Глава 11: Альтернативные фреймворки ИИ в науке о данных
С момента зарождения ИИ было предпринято множество усилий по открытию новых техник и подходов, способствующих развитию дисциплины. Иногда новые достижения представляют собой незначительные вариации старых; в других случаях мы полностью отбрасываем старые техники и начинаем с нуля. Хотя литература по искусственному интеллекту основана на десятилетиях усилий исследователей и практиков, динамика изменений и улучшений сохраняется.
Здесь мы упомянем некоторые альтернативные фреймворки ИИ, которые кажутся нам многообещающими. При этом мы надеемся не только вооружить вас более эффективными инструментами для решения проблем, но и подчеркнуть огромный потенциал этой динамичной области для улучшения и изменений. Темы, затронутые в предыдущих главах, охватывают более популярные фреймворки ИИ. Знакомство с некоторыми альтернативными фреймворками ИИ может помочь вам исследовать возможности будущих рубежей текущих исследований.
В этой главе мы рассмотрим три альтернативных фреймворка, которые, по нашему мнению, выдержат испытание временем и будут использоваться в будущем. Первым из них является Машина экстремального обучения, семейство систем, основанных на сетях, очень похожих на те нейронные сети, которые мы видели ранее, с существенным отличием в отношении оптимизации скрытых слоев. Вторым альтернативным фреймворком является Капсульная сеть, которая является еще одним изобретением известного эксперта в области ИИ профессора Джеффри Хинтона. Наконец, мы обсудим Нечеткую логику и Систему нечеткого вывода, фреймворк, разработанный одним из людей, который вывел ИИ на карту, профессором Заде.
Машины экстремального обучения (ELMs)
Вы можете вспомнить из нашего обсуждения глубокого обучения, что многослойные прямые сети состоят из множества слоев, соединенных друг с другом. Первый слой называется входным, последний — выходным, а между ними находятся скрытые слои. Когда мы обучаем многослойную прямую сеть с использованием обратного распространения ошибки, мы настраиваем все веса, связанные с соединениями между всеми соединенными слоями. Даже если мы начинаем со случайной инициализации весов (как мы обычно делаем), в каждой итерации алгоритма обратного распространения ошибки мы соответствующим образом обновляем веса. Помните, что мы используем численные методы аппроксимации (например, градиентный спуск) для реализации обратного распространения ошибки.
Основная идея ELM заключается в том, что настраиваться должны только веса выходных слоев; веса скрытых узлов настраиваться не должны. Прежде чем подробно объяснять ELM, давайте сначала рассмотрим цели ELM, чтобы понять, почему мы не будем настраивать веса скрытых узлов.
Мотивация, лежащая в основе ELMs
Когда Фрэнк Розенблатт предложил концепцию перцептрона в 1958 году, он верил, что перцептроны однажды позволят компьютеру «ходить, говорить, видеть, воспроизводить себя и быть сознательным своего существования».26 Вскоре после этого, однако, Минский и Паперт показали, что перцептроны без скрытых слоев не могут даже справиться с простой задачей XOR.27 Однако исследователи ИИ поняли, что скрытые слои являются критически важными компонентами любой модели нейронной сети. Более того, доказано, что достаточно сложные архитектуры модели нейронной сети со скрытыми слоями могут аппроксимировать любую непрерывную функцию - известную как универсальная аппроксимация! С тех пор включение скрытых слоев в модель нейронной сети и настройка параметров скрытого слоя стало основной практикой в литературе по нейронным сетям.
Согласно оппонентам идеи, что конечной целью любой искусственной нейронной сети является имитация функционирования биологического мозга, ANN должны быть спроектированы в соответствии с данными нейронауки. Основной принцип литературы по ELM также заключается в этой идее. Потому что мы знаем, что биологический мозг, и особенно человеческий мозг, отлично учится новому. Но структура биологического мозга кажется резко контрастирующей с представлением о том, что скрытые слои должны быть
настроен. Короче говоря, нейроны в биологическом мозге образуют слоистые структуры, которые имитируют ANN. Однако наивно ожидать, что каждое отдельное соединение между двумя нейронами в нашем мозге подстраивается под каждое наблюдение, которое мы встречаем в нашей жизни. Действительно, недавние открытия в нейронауке подтверждают эту идею.28 Таким образом, сторонники ELM утверждают, что для того, чтобы ANN соответствовали работе биологического мозга, скрытые узлы ANN не должны настраиваться.
