Глава 12: Следующие шаги
Мы охватили множество тем в этой книге. Большая часть книги посвящена популярным и полезным подходам, которые широко применимы в современных задачах ИИ. Мы обсудили основные концепции и модели глубокого обучения, а также несколько библиотек программирования, которые оказались очень удобными для реализации моделей глубокого обучения. Основным алгоритмом оптимизации, который сегодня в основном используется в глубоком обучении, является обратное распространение ошибки, и мы привели несколько примеров использования этого метода оптимизации.
Однако современные задачи, связанные с ИИ, довольно масштабны; обратное распространение ошибки применимо только к функциям, которые являются дифференцируемыми. Известный исследователь ИИ Франсуа Шолле сформулировал это так:34
Обратное распространение — это централизованный ответ, который применим только к дифференцируемым функциям, где «управление» означает настройку некоторых параметров и где цель оптимизации уже известна. Его диапазон применимости минимален.
С учетом этого мы предоставили другие алгоритмы оптимизации (такие как оптимизация роем частиц, генетические алгоритмы и имитация отжига), чтобы охватить возможности оптимизации многих задач ИИ, а также несколько других приложений как в промышленности, так и в научных исследованиях. И наконец, мы представили общую картину альтернативных фреймворков ИИ, чтобы вы могли полностью понять искусственный интеллект в современном мире науки о данных.
В этой заключительной главе книги мы рассмотрим «следующие шаги», необходимые для продвижения за пределы этой книги и улучшения вашего понимания области науки о данных. Сначала мы кратко обсудим большие данные, которые стали по существу неизбежными. После этого мы очертим некоторые выдающиеся области специализации в современной науке о данных. Мы надеемся, что это обсуждение предоставит вам некоторые перспективы относительно широких областей, которые могут быть задействованы в ваших будущих проектах. Наконец, мы перечислим некоторые полезные, общедоступные
доступные наборы данных, которые вы можете использовать для практики и исследований.
Большие данные
Термин «Большие данные» — вероятно, один из самых часто используемых терминов в компьютерных науках сегодня. Хотя определение термина несколько расплывчато (так как название включает очень субъективный термин «большой»), мы можем кратко определить его как «объем данных, достаточно большой, чтобы обычный персональный компьютер не мог их обработать». По этому определению, термин «большие» относится к терабайтам, петабайтам или даже экзабайтам данных (чтобы дать вам представление о масштабе, если собрать все данные, к которым человек обычно имел бы доступ за всю свою жизнь, то вряд ли получится больше 1 экзабайта).
Чтобы еще более сузить определение, рассмотрим четыре V, описанные IBM.35 Большие данные постоянно увеличиваются в объеме, поступают с растущей скоростью, добываются из постоянно увеличивающегося разнообразия и с неопределенностью в отношении достоверности. Эти так называемые четыре V — объем, скорость, разнообразие и достоверность — являются одними из наиболее важных характеристик больших данных в современном высокосвязанном цифровом мире.
Почему большие данные важны? Ответ на этот вопрос кроется всего в двух утверждениях:
- Большие данные позволяют нам получать более полные ответы на наши вопросы, потому что они содержат много информации.
- Мы полагаемся на эти ответы с большей уверенностью, потому что по мере увеличения объема данных наша уверенность обычно растет.
Успехи алгоритмов глубокого обучения, которые мы рассмотрели в предыдущих главах, также связаны с большими данными. Две основные причины такого успеха глубокого обучения — это достижения в вычислительной мощности современных компьютеров и огромный объем доступных для использования данных.
Для работы с огромными объемами данных важны две новые технологии; остаток обсуждения больших данных мы посвятим этим
технологиям. Одна из них — Hadoop, а другая — Spark, оба проекта с открытым исходным кодом, созданные Apache Foundation. Мы рекомендуем вам узнать о них больше, поскольку они особенно полезны при работе с большими объемами данных.
Hadoop
Если мы хотим хранить данные только для резервного копирования, то объем данных может не быть приоритетом для специалиста по данным. Однако, чаще всего, мы хотим анализировать эти данные, извлекая полезные знания из скрытой в них информации. Распределенная технология хранения данных под названием Hadoop была разработана именно для удовлетворения этой потребности.
