Глава 4: Построение сети глубокого обучения с использованием TensorFlow
В этой главе представлено введение в самый популярный программный фреймворк в сообществе глубокого обучения: TensorFlow. Разработанный и поддерживаемый Google, TensorFlow был адаптирован и развит огромным сообществом открытого исходного кода. Поэтому для практиков глубокого обучения важно освоить хотя бы основы. Фактически, большая часть кода, который вы можете найти в Интернете, написана на TensorFlow.
Мы рассмотрим составляющие основной библиотеки TensorFlow, а также некоторые высокоуровневые API, доступные в экосистеме Python. Наше обсуждение в этой главе должно помочь вам понять базовые структуры фреймворка, позволяя создавать собственные модели глубокого обучения с использованием TensorFlow. Хотя мы рекомендуем использовать Keras (который мы рассмотрим в следующей главе), если вы новичок в глубоком обучении, изучение основ TensorFlow очень полезно, так как Keras также построен поверх TensorFlow.10
TensorFlow доступен как для Python 2, так и для Python 3. Поскольку в этой книге мы используем Python 3, мы кратко расскажем, как установить TensorFlow на ваш локальный компьютер. Однако, если вы используете предоставленный файл Docker, TensorFlow уже установлен для вас.
Перед установкой TensorFlow важно обратить внимание на вычислительные блоки на вашей машине, которые могут использоваться TensorFlow. У вас есть два варианта для запуска кода TensorFlow: вы можете использовать CPU или GPU. Поскольку GPU предназначены для более быстрого выполнения операций линейной матрицы, чем CPU, специалисты по данным предпочитают использовать GPU, когда они доступны. Однако код TensorFlow, который вы пишете, будет одинаковым (за исключением указания предпочтения в отношении используемых вычислительных блоков).
Давайте начнем с установки TensorFlow. При этом мы используем
используем менеджер пакетов Python pip. Итак, если Python 3 — единственная установленная версия Python на вашей машине, то команда:
pip install –upgrade tensorflow
установит Tensorflow для Python 3. Однако, если на вашем компьютере установлены и Python 2, и Python 3, то команда выше может установить TensorFlow для Python 2. В этом случае вы также можете использовать следующую команду для установки TensorFlow для Python 3:
pip3 install –upgrade tensorflow
Фреймворк TensorFlow теперь установлен для вашего изучения. В вашем коде импортируйте TensorFlow, чтобы использовать его:
import tensorflow
Если хотите, можете переименовать его в "tf". Мы будем делать это на протяжении всей главы, так как это принято в сообществе:
import tensorflow as tf
Архитектура TensorFlow
Базовая архитектура TensorFlow показана на
Рисунке 3
. TensorFlow по своей природе разработан как распределенная система, поэтому очень легко запускать модели TensorFlow в распределенных средах. Движок распределенного выполнения TensorFlow отвечает за обработку этой возможности TensorFlow. Как мы уже упоминали, модели TensorFlow могут работать поверх CPU и GPU. Однако доступны и другие вычислительные блоки. Недавно Google объявил о процессорах обработки тензоров (TPU), разработанных для быстрого запуска моделей TensorFlow. Вы можете даже запускать TensorFlow непосредственно на устройствах Android.
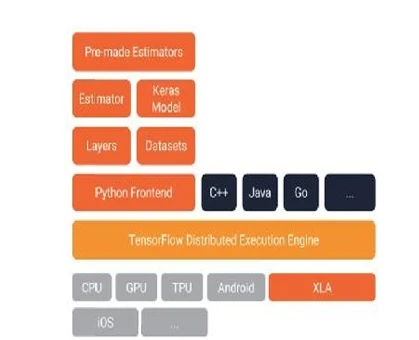
Рисунок 3: Архитектура TensorFlow. Движок распределенного выполнения TensorFlow позволяет TensorFlow работать в распределенной среде. Несколько интерфейсов включают Python, Java и Go. Модуль Layers включает различные типы модулей нейронных сетей, включая сверточный слой. Модуль Datasets включает утилиты для работы с внешними данными. Estimator и Keras - это высокоуровневые API поверх TensorFlow, которые упрощают кодирование. TensorFlow также поставляется с некоторыми предварительно построенными моделями. TensorFlow может работать на CPU, GPU, TPU и устройствах Android. Источник: https://bit.ly/2IwayBN.
