перевод выполнен с помощью Google Gemini 2.5 pro

Введение
Люди прекрасно справляются с задачами распознавания сложных закономерностей. Однако они часто полагаются на инструменты — такие как книги, Google Поиск или калькулятор — чтобы дополнить свои знания перед тем, как прийти к заключению. Подобно людям, генеративные ИИ-модели могут быть обучены использовать инструменты для доступа к информации в реальном времени или для предложения реальных действий. Например, модель может использовать инструмент для извлечения данных из базы данных, чтобы получить доступ к конкретной информации, такой как история покупок клиента, и сгенерировать персонализированные рекомендации по покупкам. В качестве альтернативы, на основе запроса пользователя модель может выполнить различные вызовы API, чтобы отправить ответ по электронной почте коллеге или завершить финансовую транзакцию от вашего имени. Для этого модель должна не только иметь доступ к набору внешних инструментов, но и обладать способностью планировать и выполнять любую задачу самостоятельно. Эта комбинация рассуждений, логики и доступа к внешней информации, подключенная к генеративной ИИ-модели, вызывает концепцию агента, или программы, которая выходит за рамки автономных возможностей генеративной ИИ-модели. В этом документе подробно рассматриваются все эти и связанные с ними аспекты.
Что такое агент?
В своей самой фундаментальной форме, агент генеративного ИИ может быть определен как приложение, которое пытается достичь цели, наблюдая за миром и воздействуя на него с помощью имеющихся в его распоряжении инструментов. Агенты автономны и могут действовать независимо от вмешательства человека, особенно когда им предоставлены надлежащие цели или задачи, которые они должны выполнить. Агенты также могут быть проактивны в своем подходе к достижению целей. Даже при отсутствии явных наборов инструкций от человека, агент может рассуждать о том, что ему следует делать дальше для достижения своей конечной цели. Хотя понятие агентов в ИИ довольно общее и мощное, этот документ фокусируется на конкретных типах агентов, которые могут быть созданы с помощью моделей генеративного ИИ на момент публикации.
Чтобы понять внутреннюю работу агента, давайте сначала представим основополагающие компоненты, которые управляют поведением, действиями и принятием решений агента. Комбинация этих компонентов может быть описана как когнитивная архитектура, и существует множество таких архитектур, которые могут быть достигнуты путем смешивания и сопоставления этих компонентов. Сосредоточившись на основных функциональных возможностях, можно выделить три существенных компонента в когнитивной архитектуре агента, как показано на Рисунке 1.
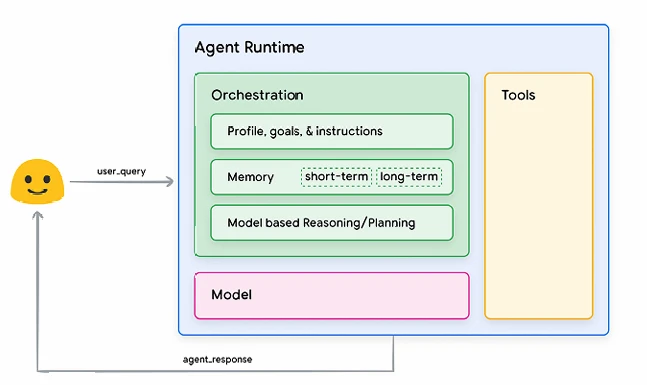
Рисунок 1. Общая архитектура и компоненты агента
Модель
В контексте агента, модель относится к языковой модели (LM), которая будет использоваться в качестве центрального элемента принятия решений для процессов агента. Модель, используемая агентом, может быть одной или несколькими LM любого размера (маленькой/большой), способными следовать инструкциям на основе фреймворков рассуждений и логики, таких как ReAct, Chain-of-Thought или Tree-of-Thoughts. Модели могут быть общего назначения, мультимодальными или дообученными (fine-tuned) в зависимости от потребностей вашей конкретной архитектуры агента. Для достижения наилучших результатов в производственной среде следует использовать модель, которая наилучшим образом соответствует вашему желаемому конечному приложению и, в идеале, была обучена на сигнатурах данных, связанных с инструментами, которые вы планируете использовать в когнитивной архитектуре. Важно отметить, что модель обычно не обучается с конкретными настройками конфигурации агента (т.е. выбором инструментов, настройкой оркестрации/рассуждений). Однако возможно дальнейшее уточнение модели для задач агента, предоставляя ей примеры, демонстрирующие возможности агента, включая случаи использования агентом определенных инструментов или шагов рассуждений в различных контекстах.
