Использование ваших данных как дифференциатора
Как мы уже отмечали ранее в этой книге, менее 1% корпоративных данных находится в сегодняшних БЯМ. И если вы собираетесь стать Создателем ценности ИИ, кем вам поможет стать эта книга, вам придется работать с вашим самым ценным активом (вашими корпоративными данными) и сделать его частью вашей стратегии БЯМ — в конечном итоге раскрывая множество возможностей для создания ценности.
Чтобы действительно понять, насколько это глубоко, давайте отправимся назад во времени к истокам нашего цифрового мира, истокам, которые были поняты и концептуализированы почти 350 лет назад Готфридом Вильгельмом Лейбницем. Уже тогда Лейбниц понял, что информацию, доступную вокруг нас в виде языка или математики, можно закодировать в двоичное представление. (Лейбниц не только создал двоичную математику, но и помог создать исчисление, поэтому мы видим, почему некоторые из вас могут быть не его поклонниками.) Он знаменито сказал: «Для создания всего достаточно одного». Лейбниц ясно понимал ценность и силу представления информации по-разному (в данном случае, в двоичной нотации). Быстро вперед, к сегодняшнему дню, и вы легко заметите, что за последние несколько десятилетий наблюдался огромный объем создания ценности и бизнес-трансформации, обусловленный эволюцией и выразительностью представлений данных в нашем мире. Например, сегодня вкусы и запахи имеют представления данных, в конечном итоге представленные числами, которые далее переводятся в единицы и нули к тому моменту, как компьютер начинает работать с данными. Фактически, парфюмерные и ароматические дома буквально открывают и предлагают новые продукты, используя векторы для представления свежего лимона или медового масла. Подумайте об этом. Кто, кроме ИИ, мог бы когда-либо подумать о создании мороженого со вкусом «Эврика Багель»! Честно говоря, задолго до появления БЯМ описания вин и парфюмерии развлекали нас своей поэтической (и часто нелепой) креативностью на протяжении многих лет. В будущем ожидайте, что креативность достигнет новых (вежливое слово для «потенциально еще более нелепых») уровней благодаря БЯМ.
Оригинальный тур по эпохам: Оглядываясь на несколько десятилетий назад на представления данных
За последние десятилетия новые представления данных создали совершенно новые возможности и способности для всех бизнесов и отраслей. Мы посчитали целесообразным потратить некоторое время на эту тему, чтобы помочь вам полностью оценить ценность БЯМ для вашего предприятия — особенно когда она нюансирована вашими данными. Суть в том, что ваши корпоративные данные могут быть свернуты в это новое представление данных (БЯМ), которое может сделать ваши данные пригодными для использования способами, которые только фильмы могли себе представить всего несколько лет назад, и которое может принести огромный объем ценности вашей компании.
220 | Глава 8: Использование ваших данных как дифференциатора
Если подумать, помимо весов в модели, ИИ — это просто сжатые данные. Это всего лишь новое представление этих данных, и, как оказалось, за последние десятилетия были различные эпохи представлений данных, каждая из которых открывала новую эру создания ценности. Эта текущая революция в области ИИ во многом связана с мощью представлений данных и способностью кодировать невероятные объемы информации, в любой возможной форме, внутри этих новых, невероятно способных «сосудов», которые являются фундаментальными моделями (БЯМ). Вот как мы видим некоторые из этих эпох представлений данных за эти годы.
До 1980-х: Экспертные системы
Это были (а поскольку они используются и сегодня, возможно, нам следовало бы написать «есть») ручные символические представления наших данных. Данные кодировались в реляционной базе данных, что создало новый способ организации и связи данных для бизнеса, который раньше был недоступен. Эта эпоха оказала очень глубокое влияние на бизнес. Внезапно компания могла автоматизировать такие вещи, как расчет заработной платы, транзакции могли быть связаны с запасами и другими основными процессами. По ходу дела были созданы экспертные системы. Люди писали правила для логических бизнес-потоков с подключенными структурированными данными. Отличным примером является обнаружение мошенничества или управление цепочкой поставок — и многие компании до сих пор используют этот метод — есть правило, и если оно нарушается, появляется флаг или предпринимается действие.
Правила отлично подходят для подмножества вещей, но они не всегда творческие, и всегда есть исключения, поэтому они могут правильно работать лишь в очень ограниченном количестве случаев. На бэкенде правило-основанной системы требуется много ручных усилий для поддержания и построения этих правил. Для каждой отдельной ситуации нужно писать новое правило. (Вот почему мы называем эту репрезентационную эру ручной. Например, для хранения данных в реляционной базе данных требовался DBA для ручного создания схемы для их получения. Люди проделывают много работы и много размышляют над дизайном этой работы.) Возможно, способ выявления потенциального мошенничества с кредитными картами на заправке заключался в покупке на 1 доллар... новое правило. Со временем это правило ослабевало как предиктор, и какой-то другой индикатор оказывался полезным... новое правило. Это простой пример, но он постоянно происходил (или не происходил, и компании расстраивались). В итоге эти системы работали до тех пор, пока правила были правильными. Но со временем вариаций и правил стало так много, что большинство этих систем рухнуло сами по себе. Теперь подумайте о сегодняшней цифровой экономике — как правило-основанная система может реагировать на угрозы с увеличенным количеством точек доступа и сложных транзакций, выявлять сигналы, оставленные злоумышленниками, скрытые в шумной и эфемерной ежедневной активности, или своевременно реагировать на скоординированные атаки с консолидированным мониторингом? Они не могут.
Использование ваших данных как дифференциатора | 221
1980-е — ~2010: Машинное обучение
Теперь мы переходим в эру более специфичных для задач, менее ручных представлений признаков наших данных. Как это произошло? Потому что по мере того, как данные становились все более доступными, произошел сдвиг в сторону подходов, основанных на данных. Это было очень большое событие тогда, потому что машины начали генерировать свои собственные правила на основе этих данных и учиться новым представлениям нашего мира, основываясь на примерах, а не на заданных вручную правилах (программно). Очень круто! Многие из этих техник до сих пор используются специалистами по данным; например, деревья решений, машины опорных векторов (SVM), метод ближайшего соседа и многое другое. Эта эра была посвящена тому, как заставить компьютеры помочь построить признаки и заставить эти машины учиться на основе их аналитических данных. Эти знания были хорошими, возможно, даже отличными. И хотя машины (с помощью людей) использовали данные по-новому, появились новые представления и механизмы кодирования — например, графовые представления данных (представленные как сети с узлами и ребрами). Внезапно мир начал использовать эти новые представления данных и нашел способ их обхода, и это стало критически важным для бизнесов, занимающихся такими вещами, как интернет-поиск, социальные сети и связь людей и групп.
2010 — ~2017: Глубокое обучение
Теперь мы переходим в эру больших данных (помните о трех V: объеме, скорости и разнообразии). Компьютеры теперь могли получать доступ к большему объему данных, чем когда-либо. Теперь компьютеры не просто обнаруживали, но могли создавать новые представления данных. Вступите в мир специфичных для задач изученных представлений признаков наших данных. В эту эру мир получил доступ к огромным объемам вычислений (благодаря облаку и графическим процессорам) и постоянно растущим объемам данных (благодаря интернету). Компьютеры создавали и строили представления признаков, но все еще сильно зависело от человеческого опыта и большого объема ручных усилий. Такие вещи, как доступность ресурсов для обработки большего объема данных и отсутствие возможностей для создания более сложных моделей, все еще «мешали». Например, ИИ для обработки естественного языка (NLP) не имел большой памяти, превышающей несколько слов.
Это было началом эры глубокого обучения. Существует много вещей, выходящих за рамки этой книги, таких как функции активации, которые оживили эту эру. У нас была синергетическая комбинация все большего количества данных (начиная с эры больших данных, когда мир был занят сбором данных) и вычислений (а именно, было обнаружено, что графические процессоры, которые мы использовали для игр, могут предоставить мощные вычислительные возможности благодаря тому, как они обрабатывают матричную математику, которая является математикой глубокого обучения). Теперь в эту эру начали происходить очень крутые вещи, возможно, не магические (пока... это следующая фаза). Вся эта математико-компьютерная мощность (графические процессоры для построения представлений) смешалась с моделью потребления (облако), и внезапно любой мог построить модели ИИ за меньшую стоимость, чем дешевая чашка кофе. В эту эру компьютеры начали учиться на огромных объемах данных и строить специфичные для задач представления признаков; например, компьютерное зрение для обнаружения аномалий на рентгеновском снимке или дефекта в точке сварки
222 | Глава 8: Использование ваших данных как дифференциатора
на производственной линии, и так далее. Некоторые из этих представлений признаков были чрезвычайно сложными, и компьютеры изобрели новые составные признаки, такие как смешивание пола, местоположения, роста и профессии в усредненный признак, который описывал что-либо.
