Куда движется эта технология — Одна модель не будет править всеми!
Можете ли вы понять эту мантру?
"Одно кольцо, чтобы править всеми,
Одно кольцо, чтобы найти их,
Одно кольцо, чтобы собрать их всех,
И во тьме связать их".
Если вы настоящий толкиенист, ваши эльфийские уши, вероятно, навострились; в противном случае, мы скажем вам, что это основа истории из культового «Властелина колец» Дж.Р.Р. Толкина, и эта надпись на Едином Кольце дает его носителю способность контролировать все. (Пуристы заметят, что не надпись давала силу, и затем перейдут к Саурону, но мы оставим это на этом; как мы сказали, нерды.) Полное доминирование. Оставляя все зло в стороне, возникает один вопрос (вероятно, из-за шумихи вокруг ChatGPT, который представил миру GenAI): будет ли одна единственная БЯМ править всеми?
Спойлер: мы так совсем не считаем. Даже близко нет. Как вы узнали ранее в этой книге, только на Hugging Face почти 1,5 миллиона (вероятно, больше к тому моменту, когда вы прочтете эту книгу) моделей. Мы также уверены (при условии, что вы прочитали книгу линейно до сих пор), что вы легко сможете объяснить разницу между Пользователями Ценности и Создателями Ценности, и вы понимаете этику ИИ и происхождение данных. Короче говоря, вы понимаете, почему одна модель не может править всеми... но мы дадим вам более полный ответ на вопрос, почему. Все начинается с того, что даже в лабораториях ИИ, разрабатывающих самые высокопроизводительные пограничные модели, мы видим сдвиг от инноваций в рамках одной модели, выполняющей одну задачу, к предоставлению системе моделей и техник возможности работать вместе и выполнять задачу. В этой главе мы хотим обратить ваше внимание на то, что происходит на рынке, и на какие тенденции
и технологические инновации подпитывают будущее GenAI. От стремительных инноваций, происходящих в сфере малых моделей, до внутри- и межмодельной маршрутизации, до захватывающих достижений в агентных системах, мы верим, что никогда не будет одной модели, которая будет править всеми.
Чем больше, тем лучше, верно? Возможно, сначала, но это было давно
Следуя нашей теме в этой книге, о том, что технологические годы стареют как собачьи (1:7), а годы GenAI — как мышиные (1:30), это делает 2018 год более чем 200-летним в годах GenAI — это было давно! Что произошло в 2018 году? OpenAI выпустила GPT-1 с всего 117 миллионами параметров.
В рамках своих поисков искусственного общего интеллекта (AGI) OpenAI выпустила последовательно более мощные версии GPT (некоторые до триллионов параметров), которые могут выполнять больше задач с каждым последующим выпуском.
ИИ и AGI не следует путать. GenAI — это инструмент. AGI — это цель эволюции этого инструмента до такой степени, чтобы его возможности соответствовали когнитивным способностям человека или даже превосходили их, в широком диапазоне задач. Мы еще не там, возможно, никогда не будем, или, возможно, это произойдет быстрее, чем мы ожидаем. Но когда речь заходит о AGI, подумайте о БЯМ, демонстрирующих и превосходящих человеческий интеллект.
Изначально казалось, что основным двигателем улучшения производительности моделей является просто увеличение размера модели. Как показано в Table 7-1, между GPT-1 и GPT-3 размер моделей, выпущенных OpenAI, увеличился более чем в 10 000 раз! После GPT-3 OpenAI прекратила публиковать размеры моделей, но GPT-4 и модели GPT-4o, по слухам1 , в один момент достигали более одного триллиона параметров! И по мере увеличения этих моделей они также становились дороже. Малые модели обычно стоят менее 0,25 доллара за 1 миллион выходных токенов (или «бесплатно», если вы можете получить их на своем ноутбуке с фреймворками типа Ollama). Напротив, большие модели дороже. Например, в последний раз, когда мы смотрели, затраты OpenAI на o1 составляли около 60 долларов за тот же объем выходных данных.2 Независимо от цены, которую вы платите (цены в этой области меняются так же быстро, как технология, в основном в хорошем смысле), высокопроизводительные малые модели имеют большой бизнес-смысл.
1 Максимилиан Шрайнер, «Архитектура, наборы данных, затраты и прочее GPT-4 утёкшее», The Decoder, 11 июля 2023 г., https://oreil.ly/6sD6g.
2 См. информацию о ценах API OpenAI онлайн.
180 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
Table 7-1 показывает, что по мере роста семейства моделей GPT мир наблюдал значительные улучшения в возможностях, которые эти модели могли достичь.
Table 7-1
Table 7-1. Семейство GPT от OpenAI со временем
| Название модели OpenAI | Параметры | Интересные моменты |
|---|---|---|
| GPT-1 | 117 миллионов | Это «оригинал». Было лучше некоторых предыдущих технологий, но оказалось, что это только начало чего-то большего. |
| GPT-2 | ~1 миллиард | Эта модель начала делать интересные завершения и доказала, что есть другой горизонт для обработки естественного языка (NLP). Она была далека от того, что вы впервые испытали с ChatGPT и далее, но она получила некоторую огласку в новостях за написание истории о единорогах.a |
| GPT-3 GPT-3.5 GPT-3.5 Turbo |
~175 миллиардов | GPT-3.5 была первоначальной моделью, лежащей в основе дебюта ChatGPT. По сравнению с GPT-2 произошли два важных изменения. Она была разработана для следования инструкциям (в отличие от простого предсказания следующего наиболее вероятного слова в предложении), и они добавили пользовательский интерфейс. Все сказано. GPT-3.5 также была выпущена как более эффективная, легковесная версия под названием «Turbo». |
| GPT-4 GPT-4 turbo GPT-4o GPT-4o mini GPT-4.5 |
OpenAI прекратила публикацию количества параметров после GPT-3 (которое, как отмечалось, имело 175 миллиардов параметров). Различные блоги предполагают, что GPT-4 имеет ~1,8 триллиона параметров. | Их четвертое поколение моделей предоставило больше мощности и мультимодальных возможностей. На момент публикации GPT-4o считалась флагманской моделью OpenAI, и только что вышла GPT-4.5. GPT-5 еще не вышел, когда мы ушли в печать, но многие предполагают, что его следует ожидать где-то в середине 2025 года. |
| OpenAI o1 OpenAI o3 mini |
(См. выше.) | Рассматриваемая как отдельный проект и не являющаяся частью основного семейства GPT, эти модели рассуждения были обучены производить длинные цепочки мыслей перед ответом, что позволяет им решать более сложные задачи. Ожидается, что эта возможность будет объединена в GPT-5. |
a См. историю на сайте OpenAI.
Это вызывает вопрос: нужна ли вам вся эта мощность для вашего бизнеса? Даже OpenAI начала создавать более мелкие, более эффективные версии своих моделей. Для каждого крупного выпуска модели выпускалась парная версия более эффективной и более экономичной альтернативы. GPT-3.5, встречайте GPT-3.5 Turbo; GPT-4o, встречайте GPT-4o mini.
Последняя модель рассуждения, выпущенная OpenAI на момент публикации этой книги, была OpenAI o3 mini. В то время как OpenAI изначально обязалась выпустить OpenAI o3, они с тех пор приостановили работу и объявили, что вместо этого GPT-5 представит систему ИИ, которая объединит лучшее от OpenAI o3 и серии моделей GPT, с
Чем больше, тем лучше, верно? Возможно, сначала, но это было давно | 181
3 См. обновление на https://oreil.ly/jCoxe.
4 Muddu Sudhakar, «Малые языковые модели (SLM): Следующий горизонт для предприятий», Forbes, https://oreil.ly/slTCo.
Сэм Альтман поделился целью «упростить наши продуктовые предложения» и «вернуться к магическому единому интеллекту».3
Подводя итог этому разделу, даже в пограничных лабораториях ИИ, прославившихся инновациями в масштабе, мы видим инновации и дорожные карты, сосредоточенные вокруг объединения нескольких моделей, работающих как система для достижения «единого интеллекта».
И несмотря на распространенное убеждение, что «больше — значит лучше», когда речь идет о размере моделей, существует множество захватывающих инноваций, позволяющих создавать малые, но мощные БЯМ. Настолько, что появился термин «малые языковые модели» (SLM)4 . Точного определения нет, но под SLM обычно подразумевают БЯМ размером менее 13 миллиардов параметров. В некоторых сценариях SLM достигли производительности БЯМ размером 100+ миллиардов параметров.
Рост малых языковых моделей
Возможно, самый простой способ описать феномен SLM заключается в том, что поставщики моделей становятся лучше в обучении. Пример: когда некоторые из наших исследовательских групп впервые получили доступ к Llama-2-70B в июле 2023 года, они были поражены тем, что он может делать. Всего чуть больше года спустя они смогли достичь той же, если не лучшей, производительности, используя версию Granite с 2 миллиардами параметров, согласно табло Open LLM v2 на Hugging Face (см. Figure 7-1).

Figure 7-1
Figure 7-1. Снимок производительности модели из табло Open LLM v2 на Hugging Face в феврале 2024 г.
182 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
Это, опять же, всего лишь часть естественного преимущества продвижения по кривой обучения; так же, как наши электромобили (EV) ездят дальше и быстрее заряжаются, мы получаем все больше пикселей и камер на наших телефонах каждый год, а наши телевизоры становятся тоньше, поставщики получают все больше опыта в обучении моделей, и новые инновации делают их более эффективными.
В следующих нескольких разделах мы хотим поделиться с вами некоторыми многообещающими стратегиями, лежащими в основе роста высококонкурентных SLM, в частности, курирование данных и дистилляция моделей.
Не случайно, что обе эти стратегии сосредоточены вокруг данных, используемых для обучения и тонкой настройки БЯМ. Многих наших собеседников удивляет, что чаще всего достижения, уменьшающие размер модели, связаны скорее с инновационными стратегиями работы с обучающими данными, чем с техническими инновациями в самой архитектуре модели. Пожалуйста, не поймите нас неправильно. Инновации в архитектуре определенно происходят. Фактически, мы рассмотрим некоторые захватывающие достижения в архитектуре в этой главе! Но, когда мы смотрим на огромную скорость, с которой SLM стали выдающимися (и они сделали это менее чем за год после выпуска ChatGPT в ноябре 2022 года), очевиден вклад: данные правят бал! И мы подробно рассмотрим эти тенденции, связанные с данными, потому что в Главе 8 мы покажем вам, как те же методы, которые сегодня используют поставщики моделей для создания SLM, могут быть использованы вашей компанией для дифференциации и создания ценности с корпоративными данными.