Хотя Python является наиболее часто используемым языком с TensorFlow, вы можете использовать TensorFlow с C++, Java, Julia, Go, R и другими. TensorFlow включает два относительно высокоуровневых абстрактных модуля, называемых слоями и наборами данных. Модуль Layers предоставляет методы, которые упрощают создание полносвязных слоев, сверточных слоев, пулинговых слоев и многого другого. Он также предоставляет методы, такие как добавление функций активации или применение регуляризации dropout. Модуль Datasets включает возможности для управления вашими наборами данных.
Высокоуровневые API (такие как Keras или Estimators) проще использовать, и они
предоставляют ту же функциональность, что и эти низкоуровневые модули. Наконец, следует отметить, что TensorFlow включает в себя некоторые предварительно обученные модели из коробки.
Основные компоненты
Чтобы понять основную архитектуру фреймворка TensorFlow, мы введем несколько базовых понятий. Во-первых, начнем с фундаментального принципа проектирования TensorFlow: TensorFlow разработан для работы со «статическими графами». Вычислительный поток вашей модели будет преобразован в графическое представление в фреймворке перед выполнением. Статический граф в TensorFlow — это вычислительный граф, а не данные. Это означает, что перед запуском кода вы должны определить вычислительный поток ваших данных. После этого все данные, подаваемые в систему, будут проходить через этот вычислительный граф, даже если данные меняются время от времени.
Начнем с базовых понятий фреймворка. Первое понятие, которое необходимо понять, — это «тензор», который также включен в название фреймворка. Тензоры — это единицы, содержащие данные. Тензоры можно представить как n-мерные массивы NumPy. Ранг тензора определяет размерность, а форма определяет длины каждой размерности в виде кортежа. Так
[ [1.0, 2.0, 3.0], [4.0, 5.0, 6.0] ]
— это тензор ранга 2 и формы (2,3).
Еще одним важным понятием TensorFlow является «направленный граф», который содержит операции и тензоры. В этом графе операции представлены узлами; тензоры представлены ребрами. Операции принимают тензоры в качестве входных данных и производят тензоры в качестве выходных. Рассмотрим простой пример:
# first, we have to import tensorflow import tensorflow as tf # constants are the most basic type of operations x = tf.constant(1.0, dtype = tf.float32) y = tf.constant(2.0, dtype = tf.float32) z = x + y
В приведенном выше коде мы определяем два тензора x и y с помощью операции tf.constant. Эта операция принимает 1.0 и 2.0 в качестве входных данных и просто производит их эквиваленты тензоров и ничего более. Затем, используя x и y, мы создали еще один тензор под названием z. Теперь, что вы ожидаете увидеть из приведенного ниже кода?
print(z)
Вы ошибаетесь, если ожидаете увидеть 3.0. Вместо этого вы увидите:
Tensor(“add:0”, shape=(), dtype=float32)
Определение графов отличается от выполнения операторов. На данный момент z — это просто объект тензора и не имеет связанного с ним значения. Нам как-то нужно запустить граф, чтобы получить 3.0 из тензора z. Здесь появляется другое понятие в TensorFlow: сессия.
Сессии в TensorFlow — это объекты, которые содержат состояние времени выполнения, где будет выполняться наш граф. Нам необходимо создать экземпляр сессии, а затем запустить операции, которые мы уже определили:
sess = tf.Session()
Код выше создает экземпляр объекта сессии. Теперь, используя этот объект, мы можем запустить наши операции:
print(sess.run(z))
и мы получим 3.0 из оператора print! Когда мы запускаем операцию (а именно узел в графе), TensorFlow выполняет ее, вычисляя тензоры, которые наша операция принимает в качестве входных данных. Это включает обратное вычисление узлов и тензоров, пока оно не достигнет естественной начальной точки – точно так же, как в наших операциях tf.constant выше.
