Глава 3: Создание сети глубокого обучения с использованием MXNet
Мы начнем наше углубленное исследование фреймворков глубокого обучения с одного из самых многообещающих: Apache MXNet. Мы рассмотрим его основные компоненты, включая интерфейс Gluon, NDArrays и пакет MXNet в Python. Вы узнаете, как можно сохранять свою работу, например, сети, обученные на файлах данных, и другие полезные вещи, о которых следует помнить, работая с MXNet.
MXNet поддерживает различные языки программирования через свой API, большинство из которых полезны для науки о данных. Языки, такие как Python, Julia, Scala, R, Perl и C++, имеют свои обертки системы MXNet, что делает их легко интегрируемыми в ваш конвейер данных.
Кроме того, MXNet позволяет распараллеливать вычисления, что позволяет в полной мере использовать дополнительные аппаратные ресурсы вашей машины, такие как дополнительные процессоры (CPU) и графические процессоры (GPU). Это делает MXNet довольно быстрым, что важно при решении вычислительно сложных задач, подобных тем, которые встречаются в большинстве приложений глубокого обучения.
Интересно, что системы глубокого обучения, созданные в MXNet, могут быть развернуты на всех видах компьютерных платформ, включая умные устройства. Это возможно благодаря процессу, называемому амальгамацией, который переносит всю систему в один файл, который затем может быть выполнен как автономная программа. Амальгамация в MXNet была создана Джеком Денгом и включает разработку файлов .cc, единственной зависимостью которых является библиотека BLAS. Файлы такого типа, как правило, довольно большие (более 30000 строк). Также есть возможность компиляции файлов .h с использованием программы emscripten. Эта программа не зависит от какой-либо библиотеки и может использоваться другими языками программирования с соответствующим API.
Наконец, существует несколько руководств по MXNet, если вы хотите узнать больше о его различных функциях. Поскольку MXNet является проектом с открытым исходным кодом, вы даже можете создать свое собственное руководство, если захотите.
Более того, это кроссплатформенный инструмент, работающий на всех основных операционных системах. MXNet существует достаточно долго, чтобы стать темой многих исследований, включая известную научную статью Чена и др.7
Основные компоненты
Интерфейс Gluon
Gluon - это простой интерфейс для всей вашей работы с глубоким обучением с использованием MXNet. Вы устанавливаете его на свою машину точно так же, как любую библиотеку Python:
pip install mxnet --pre --user
Главное преимущество Gluon в том, что он прост. Он предлагает абстракцию всего процесса построения сети, что может быть пугающим для новичков в этой области. Кроме того, Gluon очень быстрый, не добавляя значительных накладных расходов при обучении вашей системы глубокого обучения. Более того, Gluon может обрабатывать динамические графы, предлагая некоторую гибкость в структуре создаваемых ANN. Наконец, Gluon имеет общую гибкую структуру, что делает процесс разработки для любой ANN менее жестким.
Естественно, для работы Gluon у вас должен быть установлен MXNet на вашей машине (хотя это не требуется, если вы используете контейнер Docker, поставляемый с этой книгой). Это достигается с помощью знакомой команды pip:
pip install mxnet --pre --user
Из-за его полезности и отличной интеграции с MXNet, мы будем использовать Gluon на протяжении всей этой главы, исследуя этот фреймворк глубокого обучения. Однако, чтобы лучше понять MXNet, мы сначала кратко рассмотрим, как вы можете использовать некоторые из его других функций (которые пригодятся для одного из примеров, которые мы рассмотрим позже).