Инструменты
Фундаментальные модели, несмотря на их впечатляющие возможности генерации текста и изображений, остаются ограниченными своей неспособностью взаимодействовать с внешним миром. Инструменты преодолевают этот разрыв, позволяя агентам взаимодействовать с внешними данными и сервисами, открывая при этом более широкий спектр действий, выходящих за рамки возможностей базовой модели. Инструменты могут принимать различные формы и иметь разную сложность, но обычно соответствуют распространенным методам веб-API, таким как GET, POST, PATCH и DELETE. Например, инструмент может обновить информацию о клиенте в базе данных или получить данные о погоде, чтобы повлиять на рекомендацию по путешествию, которую агент предоставляет пользователю. С помощью инструментов агенты могут получать доступ к реальной информации и обрабатывать ее. Это позволяет им поддерживать более специализированные системы, такие как генерация с дополнением извлеченными данными (RAG), что значительно расширяет возможности агента по сравнению с тем, чего может достичь базовая модель сама по себе. Мы обсудим инструменты более подробно ниже, но самое важное — понять, что инструменты устраняют разрыв между внутренними возможностями агента и внешним миром, открывая более широкий спектр возможностей.
Слой оркестрации
Слой оркестрации описывает циклический процесс, который управляет тем, как агент принимает информацию, выполняет некоторые внутренние рассуждения и использует эти рассуждения для информирования своего следующего действия или решения. В целом, этот цикл будет продолжаться до тех пор, пока агент не достигнет своей цели или точки остановки. Сложность слоя оркестрации может сильно варьироваться в зависимости от агента и выполняемой им задачи. Некоторые циклы могут быть простыми вычислениями с правилами принятия решений, в то время как другие могут содержать цепочки логики, включать дополнительные алгоритмы машинного обучения или реализовывать другие вероятностные методы рассуждений. Мы подробнее обсудим детальную реализацию слоев оркестрации агентов в разделе о когнитивной архитектуре.
Агенты против моделей
Чтобы получить более четкое представление о различии между агентами и моделями, рассмотрим следующую таблицу:
| Модели | Агенты |
|---|---|
| Знания ограничены тем, что доступно в их обучающих данных. | Знания расширяются за счет связи с внешними системами через инструменты. |
| Одиночный вывод / предсказание на основе запроса пользователя. Если это явно не реализовано для модели, нет управления историей сеанса или непрерывным контекстом (т.е. историей чата). | Управляемая история сеанса (т.е. история чата) для обеспечения многоходового вывода / предсказания на основе запросов пользователя и решений, принятых на уровне оркестрации. В этом контексте 'ход' определяется как взаимодействие между взаимодействующей системой и агентом (т.е. 1 входящее событие/запрос и 1 ответ агента). |
| Нет встроенной реализации инструментов. | Инструменты реализованы нативно в архитектуре агента. |
| Нет встроенного логического слоя. Пользователи могут формировать промпты в виде простых вопросов или использовать фреймворки рассуждений (CoT, ReAct и т.д.) для формирования сложных промптов, чтобы направлять модель в предсказании. | Нативная когнитивная архитектура, использующая фреймворки рассуждений, такие как CoT, ReAct, или другие готовые фреймворки агентов, такие как LangChain. |
Когнитивные архитектуры: Как работают агенты
Представьте себе шеф-повара на оживленной кухне. Его цель — создавать вкусные блюда для посетителей ресторана, что включает в себя определенный цикл планирования, выполнения и корректировки.
- Они собирают информацию, такую как заказ посетителя и какие ингредиенты есть в кладовой и холодильнике.