Сегодня: Фундаментальные модели (они же БЯМ)
Сегодня мы можем кодировать любую форму знаний и работать с этими данными так, как никогда раньше не представляли.
Как мы уже говорили, фундаментальные модели — это все о способности кодировать невероятные объемы информации в любой возможной форме внутри этих новых невероятных типов моделей. Наш мир вступил в эру БЯМ, где подход не только использует огромные вычислительные возможности и все эти данные, но и новая технология (самообучение в масштабе — благодаря трансформерам) резко сократила количество курированных размеченных данных, необходимых для обучения модели. Это огромное отступление от прошлого.
В частности, это новое представление данных обучается на обширных, огромных наборах данных и может выполнять широкий спектр общих задач. Эти новые представления данных (БЯМ) служат основой или строительными блоками для создания более специализированных приложений. Их гибкость и огромный размер отличают их от представлений предыдущей эры, которые обучались на ограниченных наборах данных для выполнения конкретных задач.
Эти новые представления данных создаются путем взятия обучающих данных и разбиения их на более мелкие фрагменты, называемые *токенами* (токен может быть словом или фрагментом слова). Этот процесс создает триллионы этих токенов, которые затем преобразуются в вектор, а эти векторы используются для представления токенов в форме, которую может понять ИИ. Но эти токены могут быть чем угодно, и, как вы уже узнали, это означает, что данные, хранящиеся внутри, не обязательно являются словами — это может быть что угодно (код, изображения, звуковые данные, профили вкусов и запахов и многое другое). По мере прохождения этих токенов (не преобразованных в векторы) через слои нейронной сети во время обучения применяется ряд математических операций, которые в основном состоят из матричных умножений и нескольких других простых операций — но все это делается в огромном масштабе. В процессе построения объединяются и перекомбинируются данные, изменяя последовательности этих токенов. Фактически, информация из разных модальностей (аудио и текст) может быть объединена в одной и той же фундаментальной модели во время обучения. Отличным примером этого является последняя модель GPT от OpenAI, которая объединяет мощность генерации текста и изображений (из их модели DALL-E) в одном месте.
Во время обучения параметры сети корректируются, чтобы выходные БЯМ становились все лучше и лучше в представлении последовательностей входных токенов. И по мере прохождения этого процесса обучения модель все больше и больше узнает о структуре данных, на которых она обучается, ее нюансах, а также о знаниях и корреляциях внутри. Опять же, это не совсем магия; это всего лишь математика, человеческая изобретательность и много вычислительной мощности.
Использование ваших данных как дифференциатора | 223
Теперь сила этого нового представления данных, которое закодировано внутри БЯМ, черпает свои возможности из своего масштаба (чистого объема данных, которые могут быть в нее введены), из своей связности данных (семантические связи устанавливаются между широким спектром разнородных входных данных, что делает их очень выразительными) и из своей мультимодальности.
Теперь наши наблюдения и причина этой главы. За последние пару лет мы стали свидетелями того, как эти представления практически взяли все общедоступные данные, которые доступны в мире, и включили их в БЯМ. Для аргументации предположим, что 100% таких данных попали в БЯМ. Теперь сравните это с нашей ранее опубликованной оценкой, что лишь 1% корпоративных данных попал в готовую БЯМ. Это очень интересный контраст: почти все общедоступные данные попали внутрь, а почти все корпоративные данные — нет.
Встаньте и представьте!...Ваши данные
К этому моменту в книге у вас должно быть представление о том, насколько важным является момент перегиба в эре ИИ. Данные, собранные в огромных объемах, — это хорошо решаемая проблема (понимание — другая проблема), а вычислительная мощность доступна в больших масштабах — эти силы, синергизированные с новыми методами ИИ, создали идеальный шторм для деструкции ИИ. Итак, с чего начать использовать ваши данные в работе? Как мы обсуждали в Главе 5, вы должны начать с доверенной БЯМ. Как только вы идентифицировали базовую модель, которой можете доверять, пришло время включить ваши корпоративные данные в это представление, основанное на данных этой эры. Наконец, вы развертываете вашу настроенную модель и масштабируете ее, создавая ценность с помощью вашего ИИ. Итак, давайте поговорим об этих трех шагах.
Шаг 1: Все начинается с доверия
Не недооценивайте этот поворотный момент для ИИ: с этого момента все в ИИ будет иначе из-за этого новейшего репрезентационного формата.
В конечном итоге, для создания ценности из ваших корпоративных данных, самый первый шаг не имеет ничего общего с вашими данными. Ваш первый шаг будет заключаться в выборе надежной модели — представьте ее как «ценный» сосуд или основу, на которой вы будете строить. Этот шаг критически важен, потому что ваши корпоративные данные будут добавлены поверх этой отправной точки, поэтому будет очень полезно знать, что уже находится внутри этой основы, какой «рецепт» был использован для ее создания, и как она работает. Все это возвращает нас к Главе 1, где мы говорили вам спрашивать поставщика вашей БЯМ вопросы, такие как «Какие данные вы использовали для обучения вашей модели?» и считать ответы типа «Это не ваше дело» и «Мы не знаем» неприемлемыми. Опять же, действительно ли это отличается от того, где вы решаете построить дом? Фундамент должен быть прочным. Содержит ли ваш фундамент (БЯМ) нарушение авторского права, ненависть, гнев, нецензурную лексику (HAP), предвзятость, расизм, порнографию и многое другое? Если сегодняшние БЯМ являются сжатыми представлениями интернета, и вы верите, что все в интернете истинно, нет вредоносного контента, и у вас нет никаких из этих опасений, тогда все в порядке! Вы когда-нибудь просматривали ветку на Reddit и видели токсичность в некоторых из
224 | Глава 8: Использование ваших данных как дифференциатора
этих групп? (И в комнатах, куда мы не заходим, дела обстоят гораздо хуже.) Это то, что вы хотите смешивать со своими драгоценными данными, когда пытаетесь использовать их? Это будет в основе модели, которая в конечном итоге будет обогащена, чтобы представлять ваш бизнес!
Вернемся к *почему*, опираясь на ту же аналогию с качеством воды, которую мы использовали в Главе 5, обсуждая важность прозрачности происхождения данных в БЯМ. Представьте, что мы даем вам стакан воды (БЯМ), и ваше намерение — добавить лимонный сок и сахар (мы будем считать это вашими корпоративными данными) с целью приготовления лимонада. Если бы мы дали вам непрозрачный стакан, полный воды (БЯМ, о данных которой вы ничего не знаете, и когда вы спросите, откуда мы взяли воду, вам не дадут четких ответов), чувствовали бы вы себя комфортно, используя его с вашими свежими лимонами и дорогим органическим тростниковым сахаром? Подумайте об этом: стакан непрозрачный, вы даже не можете увидеть, что внутри! Вода внутри этого стакана могла быть чистой родниковой водой, но могла быть и мутной лужицей, или даже загрязненной водой! Если бы вы не могли увидеть, что внутри этого стакана, вы все равно пили бы то, что внутри, после добавления туда тонн высококачественного сахара и лимона? Вероятно, нет, так почему бы вам делать это с одним из самых ценных активов вашей компании — вашими данными?
Аналогично, с БЯМ практически невозможно изолировать или ограничить модель, чтобы она давала ответы, информированные *только* добавленными вами корпоративными данными, и игнорировала всю мутную воду (данные) в стакане. Конечно, такие техники, как генерация с извлечением (RAG) и тонкая настройка, могут помочь, но даже когда ваша модель настроена, она, скорее всего, все равно будет наследовать определенную степень производительности и безопасности (или их отсутствие) от базовой модели, которую вы использовали в качестве отправной точки.
В этой аналогии важно, чтобы стакан, который вам дали для приготовления лимонада, был *прозрачным*, чтобы вы могли видеть, что внутри. Вам нужно знать, откуда поступает вода, служащая основой для вашего лимонада, чтобы при смешивании ингредиентов у вас было хорошее представление о том, что произойдет, как это будет выглядеть и каков будет вкус. То же самое, когда вы хотите использовать свои данные с БЯМ. Вам нужна базовая модель, прозрачная с точки зрения используемых данных и рецепта. Таким образом, добавляя в нее свои данные, вы делаете это уверенно, безопасно и надежно.