NDArrays
NDArray — это особенно полезная структура данных, которая используется в проектах MXNet. NDArray по сути представляют собой массивы NumPy, но с добавленной возможностью асинхронной обработки на ЦП. Они также совместимы с распределенными облачными архитектурами и могут использовать автоматическое дифференцирование, что особенно полезно при обучении системы глубокого обучения, но NDArrays также можно эффективно использовать и в других приложениях машинного обучения. NDArrays являются частью пакета MXNet, который мы скоро рассмотрим. Вы можете импортировать модуль NDArrays следующим образом:
from mxnet import nd
Например, чтобы создать новый NDArray, состоящий из 4 строк и 5 столбцов, вы можете набрать следующее:
nd.empty((4, 5))
Результат будет отличаться каждый раз, когда вы его запускаете, поскольку фреймворк будет выделять любое значение, которое он найдет в тех частях памяти, которые он выделяет для этого массива. Если вы хотите, чтобы NDArray содержал только нули, введите:
nd.zeros((4, 5))
Чтобы узнать количество строк и столбцов переменной, которой присвоен NDArray, необходимо использовать функцию .shape, как в NumPy:
x = nd.empty((2, 7)) x.shape
Наконец, если вы хотите найти общее количество элементов в NDArray, используйте функцию .size:
x.size
Операции в NDArray точно такие же, как в NumPy, поэтому мы не будем здесь подробно останавливаться на них. Содержимое также доступно таким же образом, через индексирование и нарезку.
Если вы хотите преобразовать NDArray в более знакомую структуру данных из пакета NumPy, вы можете использовать функцию asnumpy():
y = x.asnumpy()
Обратное можно достичь с помощью функции array():
z = nd.array(y)
Одна из отличительных особенностей NDArrays заключается в том, что они могут присваивать разные вычислительные контексты разным массивам — либо на CPU, либо на GPU, подключенном к вашей машине (это называется «контекст» при обсуждении NDArrays). Это стало возможным благодаря параметру ctx во всех соответствующих функциях пакета. Например, при создании пустого массива нулей, который вы хотите присвоить первому GPU, просто введите:
a = nd.zeros(shape=(5,5), ctx=mx.gpu(0))
Конечно, данные, присвоенные конкретному вычислительному блоку, не закреплены навсегда. Легко скопировать данные в другое место, связанное с другим вычислительным блоком, используя функцию copyto():
y = x.copyto(mx.gpu(1)) # copy the data of NDArray x to the 2nd GPU
Вы можете узнать контекст переменной с помощью атрибута .context:
print(x.context)
Часто удобнее определить контекст как данных, так и моделей, используя для каждого отдельную переменную. Например, предположим, что ваш проект глубокого обучения использует данные, которые вы хотите обрабатывать на CPU, и модель, которую вы предпочитаете обрабатывать на первом GPU. В этом случае вы можете набрать что-то вроде:
DataCtx = mx.cpu() ModelCtx = mx.gpu(0)
Пакет MXNet в Python
Пакет MXNet (или «mxnet», с нижним регистром при наборе в Python) является очень надежной и самодостаточной библиотекой в Python. MXNet предоставляет возможности глубокого обучения через фреймворк MXNet.
Импорт этого пакета в Python довольно прост:
import mxnet as mx
Если вы хотите выполнить некоторые дополнительные процессы, которые сделают использование MXNet еще лучше, настоятельно рекомендуется сначала установить следующие пакеты на свой компьютер:
- graphviz (версия 0.8.1 или новее)
- requests (версия 2.18.4 или новее)
- numpy (версия 1.13.3 или новее)
Вы можете узнать больше о пакете MXNet через соответствующий репозиторий на GitHub.8
MXNet в действии
Теперь давайте посмотрим, что мы можем сделать с MXNet, используя Python, на образе Docker со всем необходимым программным обеспечением, уже установленным. Мы начнем с краткого описания наборов данных, которые будем использовать, а затем перейдем к паре конкретных приложений глубокого обучения, использующих эти данные (а именно классификация и регрессия). Освоив их, вы сможете самостоятельно изучить более продвинутые системы глубокого обучения этого фреймворка.
Описание наборов данных
В этом разделе мы представим два синтетических набора данных, которые мы подготовили для демонстрации методов классификации и регрессии на них. Первый набор данных предназначен для классификации, а второй - для регрессии. Причина, по которой мы используем синтетические наборы данных в этих упражнениях, заключается в максимальном понимании данных, чтобы мы могли оценивать результаты систем глубокого обучения независимо от качества данных.
