Глава 5: Создание сети глубокого обучения с использованием Keras
Теперь, когда вы поняли основы фреймворка TensorFlow, мы рассмотрим другой очень популярный фреймворк, построенный поверх TensorFlow: Keras. Keras — это фреймворк, который сокращает количество строк кода, которые вам нужно написать, благодаря своим абстрактным слоям. Он предоставляет простой, но мощный API, позволяющий почти любому реализовать даже сложные модели глубокого обучения всего за несколько строк кода.
Наш совет заключается в следующем: если вы новичок в глубоком обучении, используйте Keras, поскольку с его помощью вы можете реализовать практически все. Тем не менее, знакомство с TensorFlow также полезно. Вы, скорее всего, встретите модели, написанные на TensorFlow, и чтобы понять их, вам потребуется хорошее знание TensorFlow. Это одна из причин, по которой мы представили TensorFlow перед Keras. Другая причина в том, что теперь мы можем оценить простоту, которую Keras приносит на стол, по сравнению с TensorFlow!
Мы рассмотрим базовые структуры в Keras и покажем, как реализовать модели глубокого обучения в Keras, используя наш синтетический набор данных. Затем мы изучим возможности визуализации фреймворка. После этого мы покажем, как преобразовать ваши модели, написанные на Keras, в эстиматоры TensorFlow.
Keras работает поверх бэкэнд-движка, которым может быть TensorFlow, Theano или CNTK. Поэтому, прежде чем устанавливать Keras, следует сначала установить один из этих трех бэкэндов, которые поддерживает Keras. По умолчанию Keras поддерживает бэкэнд-движок TensorFlow. Поскольку мы рассмотрели TensorFlow в предыдущей главе, мы предполагаем, что вы уже установили TensorFlow на свою систему. Если нет, обратитесь к соответствующему разделу главы о TensorFlow, чтобы сначала установить TensorFlow.
После установки TensorFlow, Keras можно установить через PyPl.11 Просто запустите эту команду:
pip install keras
После выполнения приведенной выше команды фреймворк глубокого обучения Keras должен быть установлен в вашей системе. После импорта вы можете использовать Keras в своем коде Python следующим образом:
import keras
Keras абстрагирует низкоуровневые структуры данных TensorFlow, заменяя их интуитивно понятными, легко интегрируемыми и расширяемыми структурами. При разработке этого фреймворка разработчики следовали этим руководящим принципам:
- Удобство для пользователя: Keras ориентирует внимание человека на модели и строит детали вокруг этой структуры. Таким образом, он сокращает объем работы в общих случаях, предоставляя соответствующую функциональность по умолчанию.
- Модульность: В Keras мы можем легко интегрировать слои, оптимизаторы, слои активации и другие компоненты модели глубокого обучения вместе, как если бы они были модулями.
- Простая расширяемость: Мы можем легко создавать новые модули в Keras и интегрировать их в наши существующие модели. Они могут использоваться как объекты или функции.
Основные компоненты
Основной компонент в Keras называется моделью. Вы можете думать о модели Keras как об абстракции модели глубокого обучения. Когда мы начинаем реализовывать модель глубокого обучения в Keras, мы обычно начинаем с создания так называемого объекта модели. Из множества типов моделей в Keras Sequential является простейшей и наиболее часто используемой.
Еще одна базовая структура в Keras называется слоем. Объекты слоев в Keras представляют фактические слои в модели глубокого обучения. Мы можем добавлять объекты слоев к нашему объекту модели, просто определяя тип слоя, количество единиц и размеры входа/выхода. Наиболее часто используемый тип слоя — это
Плотный слой.
И это всё! Вы можете удивиться, что авторы забыли упомянуть некоторые другие критически важные части фреймворка Keras. Однако, как вы увидите ниже, вы можете начать строить свою модель с того, что уже изучили!
Keras в действии
Теперь пришло время увидеть Keras в действии. Помните, что наборы данных и код, рассматриваемые в этом разделе, доступны вам через образ Docker, предоставленный с книгой.
Наборы данных, используемые для демонстрации Keras, — это те же самые синтетические наборы данных, которые использовались в главе о TensorFlow. Мы снова будем использовать их для целей классификации и регрессии.