Hadoop (обычно называемый «кластер Hadoop») имеет четыре ключевых компонента: Commons, YARN, HDFS и MapReduce. Commons — это структура утилит Hadoop, а YARN — инструмент для распределения ресурсов и планирования в Hadoop. HDFS — это аббревиатура Hadoop Distributed File System; именно здесь фактически хранятся данные. MapReduce — это инструмент для обработки данных в распределенных системах.
Рисунок 26
иллюстрирует компоненты Hadoop простым способом.
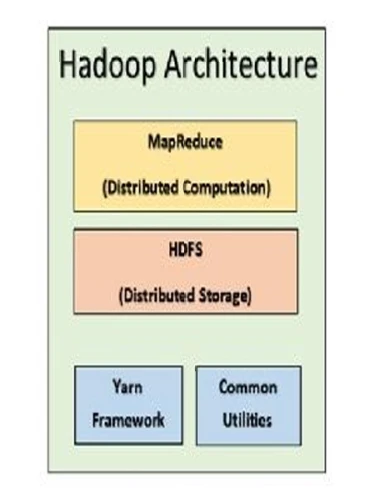
Рисунок 26: Основные компоненты Hadoop. Hadoop включает Commons, YARN, HDFS и MapReduce. Источник: https://bit.ly/2NTVBg7.
Как специалист по данным, вы, вероятно, используете более широкий набор инструментов, чем указанные выше четыре. Вы используете эти инструменты, потому что они облегчают вам жизнь. Они обычно абстрагируют архитектурные и административные аспекты работы в кластере Hadoop. Основное, что специалист по данным хочет испытать, работая с данными, хранящимися в кластере Hadoop, — это, вероятно, запрашивать данные так, как если бы он запрашивал одномашинную реляционную систему управления базами данных, а не администрировал кластер Hadoop.
Для этого вы можете использовать Hive и его язык запросов HiveQL. С помощью HiveQL можно забыть о распределенной природе данных и писать запросы так, как если бы все данные находились на одной машине. Однако из-за огромных объемов данных в HDFS запросы HiveQL обычно занимают больше времени, чем традиционные запросы SQL! Другие инструменты (например, Presto) обеспечивают более быстрый доступ к данным в HDFS, но они, как правило, более требовательны к вычислительным ресурсам и их требования более высоки.
Apache Spark
На данный момент мы рассмотрели, как хранить данные большого объема и получать к ним доступ в кластерной и распределенной среде. Поскольку конечная цель специалиста по данным — создавать аналитические модели на основе этих данных, нам нужна другая технология для удобной работы с данными, хранящимися в HDFS.
Apache Spark — одна из наиболее широко используемых технологий, предоставляющих распределенные вычисления. Spark упрощает некоторые распространенные задачи, включая планирование ресурсов, выполнение заданий и надежную связь между узлами кластера. С 2018 года Spark поддерживает пять языков программирования: Scala, Python, Julia, R и Java.
Spark использует представление данных под названием Resilient Distributed Dataset (RDD), которое очень похоже на датафреймы в Python, Julia и R. RDD поддерживает распределенные вычисления, работая на нескольких машинах, используя память всех этих распределенных компьютеров в кластере. Когда RDD создан, вы можете использовать Spark для взаимодействия с этими распределенными данными так, как если бы данные находились в памяти одной машины. Таким образом, Apache Spark изолирует распределенную природу вычислительной инфраструктуры для пользователя, что очень удобно при работе над задачами науки о данных.
Рисунок 27
изображает базовую архитектуру Apache Spark.
Приведенный ниже пример на Python демонстрирует, как несколько строк кода в Apache Spark могут легко подсчитать слова в документе, хранящемся в HDFS:
text_file = sc.textFile(“hdfs://...”) counts = text_file.flatMap(lambda line: line.split(“ “)) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) counts.saveAsTextFile(“hdfs://...”)
Первая строка считывает распределенные данные из HDFS. Функция flatMap() разделяет каждое слово в текстовом файле. Функция map() объединяет каждое слово с 1 в виде кортежа ключ-значение. Функция reduceByKey() суммирует числа для одинаковых ключей (в данном примере — слова). Последняя строка просто сохраняет результаты — вот и всё!