Первый набор данных содержит 4 переменные: 3 признака и 1 переменная-метка. С 250 000 точек данных он достаточно велик для работы сети глубокого обучения.
с ним. Его небольшая размерность делает его идеальным для визуализации (см.Рисунок 2). Он также сделан так, чтобы иметь большую степень нелинейности, что делает его хорошей задачей для любой модели данных (хотя и не слишком сложной для системы глубокого обучения). Кроме того, классы 2 и 3 этого набора данных достаточно близки, чтобы вызывать путаницу, но при этом различаются. Это делает их хорошим вариантом для применения кластеризации, как мы увидим позже.
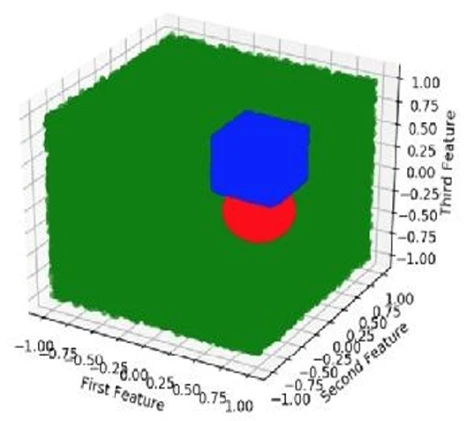
Рисунок 2: Графическое изображение первого набора данных, использованного в этих примерах. Различные цвета соответствуют разным классам набора данных. Хотя три класса четко выделяются, определение, к какому из них принадлежит неизвестная точка данных, является нелинейным. Это связано с наличием сферического класса, что делает всю проблему достаточно сложной, чтобы сделать подход глубокого обучения актуальным.
Второй набор данных несколько больше, содержащий 21 переменную — 20 из которых являются признаками, используемыми для предсказания последней, которая является целевой переменной. С 250 000 точек данных он снова идеально подходит для системы глубокого обучения. Обратите внимание, что только 10 из 20 признаков релевантны целевой переменной (которая является комбинацией этих 10). К данным добавлен небольшой шум, чтобы сделать
всю проблему немного более сложной. Оставшиеся 10 признаков — это просто случайные данные, которые должны быть отфильтрованы моделью глубокого обучения. Релевантны они или нет, этот набор данных имеет достаточно признаков, чтобы сделать применение уменьшения размерности целесообразным. Естественно, из-за его размерности мы не можем построить график этого набора данных.
Загрузка набора данных в NDArray
Теперь давайте посмотрим, как мы можем загрузить набор данных в MXNet, чтобы затем обработать его с помощью модели глубокого обучения. Сначала давайте установим некоторые параметры:
DataCtx = mx.cpu() # assign context of the data used BatchSize = 64 # batch parameter for dataloader object r = 0.8 # ratio of training data nf = 3 # number of features in the dataset (for the classification problem)
Теперь мы можем импортировать данные так, как мы обычно делаем в традиционном DS-проекте, но на этот раз сохранить их в NDArrays вместо массивов Pandas или NumPy:
with open("../data/data1.csv") as f:
data_raw = f.read()
lines = data_raw.splitlines() # split the data
into separate lines
ndp = len(lines) # number of data points
X = nd.zeros((ndp, nf), ctx=data_ctx)
Y = nd.zeros((ndp, 1), ctx=data_ctx)
for i, line in enumerate(lines):
tokens = line.split()
Y[i] = int(tokens[0])
for token in tokens[1:]:
index = int(token[:-2]) - 1
X[i, index] = 1
Теперь мы можем разделить данные на обучающий и тестовый наборы, чтобы использовать их как для построения, так и для проверки нашей модели классификации:
import numpy as np # we’ll be needing this package as well n = np.round(N * r) # number of training data points train = data[:n, ] # training set partition test = data[(n + 1):,] # testing set partition data_train = gluon.data.DataLoader(gluon.data.ArrayDataset(tra in[:,:3], train[:,3]), batch_size=BatchSize, shuffle=True) data_test = gluon.data.DataLoader(gluon.data.ArrayDataset(tes t[:,:3], test[:,3]), batch_size=BatchSize, shuffle=True)
Затем нам потребуется повторить тот же процесс для загрузки второго набора данных — на этот раз используя data2.csv в качестве исходного файла. Также, чтобы избежать путаницы с объектами загрузчиков данных первого набора данных, вы можете назвать новые загрузчики данных data_train2 и data_test2, соответственно.