Как вы уже заметили, tf.constant просто предоставляет константы в качестве операции; это может быть не подходящим для работы с внешними данными. Для таких ситуаций TensorFlow предоставляет другой объект под названием placeholder. Вы можете представлять себе плейсхолдеры как аргументы функции. Это то, что вы предоставите позже в своем коде! Например:
k = tf.placeholder(tf.float32) l = tf.placeholder(tf.float32) m = k + l
На этот раз мы определяем k и l как плейсхолдеры; мы присвоим им некоторые значения при запуске в сессии. Используя приведенную выше сессию:
print(sess.run(m, feed_dict={k = 1.0, l = 2.0}))
выведет 3.0. Здесь мы использовали объект feed_dict, который является словарем, используемым для передачи значений в плейсхолдеры. Фактически, мы передаем 1.0 и 2.0 в плейсхолдеры k и l, соответственно, во время выполнения. Вы также можете использовать параметр feed_dict метода run сессии для обновления значений tf.constants.
Мы видели, что константы и плейсхолдеры являются полезными конструкциями TensorFlow для хранения значений. Другой полезной конструкцией является переменная TensorFlow. Переменную можно представлять как нечто, что находится между константами и плейсхолдерами. Как и плейсхолдеры, переменные не имеют присвоенного значения. Однако, подобно константам, они могут иметь значения по умолчанию. Вот пример переменной TensorFlow:
v= tf.Variable([0], tf.float32)
В приведенной выше строке мы определяем переменную TensorFlow под названием v и устанавливаем ее значение по умолчанию равным 0. Когда мы хотим присвоить какое-либо значение, отличное от значения по умолчанию, мы можем использовать метод tf.assign:
w= tf.assign(v, [-1.])
Важно знать, что переменные TensorFlow не инициализируются при их определении. Вместо этого нам нужно инициализировать их в сессии следующим образом:
init = tf.global_variables_initializer() sess.run(init)
Приведенный выше код инициализирует все переменные! Как правило, для определения констант следует использовать tf.constant, для хранения данных, подаваемых в модель, — tf.placeholder, а для представления параметров модели — tf.Variable.
Теперь, когда мы изучили основные концепции TensorFlow и продемонстрировали, как их использовать, вы готовы использовать TensorFlow для построения собственных моделей.
TensorFlow в действии
Мы начнем наши упражнения с TensorFlow, реализовав модель классификации глубокого обучения, используя элементы TensorFlow, которые мы рассмотрели в предыдущем разделе. Наборы данных, которые мы используем для демонстрации TensorFlow, — это те же самые синтетические наборы данных, которые мы использовали в предыдущем разделе. Мы используем их для целей классификации и регрессии в этой главе. Помните, что эти наборы данных, а также коды, которые мы рассмотрим в этом разделе, уже предоставлены в образе Docker, распространяемом с этой книгой. Вы можете запустить этот образ Docker, чтобы получить доступ к наборам данных и исходным кодам этой главы.
Классификация
Прежде чем приступить к реализации нашего классификатора, нам необходимо импортировать некоторые библиотеки, чтобы использовать их. Вот библиотеки, которые нам необходимо импортировать:
import numpy as np import pandas as pd import tensorflow as tf from sklearn.model_selection import train_test_split
Сначала нам следует загрузить набор данных и немного предварительно обработать его, чтобы отформатировать данные, которые мы будем использовать в нашей модели. Как обычно, мы загружаем данные в виде списка:
# import the data
with open("../data/data1.csv") as f:
data_raw = f.read()
# split the data into separate lines
lines = data_raw.splitlines()
Затем мы разделяем метки и три признака на списки под названиями "labels" и "features":
labels = []
features = []
for line in lines:
tokens = line.split(',')
labels.append(int(tokens[-1]))
x1,x2,x3 = float(tokens[0]),
float(tokens[1]), float(tokens[2])
features.append([x1, x2, x3])
Затем мы создаем фиктивные переменные для трех категорий меток, используя функцию Pandas get_dummies:
labels = pd.get_dummies(pd.Series(labels))
После этого список меток должен выглядеть так:
Figure 4
Следующий шаг — разделить наши данные на обучающий и тестовый наборы. Для этого мы используем функцию train_test_split из scikit-learn, которую импортировали ранее:
X_train, X_test, y_train, y_test = train_test_split(features, \ labels, test_size=0.2, random_state=42)