Итак, вот в чем дело: у вас есть данные. Данные, к которым у вас есть доступ, вообще не являются частью этих БЯМ. Почему? Потому что это ваши корпоративные данные. Мы можем заверить вас, что многие поставщики БЯМ хотят их. Фактически, причина, по которой 99% корпоративных данных не парсится и не извлекается в БЯМ, заключается в том, что вы не публиковали их в интернете. Итак, у вас есть несколько вариантов, о которых мы говорили ранее в этой книге, и мы углубимся в них в следующей главе. Где вы займете место в континууме обмена данными, о котором мы говорили в Главе 2? Планируете ли вы отдать их и позволить другим создать непропорционально большую ценность из ваших данных, по сути, превратив *ваши* данные в *ИХ* конкурентное преимущество, *ИЛИ* вы собираетесь сделать *ваши* данные *ВАШИМ* конкурентным преимуществом? В этом и заключается суть этой книги. И эта и следующая глава помогут вам увидеть это.
Курирование данных приводит к спасению ИИ
ОК, признаем, вы, вероятно, знаете это. Вам даже не нужно иметь опыт в машинном обучении, чтобы утверждать, что курирование большого количества высококачественных обучающих данных может оказать огромное влияние на производительность модели (или на любой аналитический проект).
Рост малых языковых моделей | 183
Но акцент на курировании данных является важной частью того, почему SLM стали такими эффективными, и это идет прямо против начальной философии ранних «выпечек» БЯМ: взять как можно больше грязных, неочищенных и неструктурированных данных и перепрофилировать их для питания БЯМ. Как оказалось, в отношении БЯМ для бизнеса компромисс необходим. Технология трансформеров позволила взять большое количество относительно грязных данных для создания БЯМ, но чем выше качество данных, тем выше качество модели. Спросите себя, есть ли у вас большие объемы высококачественных данных, специализированных для бизнеса, о которых вы заботитесь. Конечно, есть! Теперь вы готовы готовить на полную мощность, потому что количество, качество и специализация — три ключевых ингредиента курирования данных, которые помогли привести к росту SLM.
Объем данных
Сколько данных оптимально для заданного размера модели? Этот вопрос был предметом многих исследований сообщества ИИ, поскольку, как вы можете себе представить, с обучением БЯМ связаны очень высокие экологические и финансовые затраты. По этой причине первоначальный фокус ранних поставщиков моделей заключался в попытке оптимизировать производительность, минимизируя свои собственные первоначальные затраты на обучение моделей. Ключевой частью этой оптимизации было определение, сколько *токенов* (напомним, это по сути часть слова, целое слово или даже знак препинания) языковых данных следует добавлять в модель для каждого дополнительного параметра, добавленного к общему размеру модели, которую они обучали. Эти отношения — часто называемые *законами масштабирования* в научной литературе — определяют, сколько данных вам нужно для масштабирования модели по размеру.
В своей статье 2020 года5 команда исследователей OpenAI предположила, что для обучения каждого параметра БЯМ следует использовать около 2 токенов текста. Это соотношение 2:1 стало известно как закон масштабирования Каплана (мы предполагаем, что «закон масштабирования Каплана и др.» звучал не так хорошо) и впоследствии использовалось для обучения моделей, таких как GPT-3 и BLOOM (обе модели имеют 175 миллиардов параметров и обучались на 300–350 миллиардах токенов текста). В 2022 году Google DeepMind опубликовала6 альтернативный взгляд на оптимальные отношения масштабирования, называемый законом масштабирования шиншиллы. (Этот закон также известен как закон масштабирования Хоффмана, названный по имени ведущего исследователя; Шиншилла — это семейство моделей, опубликованных DeepMind.) Исследователи DeepMind полагали, что OpenAI резко недооценила количество данных, необходимых для оптимального обучения БЯМ... они считали, что оптимальное соотношение масштабирования для достижения наилучшей производительности модели при данном вычислительном бюджете составляет 20:1, в отличие от соотношения ~2:1. Они приступили к созданию 70-миллиардной БЯМ Chinchilla с использованием этого закона масштабирования. Как им это удалось? При всего 70 миллиардах параметров Chinchilla показала гораздо лучшую производительность, чем более крупные модели, такие как GPT-3 (175 миллиардов
5 Джаред Каплан и др., «Законы масштабирования для нейронных языковых моделей», препринт, arXiv, 23 января 2020 г., arXiv: 2001.08361 (2020). https://arxiv.org/abs/2001.08361.
6 Джордан, Хоффманн и др., «Обучение оптимальных по вычислениям больших языковых моделей», препринт, arXiv, 29 марта 2022 г., https://arxiv.org/abs/2203.15556.
184 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
7 Аарон Граттафиори и др., «Стадо моделей Llama 3», препринт, arXiv, 23 ноября 2024 г., https://arxiv.org/abs/2407.21783.
параметров). Оглядываясь назад, мы считаем, что Chinchilla была своего рода «OG» среди SLM (как говорят дети — это сленг для оригинала). Эта модель все еще довольно большая, но это не огромная модель с параметрами на трехзначное число миллиардов или больше.
Первоначальная цель исследовательского сообщества заключалась в определении законов масштабирования для оптимизации фиксированных первоначальных затрат на обучение своих моделей. Но что насчет постоянно возникающих маржинальных затрат на протяжении всего жизненного цикла модели? Сверхбольшая модель будет дороже в размещении и выводе. И кто понесет эти расходы? Вы, верно! Чтобы сократить эти расходы, вам нужно сократить размер модели. Чтобы сократить размер модели, сохраняя производительность, вам нужно обучаться на большем объеме (высококачественных) данных.
Именно поэтому SLM привлекают столько внимания. Поскольку затраты на вывод и размещение прямо передаются потребителям модели, реакция была несколько отложенной. Но по мере того, как GenAI превратился из любопытства в развернутую технологию, поставщики моделей начали оптимизировать свою настройку обучения, чтобы сделать ее максимально эффективной с точки зрения вывода, а не просто обучения.
Чтобы создать модели, эффективные с точки зрения вывода, может быть экономически выгодно обучать модель на более высоком соотношении данных, чем даже предлагалось законом масштабирования Chinchilla. На момент выхода этой книги в печать научное сообщество еще не пришло к единому закону масштабирования для моделей, оптимальных по выводу (и, возможно, никогда не придет), но существуют убедительные отраслевые примеры очень производительных SLM, обученных на гораздо больших объемах данных, чем предлагали доктрины Chinchilla или Kaplan (мы показываем некоторые из этих законов масштабирования со временем в Table 7-2).
В феврале 2023 года Meta открыла исходный код своей серии моделей Llama 2, обученных на примерно 2 триллионах токенов обучающих данных (в то время это считалось огромным объемом данных). В серии Llama 2 модель размером 7 миллиардов имела соотношение масштабирования почти 300:1! К августу 2024 года, с выпуском Llama 3, Meta удвоила (на самом деле, восьмерила) и выпустила модель Llama3.1-8B. Эта модель, обученная на более чем 15 триллионах токенов, имеет соотношение плотности данных почти 2000:1 и демонстрирует еще более высокую производительность, чем серия Llama 2.7 Чувствуете тенденцию? Meta сохранила размер своих SLM примерно таким же, но значительно улучшила производительность, просто обучая на большем количестве данных!
Table 7-2
Table 7-2. Законы масштабирования со временем
| Дата | Количество обучающих токенов/параметр | Закон масштабирования |
|---|---|---|
| 23.01.20 | 1.7 | Kaplan |
| 29.03.22 | 20 | Chinchilla |
| 01.02.23 | 286 | Llama-2-7B |
| 01.08.23 | 1875 | Llama-3.1-8B |
Рост малых языковых моделей | 185
8 Аарон Граттафиори и др., «Стадо моделей Llama 3», препринт, arXiv, 23 ноября 2024 г., https://arxiv.org/abs/2407.21783.
Фактически, в технической статье, сопровождающей этот выпуск, «Стадо моделей Llama 3» Meta цитирует, что ее флагманская модель с 405 миллиардами параметров, также обученная на ~15 триллионах токенов, является «примерно оптимальной по вычислениям» с точки зрения обучения, но ее более мелкие модели обучались «значительно дольше, чем оптимально по вычислениям». Результат? Модели демонстрируют лучшую производительность, чем модели, оптимальные по вычислениям, при той же скорости вывода.8 Проще говоря, хотя эти более мелкие модели были дороже в обучении (обучались дольше на большем объеме данных), они гораздо эффективнее в работе на этапе вывода. Результат? Сегодня модели Llama 3 являются одними из самых популярных моделей с открытым исходным кодом, и мы ожидаем, что когда в 2025 году выйдет Llama 4, она будет так же популярна.
Возвращаясь к SLM: при соотношении данных, требующем сотни токенов данных на каждый параметр в модели, модели, оптимизированные по выводу, и SLM начинают означать одно и то же. Практически невозможно иметь большую, оптимизированную по выводу БЯМ. Учитывая затраты на приобретение данных и объем доступных данных в мире, эти соотношения данных просто слишком дороги для поддержки обучения SLM, оптимизированных по выводу, которые имеют сотни миллиардов параметров. У нас просто недостаточно данных.
Возникает реальный вопрос: когда мы достигнем потолка данных? Сегодняшние модели обучаются на более чем 15 триллионах токенов, но чтобы достичь этого, поставщики моделей в основном вынуждены были исследовать весь интернет. И, как вы увидите в следующем разделе, нам не нужны большие объемы *любых* данных, нам нужны объемы данных очень *высокого качества*, которые гораздо труднее получить.
Качество данных
Можете ли вы представить себе песню «Cecelia» без Гарфанкеля, а только Саймона? А могли бы Холл и Оутс включить «Kiss on My List» в свой список, если бы они не начали эту песню с комбинации клавишных инструментов 1980-х годов и пошлых усов, которые великолепно кричали: «Романтика обеспечена? Просто нажмите кнопку воспроизведения?» (Да, юные читатели... тогда приходилось нажимать реальную громоздкую физическую кнопку.) И хотя мы музыкально устареваем, не только трудно понять, насколько великолепными могли бы быть эти песни без партнерства, но и столь же трудно выделить влияние объема данных от влияния качества данных на БЯМ. Качество, данные и очень производительные эффективные модели сочетаются вместе... точно так же, как Саймон и Гарфанкель, и Холл и Оутс.