Классификация
Теперь давайте исследуем, как мы можем использовать эти данные для построения системы MLP, способной различать различные классы внутри подготовленных данных. Для начала, давайте посмотрим, как это сделать, используя сам пакет mxnet; затем мы рассмотрим, как то же самое можно достичь с помощью Gluon.
Сначала определим некоторые константы, которые будем использовать позже для построения, обучения и тестирования сети MLP:
nhn = 256 # number of hidden nodes for each layer WeightScale = 0.01 # scale multiplier for weights ModelCtx = mx.cpu() # assign context of the model itself no = 3 # number of outputs (classes) ne = 10 # number of epochs (for training)
Далее инициализируем параметры сети (веса и смещения) для первого слоя:
lr = 0.001 # learning rate (for training) sc = 0.01 # smoothing constant (for training) ns = test.shape[0] # number of samples (for testing)
W1 = nd.random_normal(shape=(nf, nhn), scale=WeightScale, ctx=ModelCtx) b1 = nd.random_normal(shape=nhn, scale=WeightScale, ctx=ModelCtx)
И сделаем то же самое для второго слоя:
W2 = nd.random_normal(shape=(nhn, nhn), scale=WeightScale, ctx=ModelCtx) b2 = nd.random_normal(shape=nhn, scale=WeightScale, ctx=ModelCtx)
Затем инициализируем выходной слой и объединим все параметры в единую структуру данных под названием params:
W3 = nd.random_normal(shape=(nhn, no), scale=WeightScale, ctx=ModelCtx) b3 = nd.random_normal(shape=no, scale=WeightScale, ctx=ModelCtx) params = [W1, b1, W2, b2, W3, b3]
Наконец, выделим немного места для градиента для каждого из этих параметров:
for param in params: param.attach_grad()
Помните, что без нелинейных функций в нейронах MLP вся система была бы слишком рудиментарной, чтобы быть полезной. Мы будем использовать функции ReLU и Softmax в качестве функций активации для нашей
system: def relu(X): return nd.maximum(X, nd.zeros_like(X)) def softmax(y_linear): exp = nd.exp(y_linear - nd.max(y_linear)) partition = nd.nansum(exp, axis=0, exclude=True).reshape((-1, 1)) return exp / partition
Обратите внимание, что функция Softmax будет использоваться в выходных нейронах, в то время как функция ReLU будет использоваться во всех остальных нейронах сети.