Теперь мы готовы построить нашу модель с помощью TensorFlow. Сначала мы определим гиперпараметры модели, связанные с процессом оптимизации:
# Parameters
learning_rate = 0.1 epoch = 10
Далее определяем гиперпараметры, связанные со структурой модели:
# Network Parameters n_hidden_1 = 16 # 1st layer number of neurons n_hidden_2 = 16 # 2nd layer number of neurons num_input = 3 # data input num_classes = 3 # total classes
Затем нам нужны плейсхолдеры для хранения наших данных:
# tf Graph input
X = tf.placeholder("float", [None, num_input])
Y = tf.placeholder("float", [None, num_classes])
Параметры модели будем хранить в двух словарях:
# weights and biases
weights = {
'h1': tf.Variable(tf.random_normal([num_input,n_h
idden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1,n_
hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2,
\
num_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1]))
,
‘b2’: tf.Variable(tf.random_normal([n_hidden_2])) , ‘out’: tf.Variable(tf.random_normal([num_classes] )) }
Теперь мы можем определить наш граф в TensorFlow. Для этого мы предоставляем функцию:
# Create model def neural_net(x): # Hidden fully connected layer with 16 neurons layer_1 = tf.nn.relu(tf.add(tf.matmul(x, weights[‘h1’]), \ biases[‘b1’])) # Hidden fully connected layer with 16 neurons layer_2 = tf.nn.relu(tf.add(tf.matmul(layer_1, \ weights[‘h2’]), biases[‘b2’])) # Output fully connected layer with a neuron for each class out_layer = tf.add(tf.matmul(layer_2, weights[‘out’]), \ biases[‘out’]) # For visualization in TensorBoard tf.summary.histogram(‘output_layer’, out_laye r) return out_layer
Эта функция принимает входные данные в качестве аргумента. Используя эти данные, она сначала строит скрытый слой. В этом слое каждая точка входных данных умножается на веса первого слоя и добавляется к членам смещения. Используя выходные данные этого слоя, функция строит еще один скрытый слой. Аналогично, этот второй слой умножает выходные данные первого слоя на свои собственные веса и добавляет результат к члену смещения. Затем выходные данные второго слоя подаются в последний слой, который является выходным слоем нейронной
сети. Выходной слой делает то же самое, что и предыдущие слои. В результате функция, которую мы определяем, просто возвращает выходные данные последнего слоя.
После этого мы можем определить нашу функцию потерь, алгоритм оптимизации и метрику, которую мы будем использовать для оценки нашей модели:
# Construct model
logits = neural_net(X)
# Define loss and optimizer
loss_op = tf.losses.softmax_cross_entropy(logits=
logits, \
onehot_labels=Y)
# For visualization in TensorBoard
tf.summary.scalar(‘loss_value’, loss_op)
optimizer
= tf.train.AdamOptimizer(learning_rate=learning_r
ate)
train_op = optimizer.minimize(loss_op)
# Evaluate model with test logits
correct_pred = tf.equal(tf.argmax(logits,
1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred,
tf.float32))
# For visualization in TensorBoard
tf.summary.scalar(‘accuracy’, accuracy)
#For TensorBoard
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter("events")
# Initialize the variables (assign their default
value)
init = tf.global_variables_initializer()
В качестве функции потерь мы используем кросс-энтропийные потери с softmax. Помимо этого, в TensorFlow есть и другие встроенные функции потерь. Некоторые из них:
weighted_cross_entropy_with_logits.
Adam — один из наиболее часто используемых алгоритмов оптимизации в сообществе машинного обучения. Некоторые другие оптимизаторы, доступные в TensorFlow:
GradientDescentOptimizer, AdadeltaOptimizer, AdagradOptimizer, MomentumOptimizer, FtrlOptimizer, and RMSPropOptimizer.
Точность — наша метрика оценки, как обычно.
Теперь пришло время обучить нашу модель!
with tf.Session() as sess:
# Run the initializer
sess.run(init)
# For visualization of the graph
in TensorBoard
train_writer.add_graph(sess.graph)
for step in range(0, epoch):
# Run optimization
sess.run(train_op, feed_dict={X: X_train,
Y: y_train})
# Calculate loss and accuracy
summary, loss, acc
= sess.run([merged, loss_op, \
accuracy], feed_dict={X: X_train,
Y: y_train})
# Add summary events for TensorBoard
train_writer.add_summary(summary,step)
print("Step " + str(step) + ", Loss= " +
\
"{:.4f}".format(loss) + ", Training
Accuracy= "+ \
"{:.3f}".format(acc))
print("Optimization Finished!")