Архитектуры ELMs
Простейшая Машина экстремального обучения представляет собой прямую сеть с одним скрытым слоем; фактически, она весьма похожа на модель однослойного перцептрона. Однако, если мы используем различные ELM для каждого слоя, легко расширить эту архитектуру с одним скрытым слоем до многослойных прямых сетей.
Начнем с архитектуры прямой сети с одним скрытым слоем.
Рисунок 18
показывает базовую архитектуру ELM, с входным слоем, скрытым слоем и выходным слоем. Как упоминалось ранее, архитектура сравнима с архитектурой прямой сети с одним слоем. Разница в том, что при оптимизации однослойного ELM мы не настраиваем веса скрытого слоя. Мы просто настраиваем веса выходного слоя.
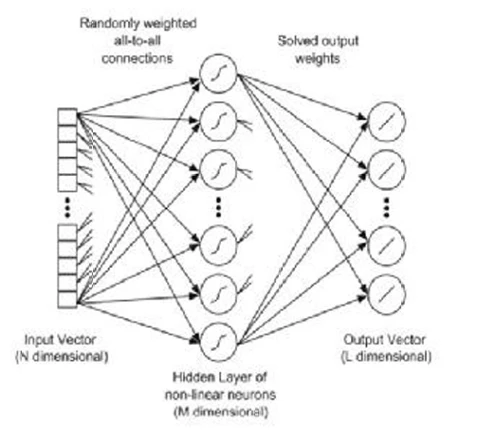
Рисунок 18. Базовая архитектура машины экстремального обучения. ИСТОЧНИК: Tissera, Migel D., and Mark D. McDonnell. “Deep extreme learning machines: supervised autoencoding architecture for classification.” Neurocomputing 174 (2016): 42-49.
Строительные блоки многослойных прямых ELM - это просто однослойные прямые ELM. В этом случае мы комбинируем различные однослойные элементы, складывая их друг за другом. По сути, каждый скрытый слой - это просто еще один ELM. По сути, это делает многослойный ELM ансамблем ELM, хотя и более сложным, чем те, которые мы видели в предыдущей главе.
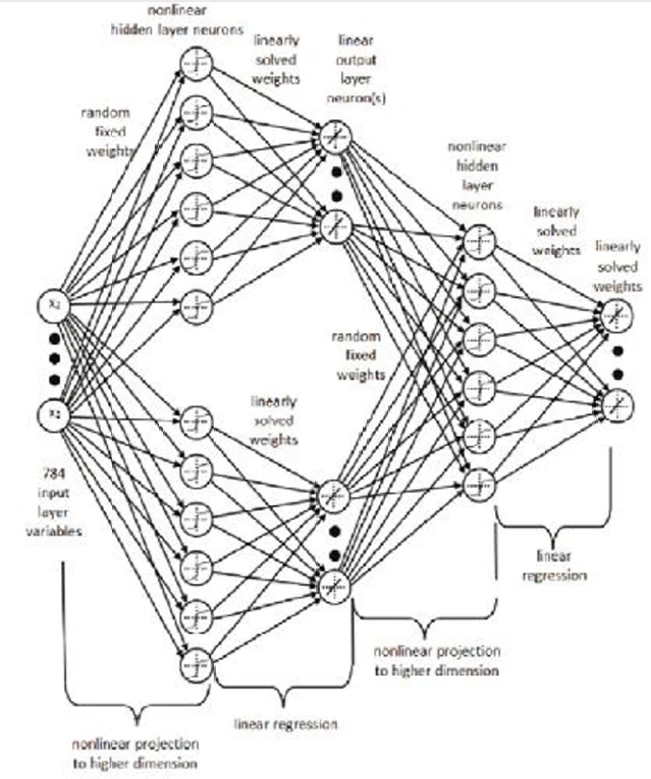
Рисунок 19. Базовая архитектура многослойной машины экстремального обучения. ИСТОЧНИК: Tissera, Migel D., and Mark D. McDonnell. “Deep extreme learning machines: supervised autoencoding architecture for classification.” Neurocomputing 174 (2016): 42-49.