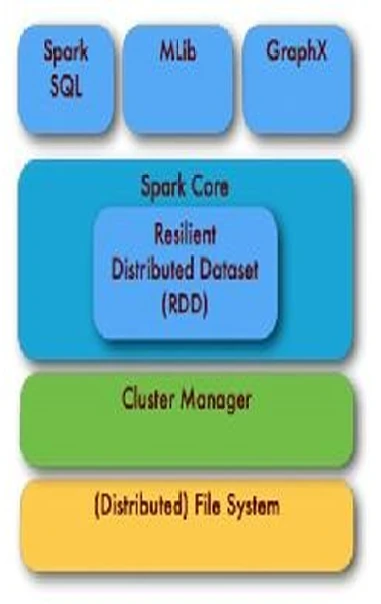
Рисунок 27: Архитектура Apache Spark. Включает распределенную файловую систему (например, HDFS), менеджер кластера, ядро Spark (RDD) и высокоуровневые API (такие как MLlib, Spark SQL и GraphX). Источник: https://bit.ly/2JqjBWs.
Специализации в науке о данных
В последнее время наука о данных стала широкой дисциплиной, поэтому специализация в конкретной области обычно является необходимостью, а не роскошью. Здесь мы обсудим несколько разных нишевых областей в рамках науки о данных, в надежде помочь вам решить, какая область вас больше всего интересует.
Инженерия данных
Ранее в этой главе мы говорили о больших данных и некоторых связанных технологиях. Мы отметили, что большие объемы данных требуют специального подхода с точки зрения хранения и вычислительных сред. Сегодня управление огромными объемами данных — трудоемкая задача, требующая
специализации, связанной с администрированием систем и управлением базами данных. Инженеры данных отвечают за сбор, хранение и обеспечение безопасности данных. Они также управляют инфраструктурой конвейера науки о данных или машинного обучения в компании или организации. В этом отношении инженерия данных больше связана с системным администрированием, чем с наукой о данных. Однако для тех из вас, кто заинтересован в работе с этими аспектами технологии, должности инженеров данных могут быть наиболее актуальными.
Обработка естественного языка
Обработка естественного языка (NLP) — это конкретная область в рамках искусственного интеллекта, которая фокусируется на задачах, связанных с человеческими языками. Эти задачи включают суммаризацию текста, тематическое моделирование, языковое моделирование, машинный перевод, категоризацию текста, анализ настроений и многое другое. Технология, используемая Google Translate, — лишь одно из распространенных приложений NLP. Не все задачи, связанные с NLP, подпадают под зонтик ИИ, поскольку определенные структуры (такие как системы представления знаний), хотя и полезны для NLP, не имеют никаких черт современных систем ИИ.
NLP наследует множество концепций и идей из лингвистики, сочетая их со статистическими методами машинного обучения для решения задач понимания человеческого языка. Эта область находится на передовом крае таких технологий, как последовательный перевод между языками, чат-боты, поисковые системы и системы машинного перевода.
Компьютерное зрение
Компьютерное зрение — еще одна область ИИ, целью которой является заставить машины понимать визуальные аспекты мира, в котором мы все живем. Модели и методы, используемые в компьютерном зрении, обрабатывают цифровые изображения или видео, которые им предоставляются. Распознавание изображений, обнаружение объектов и отслеживание объектов — лишь небольшое подмножество задач, решаемых сегодня компьютерным зрением.
Некоторые фантастические применения экспертизы в области компьютерного зрения — это распознавание движения, дополненная реальность, автономные автомобили, робототехника, изображение
восстановление и генерация изображений. Кроме того, компьютерное зрение имеет большой потенциал в приложениях дополненной реальности, где виртуальные объекты накладываются на реальный мир. Исходя из всего этого, мы считаем, что компьютерное зрение продолжит быть одной из самых многообещающих областей исследований в рамках искусственного интеллекта и науки о данных.
Интернет вещей
Этот термин (часто сокращаемый как IoT) относится к тому факту, что в современном мире миллиарды гаджетов и всевозможные машины постоянно подключены к Интернету (есть вероятность, что вы читаете электронную версию этой книги через одно из них!). Поскольку компьютеры становятся все меньше (например, Raspberry Pi), они могут помещаться во все более распространенные устройства, что приводит к взрывному росту доступных «умных» гаджетов. Данные, генерируемые всеми этими подключенными устройствами, огромны и предоставляют очень обширное поле для науки о данных. Инфраструктура больших данных, необходимая для хранения и обработки такого огромного количества данных, требует экспертизы в области больших данных.
Кроме того, анализ такого большого объема данных является особой областью внимания науки о данных. Обнаружение аномалий и прогнозное обслуживание — лишь два примера применения науки о данных в рамках IoT. С постоянным увеличением числа устройств, подключенных друг к другу и к Интернету, IoT станет одной из основных областей изучения в науке о данных.
