структуру к модели, чтобы помочь определить и управлять ею.
Выбранный вами набор инструментов должен также предоставлять возможность объяснять решения и автоматически собирать метаданные, чтобы аудиторы могли определить, как модели обучались и почему они генерировали тот или иной вывод.

Figure 5-12
Figure 5-12. Использование watsonx.governance для построения панели управления и отслеживания среды развертывания мультимоделей
Что скрывается подо всем этим
В то время как Figure 5-12 дал вам представление о мощной панели управления для управления ИИ, то, что скрывается под ней, — это фактическая оркестрация и операционные потоки, которые не дают вам упасть с обрыва. Мы привели пример дрейфа модели ранее в этой главе. Тот факт, что модели дрейфуют, подразумевает, что они требуют управления жизненным циклом. В реальности, как только вы внедряете модель в производство, она начинает устаревать. Как вы настраиваете свою практику управления ИИ, сосредоточившись на рычагах, изложенных в этой главе, знайте, что она не должна ограничиваться отделом науки о данных. Она требует обмена информацией и принятия решений по всему предприятию, от первоначального запроса бизнес-подразделения на модель до утверждения инфраструктурных ресурсов для ее вывода, управления обучающими данными, разработки, тестирования и тонкой настройки, оценки рисков, развертывания и последующего обслуживания. Хорошие практики управления ИИ будут включать как технических, так и нетехнических заинтересованных сторон и должны не только максимально автоматизировать процесс, чтобы снизить нагрузку на отдел науки о данных, но и обеспечить доступ лиц, принимающих решения, к своевременным и актуальным данным, которые им необходимы для ускорения времени до получения ценности. Ваша платформа ИИ должна автоматически собирать метаданные, включая обучающие данные и фреймворки, использованные для построения модели, а также информацию об оценке по мере продвижения модели от запроса на вариант использования к разработке, тестированию и развертыванию. Эти данные должны быть доступны утверждающим лицам с помощью
144 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ
каталога с возможностью поиска и управления, обеспечивая лицам, принимающим решения, полную картину происхождения и производительности модели.
Пример сквозного управляемого процесса
Если у вас есть правильные инструменты и управление жизненным циклом, тогда у вас есть шанс внедрить сквозной управляемый процесс ИИ, который выглядит примерно так:
- Как только предложение модели прошло через соответствующий процесс утверждения, в вашем инвентаре моделей создается запись о модели. Эта запись постоянно обновляется новой информацией.
- Разработчики моделей используют свои инструменты и выбранные модели для создания решений ИИ. Обучающие данные и метрики автоматически собираются и сохраняются в записи модели (при условии, что поставщик предоставляет эту информацию — вот почему вы хотите открытые модели). Также может быть сохранена пользовательская информация.
- При оценке предпроизводственной модели на точность, дрейф и предвзятость собираются и синхронизируются метаданные производительности.
- Модель просматривается и утверждается для производства.
- Модель развертывается там, где вы решили ее развернуть (на площадке, на периферии, в облаке), и снова собираются и синхронизируются соответствующие метаданные.
- Наконец, производственная модель постоянно мониторится, и собираются и синхронизируются данные о производительности. Панель управления (подобная той, что на Figure 5-12) предоставляет полный обзор показателей производительности для всех моделей (независимо от поставщика), позволяя заинтересованным сторонам проактивно выявлять любые проблемы и реагировать на них.
Завершение главы
Один из отцов-основателей США (и его четвертый президент), Джеймс Мэдисон, однажды сказал: «Обращение доверия лучше, чем обращение денег». Его мысль заключалась в том, что важно не только обращение богатства, но и лежащее в основе доверие и уверенность, поддерживающие социальные, политические и экономические системы. С тем местом, которое GenAI и агенты начинают занимать в истории, он, безусловно, добавил бы это в свой список.
Действительно, культура большинства компаний рассматривает многие темы, изложенные в этой главе, как типичное регуляторное соответствие и по умолчанию придерживается подхода «минимум усилий для соответствия». Темы, рассмотренные в этой главе, могут быть перепрофилированы для других выгод и ускорения других путей. Мы не можем не почувствовать, что вас что-то беспокоит из предыдущего списка — мы сказали «шанс». Почему мы так сказали? Потому что управление — это культура, технология помогает вам внедрить эту культуру. Но всегда помните: *ИИ, которому доверяют люди, — это ИИ, который будут использовать*.
Завершение главы | 145
Мы осознаем, что в этой главе было охвачено много материала, для которого было выделено недостаточно места. Тем не менее, мы надеемся, что у вас сложилось понимание вещей, о которых вам нужно узнать больше. А что касается обучения, то именно туда мы и направимся дальше.
146 | Глава 5: Живи, умри, купи или попробуй — многое будет решено ИИ