Рисунок 19
демонстрирует многослойный прямой ELM как комбинацию двух однослойных ELM. В этой многослойной архитектуре рассмотрите каждый скрытый слой как представитель операции или роли. Например, каждый однослойный ELM может заниматься сжатием, обучением признаков, кластеризацией, регрессией или классификацией, которые являются базовыми операциями или ролями любого ELM.
В другой альтернативной архитектуре для многослойных ELM, скрытый узел сам по себе может быть подсетью, образованной несколькими узлами. В результате некоторые локальные части одиночного ELM могут содержать многослойные слои.
Опять же, основной принцип ELM заключается в том, что скрытые слои не должны быть настроены. Хотя случайное присвоение значений весам скрытых слоев является вариантом, это не единственный доступный вариант. Альтернативно, скрытый узел в любом данном слое может быть линейным преобразованием узлов в предыдущем слое. В результате некоторые узлы генерируются случайным образом, а некоторые нет, но ни один из них не настраивается.29 Последнее, что следует отметить перед завершением обсуждения ELM, это то, что ELM могут быть объединены с другими моделями обучения. Выходные данные других моделей могут подаваться на вход ELM, или выходные данные ELM могут подаваться на вход других моделей. Это называется стекированными моделями и является еще одной формой ансамблей.30
Капсульные сети (CapsNets)
Капсульная сеть (или CapsNet) — это новый тип нейронной сети, предложенный в 2017 году профессором Джеффри Хинтоном и его студентами. Она демонстрирует невероятные перспективы для задач компьютерного зрения, в частности. Как мы обсуждали ранее, CNN обычно достаточно для решения этих задач, но у CNN есть некоторые недостатки. CapsNets, возможно, смогут устранить некоторые «слепые пятна» CNN.
Хотя идея базового архитектурного элемента «капсулы» не нова, модель, разработанная Хинтоном и его студентами, действительно нова. До их работы никто не знал, как обучать модель, построенную на основе капсул. Профессор Хинтон и его коллеги также предложили новый метод обучения этим методам, названный «динамическая маршрутизация между капсулами».
Мотивации, лежащие в основе CapsNets
Сверточные нейронные сети показали замечательные успехи в задачах компьютерного зрения, включая распознавание изображений и обнаружение объектов. Однако ориентация и пространственные отношения между этими компонентами не важны для CNN. Факторы, такие как угол обзора, перспектива и относительное положение объектов, не учитываются. Например, на
Рисунке 20
CNN обнаружит два лица-
похожие формы почти идентичны. Конечно, нам, людям, очевидно, что правая фигура совсем не является лицом, даже если некоторые энтузиасты современного искусства всё равно увидят в этом изображении лицо.
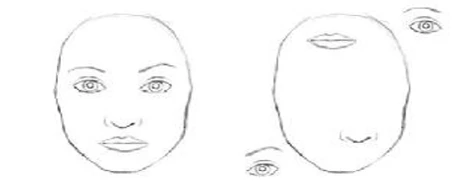
Рисунок 20: Эти два изображения будут считаться лицами по мнению CNN. Источник: https://bit.ly/2NTvsjB.
Чтобы смягчить эти недостатки CNN, Хинтон утверждал, что мы должны придумать новые типы сетевых структур, которые напоминают работу нашего мозга, поскольку он отлично справляется с вышеупомянутыми недостатками CNN. Согласно Хинтону, наш мозг делает нечто, называемое «обратной графикой», так что, когда мы видим что-то в мире глазами, наш мозг деконструирует иерархическое представление информации, пытаясь сопоставить его с выученными отношениями и паттернами, которые уже хранятся в нашем мозгу. Эти понятия в нашем мозгу не зависят от перспективы или угла обзора объектов. Чтобы более точно классифицировать изображения и распознавать объекты, ключевым является сохранение иерархических отношений «позы» между различными компонентами объектов.