- Они выполняют некоторое внутреннее рассуждение о том, какие блюда и вкусовые профили они могут создать на основе только что собранной информации.
- Они предпринимают действия для создания блюда: нарезают овощи, смешивают специи, обжаривают мясо.
На каждом этапе процесса шеф-повар вносит необходимые коррективы, уточняя свой план по мере истощения ингредиентов или получения обратной связи от клиентов, и использует набор предыдущих результатов для определения следующего плана действий. Этот цикл сбора информации, планирования, выполнения и корректировки описывает уникальную когнитивную архитектуру, которую использует шеф-повар для достижения своей цели.
Так же, как и шеф-повар, агенты могут использовать когнитивные архитектуры для достижения своих конечных целей путем итеративной обработки информации, принятия обоснованных решений и уточнения следующих действий на основе предыдущих результатов. В основе когнитивных архитектур агентов лежит слой оркестрации, отвечающий за поддержание памяти, состояния, рассуждений и планирования. Он использует быстро развивающуюся область инженерии промптов и связанные с ней фреймворки для управления рассуждениями и планированием, позволяя агенту более эффективно взаимодействовать со своей средой и выполнять задачи. Исследования в области фреймворков инженерии промптов и планирования задач для языковых моделей быстро развиваются, предлагая разнообразные перспективные подходы. Хотя список не является исчерпывающим, вот несколько наиболее популярных фреймворков и методов рассуждений, доступных на момент публикации:
- ReAct, фреймворк инженерии промптов, который предоставляет стратегию мыслительного процесса для языковых моделей для Рассуждения (Reason) и выполнения действия (Act) по запросу пользователя, с примерами в контексте или без них. Промптинг ReAct показал превосходство над несколькими передовыми базовыми показателями (SOTA) и улучшает взаимодействие с человеком и надежность LLM.
- Chain-of-Thought (CoT), фреймворк инженерии промптов, который включает возможности рассуждения через промежуточные шаги. Существуют различные подтехники CoT, включая self-consistency (самосогласованность), active-prompt (активный промпт) и мультимодальный CoT, каждая из которых имеет свои сильные и слабые стороны в зависимости от конкретного применения.
- Tree-of-thoughts (ToT), фреймворк инженерии промптов, который хорошо подходит для задач исследования или стратегического планирования наперед. Он обобщает промптинг chain-of-thought и позволяет модели исследовать различные цепочки мыслей, которые служат промежуточными шагами для общего решения проблем с помощью языковых моделей.
Агенты могут использовать одну из вышеупомянутых техник рассуждения или многие другие техники для выбора наилучшего следующего действия для данного запроса пользователя. Например, давайте рассмотрим агента, который запрограммирован использовать фреймворк ReAct для выбора правильных действий и инструментов для запроса пользователя. Последовательность событий может выглядеть примерно так:
- Пользователь отправляет запрос агенту
- Агент начинает последовательность ReAct
- Агент предоставляет промпт модели, прося ее сгенерировать один из следующих шагов ReAct и соответствующий ему вывод:
- Вопрос (Question): Входной вопрос из запроса пользователя, предоставленный вместе с промптом
- Мысль (Thought): Мысли модели о том, что ей следует делать дальше
- Действие (Action): Решение модели о том, какое действие предпринять дальше
- Здесь может происходить выбор инструмента
- Например, действием может быть одно из [Flights, Search, Code, None], где первые 3 представляют известный инструмент, который модель может выбрать, а последний представляет "нет выбора инструмента"
- Ввод действия (Action input): Решение модели о том, какие входные данные предоставить инструменту (если таковые имеются)
- Наблюдение (Observation): Результат последовательности действия / ввода действия
- Эта последовательность мысль / действие / ввод действия / наблюдение может повторяться N раз по мере необходимости
- Окончательный ответ (Final answer): Окончательный ответ модели для предоставления на исходный запрос пользователя
- Цикл ReAct завершается, и окончательный ответ возвращается пользователю
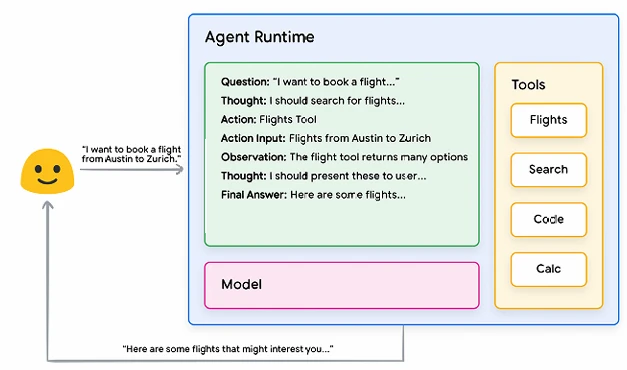
Рисунок 2. Пример агента с рассуждением ReAct в слое оркестрации
Как показано на Рисунке 2, модель, инструменты и конфигурация агента работают вместе, чтобы предоставить обоснованный, краткий ответ пользователю на основе его первоначального запроса. Хотя модель могла бы угадать ответ (галлюцинировать) на основе своих предварительных знаний, вместо этого она использовала инструмент (Flights) для поиска внешней информации в реальном времени. Эта дополнительная информация была предоставлена модели, что позволило ей принять более обоснованное решение на основе реальных фактических данных и обобщить эту информацию для пользователя.