В качестве функции стоимости сети (или, другими словами, функции приспособленности метода оптимизации, лежащего в основе), мы будем использовать функцию кросс-энтропии:
def cross_entropy(yhat, y): return - nd.nansum(y * nd.log(yhat), axis=0, exclude=True)
Чтобы сделать всю систему более эффективной, мы можем объединить функции softmax и кросс-энтропии в одну, следующим образом:
def softmax_cross_entropy(yhat_linear, y): return - nd.nansum(y * nd.log_softmax(yhat_linear), axis=0, exclude=True)
После всего этого мы теперь можем определить функцию всей нейронной сети, основанную на вышеуказанной архитектуре:
def net(X): h1_linear = nd.dot(X, W1) + b1 h1 = relu(h1_linear) h2_linear = nd.dot(h1, W2) + b2 h2 = relu(h2_linear) yhat_linear = nd.dot(h2, W3) + b3 return yhat_linear
Метод оптимизации для обучения системы также должен быть определен. В данном случае мы будем использовать форму градиентного спуска:
def SGD(params, lr): for param in params: param[:] = param - lr * param.grad return param
Для целей этого примера мы будем использовать простую метрику оценки для модели: точность. Конечно, это необходимо определить сначала:
def evaluate_accuracy(data_iterator, net): numerator = 0. denominator = 0. for i, (data, label) in enumerate(data_iterator): data = data.as_in_context(model_ctx).reshape((-1, 784)) label = label.as_in_context(model_ctx) output = net(data) predictions = nd.argmax(output, axis=1) numerator += nd.sum(predictions == label) denominator += data.shape[0] return (numerator / denominator).asscalar()
Теперь мы можем обучить систему следующим образом:
Now we can train the system as follows: for e in range(epochs): cumulative_loss = 0 for i, (data, label) in enumerate(train_data): data = data.as_in_context(model_ctx).reshape((-1, 784)) label = label.as_in_context(model_ctx) label_one_hot = nd.one_hot(label, 10) with autograd.record(): output = net(data)
loss = softmax_cross_entropy(output,
label_one_hot)
loss.backward()
SGD(params, learning_rate)
cumulative_loss +=
nd.sum(loss).asscalar()
test_accuracy = evaluate_accuracy(test_data,
net)
train_accuracy =
evaluate_accuracy(train_data, net)
print("Epoch %s. Loss: %s, Train_acc %s,
Test_acc %s" %
(e, cumulative_loss/num_examples,
train_accuracy, test_accuracy))
Наконец, мы можем использовать систему для получения некоторых предсказаний, используя следующий код:
def model_predict(net, data):
output = net(data)
return nd.argmax(output, axis=1)
SampleData = mx.gluon.data.DataLoader(data_test,
ns, shuffle=True)
for i, (data, label) in enumerate(SampleData):
data = data.as_in_context(ModelCtx)
im = nd.transpose(data,(1,0,2,3))
im = nd.reshape(im,(28,10*28,1))
imtiles = nd.tile(im, (1,1,3))
plt.imshow(imtiles.asnumpy())
plt.show()
pred=model_predict(net,data.reshape((-1,784)))
print('model predictions are:', pred)
print('true labels :', label)
break
Если вы запустите приведенный выше код (желательно в среде Docker), вы увидите, что эта простая система MLP хорошо справляется с
предсказанием классов некоторых неизвестных точек данных — даже если границы классов сильно нелинейны. Экспериментируйте с этой системой больше и посмотрите, как можно еще больше улучшить ее производительность, используя фреймворк MXNet.
Теперь мы увидим, как значительно упростить всё это, используя интерфейс Gluon. Сначала давайте определим класс Python для охвата некоторых распространенных случаев многослойных перцептронов, преобразуя объект "gluon.Block" в нечто, что можно использовать для постепенного построения нейронной сети, состоящей из нескольких слоев (также известных как MLP):
class MLP(gluon.Block): def __init__(self, **kwargs): super(MLP, self).__init__(**kwargs) with self.name_scope(): self.dense0 = gluon.nn.Dense(64) # architecture of 1st layer (hidden) self.dense1 = gluon.nn.Dense(64) # architecture of 2nd layer (hidden) self.dense2 = gluon.nn.Dense(3) # architecture of 3rd layer (output) def forward(self, x): # a function enabling an MLP to process data (x) by passing it forward (towards the output layer) x = nd.relu(self.dense0(x)) # outputs of first hidden layer x = nd.relu(self.dense1(x)) # outputs of second hidden layer x = self.dense2(x) # outputs of final layer (output) return x
Конечно, это всего лишь пример того, как вы можете определить MLP с использованием Gluon, а не универсальное решение. Возможно, вы захотите определить класс MLP по-другому, поскольку используемая архитектура повлияет на производительность системы. (Это особенно верно для сложных задач, где дополнительные скрытые слои были бы полезны.) Однако, если то, что следует далее, кажется вам слишком сложным, и у вас нет времени,
усвоить теорию систем глубокого обучения, рассмотренную в Главе 1, вы можете использовать объект MLP, подобный описанному выше, для своего проекта.