CapsNets включают эти относительные взаимосвязи между объектами, представляя их в виде 4-мерных матриц поз. Для капсульной сети, те же объекты в верхнем и нижнем рядах
Рисунка 21
будут интерпретированы как идентичные.

Рисунок 21: Для капсульной сети, объекты в верхнем и нижнем рядах считаются одинаковыми. Источник: https://bit.ly/2NgLHfg.
CapsNet, созданная Хинтоном и его студентами, снизила частоту ошибок предыдущей передовой модели на 45% в задаче распознавания 3D-изображений! Более того, CapsNet достигает своей производительности, используя лишь небольшую часть обучающего набора предыдущей модели. В этом отношении CapsNet хорошо справляется с тем, что делают наши человеческие мозги. Далее, кратко рассмотрим архитектуру CapsNet.
Архитектура CapsNets
CapsNet включает шесть слоев. Первые три — это кодировщики, а последние три — декодеры:
- Сверточный слой
- Слой PrimaryCaps
- Слой DigitCaps
- Полносвязный слой
- Полносвязный слой
- Полносвязный слой
Рисунок 22
иллюстрирует первые три слоя кодировщиков:
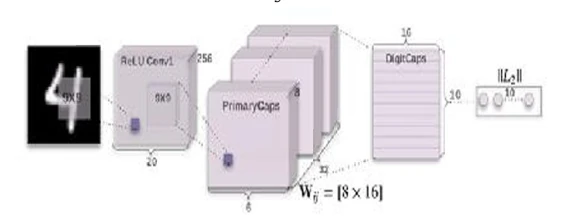
Рисунок 22: Кодировщики (первые три слоя) в CapsNet. Источник: https://bit.ly/2yyTvP2.
Мы уже обсуждали сверточный слой. Следующие два слоя используют капсулы. Капсула — это набор нейронов, которые индивидуально активируются для различных свойств объекта, таких как положение, размер и оттенок. Формально, капсула — это набор нейронов, которые коллективно производят вектор активности, причем один элемент для каждого нейрона содержит значение инстанцирования этого нейрона, такое как оттенок.31 Другими словами, капсула — это вложенный набор нейронных слоев (подобно сложному ансамблю). В нейронных сетях, которые мы рассматривали в предыдущих главах, мы добавляли слои поверх друг друга. Однако в CapsNets мы добавляем больше слоев внутри одного слоя. По сути, внутри капсулы состояние нейронов фиксирует свойства (такие как размер, положение или оттенок) одного объекта внутри изображения.32
После кодировщиков появляются декодирующие слои.
Рисунок 23
иллюстрирует эти последние три слоя, которые являются полностью связанными и работают как декодеры.
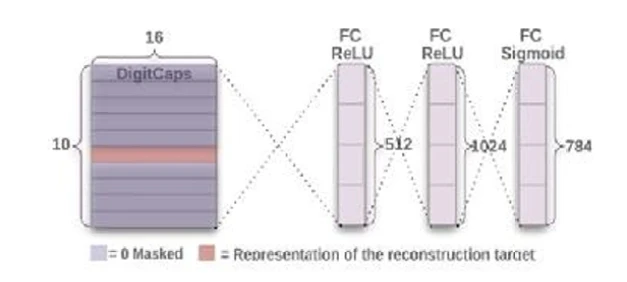
Рисунок 23: Декодеры (последние три слоя) в CapsNet. Источник: https://bit.ly/2yyTvP2.
Теперь, как обучать CapsNets, учитывая, что обратное распространение ошибки не применяется?
Динамическая маршрутизация между капсулами
CapsNets обучаются с использованием алгоритма динамической маршрутизации между капсулами, который мы подробно рассмотрим здесь. Таблица 1 показывает шаги алгоритма, как они объяснены в оригинальной статье Хинтона и др.33 Мы опустим подробное объяснение алгоритма для читателей, но укажем, что новая часть алгоритма происходит на строке 7, где обновляются веса. На этой строке каждая низкоуровневая капсула обращается к каждой высокоуровневой капсуле, исследует входные данные для каждой и затем обновляет соответствующий вес.