Биостатистика и здравоохранение
Ещё одна область, которая всё больше зависит от науки о данных, — это биостатистика. От прогнозирования заболеваний до исследований в области геномики, наука о данных является краеугольным камнем здравоохранения. Что касается IoT, носимые медицинские гаджеты — это ещё одна область экспертизы для специалистов по данным. Учитывая критическую важность здравоохранения в жизни людей, мы считаем, что биостатистика и здравоохранение входят в число наиболее перспективных областей специализации в науке о данных.
Социальные науки
Эта область слишком обширна, чтобы начать детально ее рассматривать, но ясно, что
анализ людей (их привычек, расходов или взаимоотношений, например) в большом масштабе требует сложных методов. В частности, методы временных рядов широко применимы в социальных науках, особенно с учетом современных достижений в вычислительной мощности и доступности данных.
Очевидно, это не исчерпывающий список ниш в науке о данных. Это просто основные моменты, которые относительно популярны в настоящее время. Более того, многие междисциплинарные области (такие как робототехника, например) могут включать различные компоненты искусственного интеллекта (например, компьютерное зрение и НЛП). Рассмотрим, например, как дополненная реальность сочетает компьютерное зрение со многими другими процессами, как мы кратко видели ранее.
Чтобы стать экспертом практически в любой области, включая любую из этих подобластей науки о данных, требуется много практики. Конечно, вы не сможете практиковаться без доступа к полезным инструментам и наборам данных. С этой целью в следующем разделе мы предоставим некоторые ресурсы, которые могут оказаться вам полезными.
Общедоступные наборы данных
Изучение науки об искусственном интеллекте требует надежных (и, в идеале, интересных) данных. Поскольку темы в этой книге в основном охватывают методы обучения с учителем, данные, необходимые для этих методов, должны быть предварительно размечены. Данные должны сопровождаться истинными классами или истинными значениями целевых переменных. Однако разметка набора данных — непростая задача. Поэтому обычно мы используем общедоступный набор данных, который уже размечен. В предыдущих главах этой книги мы приводили примеры использования нескольких синтетических наборов данных, которые мы подготовили для вас, а также некоторые общедоступные наборы данных, популярные в литературе.
Одним из отличных ресурсов, включающих множество полезных наборов данных, является Kaggle, веб-сайт, ориентированный на соревнования по науке о данных. Эти соревнования собирают тысячи команд со всего мира для состязания друг с другом в решении конкретной задачи науки о данных. Kaggle также предлагает множество полезных наборов данных.36 Более того, участие в соревнованиях Kaggle также является эффективным способом практиковать свои навыки в науке о данных, особенно связанные с моделированием данных. Вы также можете анализировать ядра (kernels), которые предоставляются участниками, поскольку они содержат много полезных знаний.
Помимо наборов данных Kaggle, здесь мы приводим список полезных наборов данных, которые являются общедоступными. Список включает наборы данных, которые обычно используются в компьютерном зрении, обработке естественного языка, распознавании речи и анализе временных рядов.
Компьютерное зрение
- MNIST: Это очень популярный набор данных, содержащий рукописные цифры размером 25x25. Он включает 60 000 примеров для обучения и 10 000 примеров для тестирования. Посетите https://bit.ly/1REjJgL.
- CIFAR 10 и CIFAR 100: Набор данных CIFAR-10 состоит из 60 000 цветных изображений размером 32x32 в 10 классах, по 6 000 изображений в каждом классе. Имеется 50 000 обучающих изображений и 10 000 тестовых изображений. Набор данных CIFAR-100 точно такой же, как CIFAR-10, за исключением того, что он содержит 100 классов, по 600 изображений в каждом. Имеется 500 обучающих изображений и 100 тестовых изображений в каждом классе. 100 классов в CIFAR-100 сгруппированы в 20 суперклассов. См. https://bit.ly/1QZAvsv.
- ImageNet: Это очень популярный набор данных изображений с 1000 категориями. Посетите https://bit.ly/2Lk69DC.
- Open Images: Это набор данных, содержащий около 9 миллионов изображений, размеченных (Google) с метками на уровне изображений и ограничивающими рамками объектов. 4-я версия обучающего набора содержит 14.6 миллиона ограничивающих рамок для 600 классов объектов на 1.74 миллиона изображений, что делает его крупнейшим существующим набором данных с аннотациями местоположения объектов. См. https://bit.ly/2JqJ5Bf.