Теперь, если вы верите, что интернет содержит только надежные данные, что интернет-данные не имеют предвзятости, нецензурной лексики, ненависти, лжи или гнева... ничего этого, тогда вы, вероятно, можете перестать читать эту книгу. Эта вера сродни тому, чтобы съесть галлон мороженого в день и удивляться, как ваши джинсы сели, когда вы стирали их только в холодной воде. Когда речь заходит о
186 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
9 Сурия Гунасекар и др., «Учебники — это все, что вам нужно», arXiv, 2 октября 2023 г., https://arxiv.org/pdf/2306.11644.
10 Кейт Книббс, «Битва за Books3 — это только начало», Wired, 4 сентября 2023 г., https://oreil.ly/58JTr.
GenAI, поговорка по-прежнему верна: что входило, то и выходило! Реальность по-прежнему такова: чем больше вы сможете курировать данные, используемые для обучения вашей модели (как с точки зрения обеспечения больших объемов, так и с точки зрения высококачественных размеченных примеров), тем выше производительность, которую вы сможете упаковать в свою модель. И хотя существуют некоторые техники улучшения производительности вашей модели после ее обучения — такие как генерация с извлечением (RAG) и многое другое, эти техники получают выгоду от высокого качества данных с самого начала (подробнее об этом чуть позже).
Microsoft публично признает, что качество данных играет критически важную роль в обеспечении производительности (в то время) передовой (SOTA) SLM Phi-2 размером 2,7 миллиарда параметров, которая по некоторым бенчмаркам превзошла более крупные модели в 25 раз. Но можно было сказать, что Microsoft учуяла этот путь вперед еще до Phi-2, потому что представила своего предшественника (Phi-1) миру в исследовательской публикации9 под названием «Учебники — это все, что вам нужно». В этой статье Microsoft описала, как «высококачественные данные могут даже улучшить передовые SLM, одновременно резко сокращая размер набора данных и вычислительные затраты на обучение». И точно так же, как люди лучше учатся по четко изложенным учебникам, результаты Microsoft подтверждают, что обучающие данные учебникового качества, которые являются «четкими, самодостаточными, поучительными и сбалансированными», приводят к более производительным БЯМ, демонстрирующим лучшие законы масштабирования; и, конечно, это позволило БЯМ с масштабом и производительностью Phi-2 стать (в то время) SOTA. На момент публикации этой книги Microsoft только что выпустила свою четвертую итерацию этого SLM: Phi-4. Подобно Phi-1 и Phi-2, Microsoft ссылается на «улучшенные данные» (среди других достижений в обучении) как на ключевой драйвер достижения сильной производительности Phi-4 по сравнению с его размером.
Хотя мы говорили об этом ранее в книге, это настолько важно, что мы подумали, что стоит повторить это здесь, потому что высококачественные данные критически важны для SLM. Хотя многие поставщики моделей прозрачны в отношении объема данных, используемых для обучения БЯМ, очень немногие поставщики прозрачны в отношении фактических источников данных, использованных для обучения их БЯМ. Фактически, если вы спросите самых популярных поставщиков БЯМ, какие данные они использовали для обучения своей модели, они либо не смогут вам сказать, либо скажут, что это не ваше дело, на что вам следует ответить: «Но это мое дело!»
Суть в том, что наборы данных самого высокого качества — это длинные учебники или другие научные книги, написанные и защищенные авторским правом людьми — а не сообщения на Reddit среднего или высокого уровня и другие свободные источники информации. Высококачественные артефакты данных — это не общие снимки веб-контента, размещенные на общедоступных сайтах, которые могут собирать автоматизированные краулеры. Уродливая правда многих популярных БЯМ заключается в том, что их включение многих наборов данных самого высокого качества (например, корпус Books310 , который мы впервые представили вам в Главе 5) к сожалению, доступно только для использования в обучении моделей, потому что они были
Рост малых языковых моделей | 187
пиратски скопированы и опубликованы без разрешения автора. Опять же, некоторая наша предыдущая тяжелая работа была пропылесосена во внутренности множества БЯМ, чтобы все остальные воспользовались ею и другие получили прибыль. Мы не получили выбора. Нас даже не спросили; это просто случилось. И хотя мы не подаем в суд (мы не писали бестселлер под названием «50 оттенков больших данных», который слетел с полок, и Голливуд хотел снять его в кино), есть много людей, чьи средства к существованию и бизнес-различия были «украдены», чтобы создать БЯМ, которую вы, вероятно, также использовали. Все это возвращает нас к обсуждению ценностного обмена, которое мы вели в разделе «Как вы потребляете ИИ: быть ли вам Создателем ценности или Пользователем?» на странице 42.
Только прозрачные политики сбора и курирования данных могут гарантировать, что БЯМ, которые вы оцениваете для своего бизнеса, не были созданы на основе неэтично полученных данных. Вывод? При оценке SLM, где курирование данных критически важно для производительности (и оставляя в стороне юридические последствия), повышенное осознание того, откуда взялись данные за моделью, имеет решающее значение. Задавайте вопросы. Требуйте ответов.
Доменная специализация
Будучи спортсменом выходного дня, вы возвращаетесь домой с лодыжкой, которая подает смешанные сигналы — либо претендует на участие в скоростном реалити-шоу «Думаешь, ты сломал лодыжку?», либо просто драматизирует из-за растяжения. В любом случае, это требует льда и внимания. Теперь вам предстоит выяснить, что происходит. Чтобы определить это, вы спрашиваете самого умного человека, которого знаете, или спрашиваете врача? (Не будьте наглыми... мы знаем, что некоторые из вас только что сказали вслух: «Самый умный человек, которого я знаю, — врач».) Хотя самый умный человек, которого вы знаете, может обладать потрясающими талантами, охватывающими поэзию, химию, философию и многое другое, вам гораздо лучше спросить врача, а еще лучше, если он специализируется на ортопедии. Навыки поэзии этого врача будь они прокляты; когда речь идет о специализированной проблеме (ваша потенциально сломанная лодыжка), важнее спросить специализированного эксперта, чем общего эксперта.
Как оказалось, то же самое верно и для SLM. И, как вы, вероятно, уже поняли (поскольку это раздел в этой главе), все больше доказательств того, что более мелкие, специализированные модели могут соответствовать или превосходить более крупные универсальные БЯМ при оценке специализированных задач. И когда мы говорим о специализированной модели, мы на самом деле имеем в виду модель, обученную на значительном объеме доменных данных. Например, в конце 2022 года команда Стэнфорда объявила о BioMedLM11 , модели с 2,7 миллиардами параметров, обученной на данных биомедицинской литературы. При оценке на вопросы Единого государственного лицензионного экзамена США (USMLE) тонко настроенная версия BioMedLM превзошла аналогичную тонко настроенную неспециализированную модель того же размера (GPT Neo) на
11 Ранее известный как PubMedGTP.
188 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
12 Reuters Graphics, «COBOL Blues», https://oreil.ly/lM-8U.
17%. При оценке по отношению к ненастроенной модели, которая была в 44 раза больше (модель Galactica 120B от Meta), BioMedLM превзошла ее почти на 6%. Но критически важный момент в том, была ли Galactica хороша для поставленной задачи; в отличие от BioMedLM, размер Galactica делал тонкую настройку слишком дорогостоящей. При всего 2,7 миллиардах параметров, крошечная БЯМ BioMedLM продемонстрировала, что может поддерживать специализированное преимущество, а также позволяет дополнительную настройку. Это очень ранний пример влияния доменной специализации в GenAI, но эти примеры дали старт огромной области исследований и применения специализированных моделей на целевых задачах.
Несмотря на кажущуюся хорошую производительность на медицинском бенчмарке в тестах Стэнфорда, Galactica от Meta (специально разработанная для помощи ученым) была запущена в научное сообщество с большим шумом — пока не рухнула с грохотом и не была отключена всего через три дня после ее общей доступности. Публичные эксперименты выявили много примеров предвзятости, токсичности и галлюцинаций, которые привели к научному нонсенсу. Вот почему важно полностью оценить то, что мы обсуждали в Главе 5.
Специализация может быть особенно важна для доменов с «низкими ресурсами», областей, где данных мало. Например, в Главе 4 мы рассказывали, как IBM Z (мейнфрейм) выполняет большинство мировых транзакций. В терминологии БЯМ, что-то классифицируемое как *низкий ресурс* — это домены с очень малым количеством данных, доступных для обучения систем ИИ. Как вы можете себе представить, COBOL считается языком с низкими ресурсами, так как сегодня существует очень мало общедоступных данных COBOL корпоративного уровня, особенно по сравнению с Python, SQL и другими популярными языками кодирования (да, много бизнес-логики написано на SQL). Но существует много критически важных частей бизнеса, работающих на COBOL. Фактически, Reuters оценивает12 , что сегодня существует более 230 миллиардов строк кода на COBOL — поддерживающих более 3 триллионов долларов торговли — активно работающих на предприятиях.
Для ясности, IBM Z поддерживает современные инструменты и методологии разработки приложений, такие как полностью автоматизированные конвейеры непрерывной интеграции/непрерывного развертывания (CI/CD) с использованием Jenkins и Zowe, Kafka streams, node.js, Kubernetes, Ansible, Terraform и многое другое. Но есть много критически важной бизнес-логики, написанной давно на COBOL, которая считается критически важной.
Что касается всех этих помощников по кодированию на базе БЯМ, которые парсили репозитории кода для создания настроенной модели кода, угадайте, сколько COBOL доступно для использования? Например, один популярный набор данных для обучения помощников по кодированию — это GitHub Codespaces — он содержит 1 терабайт кода на 32 разных языках. Но COBOL не охвачен. Почему нет? Вспомните ранее
Рост малых языковых моделей | 189
19 Кейд Метц, «OpenAI говорит, что DeepSeek, возможно, незаконно собрал его данные», The New York Times, 29 января 2025 г., https://oreil.ly/7xn_C.
20 См. лицензионное соглашение на сайте Llama.
в этой книге, насколько критичны ваши данные и как сегодняшние БЯМ не построены на корпоративных данных. Теперь вспомните о транзакциях, выполняемых на IBM Z (кредитные карты, банкоматы, авиакомпании). Думаете ли вы, что этот код просто лежит там, готовый к парсингу миром? Конечно, нет! Итак, как БЯМ может помочь в этом сценарии?