Поскольку системы глубокого обучения редко бывают такими компактными, как описанный выше MLP, и поскольку нам часто необходимо добавлять больше слоев (что было бы громоздким при использовании вышеупомянутого подхода), обычно используется другой класс под названием Sequential. После того как мы определим количество нейронов в каждом скрытом слое и укажем функцию активации для этих нейронов, мы можем построить MLP, подобно лестнице, где каждый шаг представляет собой один слой в MLP:
nhn = 64 # number of hidden neurons (in each layer) af = “relu” # activation function to be used in each neuron net = gluon.nn.Sequential() with net.name_scope(): net.add(gluon.nn.Dense(nhn , activation=af)) net.add(gluon.nn.Dense(nhn , activation=af)) net.add(gluon.nn.Dense(no))
Это заботится об архитектуре за нас. Чтобы сделать вышеуказанную сеть функциональной, нам сначала нужно ее инициализировать:
sigma = 0.1 # sigma value for distribution of
weights for the ANN connections
ModelCtx = mx.cpu()
lr = 0.01 # learning rate
oa = ‘sgd’ # optimization algorithm
net.collect_params().initialize(mx.init.Normal(si
gma=sigma), ctx=ModelCtx)
softmax_cross_entropy =
gluon.loss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), oa,
{‘learning_rate’: lr})
ne = 10 # number of epochs for training
Далее необходимо определить, как мы будем оценивать прогресс сети, с помощью функции оценки. Для простоты будем использовать стандартную метрику точности:
def AccuracyEvaluation(iterator, net): acc = mx.metric.Accuracy() for i, (data, label) in enumerate(iterator): data = data.as_in_context(ModelCtx).reshape((-1, 3)) label = label.as_in_context(ModelCtx) output = net(data) predictions = nd.argmax(output, axis=1) acc.update(preds=predictions, labels=label) return acc.get()[1]
Наконец, пришло время обучить и протестировать MLP, используя вышеупомянутые настройки:
for e in range(ne):
cumulative_loss = 0
for i, (data, label) in
enumerate(train_data):
data =
data.as_in_context(ModelCtx).reshape((-1, 784))
label = label.as_in_context(ModelCtx)
with autograd.record():
output = net(data)
loss = softmax_cross_entropy(output,
label)
loss.backward()
trainer.step(data.shape[0])
cumulative_loss +=
nd.sum(loss).asscalar()
train_accuracy =
AccuracyEvaluation(train_data, net)
test_accuracy = AccuracyEvaluation(test_data,
net)
print("Epoch %s. Loss: %s, Train_acc %s,
Test_acc %s" %
(e, cumulative_loss/ns, train_accuracy,
test_accuracy))
Запуск приведенного выше кода должен дать результаты, аналогичные результатам стандартных команд mxnet.
Чтобы упростить задачу, мы будем полагаться на интерфейс Gluon в следующем примере. Тем не менее, мы по-прежнему рекомендуем поэкспериментировать со стандартными функциями mxnet впоследствии, если вы хотите разработать свои собственные архитектуры (или лучше понять теорию глубокого обучения).
Регрессия
Создание системы регрессии MLP похоже на создание системы классификации, но с некоторыми различиями. В случае регрессии регрессия будет проще, поскольку регрессоры обычно архитектурно легче, чем классификаторы. Для этого примера мы будем использовать второй набор данных.