Естественный язык
- WikiText: Набор данных для языкового моделирования WikiText — это коллекция из более чем 100 миллионов токенов, извлеченных из набора проверенных Хороших и Избранных статей в Википедии. Посетите https://bit.ly/2NSPI2J.
- Пары вопросов Quora: Это включает более 400 000 строк
- потенциальных пар дубликатов вопросов. Каждая строка содержит идентификаторы для каждого вопроса в паре, полный текст каждого вопроса и бинарное значение, указывающее, действительно ли строка содержит дубликат пары. См. https://bit.ly/2upwz0x.
- SQuAD: Stanford Question Answering Dataset (SQuAD) — набор данных для понимания прочитанного, состоящий из вопросов (заданных краудсорсерами) к набору статей Википедии. Ответ на каждый вопрос является частью текста из соответствующего пассажа для чтения. Вопрос также может не иметь ответа в соответствующей статье. Версия 2 содержит 100 000 вопросов и доступна для просмотра на https://bit.ly/2v0G8At.
- Billion Words: Этот большой, общего назначения набор данных для языкового моделирования находится по адресу https://bit.ly/2Ll43Dy.
- Common Crawl: Содержит петабайты данных, собранных за 8 лет веб-обхода. Корпус содержит необработанные веб-данные, метаданные и текстовые извлечения. См. https://bit.ly/2NQjZzv.
- Stanford Sentiment Treebank: Это общий набор данных о настроениях, находится по адресу https://stanford.io/2uwa8qz.
Речь на английском
- Тексты разговоров на английском языке из HUB5 за 2000 год: Этот набор был разработан Консорциумом лингвистических данных (LDC). Он включает тексты 40 телефонных разговоров на английском языке, использованные в оценке HUB5 2000 года, спонсируемой NIST (Национальный институт стандартов и технологий). Посетите https://bit.ly/2JrtkKn.
- LibriSpeech: Этот корпус содержит около 1000 часов английской речи, прочитанной, подготовленной Василом Панайотовым при содействии Даниэля Поуви. Данные взяты из прочитанных аудиокниг проекта LibriVox, тщательно сегментированы и выровнены. См. https://bit.ly/2zJnjJC.
- TIMIT: Содержит широкополосные записи 630 носителей восьми основных диалектов американского английского, каждый из которых читает десять
фонетически насыщенных предложений. Посетите https://bit.ly/2zJni8w.
Социальные науки и временные ряды
- Всемирный банк: Всемирный банк — международная организация, которая собирает и публикует данные об экономическом и социальном развитии, а также финансовые показатели. Эти наборы данных особенно полезны для специалистов по науке о данных в социальных науках, а также для тех, кто интересуется анализом временных рядов. См. https://bit.ly/2yUZmdS.
- МВФ: Международный валютный фонд — международная организация, которая фокусируется на финансовой стабильности. Его наборы данных состоят из финансовых и монетарных индексов, которые полезны для анализа временных рядов. Посетите https://bit.ly/2FqDyNr.
Резюме
- Большие данные критически важны для искусственного интеллекта и современной науки о данных. Огромные объемы данных постоянно генерируются нашим высокосвязанным цифровым миром. Эти данные требуют специальных технологий для хранения и анализа. Hadoop и Spark, которые являются проектами Apache Foundation, — две полезные технологии для больших данных.
- Существует множество областей специализации в науке о данных; для специалистов по данным естественно специализироваться в одной (или нескольких) областях.
- Один из важнейших источников данных — сайт www.kaggle.com. Kaggle проводит соревнования по науке о данных и предоставляет множество наборов данных.
- Существует несколько общедоступных наборов данных, которые полезны для практики науки о данных. Вы улучшите свое понимание
- науки о данных и приобретете опыт, создавая модели на основе этих наборов данных. Большинство перечисленных наборов данных уже имеют некоторые эталонные оценки, так что вы можете сравнить производительность своих моделей с эталонными.
https://bit.ly/2wsdhIC.
Мы хотим предупредить наших читателей, что в литературе и в Интернете они найдут всевозможные дополнительные «V». Здесь мы используем определение IBM как краткое и точное. Источник: https://ibm.co/2AFln5v.
https://www.kaggle.com/.