В 2023 году IBM Research обучила модель кода с 20 миллиардами параметров (называемую granite.20b.cobol), специализирующуюся на COBOL. Чтобы специализировать модель конкретно на COBOL, команда IBM Research отложила отдельно приобретенные данные COBOL, сначала обучила универсальную модель кода, а затем специализировала эту модель, дополнительно обучая ее на наборе данных, который был высококонцентрирован на высококачественных курированных данных COBOL (это как ваши проприетарные данные, ожидающие обработки). Конечный результат? Модель SLM, ориентированная на COBOL, значительно превзошла ChatGPT по выполнению задач COBOL на бенчмарках CodeNet.
Вывод? Целевые фундаментальные модели с качеством в основе означают лучшую производительность и большую эффективность. Эта концепция станет чрезвычайно важной в Главе 8, когда мы обсудим, как вы можете специализировать предварительно обученные модели, используя свои корпоративные данные.
Подумайте об этом, когда речь заходит о курировании данных
Помимо этических соображений при курировании данных, понимание и оценка законов масштабирования данных и влияния качества данных и доменной специализации на производительность могут помочь вам найти более экономичные альтернативы SLM по сравнению с более крупными, менее оптимально обученными, дорогостоящими монструозными БЯМ. Как уже предлагалось ранее, старые БЯМ, как правило, менее плотны по данным и, следовательно, менее эффективны по выводу, потому что они обучались, когда только появились законы масштабирования Каплана и Чинчиллы.
И хотя количество данных наиболее важно для тех, кто обучает модель с нуля, для любого, кто пытается настроить уже обученные модели, как мы рассмотрим в Главе 8, уроки по качеству данных и доменной специализации по-прежнему применимы.
Дистилляция моделей — Использование ИИ для улучшения ИИ
Давайте поговорим о втором крупном технологическом новшестве, стимулирующем развитие SLM: дистилляция моделей. Дистилляция моделей часто используется, когда вам нужна точность большой нейронной сети, но требуется что-то более практичное для приложений реального времени или устройств с ограниченной вычислительной мощностью. Это, по сути, еще одна техника для упаковки производительности большой модели в малый форм-фактор; и хотя на первый взгляд это может показаться немного хакерством, на самом деле это невероятно мощный инструмент. Дистилляция моделей — это процесс, при котором большая пограничная (большая, дорогая, передовая) модель, такая как Llama-3.1-405B, может инструктировать меньшую модель, такую как Llama3.1-8B, обучая ее вести себя как большая модель.
190 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
13 Команда Vicuna (блог), «Vicuna: чат-бот с открытым исходным кодом, впечатляющий качеством ChatGPT на 90% от GPT-4», LMSYS, 30 марта 2023 г., https://oreil.ly/qRHD4.
Отличный пример этого: попытка воспроизвести мастерство барбекю Тутси Томанец. Этот 85-летний работник по хозяйству днем и мастер барбекю ночью — легенда знаменитого Hill Country BBQ (Техас).
Она прямо скажет вам, что даже если даст рецепт, вы все равно не сможете повторить то, что делает она. Мы все были там — пытаясь уловить магию кулинарии бабушки, только чтобы понять, что это больше, чем просто ингредиенты; это жизнь, посвященная любви и технике.
Например, на вопрос о правильной температуре для начала приготовления говяжьего грудинки, она отмечает, что не знает... она просто кладет руку на коптильню и ориентируется на ощущения. (Это напомнило об одной из наших бабушек, которая использовала палец как подушечку для булавок.) Но мы готовы поспорить, что если бы мы могли провести неделю с Тутси и задавать ей безостановочные вопросы, мы могли бы в конечном итоге научиться готовить что-то близкое к грудинке, отмеченной наградами. Мы наверняка не узнали бы всего, что знает она. Например, мы не узнали бы, как она готовит свои невероятные соусы. Но если бы мы потратили еще неделю на безостановочные вопросы, мы, вероятно, смогли бы выяснить что-то довольно хорошее. Следующее — курица.
По сути, дистилляция моделей подобна извлечению всех существенных знаний из тяжелой модели в более легковесную версию, чтобы получить аналогичную производительность, но с меньшей сложностью.
Во многих смыслах дистилляция моделей — это просто новый, более дешевый способ создания обучающих данных. По мере того как БЯМ становятся все лучше и лучше в выполнении различных задач, они становятся мощными инструментами для генерации обучающих данных, которые раньше приходилось определять вручную армией аннотаторов данных. Для выполнения дистилляции ученые-исследователи используют учительскую модель (большую, всезнающую) для генерации большого объема синтетических данных, демонстрирующих целевой набор поведений, которые учительская модель умеет выполнять (например, навык приготовления пищи в нашем примере). Эти синтетические данные часто имеют разговорный характер, представляя собой пары «вопрос-ответ» (QA) или многопользовательские разговоры. Затем синтетические данные используются для тонкой настройки меньшей (ученической) модели, тем самым внедряя паттерны поведения большей модели в меньшую. И хотя на первый взгляд этот метод кажется лишь поверхностным, он оказался невероятно мощным для того, чтобы меньшая модель имитировала производительность большей. Фактически, еще в 2023 году, в качестве раннего примера дистилляции моделей, исследователи из Large Model Systems (LSMYS) Organization дистиллировали ChatGPT в модель с 13 миллиардами параметров под названием Vicuna. Производительность Vicuna шокировала сообщество, когда они впервые опубликовали свою работу. LSMYS сообщила13 , что их дистиллированная модель ChatGPT «достигает более 90% качества [имеется в виду ее ответы] OpenAI ChatGPT».
Рост малых языковых моделей | 191
14 «Nemotron-4-340B-Instruct», Hugging Face, https://oreil.ly/5Mh3Y.
15 Саманта Субин, «Nvidia теряет почти 600 миллиардов долларов рыночной капитализации, крупнейшая однодневная потеря в истории США», CNBC, 27 января 2025 г., https://oreil.ly/vWA0q.
Сообщество открытого исходного кода, включая Стэнфорд и LSMYS, стало одними из первых инноваторов, использовавших эту технику, и теперь стало «жертвами» собственного успеха. Дистилляция моделей стала настолько популярной (и конкурентно угрожающей), что большинство поставщиков пограничных моделей (таких как OpenAI, Google, Anthropic и другие) вписали ограничения в условия использования своих моделей, запрещающие их использование для улучшения производительности других конкурентных моделей.
Хотя это ограничивает коммерческую жизнеспособность моделей, дистиллированных сообществом открытого исходного кода, это настоящий клондайк для поставщиков БЯМ с доступом к большим моделям, которые служат идеальными «учителями», насыщенными кофеином. Например, благодаря партнерству с OpenAI, Microsoft выпустила Orca и Orca-2, высококонкурентные SLM, которые извлекают выгоду из дистилляции GPT-4. А Google Gemini Nano и Gemini Pro являются дистиллированной версией более крупных моделей Gemini.
Поскольку эта техника продолжает совершенствоваться, необходимо должным образом рассмотреть, будут ли сверхбольшие модели когда-либо использоваться для чего-либо, кроме обучения меньших, более быстрых и экономичных дистиллированных моделей. Например, когда NVIDIA выпустила свою модель с 340 миллиардами параметров, Nemotron-4-340B-Instruct, основной вариант использования, выделенный на карте модели, заключался в «создании обучающих данных, которые помогают исследователям и разработчикам строить свои собственные БЯМ» (то есть дистилляция моделей).14 Размещение модели с 340 миллиардами параметров для работы в реальном времени может быть очень дорогим. Но использование модели один раз для генерации синтетических обучающих данных для меньшей модели является гораздо более приемлемой разовой фиксированной затратой, которая позволяет развернуть более дешевую, меньшую и производительную модель.
И хотя закрытые поставщики пограничных моделей в настоящее время имеют «конкурентный ров» для своих SLM благодаря их обучающим моделям, мы считаем, что существует огромный потенциал для подрыва. Очень большие модели с открытым исходным кодом, такие как Nemotron-4-340B-Instruct, Llama-3.1-405B и совсем недавно DeepSeek-R1, доказывают, что являются мощными обучающими моделями, размывая это преимущество.
Как мы уже отмечали ранее в этой книге, китайская лаборатория ИИ DeepSeek открыла исходный код своего семейства моделей Mixture of Experts (MoE) с 671 миллиардом параметров, включая теперь знаменитую модель DeepSeek-R1. Выпуск модели DeepSeek поразителен по ряду причин, наименьшая из которых — то, как в ответ на выпуск рыночная капитализация NVIDIA упала на 600 миллиардов долларов за один день15 , поскольку зрители по всему миру были поражены производительностью и рассудительными способностями, демонстрируемыми китайской лабораторией ИИ, при заявленной стоимости обучения (которая не была полностью понята прессой и теми, кто на нее отреагировал) в 5,6 миллиона долларов.
192 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
Существует много вещей, которые нужно здесь распаковать, особенно в отношении заявленных затрат на обучение, некоторые из которых мы обсудим ближе к концу этой главы, когда будем рассматривать архитектуру MoE. Но большая часть выпуска DeepSeek на самом деле является важной историей о роли обучающих моделей и дистилляции моделей — в частности, о сборе более мелких рассудительных моделей «DeepSeek-Distill», которые были выпущены наряду с гораздо более крупной рассудительной моделью DeepSeek-R1.
Рассуждение по цепочке мыслей
Рассудительная модель — это новая техника, используемая разработчиками моделей, при которой модель обучается делать быструю (хотя это не обязательно) паузу «подумать» перед возвратом ответа. Во время этой паузы она сначала генерирует некоторые внутренние мысли о том, как следует подходить к ответу на промпт. Затем, полностью оценив все, она ответит окончательным ответом.
Например, в одном быстром тесте с использованием версии DeepSeek-R1, размещенной на deepinfra.com, мы задали очень простой вопрос: «Что весит больше, фунт свинца или килограмм перьев?»