# Calculate test accuracy
acc = sess.run(accuracy, feed_dict=
{X: X_test, Y: y_test})
print("Testing Accuracy:", acc)
# close the FileWriter
train_writer.close()
После нескольких итераций вы должны увидеть примерно такой вывод:
Step 0, Loss= 0.4989, Training Accuracy= 0.821 Step 1, Loss= 0.2737, Training Accuracy= 0.898 Step 2, Loss= 0.2913, Training Accuracy= 0.873 Step 3, Loss= 0.3024, Training Accuracy= 0.864 Step 4, Loss= 0.2313, Training Accuracy= 0.892 Step 5, Loss= 0.1640, Training Accuracy= 0.933 Step 6, Loss= 0.1607, Training Accuracy= 0.943 Step 7, Loss= 0.1684, Training Accuracy= 0.938 Step 8, Loss= 0.1537, Training Accuracy= 0.944 Step 9, Loss= 0.1242, Training Accuracy= 0.956 Optimization Finished! Testing Accuracy: 0.95476
Регрессия
Хотя сегодняшние приложения глубокого обучения весьма успешны в сложных задачах классификации, TensorFlow также позволяет нам строить модели регрессии почти так же. В этом разделе мы покажем вам, как предсказать непрерывную переменную исхода с использованием регрессии.
Очень важно выбрать функцию потерь, отличающуюся от той, которую мы использовали в модели классификации – ту, которая больше подходит для задачи регрессии. Мы выберем метрику L2, поскольку она является одной из самых популярных метрик в регрессионном анализе. С точки зрения оценки мы будем использовать R-квадрат для оценки производительности нашей модели на тестовом наборе.
Мы импортируем те же библиотеки, которые импортировали для задачи классификации:
import numpy as np import pandas as pd import tensorflow as tf from sklearn.model_selection import
train_test_split
Мы используем тот же синтетический набор данных, что и ранее, с 20 признаками и 1 переменной исхода. Ниже мы загружаем набор данных и выполняем некоторую предварительную обработку для форматирования данных, которые мы будем использовать в нашей модели:
import the data
with open("../data/data2.csv") as f:
data_raw = f.read()
# split the data into separate lines
lines = data_raw.splitlines()
Вместо того чтобы называть переменную исхода «метками», в данном случае мы предпочитаем называть ее «исходами», поскольку это кажется более подходящим для моделей регрессии. Как обычно, мы выделяем 20% нашего набора данных в качестве тестовых данных.
outcomes = []
features = []
for line in lines:
tokens = line.split(',')
outcomes.append(float(tokens[-1]))
features.append([float(x) for x in
tokens[:-1]])
X_train, X_test, y_train, y_test =
train_test_split(features, \ outcomes,
test_size=0.2, random_state=42)
Теперь мы можем задать гиперпараметры модели относительно процесса оптимизации и определить структуру нашей модели:
# Parameters learning_rate = 0.1 epoch = 500 # Network Parameters n_hidden_1 = 64 # 1st layer number of neurons n_hidden_2 = 64 # 2nd layer number of neurons
num_input = 20 # data input
num_classes = 1 # total classes
# tf Graph input
X = tf.placeholder("float", [None, num_input])
Y = tf.placeholder("float", [None, num_classes])
На этот раз наш исход — это одно значение по своей природе, и у нас есть 20 признаков. Мы устанавливаем соответствующие параметры выше. Далее мы сохраняем параметры модели в двух словарях, как мы делали в случае классификации:
# weights & biases
weights = {
'h1': tf.Variable(tf.random_normal([num_input,n_h
idden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1,n_
hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2,
\
num_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1]))
,
'b2': tf.Variable(tf.random_normal([n_hidden_2]))
,
'out': tf.Variable(tf.random_normal([num_classes]
))
}
Пришло время определить структуру нашей модели. Граф точно такой же,
как и граф модели классификации, которую мы использовали в предыдущей части:
# Create model def neural_net(x): # Hidden fully connected layer with 64 neurons layer_1 = tf.add(tf.matmul(x, weights[‘h1’]), biases[‘b1’]) # Hidden fully connected layer with 64 neurons layer_2 = tf.add(tf.matmul(layer_1, weights[‘h2’]), \ biases[‘b2’]) # Output fully connected layer out_layer = tf.matmul(layer_2, weights[‘out’]) \ + biases[‘out’] return out_layer
Разница между моделью классификации и моделью регрессии заключается в том, что последняя использует потери L2 в качестве функции потерь. Это связано с тем, что результат модели регрессии является непрерывным; как таковая, мы должны использовать функцию потерь, способную обрабатывать непрерывные значения потерь. В этой модели регрессии мы также используем алгоритм оптимизации Adam.