Классификация
Прежде чем приступить к реализации нашего классификатора, нам необходимо импортировать некоторые библиотеки, чтобы использовать их. Вот библиотеки, которые нам необходимо импортировать:
import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import Dense from keras import optimizers from sklearn.model_selection import train_test_split
Сначала нам следует загрузить набор данных и немного предварительно обработать его, чтобы отформатировать данные, которые мы будем использовать в нашей модели. Как обычно, мы загружаем данные в виде списка:
# import the data
with open("../data/data1.csv") as f:
data_raw = f.read()
lines = data_raw.splitlines() # split
the data into separate lines
Затем мы разделяем метки и три признака на списки, соответственно называемые метками и признаками:
labels = []
features = []
for line in lines:
tokens = line.split(',')
labels.append(int(tokens[-1]))
x1,x2,x3 = float(tokens[0]),
float(tokens[1]), float(tokens[2])
features.append([x1, x2, x3])
Затем мы создаем фиктивные переменные для трех категорий меток, используя функцию Pandas get_dummies:
labels = pd.get_dummies(pd.Series(labels))
Следующий шаг — разделить наши данные на обучающий и тестовый наборы. Для этого мы используем функцию train_test_split из scikit-learn, которую мы импортировали ранее:
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
Теперь мы готовы построить нашу модель с использованием Keras. Сначала мы определим нашу модель, а затем добавим три слоя; первые два — это плотные слои, а третий — выходной слой:
model = Sequential() model.add(Dense(units=16, activation='relu', input_dim=3)) model.add(Dense(units=16, activation='relu')) model.add(Dense(units=3, activation=‘softmax’))
Как видите, построение графа в Keras — довольно простая задача. В приведенном выше коде мы сначала определяем объект модели (который в данном случае является последовательным). Затем мы добавляем три полносвязных слоя (называемых плотными слоями).
После определения нашей модели и слоев, мы должны выбрать наш оптимизатор и
скомпилировать нашу модель. В качестве оптимизатора мы используем Adam, установив скорость обучения 0.1:
sgd = optimizers.Adam(lr=0.1)
Затем компилируем нашу модель. При этом мы определяем нашу функцию потерь как категориальную кросс-энтропию, которая является одной из предопределенных функций потерь в Keras. Для метрики оценки производительности нашей модели мы используем точность, как обычно. Все эти определения могут быть реализованы в одной строке в Keras, как показано здесь:
model.compile(loss=’categorical_crossentropy’, o ptimizer=sgd, metrics= [‘accuracy’])
Теперь пришло время обучить нашу модель одной строкой! Мы обучаем наши модели, вызывая функцию fit объекта модели. В качестве параметров мы предоставляем наши признаки и метки как массивы NumPy — размер пакета и количество эпох. Мы устанавливаем размер пакета равным 10.000, а количество эпох — 5:
model.fit(np.array(X_train), np.array(y_train), batch_size=10000, epochs = 5)
Во время обучения в консоли вы должны увидеть что-то вроде этого:
Epoch 1/5 200000/200000 [==============================] - 0s 2us/step - loss: 0.3671 - acc: 0.8255 Epoch 2/5 200000/200000 [==============================] - 0s 2us/step - loss: 0.0878 - acc: 0.9650 Epoch 3/5 200000/200000 [==============================] - 0s 2us/step - loss: 0.0511 - acc: 0.9790 Epoch 4/5 200000/200000 [==============================] - 0s 2us/step - loss: 0.0409 - acc: 0.9839 Epoch 5/5 200000/200000 [==============================] - 0s 2us/step - loss: 0.0368 - acc: 0.9854
Далее мы оцениваем производительность модели на наших тестовых данных:
loss_and_metrics = model.evaluate(np.array(X_test), np.array(y_test), batch_size=100) print(loss_and_metrics)
Должно распечататься:
[0.03417351390561089, 0.9865800099372863]
Таким образом, значение потерь нашей модели составляет примерно 0.03, а точность на тестовом наборе — около 0.99!
Регрессия
В Keras построение моделей регрессии так же просто, как построение моделей классификации. Мы сначала определяем наши модели и слои. Следует помнить, что выходной слой модели регрессии должен выдавать только одно значение.
Нам также необходимо выбрать другую функцию потерь. Как и в главе о TensorFlow, мы используем метрику L2, поскольку она является одной из самых популярных метрик в регрессионном анализе. Наконец, мы оцениваем производительность нашей модели с помощью R-квадрата.