DeepSeek-R1 затем ответила:
Окей, так вопрос: «Что весит больше, фунт свинца или килограмм перьев?» Хм, дайте подумать. Возможно, это хитрость? Я знаю, что фунты и килограммы — это единицы веса, но они принадлежат к разным системам. Фунт — из имперской системы, а килограмм — метрическая. Сначала нужно сравнить их по одной шкале. Я помню, что 1 килограмм равен примерно 2,2 фунтам. Итак, если у меня есть килограмм перьев, это уже больше фунта. Подождите, но свинец дан в фунтах, а перья — в килограммах. Итак, если килограмм равен 2,2 фунта, то килограмм перьев будет весить 2,2 фунта, верно? Тогда как свинец весит всего 1 фунт. Значит, перья на самом деле весят больше. Но возможно, люди думают, что свинец тяжелее, потому что он плотнее. Но при измерении по весу килограмм больше фунта. Итак, килограмм перьев будет тяжелее фунта свинца. Дайте проверить еще раз. Если я переведу килограмм в фунты, 1 кг равен примерно 2,20462 фунта, так что перья весят более 2 фунтов, в то время как свинец — всего 1 фунт. Значит, да, перья весят больше. Итак, ответ должен быть перья. Но я хочу убедиться, что в вопросе нет хитрости. Они оба измеряются в единицах веса, поэтому, если это фунт против килограмма, килограмм больше. Некоторые люди могут спутать фунты и килограммы, потому что они обе единицы, но на самом деле килограмм — более крупная единица. Так что да, перья весят больше. Килограмм перьев весит больше, чем фунт свинца. Объяснение: 1 килограмм (кг) — это единица массы в метрической системе, эквивалентная 2,20462 фунтам (фунты). 1 фунт (фунт) меньше, является частью имперской системы.
Рост малых языковых моделей | 193
16 DeepSeek-AI, «DeepSeek-R1: Стимулирование способности рассуждения в БЯМ с помощью обучения с подкреплением», arXiv, 22 января 2025 г., https://arxiv.org/pdf/2501.12948.
17 См. данные на веб-сайте Hugging Face.
18 См. наборы данных на веб-сайте Hugging Face.
Таким образом, 1 кг перьев (~2,2 фунта) весит более чем в два раза больше, чем 1 фунт свинца. Плотность (насколько плотно упакована масса) может сделать свинец более тяжелым на ощупь при одинаковом объеме, но вес зависит от массы, а не плотности. При сравнении равных весов большая единица (килограмм) всегда перевешивает меньшую (фунт).
Ответ: Килограмм перьев весит больше.
Обратите внимание, как внутренние токены цепочки рассуждений обернуты в теги <think>...</think>. И хотя уровень внутренней, предварительной обработки рассуждений в этом примере, безусловно, чрезмерен для этой простой загадки, при применении этой техники к гораздо более сложным задачам — например, для поддержки кодирования — она может оказать огромное влияние на производительность.
В конечном итоге, рассуждение по цепочке мыслей является примером использования «вычислительной мощности во время вывода» (подробнее об этом в Главе 9) для улучшения ответа модели. Затраты на вывод увеличиваются, потому что этому типу модели необходимо генерировать токены рассуждения по цепочке мыслей, в дополнение к ответу, но ответ модели в конечном итоге улучшается. Модели OpenAI o1 и o3, а также модели DeepSeek R1, R1-Zero и R1-Distill все используют этот тип техники и, следовательно, считаются рассудительными моделями.
Чтобы DeepSeek мог создавать эффективные SLM с возможностями рассуждения, они сначала использовали R1 для генерации большого объема (800 тысяч образцов) примеров рассуждения в математической и кодовой областях.16 Затем они взяли этот набор данных и тонко настроили набор открытых сторонних моделей, созданных Meta (Llama) и Alibaba Cloud (Qwen), размеры которых варьировались от 1,5 миллиарда до 70 миллиардов параметров, и вуаля! Родилась серия небольших моделей DeepSeek R1-Distill с расширенными возможностями математического и кодового рассуждения.
Успех DeepSeek в дистилляции рассудительных возможностей в малые модели вдохновил сообщество открытого исходного кода. В течение нескольких дней после выпуска моделей DeepSeek-R1 и DeepSeek-R1-Distill сообщество открытого исходного кода создало конвейеры дистилляции, чтобы любой мог выполнять аналогичный процесс дистилляции, используя выбранный им SLM.17 Аналогично, менее чем за месяц на Hugging Face было размещено более 400 наборов данных для дистилляции на основе DeepSeek, чтобы другие могли легко использовать выходные данные DeepSeek в своих конвейерах разработки моделей!18
194 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
27 DeepSeek-AI, «Технический отчет DeepSeek-V3», препринт, arXiv, 18 февраля 2025 г., https://arxiv.org/html/2412.19437v1.
Сообщество открытого исходного кода, включая Стэнфорд и LSMYS, стало одними из первых инноваторов, применивших эту технику, и теперь стало «жертвами» собственного успеха. Дистилляция моделей стала настолько популярной (и конкурентоспособной), что большинство поставщиков пограничных моделей (таких как OpenAI, Google, Anthropic и другие) ввели ограничения в условия использования своих моделей, запрещающие их использование для улучшения производительности других конкурентных моделей.
Хотя это ограничивает коммерческую жизнеспособность моделей, дистиллированных сообществом открытого исходного кода, это отличная новость для поставщиков БЯМ с доступом к большим моделям, которые станут идеальными «учителями», насыщенными кофеином. Например, благодаря партнерству с OpenAI, Microsoft выпустила Orca и Orca-2, высококонкурентные SLM, которые извлекают выгоду из дистилляции GPT-4. А Google Gemini Nano и Gemini Pro — это дистиллированная версия более крупных моделей Gemini.
Поскольку эта техника продолжает совершенствоваться, необходимо должным образом рассмотреть, будут ли сверхбольшие модели когда-либо использоваться для чего-либо, кроме обучения меньших, более быстрых и экономичных дистиллированных моделей. Например, когда NVIDIA выпустила свою модель с 340 миллиардами параметров, Nemotron-4-340B-Instruct, основной вариант использования, выделенный на карте модели, заключался в «создании обучающих данных, которые помогают исследователям и разработчикам строить свои собственные БЯМ» (то есть дистилляция моделей).14 Размещение модели с 340 миллиардами параметров для работы в реальном времени может быть очень дорогим. Вам лучше иметь достаточно веский вариант использования, чтобы оправдать это развертывание. Но использование модели один раз для генерации синтетических обучающих данных для меньшей модели является гораздо более приемлемой единовременной фиксированной затратой, которая позволяет развернуть более дешевую, меньшую и производительную модель.
И хотя закрытые поставщики пограничных моделей в настоящее время имеют «конкурентный ров» для своих SLM благодаря их обучающим моделям, мы считаем, что существует огромный потенциал для деструкции. Очень крупные модели с открытым исходным кодом, такие как Nemotron-4-340B-Instruct, Llama-3.1-405B и совсем недавно DeepSeek-R1, доказывают, что являются мощными обучающими моделями, размывая это преимущество.
Как отмечалось ранее в этой книге, китайская лаборатория ИИ DeepSeek открыла исходный код своего семейства моделей Mixture of Experts (MoE) с 671 миллиардом параметров, включая теперь знаменитую модель DeepSeek-R1. Выпуск модели DeepSeek поразителен по ряду причин, наименьшая из которых — то, как в ответ на выпуск рыночная капитализация NVIDIA упала на 600 миллиардов долларов за один день15 , поскольку зрители по всему миру были поражены производительностью и рассудительными способностями, демонстрируемыми китайской лабораторией ИИ, при заявленной стоимости обучения (которая не была полностью понята прессой и теми, кто на нее отреагировал) в 5,6 миллиона долларов.
192 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
28 Там же.
Во-первых, как скажет любой юрист, убедитесь, что вы внимательно прочитали мелкий шрифт! Когда DeepSeek сообщила о стоимости обучения в Техническом отчете DeepSeek-V3, она включила очень важное замечание: «Обратите внимание, что вышеупомянутые затраты включают только официальное обучение DeepSeek-V3, исключая затраты, связанные с предыдущими исследованиями и апробационными экспериментами над архитектурами, алгоритмами или данными».28
Что это означает на простом языке? Ну, чтобы обучать БЯМ, требуется много грубой силы и ошибок, чтобы оптимизировать производительность. Это означает, что для каждой выпущенной модели могут существовать сотни или тысячи меньших моделей, которые обучаются заранее, тестируя различные эффективности смешивания данных, перебирая различные настройки гиперпараметров и т. д. Эти затраты на разработку могут легко в 10 раз или более превышать конечную, одноразовую стоимость обучения модели. Итак, хотя то, что сделал DeepSeek, все еще впечатляет, истинные затраты на обучение его моделей, вероятно, были гораздо менее потрясающими, чем могла предположить пресса.
Подумайте об этом, когда речь заходит о дистилляции моделей
Исследования и инновации с моделями типа MoE все еще развиваются. Как показал DeepSeek, мир становится все лучше и лучше в обучении моделей MoE и инновациях в том, как объединять экспертов. В конце концов, мы наиболее оптимистично настроены относительно этой архитектуры, потому что ее более эффективные затраты на обучение позволят быстрее итерировать, что, как мы надеемся, будет продолжать стимулировать инновации в этой области.
Мы видим значительный инновационный простор для MoE в отношении настраиваемой эффективности вывода. Сегодня Mixtral разработан для вызова двух экспертов на этапе вывода. Чтобы обеспечить экономичный вывод в будущем, мы представляем, что эта технология будет развиваться, динамически изменяя количество вызываемых экспертов на этапе вывода, позволяя пользователям быстро настраивать компромисс между затратами и производительностью для данной задачи и варианта использования. Это похоже на случай маршрутизации моделей в предыдущем разделе, где более сложные задачи могли потребовать оправданного использования большей, более дорогой модели. В нашем хрустальном шаре мы видим, что модели MoE будут работать так же, используя больше экспертов на этапе вывода для сложных задач (возможно, всех восьми, а не только двух в нашем примере).
Независимо от того, как развивается эта технология, гибкость для потребителей моделей делает ее такой захватывающей. Когда вы уменьшаете свою зависимость от одной большой модели и используете мощь меньших моделей (или частей модели), работающих вместе, у вас появляются возможности настраивать экспертизу модели для ваших вариантов использования вплоть до оптимизации компромисса между затратами и производительностью для наилучшего удовлетворения потребностей вашего бизнеса. И теперь вы знаете, почему одна модель не могла править всеми.
Куда движется эта технология — Одна модель не будет править всеми! | 205
Агентные системы
Мы дали вам несколько высокоуровневых деталей об агентах на протяжении этой книги. В последнем разделе этой главы пришло время углубиться в них немного глубже. Когда мы говорим об агентах, мы часто имеем в виду реализацию БЯМ, где пользователь предоставляет инструкцию, ориентированную на цель, а затем БЯМ самостоятельно придумывает серию задач (и подзадач) для достижения этой цели. Затем он итерируется по этим задачам, часто используя инструменты и циклы рефлексии для выполнения каждой задачи. Агент может даже состоять из нескольких разных БЯМ, каждая из которых выполняет одну из этих задач.