В итоге, качество ответов агента может быть напрямую связано со способностью модели рассуждать и действовать в отношении этих различных задач, включая способность выбирать правильные инструменты и то, насколько хорошо этот инструмент был определен. Подобно шеф-повару, создающему блюдо из свежих ингредиентов и внимательному к отзывам клиентов, агенты полагаются на здравый смысл и надежную информацию для достижения оптимальных результатов. В следующем разделе мы углубимся в различные способы, которыми агенты подключаются к свежим данным.
Инструменты: Наши ключи к внешнему миру
Хотя языковые модели преуспевают в обработке информации, им не хватает способности непосредственно воспринимать реальный мир и влиять на него. Это ограничивает их полезность в ситуациях, требующих взаимодействия с внешними системами или данными. Это означает, что, в некотором смысле, языковая модель хороша лишь настолько, насколько хороши данные, на которых она обучалась. Но независимо от того, сколько данных мы предоставим модели, им все еще не хватает фундаментальной способности взаимодействовать с внешним миром. Итак, как мы можем дать нашим моделям возможность взаимодействовать с внешними системами в реальном времени и с учетом контекста? Функции (Functions), Расширения (Extensions), Хранилища данных (Data Stores) и Плагины (Plugins) — все это способы предоставить эту критически важную возможность модели.
Хотя их называют по-разному, именно инструменты создают связь между нашими фундаментальными моделями и внешним миром. Эта связь с внешними системами и данными позволяет нашему агенту выполнять более широкий спектр задач, делая это с большей точностью и надежностью. Например, инструменты могут позволить агентам настраивать параметры умного дома, обновлять календари, извлекать информацию о пользователе из базы данных или отправлять электронные письма на основе определенного набора инструкций.
На дату публикации этой статьи существует три основных типа инструментов, с которыми могут взаимодействовать модели Google: Расширения (Extensions), Функции (Functions) и Хранилища данных (Data Stores). Оснащая агентов инструментами, мы раскрываем огромный потенциал для них не только понимать мир, но и действовать в нем, открывая двери для множества новых приложений и возможностей.
Расширения (Extensions)
Самый простой способ понять Расширения — это представить их как стандартизированный мост между API и агентом, позволяющий агентам беспрепятственно выполнять вызовы API независимо от их базовой реализации. Допустим, вы создали агента с целью помочь пользователям бронировать авиабилеты. Вы знаете, что хотите использовать Google Flights API для получения информации о рейсах, но не уверены, как заставить вашего агента делать вызовы к этой конечной точке API.

Рисунок 3. Как Агенты взаимодействуют с Внешними API?