Формула обновления, используемая в оптимизации при обновлении весов, утверждает, что новое значение веса равно старому значению плюс скалярное произведение текущего выходного значения капсулы j и входного значения для этой капсулы из низкоуровневой капсулы i. Низкоуровневая капсула отправит свое выходное значение высокоуровневой капсуле, где выходное значение высокоуровневой капсулы похоже. Это сходство фиксируется скалярным произведением. Обратите внимание, что алгоритм повторяется r раз, где r — количество итераций маршрутизации.
Таблица 1: Алгоритм динамической маршрутизации. Источник: https://arxiv.org/abs/1710.09829
Если вы хотите глубже погрузиться в CapsNets, начните с работ, написанных Хинтоном и его студентами, уже упомянутых в этом разделе. Исследования для дальнейшего изучения CapsNets уже начались. В будущем мы, вероятно, увидим замечательную производительность этих моделей в некоторых сложных задачах.
Нечеткая логика и нечеткие системы вывода
Как мы кратко видели в Главе 2, нечеткие системы вывода (FIS) — это системы, основанные на нечеткой логике (FL), предназначенные для комплексного прогнозного анализа. Подход, который они используют, несколько отличается от других систем ИИ, поскольку они генерируют правила во время обучения и применяют их к неизвестным данным. Поскольку они используют функции принадлежности вместо оценок вероятности, подход, применяемый во всем этом процессе, является возможностным. Мы кратко объясним эту концепцию.
Нечеткие множества
В основе FL лежит концепция «нечетких множеств», которые являются объектами, не имеющими четких границ и, следовательно, допускающими потенциально бесконечное количество степеней. Точно так же, как наши глаза не могут идентифицировать одну точную точку,
где кончается зеленый цвет и начинается желтый, нечеткое множество А имеет разные уровни принадлежности для разных точек данных, которые могут иметь А как атрибут.
Например, если вы хотите узнать, насколько далеко находится место, вы можете представить его расстояние в виде серии нечетких множеств. Каждое нечеткое множество будет соответствовать определенному порогу или уровню расстояния — как пешком, на автобусе или однодневная поездка; или более абстрактным терминам: близко, средне и далеко. Каждый из этих уровней может быть выражен математической функцией (представленной буквой μ), относящейся к различным частям переменной расстояния (например, далеко). Эти функции почти всегда перекрываются каким-то образом и часто имеют треугольную или трапециевидную форму для снижения вычислительных затрат (см.Рисунок 24).
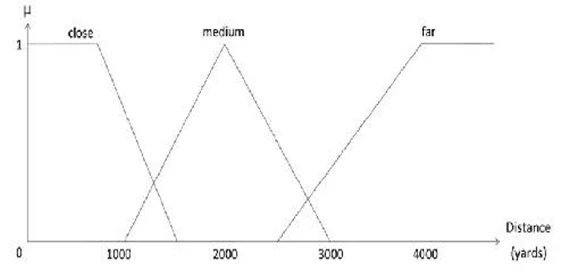
Рисунок 24. Нечеткое представление расстояния. Обратите внимание на три разных уровня, используемых (близко, среднее и дальнее), соответствующие соответствующим функциям принадлежности.
Важно отметить, что эти уровни часто выбираются так, чтобы иметь для нас смысл, поскольку они, как правило, соответствуют тому, как мы выражаем эти величины на нашем естественном языке. Присущая этим выражениям двусмысленность вполне приемлема, однако, поскольку она отражает неопределенность, всегда присутствующую в этих сценариях (например, «далеко» может означать
разные вещи для разных людей). Эта неопределенность моделируется через значения функций принадлежности этих уровней.
Функциональность FIS и нечеткие правила
FIS, по сути, анализирует полученные данные, выражает их в виде серии нечетких правил и создает модель, синтезирующую наиболее полезные из этих правил. Он работает очень похоже на дерево решений, хотя и более сложное и эффективное. Правила, которые в конечном итоге использует FIS, также легко построить в виде графика и могут быть полезны сами по себе.