Еще одно различие между нашими моделями классификации и регрессии — это метрика, которую мы используем для оценки нашей модели. Для моделей регрессии мы предпочитаем использовать метрику R-квадрат; это одна из самых распространенных метрик, используемых для оценки производительности моделей регрессии:
# Evaluate model using R-squared total_error = tf.reduce_sum(tf.square(tf.subtract (Y, \ tf.reduce_mean(Y)))) unexplained_error = tf.reduce_sum(tf.square(tf.su btract(Y, \ output))) R_squared = tf.subtract(1.0,tf.div(unexplained_er ror, \ total_error)) # Initialize the variables (assign their default values) init = tf.global_variables_initializer()
Мы готовы обучить нашу модель:
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(0, epoch):
# Run optimization
sess.run(train_op,feed_dict= \
{X: X_train, \
Y:np.array(y_train).reshape(200000,1)
})
# Calculate batch loss and accuracy
loss, r_sq = sess.run([loss_op, R_squared], \
feed_dict={X: X_train, \
Y: np.array(y_train).resha
pe(200000,1)})
print("Step " + str(step) + ", L2 Loss= "
+ \
"{:.4f}".format(loss) + ", Training
R-squared= " \
+ "{:.3f}".format(r_sq))
print("Optimization Finished!")
# Calculate accuracy for MNIST test images
print("Testing R-squared:", \
sess.run(R_squared, feed_dict=
{X: X_test, \
Y: np.array(y_test).reshape(50000,1)}))
Результат модели должен выглядеть так:
Step 497, L2 Loss= 81350.7812, Training R- squared= 0.992 Step 498, L2 Loss= 81342.4219, Training R- squared= 0.992 Step 499, L2 Loss= 81334.3047, Training R- squared= 0.992 Optimization Finished! Testing R-squared: 0.99210745
Итак, наша модель достигает R-квадрата 0.97 на тестовых данных.
Визуализация в TensorFlow: TensorBoard
Визуализация результатов вашей модели является полезным методом для исследования, понимания и отладки. Для этого TensorFlow предлагает библиотеку визуализации под названием TensorBoard; с помощью этой библиотеки вы можете визуализировать свои модели и их результаты. TensorBoard поставляется вместе с TensorFlow; как только вы установите TensorFlow на свой компьютер, TensorBoard должен быть присутствовать.
TensorBoard читает файлы событий, содержащие сводные данные о модели TensorFlow. Для генерации сводных данных TensorFlow предоставляет некоторые функции в модуле summary. В этом модуле есть функции, которые работают точно так же, как операции в TensorFlow. Это означает, что мы можем использовать тензоры и операции в качестве входных данных для этих сводных операций.