Один из подходов мог бы заключаться в реализации пользовательского кода, который принимал бы входящий запрос пользователя, разбирал бы его на релевантную информацию, а затем делал вызов API. Например, в случае использования для бронирования авиабилетов пользователь может сказать: «Я хочу забронировать рейс из Остина в Цюрих». В этом сценарии наше решение с пользовательским кодом должно было бы извлечь «Остин» и «Цюрих» как релевантные сущности из запроса пользователя перед попыткой выполнить вызов API. Но что произойдет, если пользователь скажет: «Я хочу забронировать рейс в Цюрих» и никогда не укажет город отправления? Вызов API завершится неудачей без необходимых данных, и потребуется реализовать дополнительный код для обработки подобных граничных и угловых случаев. Этот подход не масштабируем и может легко сломаться в любом сценарии, выходящем за рамки реализованного пользовательского кода.
Более устойчивый подход — использовать Расширение (Extension). Расширение устраняет разрыв между агентом и API следующим образом:
- Обучает агента, как использовать конечную точку API, с помощью примеров.
- Обучает агента, какие аргументы или параметры необходимы для успешного вызова конечной точки API.

Рисунок 4. Расширения соединяют Агентов с Внешними API
Расширения могут быть созданы независимо от агента, но должны быть предоставлены как часть конфигурации агента. Агент использует модель и примеры во время выполнения (run time), чтобы решить, какое Расширение, если таковое имеется, подойдет для решения запроса пользователя. Это подчеркивает ключевое преимущество Расширений — их встроенные типы примеров, которые позволяют агенту динамически выбирать наиболее подходящее Расширение для задачи.

Рисунок 5. Отношение 1-ко-многим между Агентами, Расширениями и API
Представьте это так же, как разработчик программного обеспечения решает, какие конечные точки API использовать при решении проблемы пользователя. Если пользователь хочет забронировать авиабилет, разработчик может использовать Google Flights API. Если пользователь хочет узнать, где находится ближайшая кофейня относительно его местоположения, разработчик может использовать Google Maps API. Точно так же стек агент/модель использует набор известных Расширений, чтобы решить, какое из них лучше всего подойдет для запроса пользователя. Если вы хотите увидеть Расширения в действии, вы можете опробовать их в приложении Gemini, перейдя в Настройки > Расширения, а затем включив те, которые хотите протестировать. Например, вы можете включить расширение Google Flights, а затем спросить Gemini: «Покажи мне рейсы из Остина в Цюрих, вылетающие в следующую пятницу».
Примеры Расширений
Чтобы упростить использование Расширений, Google предоставляет несколько готовых расширений, которые можно быстро импортировать в ваш проект и использовать с минимальной настройкой. Например, расширение Code Interpreter в Сниппете 1 позволяет генерировать и запускать код Python из описания на естественном языке.
# Python
import vertexai
import pprint
PROJECT_ID = "ВАШ_PROJECT_ID"
REGION = "us-central1"
vertexai.init(project=PROJECT_ID, location=REGION)
from vertexai.preview.extensions import Extension
extension_code_interpreter = Extension.from_hub("code_interpreter")
CODE_QUERY = """Напиши метод на Python для инвертирования бинарного дерева за время O(n)."""
response = extension_code_interpreter.execute(
operation_id = "generate_and_execute",
operation_params = {"query": CODE_QUERY}
)
print("Сгенерированный код:")
# Используем pprint для вывода сгенерированного кода, если он есть в ответе
# Предполагая, что ключ 'generated_code' существует в ответе
if 'generated_code' in response:
pprint.pprint(response['generated_code'])
else:
pprint.pprint(response) # Выводим весь ответ, если ключ не найден
# Приведенный выше сниппет сгенерирует следующий код.
# ... (оставшаяся часть кода будет на следующей странице)
# Сгенерированный код (начало):
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
Подводя итог, Расширения (Extensions) предоставляют агентам способ воспринимать, взаимодействовать и влиять на внешний мир множеством способов. Выбор и вызов этих Расширений управляются использованием Примеров (Examples), все из которых определяются как часть конфигурации Расширения.
Функции (Functions)
В мире разработки программного обеспечения функции определяются как автономные модули кода, которые выполняют определенную задачу и могут быть повторно использованы по мере необходимости. Когда разработчик пишет программу, он часто создает множество функций для выполнения различных задач. Он также определяет логику того, когда вызывать function_a вместо function_b, а также ожидаемые входные и выходные данные.