Еще один аспект прозрачности — наличие широких коммерческих прав и свободы действий в отношении окончательной модели, которая создается. Помните, эта глава не о поставщиках моделей; это глава о *ваших данных*. Вам нужны разрешительные права на вашу улучшенную модель, чтобы, когда вы кодируете свою информацию в модель, которую вы выберете для своего бизнеса, у вас была *полная свобода действий*, чтобы делать то, что вам нужно для вашего бизнеса. И, поскольку вы строите на основе модели, содержащей общедоступные данные из внешнего мира, поставщик также должен предоставлять возмещение убытков от юридических претензий.
Встаньте и представьте!...Ваши данные | 225
1 Команда Granite, IBM, «Модели языка Granite 3.0», 2023 г., https://ibm.biz/granite-report.
Как мы говорили в Главе 5, убедитесь, что вы провели надлежащую проверку относительно того, какие возмещения убытков предусмотрены в вашей БЯМ. Сегодня каждый поставщик предлагает какое-то возмещение, но нужно знать, что защита возмещения убытков у каждого поставщика разная. Некоторые не возмещают убытки за то, что создано, некоторые полностью возмещают, некоторые ограничивают размер возмещения, некоторые не возмещают убытки за вывод, но возмещают за использование и так далее. Да, вам придется привлечь свою юридическую команду.
Коммерческий проект IBM — доверьтесь Granite
Повторим еще раз: мы надеемся, что вы согласитесь, что вся эта книга была посвящена чему угодно, кроме IBM. Мы надеемся, что вы оценили заботу, которую мы приложили к построению вашей проницательности в области ИИ, определению вариантов использования и указанию на что обратить внимание, а также на что убедиться, что у вас все в порядке, когда вы отправляетесь в свое путешествие с ИИ — и все это с парой крошечных рекламных роликов IBM. Сказав это, мы решили уделить себе страницу или две, чтобы сосредоточиться на модели с открытым исходным кодом, которой, как вы заметите, мы не уделяли много времени: IBM Granite. Мы очень гордимся серией IBM Granite, потому что она соответствует тем вещам, которые мы обсуждали: прозрачность данных, используемых для обучения моделей (проверьте страницы с подробной информацией о данных, использованных при обучении Granite 3 в его техническом отчете1 ); модели выпускаются в открытом доступе с некоммерческой лицензией Apache 2.0; и, что наиболее важно, семейство Granite разработано как экономичные, целенаправленные модели, которые можно дополнительно настроить с помощью корпоративных данных (мы углубимся в детали чуть позже в этой главе).
Figure 8-1 демонстрирует широту моделей в семействе IBM Granite 3 (и к тому времени, когда вы прочтете эту книгу, Granite 4, вероятно, будет выпущен, или близок к этому).
Вот высокоуровневый обзор того, для чего предназначены модели в Figure 8-1 и почему они важны:
Гранит Язык
Это ваши основные рабочие лошадки БЯМ для корпоративных языковых задач. Эти модели обеспечивают максимальную производительность для своего размера и разработаны для дальнейшей настройки с использованием таких техник, как PEFT и InstructLab.
Гранит Зрение
Это мультимодальные модели, специализированные на задачах понимания изображений (изображение + промпт, текст на выходе). Представьте себе их для любого понимания документов, Q&A по диаграммам, например, когда БЯМ объясняет трендовые линии и высказывает мнение о вещах на столбчатой диаграмме, или даже для мультимодальных задач RAG.
226 | Глава 8: Использование ваших данных как дифференциатора
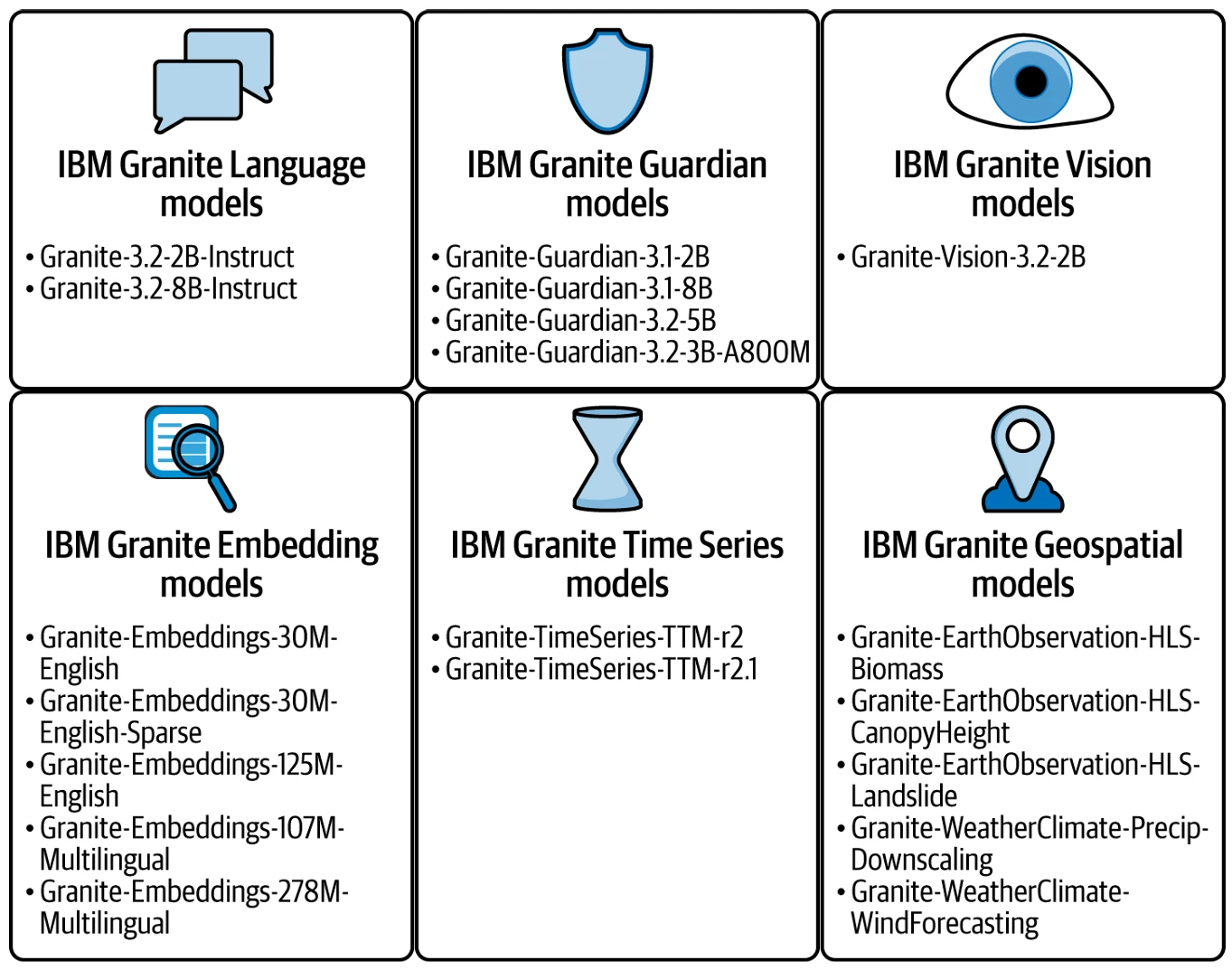
Figure 8-1
Гранит Страж
Это модели-«ограничители» (мы обсуждали их в Главе 5), которые размещаются рядом с любой развернутой БЯМ (не только Granite) и помогают мониторить входные и выходные данные модели, убеждаясь, что нет вредоносного или предвзятого контента, галлюцинаций и т.д.
Гранитное Встраивание
Эти модели преобразуют большие объемы языка и кода в векторные встраивания или числовые представления — это очень полезно для включения рабочих процессов RAG.
Гранит Временные ряды
Это очень маленькие прогностические модели на базе GenAI. Вместо того, чтобы обучаться на больших объемах языка, эти модели были обучены на больших объемах данных временных рядов, чтобы получить свои прогностические суперспособности.
Гранит Геопространственные
Эти мультимодальные модели Earth Science были разработаны в сотрудничестве с NASA для прогнозирования всего, от прогнозов погоды до количества биомассы на спутниковом изображении.