В примере с классификацией мы фактически использовали некоторые из этих функций. Вот сводка операций, которые мы использовали в нашем примере:
tf.summary.scalar: If we want data about how a scalar evolves in time (like our loss function), we can use the loss function node as an input for the tf.summary.scalar function—right after we define the loss, as shown in the following example: loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_l ogits( logits=logits, labels=Y)) tf.summary.scalar(‘loss_value’, loss_op)
tf.summary.histogram: We may also be interested in the distributions of some variables, like the results of a matrix multiplication. In this case we use tf.summary.histogram, as follows: out_layer = tf.matmul(layer_2, weights[‘out’]) + biases[‘out’] tf.summary.histogram(‘output_layer’, out_layer)
tf.summary.merge_all: Summary nodes do not alter the graph of the model, but we need them to run our summary operations. The tf.summary.merge_all function merges all of our summary operations so that we do not need to run each operation one by one. tf.summary.FileWriter: This function is used to store the summary (which was generated using the tf.summary.merge_all function) to the disk. Here is an example of how to do that: merged = tf.summary.merge_all() train_writer = tf.summary.FileWriter(“events”)
После того как мы определили наши объекты для записи файлов, нам также необходимо инициализировать их внутри сессии:
train_writer.add_graph(sess.graph)
После того как мы интегрировали функции сводки в наш код, мы должны записать сводки в файлы и визуализировать их. При запуске нашей модели мы также получим сводки:
summary, loss, acc = sess.run([merged, loss_op,
accuracy], feed_dict={X: batch_x, Y: batch_y})
После этого мы добавляем сводку в наш файл сводки:
train_writer.add_summary(summary,step)
Наконец, закрываем FileWriter:
train_writer.close()
Далее мы можем визуализировать сводки в браузере. Для этого нам нужно запустить следующую команду:
tensorboard —logdir=path/to/log-directory
где log-directory указывает на каталог, где мы сохранили наши файлы сводки. При открытии localhost:6006 в браузере вы увидите панель управления со сводками вашей модели, похожую на ту, что показана на
Рисунке 4
.
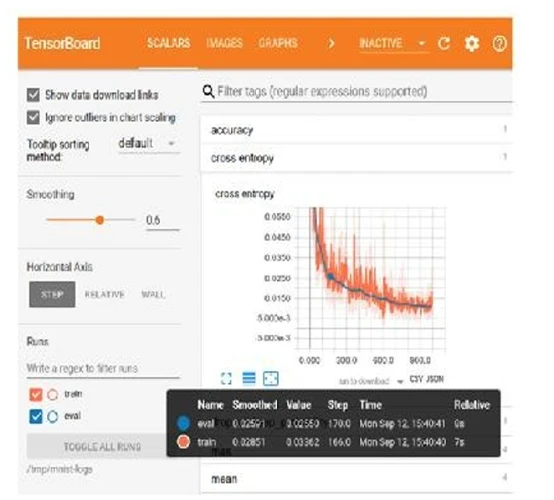
Рисунок 4: Панель управления TensorBoard. Источник: https://bit.ly/2IWkbbh.
Высокоуровневые API в TensorFlow: Estimators
До сих пор мы обсуждали низкоуровневые структуры TensorFlow. Мы видели, что мы должны строить собственный граф и следить за сессией. Однако TensorFlow также предоставляет высокоуровневый API, где утомительная работа обрабатывается автоматически. Этот высокоуровневый API называется «Estimators».
API Estimators также предоставляет готовые эстиматоры. Вы можете быстро использовать эти эстиматоры и настраивать их по мере необходимости. Вот некоторые из преимуществ этого API по сравнению с низкоуровневыми API TensorFlow:
- С меньшим количеством строк кода вы можете реализовать ту же модель.
- Построение графа, открытие и закрытие сессии, а также инициализация переменных обрабатываются автоматически.
- Тот же код выполняется на CPU, GPU или TPU.
- Поддерживается параллельное вычисление. Таким образом, при наличии нескольких серверов, код, написанный на этом API, может быть запущен без каких-либо изменений кода, который вы запускаете на своей локальной машине.
- Сводки моделей автоматически сохраняются для TensorBoard.
При написании кода с использованием этого API вы в основном следуете четырем шагам:
- Чтение набора данных.
- Определение столбцов признаков.
- Настройка предопределенного эстиматора.
- Обучение и оценка эстиматора.