Функции работают очень похоже в мире агентов, но мы можем заменить разработчика программного обеспечения моделью. Модель может принять набор известных функций и решить, когда использовать каждую Функцию и какие аргументы ей необходимы на основе ее спецификации. Функции отличаются от Расширений несколькими способами, наиболее примечательными из которых являются:
- Модель выводит Функцию и ее аргументы, но не выполняет живой вызов API.
- Функции выполняются на стороне клиента (client-side), в то время как Расширения выполняются на стороне агента (agent-side).
Используя снова наш пример с Google Flights, простая настройка для функций может выглядеть как пример на Рисунке 7.

Рисунок 7. Как функции взаимодействуют с внешними API?
Обратите внимание, что основное отличие здесь заключается в том, что ни Функция, ни агент не взаимодействуют напрямую с Google Flights API. Так как же на самом деле происходит вызов API?
При использовании функций логика и выполнение вызова фактической конечной точки API переносятся от агента обратно в приложение на стороне клиента, как показано на Рисунке 8 и Рисунке 9 ниже. Это предоставляет разработчику более гранулярный контроль над потоком данных в приложении. Существует множество причин, по которым разработчик может предпочесть использовать функции вместо Расширений, но вот несколько распространенных случаев использования:
- Вызовы API должны выполняться на другом уровне стека приложения, вне прямого потока архитектуры агента (например, система промежуточного ПО, фреймворк фронтенда и т.д.).
- Ограничения безопасности или аутентификации, которые не позволяют агенту вызывать API напрямую (например, API не доступен из интернета или недоступен для инфраструктуры агента).
- Ограничения по времени или порядку операций, которые не позволяют агенту делать вызовы API в реальном времени (т.е. пакетные операции, проверка человеком в цикле и т.д.).
- К ответу API необходимо применить дополнительную логику преобразования данных, которую агент не может выполнить. Например, рассмотрим конечную точку API, которая не предоставляет механизм фильтрации для ограничения количества возвращаемых результатов. Использование Функций на стороне клиента предоставляет разработчику дополнительные возможности для выполнения этих преобразований.
- Разработчик хочет итерировать разработку агента без развертывания дополнительной инфраструктуры для конечных точек API (т.е. Вызов Функций может действовать как "заглушка" (stubbing) для API).
Хотя разница во внутренней архитектуре между двумя подходами незначительна, как видно на Рисунке 8, дополнительный контроль и разделенная зависимость от внешней инфраструктуры делают Вызов Функций привлекательным вариантом для Разработчика.
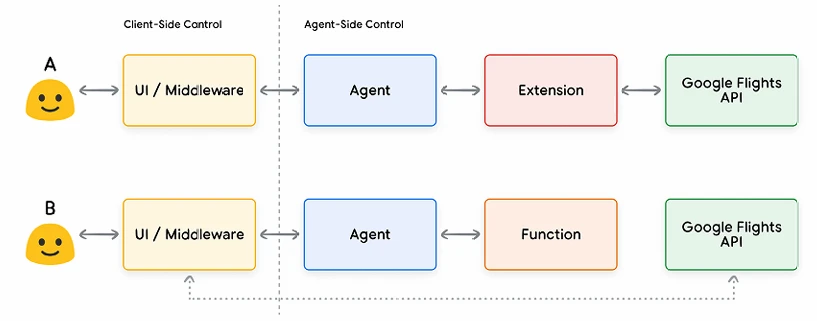
Рисунок 8. Разграничение управления на стороне клиента и на стороне агента для расширений и вызова функций
Варианты использования
Модель может использоваться для вызова функций с целью обработки сложных потоков выполнения на стороне клиента для конечного пользователя, где разработчик агента может не захотеть, чтобы языковая модель управляла выполнением API (как в случае с Расширениями). Рассмотрим следующий пример, где агент обучается как туристический консьерж для взаимодействия с пользователями, которые хотят забронировать поездки на отдых. Цель состоит в том, чтобы агент выдал список городов, который мы можем использовать в нашем приложении промежуточного ПО для загрузки изображений, данных и т.д. для планирования поездки пользователя. Пользователь может сказать что-то вроде:
Я бы хотел поехать покататься на лыжах с семьей, но не уверен, куда.