Сначала импортируем необходимые классы из пакета mxnet и установим контекст для модели:
import mxnet as mx from mxnet import nd, autograd, gluon ModelCtx = mx.cpu()
Для загрузки данных в модель мы будем использовать загрузчики данных, созданные ранее (data_train2 и data_test2). Теперь определим некоторые базовые настройки и постепенно построим сеть глубокого обучения:
nf = 20 # we have 20 features in this dataset sigma = 1.0 # sigma value for distribution of weights for the ANN connections net = gluon.nn.Dense(1, in_units=nf) # the “1” here is the number of output neurons, which is 1 in regression
Теперь инициализируем сеть случайными значениями для весов и смещений:
net.collect_params().initialize(mx.init.Normal(si gma=sigma), ctx=ModelCtx)
Как и в любой другой системе глубокого обучения, нам необходимо определить функцию потерь. Используя эту функцию, система понимает, насколько стоит каждая ошибка от значений целевой переменной. В то же время, функции потерь также могут учитывать сложность моделей (поскольку если модели слишком сложны, они могут привести к переобучению):
square_loss = gluon.loss.L2Loss()
Теперь пришло время обучить сеть, используя имеющиеся данные. После определения некоторых важных параметров (как и в случае классификации), мы можем создать цикл для обучения сети:
ne = 10 # number of epochs for training
loss_sequence = [] # cumulative loss for the
various epochs
nb = ns / BatchSize # number of batches
for e in range(ne):
cumulative_loss = 0
for i, (data, label) in
enumerate(train_data): # inner loop
data = data.as_in_context(ModelCtx)
label = label.as_in_context(ModelCtx)
with autograd.record():
output = net(data)
loss = square_loss(output, label)
loss.backward()
trainer.step(BatchSize)
CumulativeLoss +=
nd.mean(loss).asscalar()
print("Epoch %s, loss: %s" % (e,
CumulativeLoss / ns))
loss_sequence.append(CumulativeLoss)
Если вы хотите просмотреть параметры модели, вы можете сделать это, собрав их в структуру словаря:
params = net.collect_params()
for param in params.values(): print(param.name, param.data())
Вывод параметров может показаться не слишком полезным, так как их обычно слишком много, и особенно когда мы добавляем новые слои в систему, что мы делаем следующим образом:
net.add(gluon.nn.Dense(nhn))
где nhn — количество нейронов в этом дополнительном скрытом слое. Обратите внимание, что сеть требует выходного слоя с одним нейроном, поэтому обязательно добавляйте любые дополнительные слои между входным и выходным слоями.
Создание контрольных точек для моделей, разработанных в MXNet
Поскольку обучение системы может занять некоторое время, возможность сохранения и загрузки моделей и данных глубокого обучения с помощью этого фреймворка является критически важной. Мы должны создать «контрольные точки» в нашей работе, чтобы мы могли продолжить с того места, где остановились, не создавая сеть с нуля каждый раз. Это достигается следующим процессом.
Сначала импортируйте все необходимые пакеты и классы, а затем определите параметр контекста:
import mxnet as mx from mxnet import nd, autograd, gluon import os ctx = mx.cpu() # context for NDArrays
Затем мы сохраним данные, но сначала поместим их в словарь:
dict = {"X": X, "Y": Y}
Теперь установим имя файла и сохраним его:
filename = "test.dat" nd.save(filename, dict)
Мы можем убедиться, что всё сохранено правильно, загрузив контрольную точку следующим образом:
Z = nd.load(filename) print(Z)
При использовании gluon существует ярлык для сохранения всех параметров разработанной нами сети глубокого обучения. Это функция save_params():
filename = "MyNet.params" net.save_params(filename)
Однако, чтобы восстановить сеть глубокого обучения, вам потребуется воссоздать исходную архитектуру сети, а затем загрузить параметры исходной сети из соответствующего файла:
net2 = gluon.nn.Sequential()with net2.name_scope(): net2.add(gluon.nn.Dense(num_hidden, activation=”relu”)) net2.add(gluon.nn.Dense(num_hidden, activation=”relu”)) net2.add(gluon.nn.Dense(num_outputs)) net2.load_params(filename, ctx=ctx)
Лучше всего сохранять свою работу в различных частях конвейера и давать файлам контрольных точек описательные имена. Важно также помнить, что у нас нет опции «отмены обучения» и, вероятно, оптимальная производительность достигается до завершения фазы обучения. Из-за этого мы можем захотеть создавать контрольные точки после каждой эпохи обучения, чтобы мы могли вернуться к ней, когда обнаружим, в какой момент достигается оптимальная производительность.