Использование FIS включает применение лучших правил, найденных им во время фазы обучения, для генерации набора предсказаний, обычно сопровождаемых метрикой уверенности. Даже если в этих правилах много двусмысленности, конечный результат всегда однозначен (точный), поскольку после процесса дефаззификации все становится четким. Весь процесс можно суммировать на
Рисунке 25
.
Рисунок 25. Диаграмма функциональности FIS. Обратите внимание, что нечеткое представление данных, участвующих в этой форме, находится исключительно внутри самой системы, поскольку выходы (предсказания и правила) всегда точны.
Вышеупомянутые правила представляют собой соединение двух или более нечетких множеств интуитивным способом, принимающим форму IF-THEN утверждения. Нечеткое правило, таким образом, представляет собой систематический способ связи одного или нескольких нечетких множеств с решением (которое обычно является четким). Например, в зависимости от того, как вы хотели преодолеть определенное расстояние по городу за определенное время, например, пешком, на велосипеде или автобусе, или вызвать Lyft или Uber, вы могли бы моделировать проблему с помощью следующих правил (среди прочих):
IF {distance = close} THEN {walk}
IF {time = limited} THEN {call a cab}
IF {distance = medium} AND {time = enough} THEN
{take a bike / bus}
IF {distance = medium} AND {time = plenty} THEN
{walk}
IF {distance = high} AND {time = plenty} THEN
{take a bike / bus}
IF {distance = high} AND {time = enough} THEN
{call a cab}
Эти правила могут быть выражены в матричном формате для удобства:
Таблица 2: Представление нечетких правил в матричном формате.
Хотя хорошо спроектированный FIS должен минимизировать наложение правил, это все же возможно. Также возможно, что определенные сценарии не охватываются правилом — хотя таких случаев лучше избегать, если вы не уверены, что они никогда не возникнут на практике.
Естественно, при применении этих правил вы будете использовать конкретные числа, поэтому они проявятся более математически. Другими словами, хотя различные правила могут выглядеть очень общими, при применении они становятся довольно конкретными. Допустим, например, у вас встреча в 1200 ярдах от вас, и у вас есть 30 минут, чтобы добраться туда. Мы можем построить следующие соответствия принадлежности:
Таблица 3: Соответствия принадлежности для примера планирования поездки.
Исходя из этого, мы можем с разумной уверенностью предсказать, что в данной конкретной ситуации лучше всего идти пешком. Однако обратите внимание, что для другого города соответствия будут другими, и результаты, скорее всего, также будут отличаться.
К счастью, множество пакетов (в большинстве языков науки о данных) позволяют использовать нечеткую логику и нечеткие системы вывода в различных приложениях. Ниже приведены некоторые из наиболее интересных.
Python
scikit-fuzzy: расширение хорошо известного пакета scikit-learn, ориентированное на основные операции FL. Подробнее на https://pypi.org/project/scikit-fuzzy.
fuzzywuzzy: интересный пакет, ориентированный на сравнение строк с использованием FL. Подробнее на https://github.com/seatgeek/fuzzywuzzy.
pyfuzzy: более старый пакет, охватывающий операции FL. Подробнее на http://pyfuzzy.sourceforge.net/.
Peach: возможно, самый актуальный пакет на эту тему, охватывающий различные системы ИИ, используемые в науке о данных в качестве систем прогнозной аналитики. Подробнее на https://code.google.com/archive/p/peach/.
Julia
Fuzzy.jl: компактный пакет, содержащий различные инструменты как для базовой FL, так и для FIS. Это неофициальный пакет, который все еще находится в разработке. Подробнее на https://github.com/phelipe/Fuzzy.jl.
Некоторые советы по нечеткой логике
Нечеткая логика идеально подходит в случаях, когда неопределенность, присущая моделируемым явлениям, лучше описывается языком, чем математикой. Иногда математические функции могут быть подходящими для представления принадлежностей, например, функция Гаусса, поэтому FL можно рассматривать как гибкое расширение традиционных методов моделирования. FL проявляет себя там, где есть знания (возможно, от эксперта в предметной области), которые можно использовать для создания нечетких правил, или когда вы хотите расширить экспертную систему. В этом случае FL похожа на посредника между человеческими знаниями и машинной структурированной информацией.