Поскольку сложная задача разбивается на более мелкие, простые для выполнения шаги, часто открывается возможность для меньших моделей решать более простые задачи в тандеме с более крупными моделями, выполняющими более сложные задачи (например, придумывать список задач, которые нужно выполнить для достижения цели в первую очередь). И часто, за кулисами происходит какая-то маршрутизация моделей, где БЯМ выбирает другую БЯМ для выполнения подзадачи, основываясь на каталоге БЯМ.
В то время как многие вещи, которые делают агенты сегодня, могут быть выполнены вручную и статично, агенты обеспечивают прорывы в производительности, еще больше смещая работу влево, что экономит время и повышает эффективность. Например, если бы вы руководили клиническими испытаниями, вы могли бы использовать БЯМ для выявления подходящих кандидатов для испытания, но затем вам пришлось бы вручную управлять планированием визитов и координацией (задачи, такие как отправка напоминаний, перенос встреч и автоматическое напоминание всем участникам испытания о ключевых датах или требованиях, таких как утреннее голодание). С агентами вы смещаете больше работы влево, потому что агент может не только придумать отличный черновик идеального профиля клинического испытания, но и даже помочь придумать предлагаемый набор напоминаний о соответствии и даже запланировать сбор образцов с календарными приглашениями для участников! Более того, агентные системы не застывают во времени, и они могут адаптироваться в реальном времени.
Представьте себе, что вы прикрепили агента к проблеме управления цепочкой поставок — теперь у вас есть ИИ, способный понять погодное явление и оптимизировать план (понимание перекрытия дорог и т. д.), чтобы доставить столь необходимый продукт в магазины. И, как вы узнаете, агенты могут даже учиться на протяжении пути. Проще говоря, динамическая природа агентов помогает компании сдвинуть больше работы от +ИИ к ИИ+ и сохранять гибкость. Эта область постоянно меняется, поэтому вы захотите внимательно следить за ней.
Теперь вспомните то, что вы узнали в Главе 4 о БЯМ с использованием шаблона RAG. Это был один из способов не просто сделать ваши корпоративные данные доступными для БЯМ, но и предоставить БЯМ актуальную информацию. В этом шаблоне более крупная система впрыскивает информацию из внешнего источника (например, базы данных) непосредственно в промпт до времени выполнения. Это также было основой варианта использования «разговор с документом» в Главе 4. С внедрением агентов ИИ становится еще мощнее и может обрабатывать более сложные задачи, поскольку они имеют возможность вызывать инструменты (этот процесс называется tool calling) за пределами БЯМ, чтобы помочь им в работе.
206 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
29 Алан Чан и др., «Видимость в агентах ИИ», arXiv, обновлено 17 мая 2024 г., https://arxiv.org/abs/2401.13138.
*Tool calling* — это термин, обозначающий способность БЯМ взаимодействовать с внешними инструментами, приложениями и другими системами — все это для расширения их функциональности. Например, БЯМ агента может выполнить вызов инструмента для получения погоды в определенном месте, чтобы помочь завершить задачу или обратиться к калькулятору для выполнения определенных типов вычислений для точности или даже для выгрузки работы из БЯМ. Проще говоря, tool calling расширяет возможности БЯМ за пределы генерации текста, изображений и других вещей, которыми они известны, что мы охватили в этой книге.
Возможно, лучший способ оценить силу агентов — это поразмыслить над тем, как вы обычно работаете сегодня с чат-ботом на базе ИИ. Поток выглядит примерно так:
промпт человека → ответ БЯМ → промпт человека → ответ БЯМ → ...
В этой традиционной системе ваш промпт может возвращаться вперед и назад простым способом, показанным выше, но он может запускать множество вызовов, работающих на бэкенде, невидимых для вас, прежде чем будет предоставлен ответ. Например, шаблон RAG добавляет данные из источника данных, подключенного к этому потоку администратором, в промпт. Но даже при таком улучшении информация, доступная БЯМ, поддерживающей чат-бот на базе RAG, также предопределена его создателем (например, через подключение к векторной базе данных типа Chroma). В этом не-агентном архитектурном шаблоне участвующей БЯМ *не* предоставляется возможность работать «за кулисами» самостоятельно — она взаимодействует с вами постоянно, когда вы возвращаетесь вперед и назад, пытаясь завершить свою задачу.
В отличие от этого, агентные реализации предоставляют БЯМ больше свободы и власти. В этом архитектурном шаблоне БЯМ разрешено рассуждать о том, какая информация нужна для выполнения задачи, которая помогает достичь цели, например: «Составьте план по увеличению показателя чистого продвижения (NPS) для сервисного центра моей автомобильной дилерской компании». Часть БЯМ этого шаблона получает доступ к инструментам (подробнее об этом чуть позже), которые могут быть вызваны на бэкенде для получения актуальной информации, оптимизации рабочих процессов, создания подзадач для решения сложной части по частям, и даже вызвать некоторый скриптовый язык (например, VBScript) для создания нескольких диаграмм PowerPoint по найденным результатам! Все это делается автономно агентом (или агентами) для достижения сложной цели. Агентный рабочий процесс может выглядеть так:
промпт человека → основной ответ БЯМ (скрыт для пользователя) → вызов основного инструмента БЯМ (скрыт для пользователя) → ответ БЯМ (скрыт для пользователя, показан второстепенной БЯМ) → второстепенный ответ БЯМ (скрыт для пользователя, предоставлен обратно основной БЯМ) → основной ответ БЯМ (показан пользователю) → промпт человека → ...
Как конечный пользователь, общающийся с агентной системой, вы можете почувствовать, что просто запрашиваете у одной большой, многофункциональной супер БЯМ, стоящей за кулисами. Но реальность такова,
Агентные системы | 207
вы, скорее всего, работаете с системой из более крупных и мелких моделей, работающих вместе за кулисами, чтобы эффективно решить вашу задачу. (Как мы сказали, вы можете использовать несколько БЯМ в агентном рабочем процессе. Это действительно должно дать вам представление о том, насколько значительную роль SLM могут играть в этой области.)
Агенты ИИ могут охватывать широкий спектр функций, выходящих за рамки языка, включая принятие решений, решение проблем, взаимодействие с внешними средами и выполнение действий. И эти агенты могут быть развернуты в различных приложениях для решения сложных задач в корпоративных контекстах, от разработки программного обеспечения и автоматизации ИТ до инструментов генерации кода и помощников в диалогах. Мы любим думать об агентах как о цифровых стажерах с большими амбициями. Вооружите их целями, инструментами и задачами, и их сообразительность часто вас удивит — но, как мы сказали ранее, ИИ — это не магия.
Какова ваша реакция на этого агента в действии?
Агенты ИИ — это реализации БЯМ на системной основе, которые используют планирование, рассуждение и вызов инструментов для решения проблем и взаимодействия с внешними средами. За кулисами может быть одна БЯМ, обрабатывающая всю работу, множество экземпляров одной и той же БЯМ, работающих над задачей, или комбинация различных БЯМ. Хороший агентный фреймворк позволит вам смешивать и сопоставлять разных поставщиков БЯМ, что включает тонко настроенные модели, которые вы могли настроить своими данными. Например, вы можете использовать Claude Sonnet от Anthropic для управления рабочим столом, но дополнить его моделью на основе Granite, улучшенной вашими бизнес-данными — обе модели могут работать совместно, чтобы определить событие и заполнить форму. Очень круто!
Figure 7-6 дает представление об агенте, которому мы поручили написать блог о влиянии инфляции на цены на жилье в Канаде в 2024 году, а затем предложить несколько публикаций в социальных сетях, чтобы сослаться на наш блог.
Мы настроили несколько агентов, которые вызываются из нашей задачи. Один из агентов взял на себя роль ведущего аналитика рынка. Мы не будем подробно описывать каждого агента, но цель этого конкретного агента заключалась в проведении анализа финансовых новостей в реальном времени по интересующей нас теме, чтобы помочь в создании контента. Мы также дали этому агенту *бэкстори*, что заставило его принять на себя роль аналитика рынка из авторитетной фирмы, который анализирует рыночные тенденции, чтобы передать их нашим агентным писателям. Мы передали эту информацию агентному фреймворку в YAML-файлах.
Обратите внимание на Figure 7-6, что наш агент-ведущий аналитик рынка буквально рассказывает нам, как он начнет с поиска в интернете статей по теме, связанной с его задачей.
208 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
Figure 7-6

Figure 7-6. Мыслительный процесс нашего агентного рабочего процесса о некоторых шагах, которые ему необходимо выполнить, чтобы написать наш блог и сослаться на этот блог в социальных сетях
Как показано на Figure 7-7, если задача сложна, агент может сделать несколько внутренних циклов вызовов инструментов и внутреннего рассуждения, прежде чем вернуть окончательный ответ. В этом случае агент завершил поиск источников и теперь начинает изучать собранные данные. Обратите внимание, как он имеет доступ к инструментам, помогающим ему.
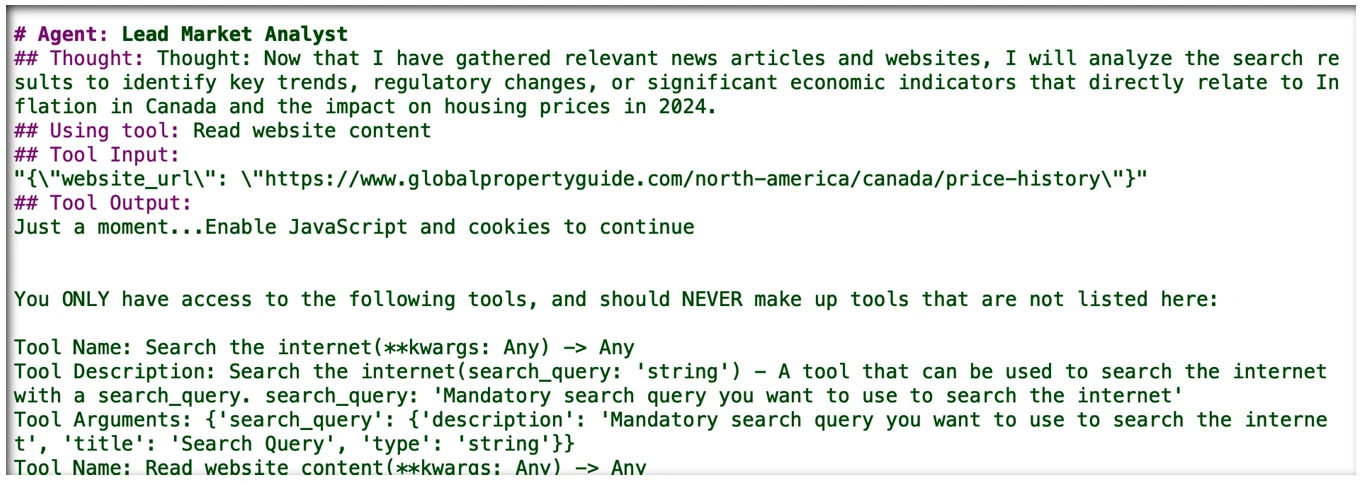
Figure 7-7
Figure 7-7. Агент начинает просматривать содержимое найденной информации
Наконец, этот конкретный агент завершает свою работу и возвращает результаты, показанные на Figure 7-8. Очевидно, что наш агентный рабочий процесс имеет информацию об источнике и пункты резюме, которые станут отличной записью в блоге!