Импортируем следующие библиотеки:
import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import Dense from keras import optimizers import keras.backend as K from sklearn.model_selection import train_test_split
Мы снова будем использовать синтетический набор данных из предыдущей главы. Напомним,
что он включает 20 признаков и 1 выходную переменную. Ниже мы загружаем набор данных и предварительно обрабатываем данные в формат, который будем использовать в нашей модели:
# import the data
with open("../data/data2.csv") as f:
data_raw = f.read()
lines = data_raw.splitlines() # split the
data into separate lines
Вместо «метки» мы предпочитаем называть целевую переменную «исходом», поскольку это более подходит для моделей регрессии. Как обычно, мы выделяем 20% нашего набора данных в качестве тестовых данных.
outcomes = []
features = []
for line in lines:
tokens = line.split(',')
outcomes.append(float(tokens[-1]))
features.append([float(x) for x in
tokens[:-1]])
X_train, X_test, y_train, y_test =
train_test_split(features, outcomes,
test_size=0.2, random_state=42)
Мы определяем нашу модель и слои следующим образом:
model = Sequential() model.add(Dense(units=64, activation='relu', input_dim=20)) model.add(Dense(units=64, activation='relu')) model.add(Dense(units=1, activation='linear'))
На этот раз наш результат является одним значением, и у нас есть 20 признаков. Поэтому мы устанавливаем соответствующие параметры. Пришло время скомпилировать нашу модель. Однако сначала мы должны определить функцию, которая вычисляет метрику R-квадрат. К сожалению, на момент написания Keras не предоставляет встроенную метрику R-квадрат в своем пакете. В таком случае,
рассмотрим нашу реализацию:
def r2(y_true, y_pred): SS_res = K.sum(K.square(y_true - y_pred)) SS_tot = K.sum(K.square(y_true - K.mean(y_true))) return ( 1 - SS_res/(SS_tot + K.epsilon()) )
После этого мы выбираем Adam в качестве нашего оптимизатора и устанавливаем скорость обучения 0.1:
sgd = optimizers.Adam(lr=0.1)
Теперь мы можем скомпилировать нашу модель. В качестве функции потерь мы используем среднеквадратичную ошибку, а в качестве метрики подаем в модель нашу функцию r2():
model.compile(optimizer=sgd, loss='mean_squared_error', metrics=[r2])
Обучение модели довольно просто в Keras, как мы видели ранее с классификацией. Мы предоставляем наши признаки и результаты в виде массивов NumPy для функции fit объекта модели. Мы также устанавливаем размер пакета равным 10 000 и количество эпох равным 10:
model.fit(np.array(X_train), np.array(y_train), batch_size=10000, epochs = 10)
Результат модели должен выглядеть так:
Epoch 1/10 200000/200000 [==============================] - 1s 5us/step - loss: 240.4952 - r2: -1.3662 Epoch 2/10 200000/200000 [==============================] - 0s 2us/step - loss: 83.3737 - r2: 0.1800 Epoch 3/10 200000/200000 [==============================] - 0s 2us/step - loss: 27.3745 - r2: 0.7308
Epoch 4/10 200000/200000 [==============================] - 0s 2us/step - loss: 5.7173 - r2: 0.9439 Epoch 5/10 200000/200000 [==============================] - 0s 2us/step - loss: 3.4069 - r2: 0.9665 Epoch 6/10 200000/200000 [==============================] - 0s 2us/step - loss: 3.0487 - r2: 0.9700 Epoch 7/10 200000/200000 [==============================] - 0s 2us/step - loss: 2.9293 - r2: 0.9712 Epoch 8/10 200000/200000 [==============================] - 0s 2us/step - loss: 2.8396 - r2: 0.9721 Epoch 9/10 200000/200000 [==============================] - 0s 2us/step - loss: 2.7537 - r2: 0.9729 Epoch 10/10 200000/200000 [==============================] - 0s 2us/step - loss: 2.6688 - r2: 0.9738
Далее мы оцениваем производительность нашей модели на тестовых данных:
loss_and_metrics = model.evaluate(np.array(X_test), np.array(y_test), batch_size=100) print(loss_and_metrics)
Вывод должен быть аналогичен этому:
50000/50000 [==============================] - 0s 7us/step [2.6564363064765932, 0.9742180906534195]
Таким образом, наша модель достигает R-квадрата 0,97 на тестовых данных.