Уточнение функции принадлежности в FIS часто достигается с помощью метода оптимизации. Однако следует проявлять осторожность, чтобы система не переобучалась, поскольку в таком виде ИИ существует возможность создания чрезмерно сложной модели. Одной из самых надежных систем под зонтиком FIS является ANFIS, которая использует архитектуру ANN для оптимизации задействованных функций принадлежности.
Хотя FL отлично подходит для моделирования неопределенности и построения надежных прогностических моделей на основе различных наборов данных (через FIS), оно не столь практично, когда речь идет о высокоразмерных наборах данных, из-за экспоненциального роста потенциальных правил. В таких случаях мы часто жертвуем интерпретируемостью ради производительности (например, путем уменьшения размерности). Однако, если у вас есть относительно небольшой метод выбора признаков, вы можете использовать его сначала; такой метод уменьшения размерности сохраняет полноту исходного набора признаков, поскольку мета-признаки не создаются (как в случае PCA, например).
Наконец, количество уровней, используемых для каждой переменной, может быть либо установлено вручную, либо выведено автоматически. Не все переменные необходимо моделировать в трехступенчатом виде, как показано в примерах.
Резюме
- Машины экстремального обучения (ELM) — одни из самых популярных альтернативных фреймворков в науке о данных.
- Основной принцип ELM заключается в том, что скрытые слои не должны настраиваться.
- Хотя ELM могут использоваться индивидуально, они также могут быть интегрированы с другими моделями обучения.
- Капсульные сети (CapsNets) — новый тип нейронной сети, направленный на лучшее улавливание иерархических представлений объектов.
- Алгоритм оптимизации, используемый в CapsNets, называется Динамическая маршрутизация между капсулами.
- CapsNets хорошо справляются с определением перспектив и угла обзора на изображениях; это основные слабые места альтернативных CNN.
- Нечеткая система вывода (FIS) анализирует полученные данные, выражает их в виде серии нечетких правил и создает модель, включающую наиболее полезные из этих правил.
- Правила, которые в конечном итоге использует FIS, легко построить, и они могут быть информативными
- самостоятельно.
- Нечеткая логика (FL) отлично подходит для моделирования неопределенности и построения надежных прогностических моделей на основе различных наборов данных (через FIS), но она не так практична, когда речь идет о высокоразмерных наборах данных, из-за экспоненциального роста потенциальных правил, которые могут быть получены.
http://en.wikipedia.org/wiki/Perceptron.
Minsky M, Papert S. Perceptrons: an introduction to computational geometry. Cambridge: MIT Press; 1969.
Sosulski DL, Bloom ML, Cutforth T, Axel R, Datta SR. Distinct representations of olfactory information in different cortical centres. Nature. 2011;472:213–6; Eliasmith C, Stewart TC, Choo X, Bekolay T, DeWolf T, Tang Y, Rasmussen D. A large-scale model of the functioning brain. Science. 2012;338:1202–5; Barak O, Rigotti M, Fusi S. The sparseness of mixed selectivity neurons controls the generalization–discrimination trade-off. J Neurosci. 2013;33(9):3844–56; Rigotti M, Barak O, Warden MR, Wang X-J, Daw ND, Miller EK, Fusi S. The importance of mixed selectivity in complex cognitive tasks. Nature. 2013;497:585–90.
Более того, другой вид случайности также может быть интегрирован в ELM. В этом случае входные слои для скрытых узлов могут быть полностью или частично случайным образом соединены в соответствии с различными непрерывными функциями распределения вероятностей.
Отличный ресурс по свойствам ELM можно найти здесь: https://bit.ly/2JoHhcg.
https://bit.ly/2PP3NQ0.
Другие незначительные различия между CNN и CapsNets существуют, но не столь существенны. См. Сноску 22 для ссылки на дополнительную литературу.
https://arxiv.org/abs/1710.09829.