Figure 8-1. Снимок семейства моделей IBM Granite
Шаг 2: Представление ваших корпоративных данных в БЯМ
Как только вы выбрали надежную отправную точку модели (в нашей аналогии, это ваш прозрачный стакан, наполненный чистой водой, который вы будете использовать для приготовления лимонада), следующий шаг — выбрать метод, которым вы будете добавлять ваши корпоративные данные в эту основу (сахар и лимоны, которые превратят воду в лимонад). Существует множество доступных техник, включая эти распространенные шаблоны:
Генерация с извлечением (RAG)
Вы, возможно, уже знакомы с RAG, поскольку это один из топовых шаблонов, развернутых на предприятиях сегодня. Мы упоминали об этом шаблоне на протяжении всей книги, но здесь стоит явно поговорить о нем, потому что это довольно распространенный механизм добавления корпоративных данных в БЯМ. В шаблоне RAG, как только пользователь отправляет запрос, этот запрос используется для извлечения релевантной корпоративной информации из (обычно) базы данных, используя по сути сходство между текстом запроса и текстом в базе данных. (Эта база данных обычно является векторной базой данных, поддерживающей семантический поиск, но это может быть и традиционная реляционная база данных, или гибридная версия двух, и даже файлы в службе объектного хранения, среди прочих вариантов.) Затем исходный запрос пользователя объединяется с извлеченной информацией (часто называемой *контекстом обоснования*) в промпт, который подается в БЯМ. Теперь БЯМ может использовать как свои обширные знания, накопленные в процессе обучения, так и извлеченную информацию, предоставленную в промпте, для ответа на вопрос. Как вы могли заметить, в шаблоне RAG веса модели вообще не изменяются, и у этого есть свои плюсы и минусы. RAG — исключительная техника, особенно когда важно иметь самую свежую информацию при ответе на запрос пользователя (гораздо проще обновлять базу данных, содержащую самые свежие данные, чем переобучать или тонко настраивать модель с обновленной информацией). Однако у RAG есть и несколько недостатков. Во-первых, существует множество зависимостей и сложностей, которыми нужно управлять; RAG — это не просто модель, это система. Во-вторых, каждый раз, когда вы хотите, чтобы модель ответила на вопрос — например, о какой-то внутренней HR-политике — вам нужно предоставить полный текст этой HR-политики БЯМ (что также увеличивает затраты на вывод, снова и снова). С этим связано то, что БЯМ никогда по-настоящему не усваивает информацию, предоставляемую в рабочем процессе RAG, что означает, что она не учится новым концепциям и не применяет их по-новому в рамках различных задач.
228 | Глава 8: Использование ваших данных как дифференциатора
Тонкая настройка
Еще один распространенный подход к настройке БЯМ с корпоративными данными — это *тонкая настройка*. Тонкая настройка — это процесс, при котором фактические веса модели обновляются на основе новых данных (пар обучающих данных «ввод-вывод», о которых мы говорили на протяжении всей книги). Этот подход может быть выполнен с гораздо меньшими вычислительными ресурсами, чем переобучение исходной модели с нуля и с меньшим объемом данных. Эта техника предлагает более разумную отправную точку для Создателей ценности ИИ для начала настройки своих моделей. Существует множество различных типов техник тонкой настройки. Одна называется *обучение с учителем* (SFT), при котором обновляются все параметры, а другая — *эффективная тонкая настройка параметров* (PEFT), при которой обновляется только часть параметров. Существуют также методы, такие как *адаптация с низким рангом* (LoRA), при которой внешний (по отношению к БЯМ) модуль параметров обучается работать с базовой моделью. LoRA удобны, потому что эти модули можно удалить, когда они не нужны, или заменить на новые модули, когда модель выполняет другую задачу. Например, возможно, вы управляете компанией, выпускающей ролевые игры (RPG), и построили адаптер LoRA поверх вашей БЯМ для диалогов в игре и взаимодействия с неигровыми персонажами, но другой адаптер LoRA используется для рассказа истории. Адаптеры LoRA также имеют недостатки — как вы можете себе представить, если вам потребуется 50 тонко настроенных настроек, тогда вам придется управлять жизненным циклом 50 различных адаптеров. Мы также предполагаем, что поскольку они используют матрицы очень низкого ранга, в какой-то момент их объем данных может быть ограничен.
В конечном итоге, метод тонкой настройки, который вы выберете, будет зависеть от ваших целей производительности и ограничений по стоимости. Чем больше параметров вы настраиваете, тем лучше производительность, но тем дороже будет обучение модели. В то время как тонкая настройка предоставляет способ *внутреннего* улучшения модели на основе проприетарных данных, тонко настроенные модели также страдают от того, что называется *катастрофическим забыванием*. Это по сути означает, что как только вы тонко настроите модель на выполнение задачи, модель становится специалистом в ней; то есть, она очень хорошо справляется с этой задачей, но теряет (забывает) некоторую часть своей способности работать как универсал и выполнять задачи, которые она раньше умела делать. Это означает, что для каждой задачи, которую вы хотите обучить свою модель, вам нужно поддерживать отдельную, тонко настроенную версию этой модели (или, в случае LoRA, отдельный адаптер LoRA для каждой важной задачи).
InstructLab
InstructLab — это форма тонкой настройки с открытым исходным кодом, разработанная в Red Hat, которая специально создана для внедрения проприетарных корпоративных знаний в БЯМ совместным образом, сохраняя при этом универсальные возможности БЯМ.
Встаньте и представьте!...Ваши данные | 229
2 Шивчандер Судалаирадж и др., «LAB: Крупномасштабное выравнивание для чат-ботов», препринт, arXiv, 29 апреля 2024 г., https://arxiv.org/abs/2403.01081.
Представляем InstructLab
Метод InstructLab с открытым исходным кодом для настройки БЯМ был разработан изначально для решения проблем, с которыми сталкиваются практики в области ИИ, желающие специализировать и развертывать БЯМ для *специфических бизнес-нужд*. InstructLab не только облегчает специализацию модели на данных конкретного домена, но и стремится сделать вклад в БЯМ таким же простым, как вклад разработчика в любой другой программный проект. InstructLab появился для того, чтобы попытаться преодолеть некоторые разрывы между тем, как работает открытый исходный код программного обеспечения, и тем, как работает открытый исходный код ИИ, и теперь имеет как открытый исходный код, так и корпоративное предложение, поддерживаемое Red Hat.
InstructLab стремится формировать будущее GenAI, предоставляя структуру, позволяющую командам и сообществам вносить знания и навыки в существующие БЯМ доступным способом. Основой InstructLab является новый метод выравнивания моделей под названием Large-scale Alignment for chatBots (LAB).2
Как мы уже намекали в предыдущем разделе, существует множество сообществ, которые активно внедряют и расширяют открытые модели ИИ с разрешительной лицензией, но все они сталкивались с тремя основными проблемами, которые хорошо решаются для традиционного программного обеспечения с открытым исходным кодом, а именно:
Нет прямого способа внести вклад обратно в те базовые БЯМ
Улучшения появляются в виде форков (поищите, и вы найдете неконтролируемое, постоянно растущее массовое стадо лам — одноразовых, тонко настроенных версий БЯМ Llama — бродящих по нашему миру GenAI), и это заставляет вас выбирать «наиболее подходящую» модель, которая не легко расширяема. Кроме того, эти форки дороги в поддержке для создателей моделей, потому что что происходит, когда «родительская» Llama меняется? Как получить эти улучшения? И мы даже не учли просеивание огромного стада Llama, чтобы выяснить, какая Llama подходит именно вам.
Существует высокий барьер входа, если вы хотите внести вклад обратно в модель
Сделали что-то особенное? Придумали невероятную новую идею — и она работает? Вам нужно научиться форкировать, обучать и улучшать модели, чтобы увидеть, как ваша идея движется вперед, что требует чертовски много опыта.
Нет прямого управления сообществом и нет лучших практик по обзору, курированию и распространению форков моделей
Когда-нибудь видели, как пятилетние дети играют в футбол? Больше не надо.
InstructLab решает эти проблемы, предоставляя вам инструменты для создания и объединения вкладов (навыков и/или артефактов знаний) в БЯМ без необходимости наличия у вас команды с глубокими навыками инженерии ИИ.