При типичном промпте к модели вывод мог бы выглядеть следующим образом:
Конечно, вот список городов, которые вы можете рассмотреть для семейного лыжного отдыха:
- Крестед-Бьютт, Колорадо, США
- Уистлер, Британская Колумбия, Канада
- Церматт, Швейцария
Хотя приведенный выше вывод содержит нужные нам данные (названия городов), формат не идеален для парсинга. С помощью Вызова Функций мы можем научить модель форматировать этот вывод в структурированном стиле (например, JSON), который удобнее для парсинга другой системой. Учитывая тот же входной промпт от пользователя, пример вывода JSON из Функции может выглядеть как в Сниппете 5.
function_call {
name: "display_cities"
args: {
"cities": ["Крестед-Бьютт", "Уистлер", "Церматт"],
"preferences": "катание на лыжах"
}
}
Сниппет 5. Пример полезной нагрузки Вызова Функции для отображения списка городов и предпочтений пользователя
Эта полезная нагрузка JSON генерируется моделью, а затем отправляется на наш сервер на стороне клиента, чтобы сделать с ней все, что мы захотим. В данном конкретном случае мы вызовем Google Places API, чтобы взять города, предоставленные моделью, найти Изображения, а затем предоставить их в виде отформатированного богатого контента обратно нашему Пользователю. Рассмотрим эту диаграмму последовательности на Рисунке 9, показывающую вышеуказанное взаимодействие шаг за шагом.
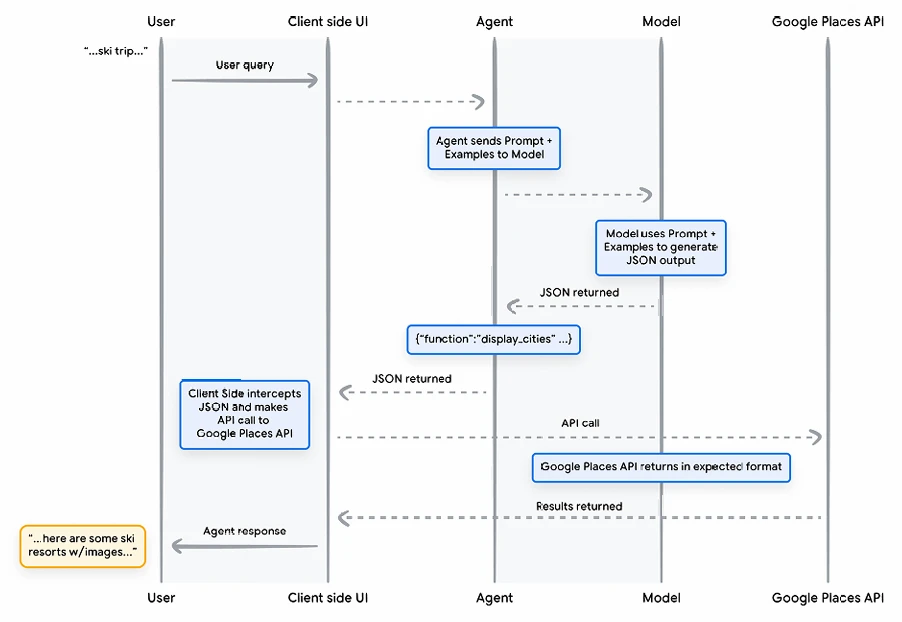
Рисунок 9. Диаграмма последовательности, показывающая жизненный цикл Вызова Функции
Результатом примера на Рисунке 9 является то, что модель используется для "заполнения пробелов" параметрами, необходимыми для того, чтобы UI на стороне клиента мог выполнить вызов Google Places API. UI на стороне клиента управляет фактическим вызовом API, используя параметры, предоставленные моделью в возвращенной Функции. Это всего лишь один вариант использования Вызова Функций, но есть много других сценариев, которые следует рассмотреть, например:
- Вы хотите, чтобы языковая модель предложила функцию, которую вы можете использовать в своем коде, но вы не хотите включать учетные данные в свой код. Поскольку вызов функции не запускает саму функцию, вам не нужно включать учетные данные в ваш код вместе с информацией о функции.