Сводка и визуализация модели
Если вам не нужны визуализации, Keras может легко предоставить текстовое резюме слоев модели. Для этого Keras предоставляет функцию summary(). При вызове из модели она возвращает текстовую информацию о модели. Просто распечатав резюме модели с помощью кода ниже, можно проверить структуру модели:
print(model.summary())
В зависимости от структуры модели, вывод должен выглядеть примерно так:
_________________________________________________ ________________ Layer (type) Output Shape Param # ================================================= ================ dense_1 (Dense) (None, 2) 4 _________________________________________________ ________________ dense_2 (Dense) (None, 1) 3 ================================================= ================ Total params: 7 Trainable params: 7 Non-trainable params: 0
Конечно, визуализация не только более эстетична, но и может помочь вам легко объяснить и поделиться своими выводами с заинтересованными сторонами и членами команды. Графическая визуализация модели в Keras довольно проста. Модуль под названием keras.utils.vis_utils включает все утилиты для визуализации графа с помощью библиотеки graphviz. В частности, функция plot_model() является основным инструментом для визуализации
модели. Приведенный ниже код демонстрирует, как создать и сохранить визуализацию графа для модели:
from keras.utils import plot_model plot_model(model, to_file = “my_model.png”)
В зависимости от структуры модели, файл .png должен содержать график, похожий на тот, что на
Рисунке 5
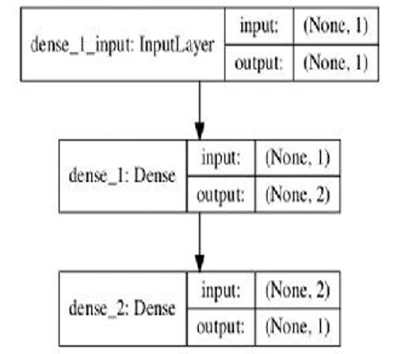
Рисунок 5: Визуализация графа модели в Keras.
Функция plot_model() принимает два необязательных аргумента:
- show_shapes: если True, граф показывает выходные формы. Значение по умолчанию False.
- show_layer_names: если True, граф показывает имена слоев. Значение по умолчанию True.
Преобразование моделей Keras в эстиматоры TensorFlow
Как мы уже упоминали в предыдущей главе, TensorFlow предоставляет богатый набор предварительно обученных моделей, которые вы можете использовать без какого-либо обучения. Абстракция Estimators в TensorFlow позволит вам использовать эти предварительно обученные модели. Чтобы полностью использовать этот богатый набор моделей, было бы неплохо преобразовать наши модели Keras в Estimators TensorFlow. К счастью, Keras предоставляет эту функциональность из коробки. Всего одной строкой кода модели Keras превращаются в Estimators TensorFlow, готовые к использованию. Функция называется model_to_estimator() в модуле keras.estimator и выглядит следующим образом:
estimator_model = keras.estimator.model_to_estimator(keras_model = model)
Как только мы преобразуем нашу модель Keras в Estimator TensorFlow, мы можем использовать этот эстиматор в коде TensorFlow (как мы продемонстрировали в предыдущей главе).
Перед завершением главы мы призываем наших пользователей прочитать больше о фреймворке Keras. Если вы используете модели глубокого обучения для исследовательских целей, Keras, вероятно, является наиболее удобным инструментом для вас. Keras сэкономит много времени на реализации множества моделей, которые вы попробуете. Если вы практик в области науки о данных, Keras является одним из лучших вариантов для вас как в прототипировании, так и в производстве. Следовательно, расширение вашего понимания и опыта в Keras полезно независимо от вашей конкретной задачи.
Резюме
- Keras — это фреймворк глубокого обучения, который предоставляет удобный и простой в использовании абстрактный слой поверх фреймворка TensorFlow.
- Keras предоставляет более удобный для пользователя API для фреймворка TensorFlow. Наряду с легкостью расширения и модульностью, это основные преимущества Keras по сравнению с другими фреймворками.
- Основная структура в Keras - это объект модели, который представляет модель глубокого обучения, подлежащую использованию. Наиболее часто используемым типом модели является последовательная модель. Еще одна важная структура в Keras - это слой, который представляет слои в модели; наиболее распространенным слоем является Плотный слой.
- Визуализация структуры модели в Keras осуществляется одним вызовом функции plot_model().
- Хорошая идея начать строить модели глубокого обучения в Keras вместо TensorFlow, если вы новичок в этой области.
- Хотя Keras предоставляет очень широкий спектр функциональности, может потребоваться переключиться на TensorFlow для написания некоторой более сложной функциональности для нестандартных моделей глубокого обучения.
TensorFlow теперь интегрирует Keras в свое ядро. Таким образом, нет необходимости дополнительно устанавливать Keras, если у вас уже установлен TensorFlow. Однако мы хотим подчеркнуть Keras как отдельный фреймворк, поскольку вы можете предпочесть использовать его поверх Theano или CNTK. В этом отношении мы предпочитаем устанавливать Keras отдельно.