230 | Глава 8: Использование ваших данных как дифференциатора
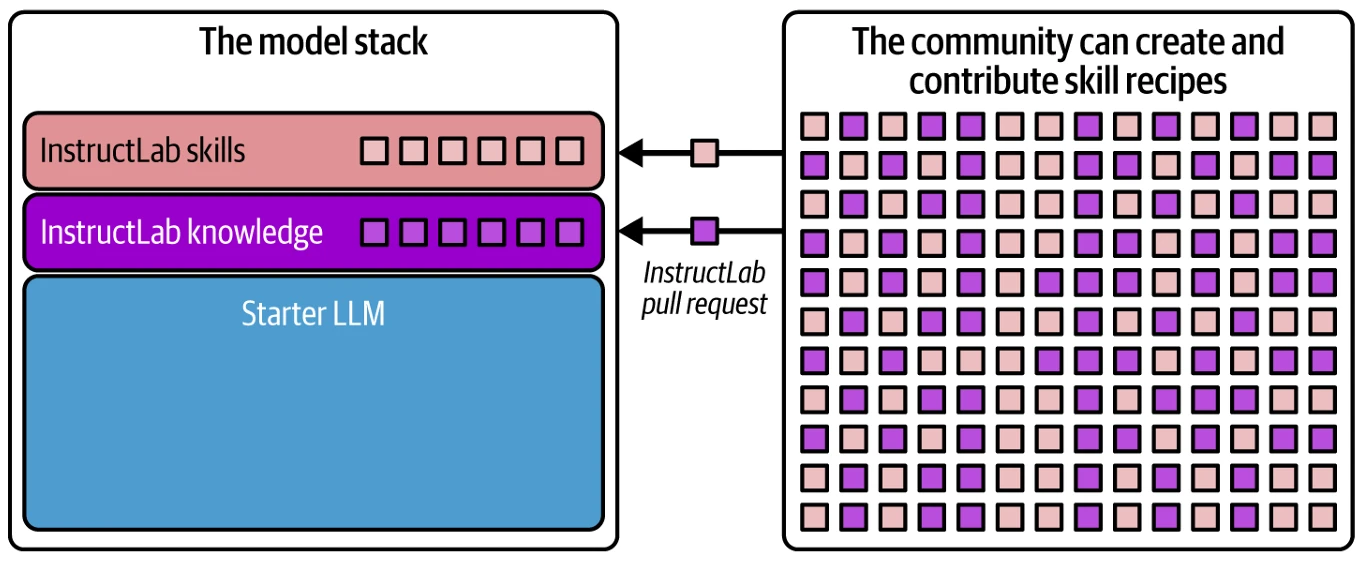
Figure 8-2
Окунемся в пул InstructLab
Технология InstructLab предоставляет моделям-источникам с достаточными инфраструктурными ресурсами возможность регулярно создавать сборки своих настраиваемых моделей — не путем перестройки и переобучения всей модели, а путем внедрения новых навыков и/или знаний. Она делает это с помощью комбинации трех ключевых процессов, которые мы рассматриваем в этом разделе:
- Методология курирования данных, основанная на таксономии
- Генерация синтетических данных — в масштабе
- Метод настройки инструкций, имеющий несколько фаз и избегающий катастрофического забывания
Жаргон
В открытом исходном коде *upstream* относится к оригинальному первичному источнику проекта (в нашем примере — оригинальная Llama). Именно там происходит основная работа. Другие версии, производные от него, известны как *форки*. *Upstream* модели — это основная авторитетная версия семейства моделей. Если *форкеры* хотят внести свои улучшения в *upstream* версию, им необходимо инициировать *pull request* (терминология кодеров для отправки изменений в *upstream* основной проект), который должен быть утвержден сопровождающими *upstream* модели. Этот процесс, который является центральным для открытого исходного кода, гарантирует, что основная модель актуальна и получает преимущества от *downstream* (форков и производных основного проекта) улучшений, внесенных более широким сообществом; более того, это дает сообществу возможность внести изменения в *upstream* для улучшения общего проекта. По сути, это позволяет БЯМ, такой как Llama, становиться в тысячи раз лучше, вместо того чтобы иметь тысячи разных моделей Llama в этом постоянно расширяющемся стаде, как в нашей предыдущей аналогии. Группа *коммиттеров* и *сопровождающих проекта* решают, какие *форки* вернуться в модель. А когда вы глубоко вовлечены в проект и внесли много исправлений или улучшений в него, вы можете продвинуться вперед и стать одним из тех людей, у кого есть последнее слово в отношении того, куда движется проект (или модель в данном случае).
Проект InstructLab предоставляет разработчикам инструменты для добавления и объединения новых навыков и/или знаний в любую открытую БЯМ через рабочий процесс GitHub — прямо с их ноутбука.
Через проект InstructLab, показанный на Figure 8-2, команды могут вносить «рецепты» выравнивания LAB для новых навыков и/или знаний (ваши корпоративные данные) через pull request в проект InstructLab. Все принятые рецепты навыков и/или знаний впоследствии добавляются поверх данного предварительно обученного стартера во время фазы выравнивания модели сопровождающими проекта InstructLab (будь они с общедоступной моделью или частной в вашей компании).
Встаньте и представьте!...Ваши данные | 231
Figure 8-2. InstructLab предлагает новый способ внесения вклада в сообщество
Возможность внесения вкладов на этапе выравнивания модели, а не инвестирование ресурсов в трудоемкий процесс предварительного обучения новых базовых моделей, позволяет реализовать гибкий итеративный процесс разработки, хорошо подходящий для совместной работы внутри вашей компании (или в открытом сообществе, возможно, в рамках отрасли, где консорциум бизнесов работает вместе над созданием модели, специально разработанной для их отрасли). Мы видели это своими глазами. Предварительное обучение БЯМ может занимать месяцы и тысячи сверхдорогих графических процессоров, испаряющих воду и ваши деньги. В отличие от этого, с использованием InstructLab, данную БЯМ часто можно выравнивать с использованием методов тонкой настройки менее чем за день, что позволяет значительно ускорить цикл выпуска обновлений.
Чувствуете запах готовки? Рецепты навыков и знаний
По сути, рецепт навыка или знания — это просто набор инструкций о том, как программно генерировать большое количество размеченных синтетических данных (опять же, ИИ помогает ИИ), которые иллюстрируют заданный набор навыков или область знаний. Каждый рецепт состоит из краткого описания пробела в навыках или знаниях, а затем пяти или более примеров, созданных вручную. В случае рецепта знаний входные данные также будут включать источник знаний, такой как руководство по льготам компании в случае использования в HR, которое охватывает требуемую тему.
Эти рецепты предоставляются в виде промпта для более крупной учительской модели (InstructLab дебютировал с Mixtral-Instruct в качестве учительской модели), который используется для генерации большого объема соответствующих синтетических данных. Зачем синтетические данные? Это критически важный компонент InstructLab, потому что у многих компаний недостаточно целевых данных для обучения (с использованием InstructLab или более стандартных методов PEFT) чему-то столь же масштабному, как БЯМ, для их ультра-специфических задач. Синтетические данные — это также то, как InstructLab превращает большие корпусы неструктурированных корпоративных данных в структурированный набор данных, который можно использовать для обучения вашей модели. Как только эти данные сгенерированы, их можно использовать для тонкой настройки вашей БЯМ, чтобы обучить ее недостающим навыкам или знаниям, которые вы хотите передать своей модели в вашей компании.
232 | Глава 8: Использование ваших данных как дифференциатора
Использование синтетических данных для выравнивания модели не является новой идеей само по себе. Фактически, существует множество примеров использования синтетических данных для выравнивания моделей, включая примеры дистилляции моделей (как мы обсуждали в Главе 7). Например, Vicuna-13B обучалась на синтетических данных, сгенерированных из GPT-4. Но опять же, есть проблема. Условия и положения OpenAI не поддерживают использование GPT-4 для создания коммерчески конкурентных моделей, что ставит под сомнение жизнеспособность этих моделей. Есть и другие модели, на которые мы могли бы указать, но все они требуют закрытых моделей, таких как GPT-4, в качестве учительской модели для генерации необходимых синтетических данных. И именно здесь проявляется, как открытый исходный код движет технологиями вперед. Что делает метод LAB столь привлекательным, так это то, что он доказывает возможность использования разрешительно лицензированных моделей с открытым исходным кодом (примером которых является Apache 2.0) в качестве учительских моделей, при этом достигая передовой производительности (SOTA).
На сегодняшний день все рецепты навыков и/или знаний, внесенные в проект InstructLab, отображены в логической, иерархической таксономии InstructLab. Проще говоря, таксономию можно представить как древовидную структуру, организующую вещи по категориям и подкатегориям (см. Figure 8-2). Для InstructLab таксономия классифицирует образцы данных на более мелкие группы (каждая ветвь далее делится на более специфические уровни), которые в конечном итоге поддерживают различные задачи (листья на ветви). Это дает разработчикам визуальную структуру не только для выявления навыков и знаний, которые могут помочь проекту, но и способ обнаружить и заполнить пробелы новыми знаниями и навыками, которые они хотят внести.