Более того, чтобы компьютер мог правильно интерпретировать эти файлы при загрузке их в вашу среду программирования, вам потребуется класс nd из mxnet в памяти, независимо от того, какой язык программирования вы используете.
Советы по MXNet
Фреймворк MXNet — это очень надежная и универсальная платформа для различных систем глубокого обучения. Хотя мы продемонстрировали его функциональность в Python, он одинаково мощен при использовании с другими языками программирования.
Кроме того, интерфейс Gluon — полезное дополнение. Если вы новичок в приложениях глубокого обучения, мы рекомендуем использовать Gluon как основной инструмент при работе с фреймворком MXNet. Это не означает, что сам фреймворк ограничен Gluon, поскольку пакет mxnet универсален и надежен на различных платформах программирования.
Более того, в этой главе мы рассмотрели только основы MXNet и Gluon. Изучение всех деталей этих надежных систем заняло бы целую книгу! Узнайте больше о деталях интерфейса Gluon в руководстве Straight Dope, которое является частью документации MXNet.9
Наконец, примеры в этой главе выполняются в контейнере Docker; поэтому вы можете испытывать некоторую задержку. При разработке системы глубокого обучения на компьютерном кластере, конечно, это происходит значительно быстрее.
Резюме
- MXNet - это фреймворк глубокого обучения, разработанный Apache. Он демонстрирует простоту использования, гибкость и высокую скорость, среди прочих преимуществ. Всё это делает MXNet привлекательным вариантом для глубокого обучения на различных языках программирования, включая Python, Julia, Scala и R.
- Модели MXNet могут быть развернуты на всех типах вычислительных систем, включая интеллектуальные устройства. Это достигается экспортом их в виде единого файла, который затем выполняется этими устройствами.
- Gluon — это пакет, предоставляющий простой интерфейс для всей вашей работы с глубоким обучением с использованием MXNet. Его основные преимущества включают простоту использования, отсутствие значительных накладных расходов, возможность обрабатывать динамические графы для ваших моделей ANN и гибкость.
- NDArrays являются полезными структурами данных при работе с фреймворком MXNet. Их можно импортировать в виде модулей из
- пакета mxnet как nd. Они похожи на массивы NumPy, но более универсальны и эффективны при работе с приложениями глубокого обучения.
- Пакет mxnet является API Python для фреймворка MXNet и содержит множество модулей для построения и использования систем глубокого обучения.
- Данные могут быть загружены в MXNet через NDArray, непосредственно из файла данных; а затем создать объект dataloader для подачи данных в модель, построенную впоследствии.
- Классификация в MXNet включает создание MLP (или другой сети глубокого обучения), его обучение и использование для предсказания неизвестных данных, выделяя по одному нейрону для каждого класса в наборе данных. Классификация значительно проще при использовании Gluon.
- Регрессия в MXNet похожа на классификацию, но выходной слой имеет один нейрон. Также необходимо принимать дополнительные меры, чтобы система не переобучалась; поэтому мы часто используем некоторую функцию регуляризации, например L2.
- Создание контрольных точек проекта в MXNet включает сохранение модели и любых других соответствующих данных в NDArrays, чтобы вы могли получить их в другое время. Это также полезно для обмена работой с другими для целей обзора.
- Помните, что MXNet, как правило, быстрее, чем на контейнере Docker, используемом в примерах этой главы, и что он одинаково полезен и надежен на других языках программирования.
https://bit.ly/2uweNb0.
https://github.com/apache/incubator-mxnet.
http://gluon.mxnet.io/index.html.