Агентные системы | 209

Figure 7-8
Figure 7-8. Основные тезисы для нашего поста в блоге
В конечном итоге, этот поток добавляет гораздо больше гибкости, предоставляя моделям, питающим ваших агентов, возможность планировать задачи, исследовать внешнюю информацию и многое другое.
Как мы уже намекали ранее, мы создали несколько агентов на бэкенде, каждый из которых специализируется на разных задачах, и поручили им всем работать над этой целью. Один агент взял на себя роль создателя контента; другой — креативного директора; еще один — гуру социальных сетей; и, наконец, один — гуру математики. Мы предлагаем вам, создавая свои собственные цифровые сотрудники в ваших агентных рабочих процессах, посмотреть на те самые объявления о вакансиях, которые вы можете сделать для таких работ. Там будут все виды *бэкстори* навыков, которые вы хотите, чтобы эти цифровые сотрудники умели делать. Когда все было сказано и сделано, наши агенты написали нам (предположительно; мы, конечно, посмотрели на собранные данные) хорошо исследованный блог, который показан на Figure 7-9.

Figure 7-9
Figure 7-9. Начало нашего финального поста в блоге
210 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
Наконец, посмотрите на сообщения для охвата в социальных сетях, которые сгенерировал наш агентный рабочий процесс (см. Figure 7-10), чтобы усилить нашу статью.

Figure 7-10
Figure 7-10. Агентный рабочий процесс не только написал наш блог; он также составил сообщения для охвата в социальных сетях, чтобы направить трафик на наш пост в блоге
Мы признаем, что мы немного поленились, глядя на вывод на Figure 7-10. Почему так? Мы дали те же навыки нашему агенту-писателю для социальных сетей для размещения на всех платформах. Оглядываясь назад, мы должны были дать этому агенту более широкие навыки и знания, чтобы он знал, как лучше сочетать тон и стиль в зависимости от социальной сети. В конце концов, в X (Twitter) ограничено 240 символов, поэтому наш агент усердно работал, чтобы все созданные им посты были короткими (что могло быть частью нашей поставленной задачи, но не было). В качестве другого примера, посты в Instagram могли бы быть намного менее формальными, чем в LinkedIn. Обратите внимание, как на Figure 7-10 агент использовал эмодзи для поста в X, которые более распространены из-за ограничений, чем в LinkedIn.
За кулисами происходило много других крутых вещей, которые мы не могли здесь показать. Например, у наших агентов была своя версия почитаемого шоу «Кто хочет стать миллионером?» — «Линия помощи другу» — только эти «друзья» были веб-краулерами, искателями и парсерами, фрагментами кода Python (мы использовали его Pydantic-библиотеку для парсинга данных, среди прочих библиотек) и другими агентами цифрового труда — самое лучшее в том, что они никогда не ставили вас на ожидание и не говорили: «Извините, братан, я застрял!»
Считаем ли мы, что Figures 7-9 и 7-10 были лучше, чем человек? Смысл был не в этом... потому что мы считаем, что предоставление этой информации человеку повысило бы его производительность, если бы его работа заключалась в выполнении именно этих задач. Мы сместили работу влево! Теперь добавьте человеческий элемент, чтобы все стало по-настоящему реальным.
Агентные системы | 211
29 Алан Чан и др., «Видимость в агентах ИИ», arXiv, обновлено 17 мая 2024 г., https://arxiv.org/abs/2401.13138.
Немного больше об агентах
В агентной системе агент часто имеет доступ к более продвинутым формам контекстуализации, таким как буферы памяти, которые хранят информацию о прошлой работе и задачах, которые он выполнял. Способность агента хранить прошлые взаимодействия в памяти и планировать будущие действия стимулирует персонализированный опыт и всеобъемлющие ответы. Но все становится лучше — эти агенты со временем учатся. Например, если есть определенный стиль, в котором вы хотите, чтобы был написан отчет, или уровень дерзости для поста в Instagram в отличие от поста в LinkedIn, память агента может сохранять эти предпочтения, и это отличный пример более персонализированного опыта и всеобъемлющего ответа. В нашем примере выше, если бы мы дополнительно проинструктировали нашего агента не делать публикацию в блоге слишком объемной с слишком большим количеством коротких разделов, он бы научился этому предпочтению. Сравните это с традиционной настройкой чат-бота на базе RAG, где модель каждый раз начинает с нуля.
Хотя агенты ИИ автономны в своих процессах принятия решений, как мы уже упоминали, они требуют целей и сред, определенных людьми.29 Существуют четыре основных влияния на поведение автономных агентов:
- Команда, которая разрабатывает и обучает (или, скорее всего, использует или тонко настраивает) лежащую в основе БЯМ(ы), используемые в агентном рабочем процессе. Как вы узнали из этой книги, более вероятно, что вы используете БЯМ, созданную кем-то другим, для поддержки своих агентов, и в зависимости от задачи, которую ей нужно выполнить, вы могли ее настроить под свой бизнес.
- Команда инженеров, которая создает агентную систему ИИ. Это люди, которые определяют инструменты, к которым система будет иметь доступ.
- Команда разработчиков, которая настраивает агента и предоставляет пользователю доступ к нему и инструментам. Эти люди работают в сочетании с бизнесом, чтобы помочь создать агентную личность.
- Пользователь, который задает промпт агенту ИИ с конкретными целями и задачами.
Как вы видели в примере ранее, учитывая цели пользователя и доступные агенту инструменты, агентный рабочий процесс создал план, который включал задачи и подзадачи для достижения сложной цели, поставленной перед ним. Если бы это была простая задача (например, написание формального письма), планирование не было бы необходимым шагом. Вместо этого, агент мог итеративно рефлексировать над своими ответами и улучшать их без планирования следующих шагов. Это не было так в случае с нашим постом в блоге. Вспомните на Figures 7-6 и 7-8, что логика нашего агента показала нам некоторые инсайты в его рассуждения и планирование того, как решить задачу, которую мы ему поставили (было гораздо больше мышления, рассуждения и планирования, которые мы вам не показали).
212 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
Агенты ИИ основывают свои действия на информации, которую они воспринимают. Часто агенты ИИ не обладают полной базой знаний, необходимой для решения всех подзадач в рамках сложной цели. Например, у наших агентов не было знаний о влиянии инфляции на жилье. Чтобы исправить это, наши агенты использовали доступные им инструменты (в нашем примере, агент зашел в интернет и искал информацию). Эти инструменты могут включать внешние наборы данных, веб-поиск, API и даже других агентов. После получения необходимой информации с помощью этих инструментов, наш агент обновил свою базу знаний. Это означает, что на каждом этапе агент может переоценивать свой план действий и корректировать себя.
Хотя наш предыдущий пример демонстрировал написание текста, представьте себе что-то более сложное, например, планирование вашего следующего отпуска. Вы поручаете агенту ИИ предсказать, в какую неделю следующего года, скорее всего, будет лучшая погода для серфинга на Гавайях. Поскольку модель БЯМ, лежащая в основе агента, не специализируется на погодных паттернах, этот агент соберет информацию из внешней базы данных (в отличие от веб-поиска), состоящей из ежедневных отчетов о погоде на Гавайях за последние несколько лет. Несмотря на получение этой новой информации, агент все еще не может определить оптимальные погодные условия для серфинга, поэтому создается следующая подзадача. Для этой подзадачи агент связывается с внешним агентом, специализирующимся на серфинге. Допустим, при этом агент узнает, что высокие приливы и солнечная погода с небольшим дождем обеспечивают лучшие условия для серфинга — не просто солнечное небо. Затем агент объединяет информацию, полученную от своих инструментов, чтобы выявить те лучшие паттерны, которые помогут сделать ваш отпуск на серфинге «маика’и лоа» (по-гавайски «отличный»). Он возвращается с прогнозом о том, в какие недели года, скорее всего, будут высокие приливы, солнечная погода и низкая вероятность дождя. Эти результаты затем представляются вам, или, возможно, агент даже бронирует вашу поездку.
Как создаются агенты
В основе своей агенты — это системные реализации БЯМ. В этой реализации у вас будет БЯМ с набором операционных инструкций о том, как планировать и как выполнять внешние вызовы инструментов (будь то веб-поиск или промпт другой БЯМ и т.д.), встроенных в более широкую систему, которая выполняет ключевые, не-GenAI действия, такие как:
- Парсинг вывода БЯМ, поиск вызовов инструментов, которые БЯМ запустит.
- Обработка внешнего API на основе идентифицированного вызова инструмента.
- Обработка ответа инструмента и впрыскивание его непосредственно обратно в историю разговора БЯМ с правильным форматированием (например, преобразование JSON в письменный текст или Markdown).
- Обработка продвинутых функций памяти, таких как манипуляция историей разговора и хранение ключевых артефактов в памяти, доступной для БЯМ.
Агентные системы | 213
30 Готье Даган и др., «Динамическое планирование с БЯМ», препринт, arXiv, 11 августа 2023 г., https://arxiv.org/abs/2308.06391.
31 Бьенфенг Сюй и др., «ReWOO: Разделение рассуждений от наблюдений для эффективных дополненных языковых моделей», препринт, arXiv, 23 мая 2023 г., arXiv. https://arxiv.org/abs/2305.18323.
Как видите, это сложная система, в которой работает БЯМ, часто приводящая к сложным, многостраничным промптам, обобщающим операционные инструкции для агента (или группы агентов).