InstructLab учится, как учатся люди
Выходит за рамки этой книги углубляться в то, как работают знания и навыки в InstructLab, но стоит уделить этому моменту немного времени. Точно так же, как и в нашей жизни, подход InstructLab похож. Например, его таксономия имеет знания, и (как и в вашей жизни) знания можно найти в книгах, и это действительно один из источников знаний для InstructLab. Чтобы выполнять некоторые довольно сложные задачи, нам, людям, необходимо иметь базовый набор фундаментальных навыков, который мы можем добавить к нашим знаниям, и InstructLab не отличается. Например, прежде чем вы сможете попросить ИИ использовать чистую приведенную стоимость (NPV) в качестве входных данных для определения, является ли что-либо хорошей инвестицией или нет, ей необходимы базовые математические навыки, такие как показатели степени, порядок операций и понятия временной стоимости денег (TVM). Наконец, как и люди, он объединяет знания и фундаментальные навыки для выполнения сложных задач — это называется композиционными навыками в InstructLab. Если ваша БЯМ является частью агентного рабочего процесса, которому нужно написать отчет с рекомендациями на основе NPV, ему потребуется все то, о чем мы только что говорили; ему нужно знать математику, как писать, нюансы и многое другое.
Таксономия InstructLab также помогает гарантировать, что будет сгенерирован разнообразный набор синтетических данных, охватывающий все различные подзадачи, которые могут потребоваться при внесении вклада в рецепт для любой высокоуровневой задачи.
Встаньте и представьте!...Ваши данные | 233
Рассмотрим БЯМ, помогающую агенту с задачей написания постов для социальных сетей, как в нашем агентном примере в прошлой главе. То, как вы публикуете в X (ранее известном как Twitter), отличается от LinkedIn или Instagram. Некоторые платформы требуют коротких форм из-за ограничений символов; эмодзи более распространены в других; некоторые платформы очень основаны на изображениях, в то время как другие требуют большей бизнес-проницательности. Это навыки написания, специфичные для социальных сетей. В сниппете таксономии InstructLab, показанном на Figure 8-3, если участник пытался улучшить способность модели писать посты для социальных сетей, он мог внести вклад в ветвь social_media (или создать новую, если она не существует), которая находится в ветви freeform, которая находится в ветви writing таксономии навыков. Его вклады были бы рецептами синтетических данных для каждой целевой социальной сети. Хотите, чтобы ваш ИИ стал поэтом? Предоставьте ему примеры различных видов поэзии и создайте навыки, специфичные для хайку, для сонета, для лимерика и так далее.
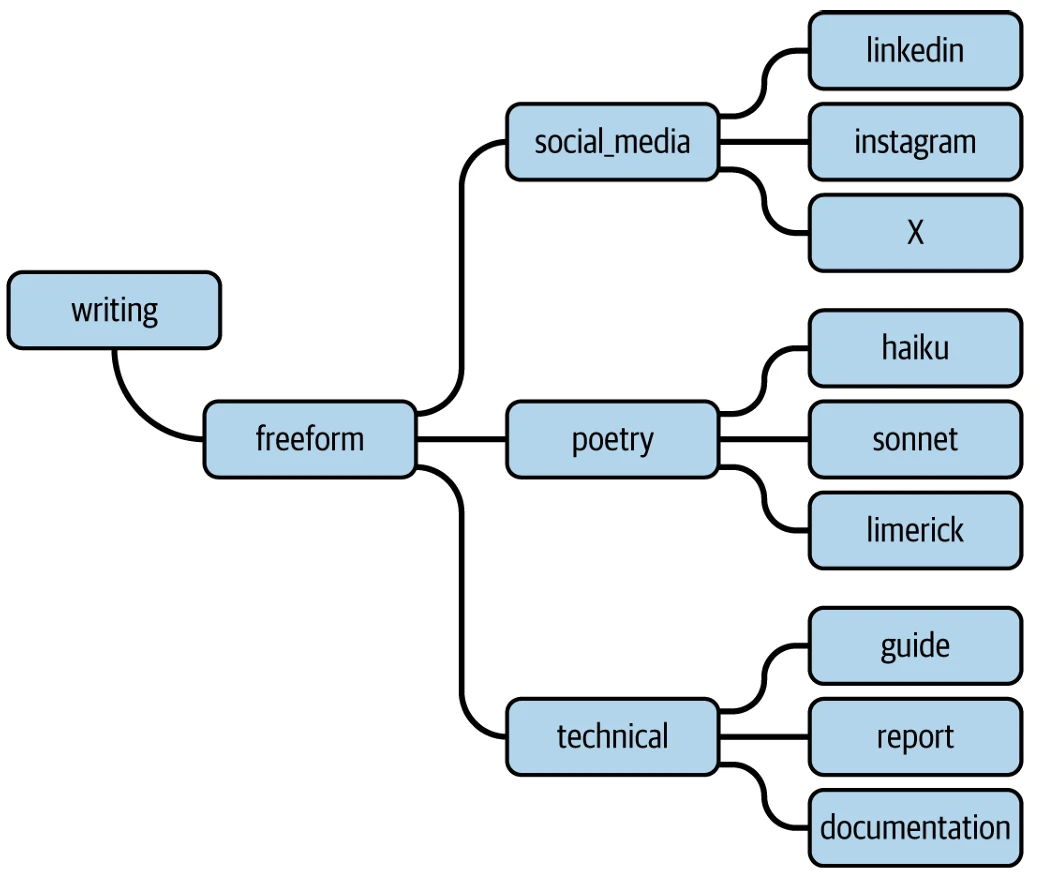
Figure 8-3
Figure 8-3. Пример таксономии навыков InstructLab для написания
Уникальный режим обучения LAB ассимилирует эти новые данные во время фазы выравнивания, вместо дорогостоящей фазы предварительного обучения, где большинство БЯМ наполняются своими базовыми знаниями и возможностями. И снова, этот протокол обучения также снижает катастрофическое забывание. Проще говоря, InstructLab работает таким образом, что недавно добавленные знания не перезаписывают то, что модель уже узнала.
Когда все рецепты синтетических данных будут представлены и добавлены в таксономию проекта, конвейер обучения и генерации InstructLab запустит все рецепты для генерации синтетических данных. Затем он отфильтрует сгенерированные данные, включив только высококачественные данные.
234 | Глава 8: Использование ваших данных как дифференциатора
образцы, и, используя новый поэтапный подход тонкой настройки, выравнивает каждую из стартовых моделей (ученических моделей) с использованием сгенерированных синтетических данных, тем самым внедряя в модель все внесенные навыки и знания. Поскольку картинка стоит тысячи слов, как говорится, мы обобщили весь этот рабочий процесс на Figure 8-4.
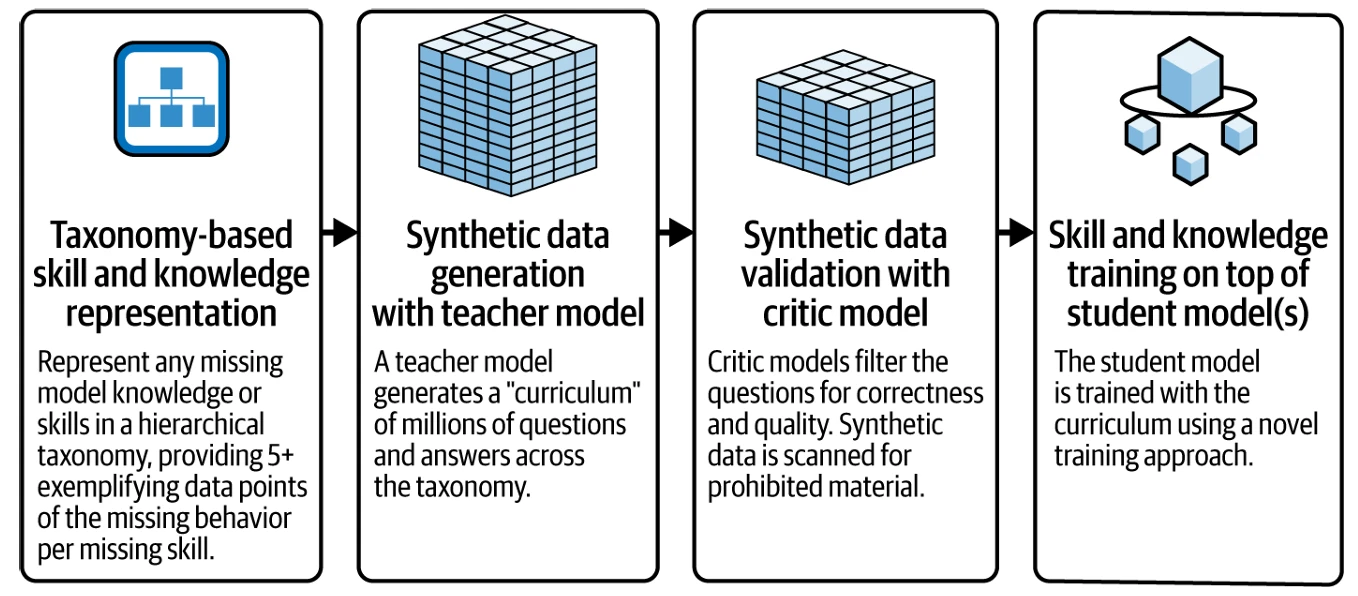
Figure 8-4
Figure 8-4. Как работает крупномасштабное выравнивание для чат-ботов (LAB)
Использование силы сообщества
Чтобы ускорить инновации, версия InstructLab с открытым исходным кодом взяла на себя обязательство проводить периодические циклы обучения и выпуска моделей, обученных сообществом. Последние версии моделей InstructLab публикуются на Hugging Face, который, как вы знаете из первой части этой книги, является сердцем крупнейшего организованного сообщества ИИ в мире. Доступность Hugging Face дает сообществу возможность загрузить модель, настроенную с помощью InstructLab, поэкспериментировать с ней и найти пробелы в ее производительности. Как только они выявлены, члены сообщества могут создавать и вносить свои собственные рецепты навыков и знаний обратно в проект InstructLab через pull request. Как и следовало ожидать от традиционных проектов с открытым исходным кодом, коммиттеры и сопровождающие проекта InstructLab просматривают вклады и объединяют все принятые вклады обратно в основную модель раз в неделю. Конечно, для ваших собственных частных моделей вы можете делать все это внутри своей компании и работать таким же образом.