Теперь мы продемонстрируем каждый из этих шагов, используя наши синтетические данные для классификации. Сначала мы считываем данные из нашего .csv файла, как обычно:
# import the data
with open("../data/data1.csv") as f:
data_raw = f.read()
# split the data into separate lines
lines = data_raw.splitlines()
labels = []
x1 = []
x2 = []
x3 = []
for line in lines:
tokens = line.split(',')
labels.append(int(tokens[-1])-1)
x1.append(float(tokens[0]))
x2.append(float(tokens[1])) x3.append(float(tokens[2])) features = np.array([x1,x2,x3]).reshape(250000,3) labels = np.array(pd.Series(labels)) X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
Второе, мы напишем функцию, которая преобразует наши признаки в словарь и возвращает признаки и метки для модели:
def inputs(features,labels):
features = {‘x1’: features[:,0],
‘x2’: features[:,1],
‘x3’: features[:,2]}
labels = labels
return features, labels
В-третьих, мы напишем функцию, которая преобразует наши данные в объект DataSet:
def train_input_fn(features, labels, batch_size): # Convert the inputs to a Dataset. dataset = tf.data.Dataset.from_tensor_slices((dict(features ), labels)) # Shuffle, repeat, and batch the examples. return dataset.shuffle(1000).repeat().batch(batch_size)
Определение наших столбцов признаков требует всего несколько строк кода:
# Feature columns describe how to use the input. my_feature_columns = [] for key in [‘x1’,’x2’,’x3’]: my_feature_columns.append(tf.feature_column.n umeric_column(key=key))
Прежде чем запустить нашу модель, мы должны выбрать предопределенный эстиматор, подходящий для наших нужд. Поскольку наша задача — классификация, мы используем два полностью связанных слоя, как мы делали ранее. Для этого API эстиматора предоставляет классификатор под названием DNNClassifier:
# Build a DNN with 2 hidden layers and 256 nodes in each hidden layer. classifier = tf.estimator.DNNClassifier( feature_columns=my_feature_columns, # Two hidden layers of 256 nodes each. hidden_units=[256, 256], # The model must choose between 3 classes. n_classes=3, optimizer=tf.train.AdamOptimizer( learning_rate=0.1 ))
Как и прежде, мы определили два плотных слоя размером 256, установили скорость обучения 0,1 и количество классов равным 3.
Теперь мы готовы обучить и оценить нашу модель. Обучение так же просто, как:
classifier.train(input_fn=lambda:train_input_fn(i nputs(X_train,y_train)[0], inputs(X_train,y_train)[1], 64), steps=500)
Мы предоставили функцию, которую написали выше, возвращающую объект DataSet для модели в качестве аргумента функции train(). Мы также установили шаги обучения в 500, как обычно. Когда вы запустите приведенный выше код, вы должны увидеть что-то вроде:
INFO:tensorflow:loss = 43.874107, step = 401 (0.232 sec) INFO:tensorflow:Saving checkpoints for 500 into /tmp/tmp8xv6svzr/model.ckpt. INFO:tensorflow:Loss for final step: 34.409817.
После этого мы можем оценить производительность нашей модели на тестовом наборе:
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:train_input_fn(inputs(X_test,
y_test)[0], inputs(X_test,y_test)[1], 64),
steps=1)
print('Test set accuracy:
{accuracy:0.3f}\n'.format(**eval_result))
Вывод должен выглядеть так:
INFO:tensorflow:Starting evaluation at 2018-04- 07-12:11:21 INFO:tensorflow:Restoring parameters from /tmp/tmp8xv6svzr/model.ckpt-500 INFO:tensorflow:Evaluation [1/1] INFO:tensorflow:Finished evaluation at 2018-04- 07-12:11:21 INFO:tensorflow:Saving dict for global step 500: accuracy = 0.828125, average_loss = 0.6096449, global_step = 500, loss = 39.017273 Test set accuracy: 0.828
Резюме
- TensorFlow — это фреймворк глубокого обучения, изначально разработанный Google и теперь поддерживаемый огромным сообществом открытого исходного кода.
- TensorFlow на сегодняшний день является самым популярным фреймворком глубокого обучения. Даже если вы решите использовать другие фреймворки, изучение основ TensorFlow полезно; большая часть кода, который вы встретите, написана другими, вероятно, будет написана на TensorFlow.
- TensorFlow поддерживает распределенные вычисления по своей природе.
- Модели TensorFlow могут запускаться на CPU, GPU и TPU.
- Вы можете писать код TensorFlow на Python, Java, Julia, C++, R и др.
- Хотя вы можете использовать низкоуровневые структуры TensorFlow, существует также много высокоуровневых API, которые упрощают процесс построения модели.
Вы также можете использовать Keras поверх Theano или CNTK, но использование его поверх TensorFlow на сегодняшний день является наиболее распространенным в отрасли.