Хотя нет единого стандартного промпта для инструктажа агентов ИИ, появилось несколько парадигм, также известных как *архитектуры агентов*, для решения многоэтапных проблем и определения того, как запускать планирование, использование инструментов и память в рамках рабочего процесса БЯМ.
ReAct (Рассуждение и Действие)
Это архитектура агентов, которую мы использовали в нашем примере блога. Она позволяет пользователям инструктировать своих агентов «думать» и планировать после каждого предпринятого действия... и после каждого ответа инструмента решать, какой инструмент использовать далее. Эти циклы «думать-действовать-наблюдать» используются для решения проблем шаг за шагом и итеративного улучшения ответов.
Через структуру промпта агенты могут быть проинструктированы рассуждать медленно и отображать каждую «мысль»30 (вы видели это в нашем примере блога). Вербальное рассуждение агента дает представление о том, как формулируются ответы. В этой структуре агенты постоянно обновляют свой контекст новыми рассуждениями. Это можно интерпретировать как форму промптинга по цепочке мыслей (CoT).
ReWOO (Рассуждение без наблюдения)
Метод ReWOO, в отличие от ReAct, выполняет все планирование заранее. Это может быть желательным с человекоцентрической точки зрения, поскольку пользователь может подтвердить план до его выполнения. Это важно, потому что в какой-то момент кто-то должен платить за запуск всего этого — это неплохой подход, чтобы знать, что произойдет (и как) до того, как вы за это заплатите.
Рабочий процесс ReWOO состоит из трех модулей. В модуле планирования агент предвидит свои следующие шаги, учитывая промпт пользователя. Следующий этап включает сбор выходных данных, полученных при вызове этих инструментов. Наконец, агент объединяет первоначальный план с выходными данными инструментов для формулирования ответа. Такое планирование наперед может значительно сократить использование токенов и вычислительную сложность, а также последствия сбоя промежуточных инструментов.31
214 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
Риски и ограничения агентных систем
Агентные системы имеют все те же риски и ограничения, что и GenAI, в частности, проблемы предвзятости, галлюцинаций, взлома и т. д. В дополнение к этим общим проблемам, существуют специфические ограничения и риски, связанные с агентными системами, которые мы хотим, чтобы вы понимали при рассмотрении развертывания агентных систем — и именно поэтому мы написали этот раздел:
Вычислительная сложность и бесконечные циклы обратной связи
Поскольку агенты ИИ часто используют несколько вызовов вывода для ответа на один промпт, они могут стать очень затратными с точки зрения вычислений, особенно для простых задач NLP. Может быть более эффективно и экономично запустить стандартный рабочий процесс БЯМ без внедрения более широкой агентной системы.
Кроме того, агенты, неспособные создать всеобъемлющий план или рефлексировать над своими результатами, могут многократно вызывать одни и те же инструменты, запуская бесконечные циклы обратной связи. Если агенты останутся без присмотра и попадут в бесконечный цикл обратной связи, который выполняет вывод на большой БЯМ, вы можете столкнуться с очень дорогим счетом! Мы буквально видели, как это происходит. Когда мы впервые начали экспериментировать с этой технологией, мы попросили агента найти лучший рецепт цацики в мире. Мы надеялись, что он найдет списки победителей и использует некоторую логику для их сравнения (например, количество просмотров на веб-сайте или популярность домена). В итоге наш агент потерялся в море противоречивых кулинарных блогов и рекомендаций множества чеснока (потому что любой ИИ знает, где происходит магия цацики) и не получил реального «Опа!» в неудовлетворительном финале.
Контроль и наблюдаемость
Гибкость, позволяющая агентам надежно выполнять новые задачи и решать проблемы, возможна только благодаря ослаблению контроля над системой. Поэтому критически важно отслеживать и понимать процесс принятия решений и действия агента в агентных рабочих процессах. В зависимости от того, как агент реализован, полная внутренняя работа и потоки принятия решений не всегда прозрачны, что потенциально может привести к непредвиденным последствиям. Например, модель может адаптироваться непредсказуемым образом, приводя к поведению, не соответствующему вашим первоначальным целям или ценностям.
Эта недостаток контроля и наблюдаемости может привести к некоторым нежелательным результатам, о которых вы узнали в Главе 5; например, предвзятые или дискриминационные действия, которые могут иметь серьезные последствия в высокорисковых приложениях, таких как здравоохранение, финансы или образование. Идя по этому пути, мы хотим напомнить вам, насколько важно разработать требования к прозрачным и объяснимым БЯМ, позволяющие в реальном времени мониторить и корректировать действия для снижения этих рисков.
Агентные системы | 215
Безопасность и сложные разрешения
Существует множество потенциальных проблем безопасности и защиты, которые необходимо решить, прежде чем любые самостоятельно построенные (и, возможно, готовые) агенты могут быть безопасно развернуты в сложных корпоративных средах. Например, если агент отдела кадров, предназначенный для выполнения запросов сотрудников, имеет доступ к базе данных отдела кадров, содержащей конфиденциальные данные обо всех сотрудниках, должны быть введены меры безопасности данных, чтобы агент случайно не раскрыл (или не имел доступа к) конфиденциальной информации о других сотрудниках конечному пользователю. Проще говоря, это требует детального контроля доступа (FGAC) и контроля доступа на основе ролей (RBAC), соблюдения протоколов передачи персонально идентифицируемой информации (PII), принципа наименьших привилегий, системы идентификации и многого другого. Аналогично, в многоагентных системах должны быть установлены протоколы связи, определяющие, как агенты с доступом к различным типам конфиденциальной информации могут работать вместе без утечки конфиденциального контента и с соблюдением регуляций по передаче данных, требующих шифрования.
Три совета, чтобы начать: Наши лучшие практики работы с агентами
Когда вы сталкиваетесь с чем-то новым, всегда лучше получить несколько советов, чтобы начать. Мы создали этот раздел с дополнительной помощью от некоторых сотрудников IBM, таких как Анна Гутовская, чья повседневная работа заключается в обучении агентных систем, которые достаточно умны, чтобы делать невероятные вещи, но не настолько дикие, чтобы они начали делать сумасшедшие вещи. Если вы обратите внимание на эти советы, вы будете жить своей лучшей агентной жизнью — жизнью, которой можно доверять.
1. Журналы активности
Чтобы лучше понять и отладить поведение агента постфактум, разработчики могут предоставить пользователям доступ к журналу действий агента. Эти действия могут включать использование внешних инструментов и описание отдельных шагов, предпринятых для достижения цели. Эта прозрачность дает пользователям представление об итеративном процессе принятия решений агента и предоставляет возможность выявить ошибки и построить доверие.
2. Прерывание и наблюдаемость во время выполнения
Не допускайте работы агентов ИИ в течение чрезмерно долгих периодов времени, чтобы избежать случаев непреднамеренных бесконечных циклов обратной связи, изменений в доступе к определенным инструментам или сбоев из-за недостатков дизайна. Один из способов достичь этого — реализовать возможность прерывания, когда пользователь-человек (или внешний менеджер ресурсов, такой как Turbonomic) может остановить бессмысленный (или бесконечный) рабочий процесс. Чтобы сделать возможность прерывания более мощной, вам также нужна наблюдаемость в вашей агентной системе, чтобы вы могли отслеживать, где находится агент в своем рабочем процессе, и если что-то пойдет не так, быстро найти, что и как.
216 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!
32 Бьенфенг Сюй и др., «ReWOO: Разделение рассуждений от наблюдений для эффективных дополненных языковых моделей», препринт, arXiv, 23 мая 2023 г., https://arxiv.org/abs/2305.18323.
33 Веселка Сашева Петрова-Димитрова, «Классификации интеллектуальных агентов и их применения», Fundamental Sciences and Applications 28, № 1 (2022).
3. Человеческий надзор
Чтобы помочь в процессе обучения агентов ИИ, особенно на ранних этапах в новой среде, полезно предоставлять время от времени человеческую обратную связь. Это позволяет вашим агентам сравнивать свою производительность с ожидаемым стандартом и соответствующим образом корректироваться. Эта форма обратной связи полезна для улучшения адаптивности любого агента к предпочтениям пользователя.32
Например, вы можете настроить свою систему таким образом, чтобы каждый раз, когда ваш агент завершает задачу, он останавливался и запрашивал обратную связь — это дает вам возможность сказать, что отсутствует или что можно сделать лучше. Figure 7-10 был примером того, где это было бы отлично. Прочитав посты в социальных сетях, мы могли бы придать им форму, лучше соответствующую нашему стилю и аудиториям, использующим эти каналы. Затем мы могли бы передать эту обратную связь в БЯМ, которая извлекала бы эти советы для каждой задачи и помещала бы их в память наших агентов для использования в будущем. Опять же, здесь мы могли бы использовать ИИ, чтобы помочь ИИ, создав модель ИИ «судья», которая смотрела бы на результат нашей работы с БЯМ и проверяла, соответствует ли он критериям.
Кроме того, лучшей практикой является требование человеческого одобрения до того, как агент ИИ предпримет действия с высоким воздействием. Например, действия, варьирующиеся от отправки массовых электронных писем до торговли на финансовых рынках, должны требовать человеческого подтверждения.33 Рекомендуется определенный уровень человеческого контроля для таких высокорисковых доменов.
Подумайте об этом, когда речь заходит об агентах ИИ
Агенты ИИ и агентные системы становятся популярными по причине: они способны значительно улучшать производительность и надежность ИИ в сложных задачах. Способность планировать и рассуждать для задачи, получать самую свежую информацию с помощью вызовов инструментов и разбивать сложные проблемы на более мелкие, более управляемые компоненты также открывает двери для более сложных задач для более мелких моделей с открытым исходным кодом. В конце концов, эта технология все еще развивается, и пока она улучшает производительность и продуктивность моделей, убедитесь, что вы уделяете время вопросам безопасности, защищенности и стоимости, прежде чем использовать агенты ИИ для производственных задач.
Агентные системы | 217
Завершение главы
В мире ИИ происходит много захватывающих вещей, и мы надеемся, что убедили вас в том, что независимо от появления SLM или эффективности более системных подходов к ИИ, включая маршрутизацию моделей, MoE или агентные системы, «одна модель не будет править всеми». В следующей главе мы расскажем о том, как предприятия могут расширить эти системные реализации БЯМ, специализируя SLM на корпоративных данных.
218 | Глава 7: Куда движется эта технология — Одна модель не будет править всеми!