Для поддержки разработчиков, использующих и вносящих вклад в модели InstructLab, проект InstructLab включает инструмент командной строки под названием Language Model Development Kit (LMDK). LMDK реализует рабочий процесс InstructLab на ноутбуке участника. Представьте это как тестовую кухню для опробования и представления новых рецептов для генерации синтетических данных, чтобы научить БЯМ новым навыкам. Теперь разработчик готов и сразу может начать, и, возможно, они начнут экспериментировать с локальной версией своей БЯМ с открытым исходным кодом (например, Granite). Они могут найти некоторые пробелы или области в производительности модели, которые они хотят улучшить, приготовить какой-то набор знаний или навыков
Встаньте и представьте!...Ваши данные | 235
рецептов, чтобы заполнить их, и вуаля! Весь этот процесс (как показано на Figure 8-5) действует как маховик для быстрых инноваций в области ИИ с открытым исходным кодом.
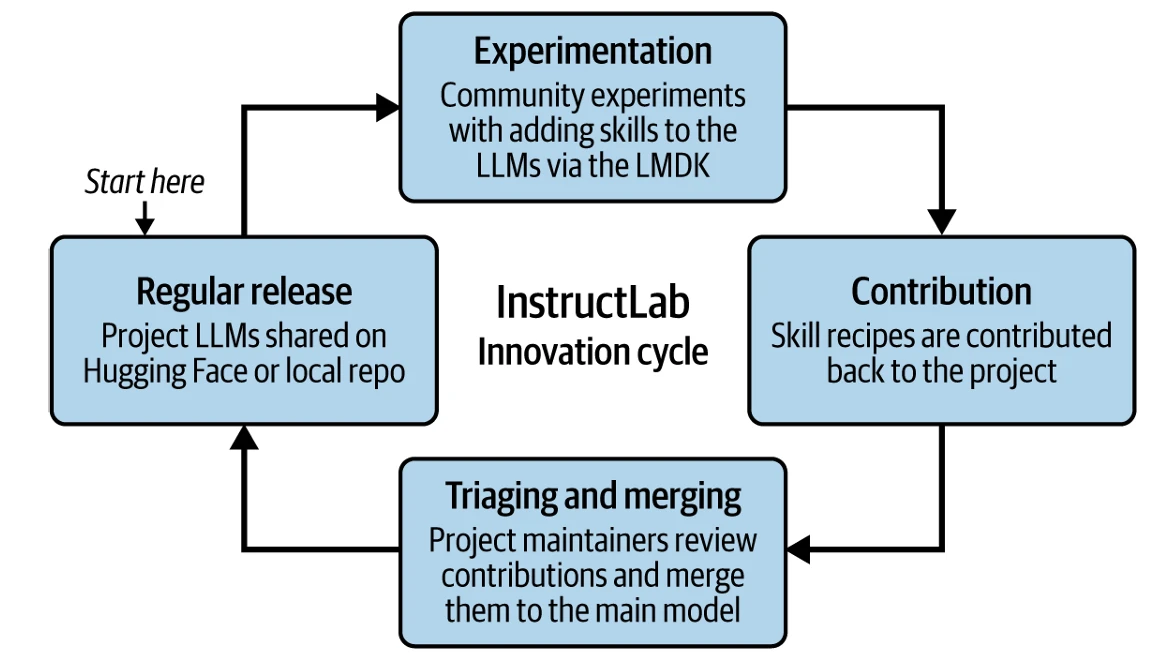
Figure 8-5
Figure 8-5. Инновационный цикл InstructLab: маховик для быстрых инноваций с открытым исходным кодом
Один день из жизни участника InstructLab
Как мы уже говорили ранее, эта книга выходит за рамки этой темы, чтобы показать вам весь процесс InstructLab, но существует множество уроков, которые вы можете легко найти с пошаговыми инструкциями, которые превратят вас в героя-участника в кратчайшие сроки.
Figure 8-4 дала вам представление об аспектах участия в InstructLab, и, как вы уже поняли, все начинается с рецепта навыка. Следующий код показывает, как на самом деле выглядит рецепт навыка рифмования (он написан на YAML):
version: 2 task_description: 'Научите модель рифмовать.' created_by: rob-paul-kate seed_examples: - question: "Назовите 5 слов, рифмующихся со словом 'boring'?" answer: "snoring, pouring, storing, scoring, and exploring." - question: "Назовите 5 слов, рифмующихся со словом 'dog'?" answer: "log, cog, frog, bog, and smog." - question: "Назовите 5 слов, рифмующихся со словом 'happy'?" answer: "snappy, crappy, scrappy, unhappy, and sappy." - question: "Назовите 5 слов, рифмующихся со словом 'bank'?" answer: "shank, crank, prank, sank, and drank." - question: "Назовите 5 слов, рифмующихся со словом 'fake'?" answer: "bake, lake, break, make, and earthquake."
236 | Глава 8: Использование ваших данных как дифференциатора
Далее, используя локальную версию генератора синтетических данных InstructLab, вы создадите свои собственные синтетические данные выравнивания для навыка или знаний, которые вы строите. Затем эти данные могут быть использованы для выравнивания вашей собственной локальной версии модели и быстрого тестирования, чтобы увидеть, закрывает ли ваш вклад пробел. Вы можете продолжать экспериментировать с этим процессом, пока ваша модель не сможет выполнить задачу, которую вы хотите. Как только ваш рецепт будет усовершенствован в LMDK, вы отправите его в виде pull request в таксономию InstructLab на GitHub, как вы сделали бы это для любого другого проекта с открытым исходным кодом или внутреннего программного проекта. Затем группа коммиттеров принимает или отклоняет предложения, обновляя окончательную таксономию новыми YAML-файлами. (Опять же, этот сценарий может быть общедоступным или полностью внутренним для вашей компании.)
Финальный шаг InstructLab — это процесс сборки, который может выполняться регулярно, периодически обновляя вашу БЯМ с (например) последними и лучшими вкладами от вашего сообщества разработчиков. В этом процессе сборки все сгенерированные до сих пор синтетические данные агрегируются и используются в многоэтапном процессе обучения, разработанном для максимизации производительности и снижения таких проблем, как катастрофическое забывание. Когда новая сборка вашей модели доступна, у вас теперь есть БЯМ, настроенная на все корпоративные данные, представленные вашими разработчиками и экспертами в области.
Хотя InstructLab находится еще на ранних стадиях, мы видим, что этот сквозной процесс специализации малых моделей на корпоративных данных может привести как к улучшению производительности (чем выше, тем лучше), так и к значительному снижению затрат по сравнению с использованием одной большой универсальной модели, как показано на Figure 8-6.
В сценариях, связанных с высокочувствительной организационной информацией — такой как данные о здоровье сотрудников или дисциплинарные записи — непосредственное встраивание этих чувствительных данных в БЯМ, вероятно, не то, что вы хотите делать. Вместо этого, вы можете использовать свои данные для настройки вашей БЯМ через InstructLab и тесно согласовать ее с вашим брендом, стилем, культурными ценностями и т. д., и отдельно хранить эту чувствительную информацию безопасно в системе RAG с контролируемым доступом. Этот подход позволяет вашей настроенной БЯМ беспрепятственно и безопасно получать доступ к чувствительным данным только при необходимости, обеспечивая как улучшенную коммуникацию, так и строгую конфиденциальность данных. Аналогично, если у вас были данные в домене, который постоянно менялся или где вариант использования требовал самых свежих данных, RAG, вероятно, больше подходит для этих данных.
Встань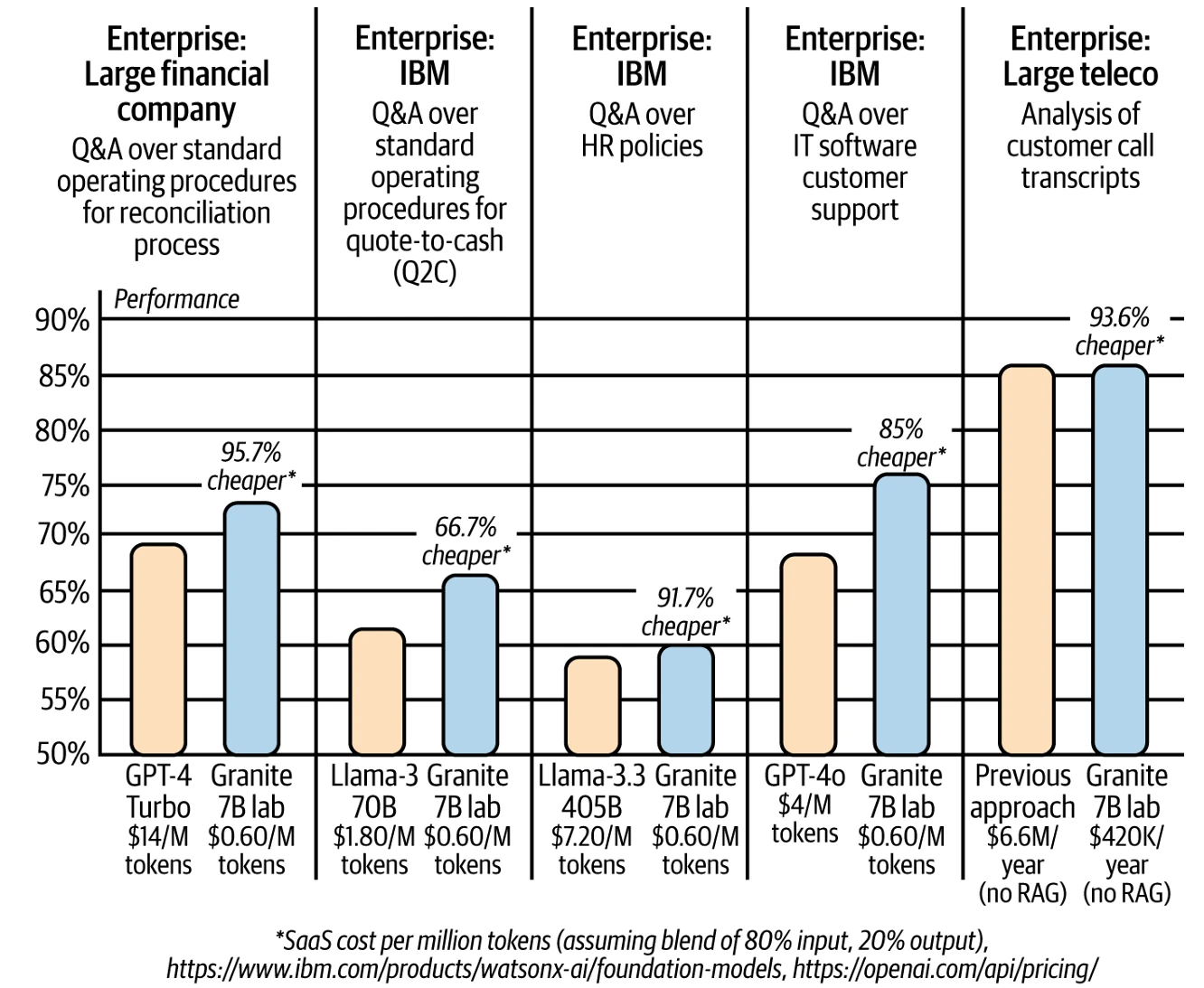 те и представьте!...Ваши данные | 237
те и представьте!...Ваши данные | 237
Figure 8-6
Figure 8-6. Демонстрация влияния InstructLab
Шаг 3: Гранд-финал: Развертывание и экспериментирование
Нет смысла иметь надежную БЯМ, обогащенную вашими данными, если никто в вашей компании не может ее использовать. Это делает финальный шаг — развертывание вашего нового актива, основанного на данных, создающего ценность. Итак, что нужно, чтобы сделать это реальностью? Много экспериментов. Если вы вспомните каждую предыдущую трансформационную технологию (например, интернет), история показывает, что есть точка перехода от экспериментирования к масштабному развертыванию.
В нашем мире сегодня существует невероятный азарт, предвкушение и ожидание, связанные с GenAI и агентами. Мы видим приложения и API, которые могут повлиять на сотни миллионов потребителей. Действительно, тип азарта, который генерируется, можно сравнить с появлением веб-браузера (момент Netscape, о котором мы говорили в Главе 1). Но, если подумать об этом сравнении с интернетом, корпоративная ценность не была раскрыта сразу после появления Netscape. Только когда интернет связал все: от запасов до цепочек поставок, до фронтенда и омниканальных каналов. Мы считаем, что ИИ пройдет ту же эволюцию: от +ИИ к ИИ+.
238 | Глава 8: Использование ваших данных как дифференциатора
Чтобы раскрыть ценность ИИ на предприятии, вам нужно уметь развертывать его в масштабе по всему предприятию. Но чтобы достичь этого, вам понадобится управляемая среда, позволяющая экспериментировать, настраивать модели с помощью ключевых рабочих процессов, таких как RAG, тонкая настройка и InstructLab, а затем переходить от этих моделей к развертыванию в масштабе.
Важно отметить, что ваши настроенные модели теперь представляют ценную корпоративную интеллектуальную собственность (ИС), поэтому при развертывании необходимо принять ключевые бизнес-решения. Решения, такие как: можете ли вы доверять своей модели работать в облаке, или данные, представленные вашей моделью, настолько чувствительны, что их можно развернуть только локально? Нужны ли вам превентивные и реактивные защитные ограждения, о которых мы говорили в Главе 5, чтобы убедиться, что ваши приложения, использующие эти модели, не злоупотребляются? Нужно ли вам активно мониторить производительность и безопасность ваших развертываний? И по мере того как GenAI проникает по всему вашему предприятию, вы расширяете поверхность атаки для цифровой эксплуатации, поэтому (опять же, из Главы 5) вам придется подумать о враждебных атаках и других новых способах, которыми плохие акторы могут попытаться эксплуатировать ваш цифровой шедевр.
Будущее открыто, совместно и настраиваемо
Большая часть интернета построена на программном обеспечении с открытым исходным кодом. Каждый день, осознаете вы это или нет, вы взаимодействуете с операционной системой Linux, и веб-сервер Apache помогает вам достигать ваших целей. Сегодня программное обеспечение с открытым исходным кодом также питает смартфоны, работающие на операционных системах Android, и криптографический протокол Secure Sockets Layer (SSL), который обеспечивает безопасность миллионов финансовых транзакций каждый день. Мы говорим вам, что открытые, построенные сообществом и настраиваемые на предприятии БЯМ могут принести те же преимущества. Предоставление весов БЯМ миру дает всем возможность инновационировать, тестировать, совершенствовать и формировать будущее этой мощной технологии. Позволяя строителям понять происхождение данных, это способствует доверию и обеспечивает объяснимость.
Прозрачное программное обеспечение с открытым исходным кодом делает системы более стабильными и безопасными. Это может привести к более быстрым, более предсказуемым циклам выпуска и более безопасному программному обеспечению, связанному с ИИ. Улучшение доверия и прозрачности БЯМ — одна из главных целей проекта InstructLab.
Программное обеспечение с открытым исходным кодом также стимулирует здоровую конкуренцию, которая предотвращает монополизацию отрасли одной или двумя компаниями. Когда всем разрешено участвовать, процветают инновации, и затраты для потребителей обычно снижаются.
Теперь вы открыли секрет превращения ваших данных в ваше конкурентное суперспособность. Но прежде чем броситься доминировать в своей отрасли (или, по крайней мере, произвести впечатление на своих коллег), давайте заглянем в наш не-ИИ хрустальный шар (это просто наши мысли, у нас его на самом деле нет) и сделаем образованное предположение о том, какие захватывающие приключения ждут в постоянно развивающемся ландшафте Gen AI и агентов.
Будущее открыто, совместно и настраиваемо | 239