- Вы выполняете асинхронные операции, которые могут занять больше нескольких секунд. Эти сценарии хорошо работают с вызовом функций, потому что это асинхронная операция.
- Вы хотите запускать функции на устройстве, отличном от системы, производящей вызовы функций и их аргументы.
Одна ключевая вещь, которую нужно помнить о функциях, заключается в том, что они предназначены для предоставления разработчику гораздо большего контроля не только над выполнением вызовов API, но и над всем потоком данных в приложении в целом. В примере на Рисунке 9 разработчик решил не возвращать информацию API обратно агенту, поскольку она не имела отношения к будущим действиям, которые мог бы предпринять агент. Однако, в зависимости от архитектуры приложения, может иметь смысл вернуть данные внешнего вызова API агенту, чтобы повлиять на будущие рассуждения, логику и выбор действий. В конечном счете, разработчик приложения должен выбрать то, что подходит для конкретного приложения.
Пример кода для функции
Чтобы достичь описанного выше вывода для нашего сценария лыжного отпуска, давайте создадим каждый из компонентов, чтобы это работало с нашей моделью `gemini-2.0-flash-001`.
Сначала мы определим нашу функцию `display_cities` как простой метод Python.
# Python
from typing import Optional, List
def display_cities(cities: List[str], preferences: Optional[str] = None):
"""Предоставляет список городов на основе поискового запроса и предпочтений пользователя.
Args:
preferences (str): Предпочтения пользователя для поиска, такие как катание на лыжах,
пляж, рестораны, барбекю и т.д.
cities (list[str]): Список городов, рекомендуемых пользователю.
Returns:
list[str]: Список городов, рекомендуемых пользователю.
"""
return cities
Сниппет 6. Пример метода Python для функции, которая будет отображать список городов.
Далее мы создадим экземпляр нашей модели, соберем Инструмент (Tool), а затем передадим запрос пользователя и инструменты в модель. Выполнение приведенного ниже кода приведет к выводу, показанному в нижней части фрагмента кода.
# Python
# Предполагается, что 'google.generativeai' импортирован как 'genai'
# import google.generativeai as genai
# И настроен, например:
# genai.configure(api_key="YOUR_API_KEY")
# Замените на ваш реальный способ инициализации клиента Vertex AI или Generative AI
# Пример для google-cloud-aiplatform (Vertex AI SDK):
# from google.cloud import aiplatform
# import vertexai
# from vertexai.generative_models import GenerativeModel, Tool, FunctionDeclaration, Part
# vertexai.init(project="PROJECT_ID", location="us-central1")
# client = GenerativeModel("gemini-2.0-flash-001") # Или как вы инициализируете
# Пример для google-generativeai (Gemini API):
import google.generativeai as genai
# Замените 'YOUR_API_KEY' на ваш ключ
genai.configure(api_key='YOUR_API_KEY')
# Создаем инструмент из функции Python
display_cities_tool = genai.Tool(
function_declarations=[
genai.FunctionDeclaration.from_func(display_cities)
]
)
client = genai.GenerativeModel(
model_name="gemini-1.5-flash-latest", # Используем актуальную модель
tools=[display_cities_tool]
)
# Используем ChatSession для автоматического управления историей и вызовами функций
chat = client.start_chat(enable_automatic_function_calling=True)
prompt = "Я бы хотел поехать покататься на лыжах с семьей, но не уверен, куда?"
response = chat.send_message(prompt)
# Вывод имени вызванной функции и аргументов
# (при использовании enable_automatic_function_calling=True, SDK обрабатывает это,
# но для демонстрации структуры ответа до обработки SDK:)
# Пример структуры ответа (может отличаться):
# print(response.candidates[0].content.parts[0].function_call)
# >> function_call {
# >> name: "display_cities"
# >> args {
# >> fields {
# >> key: "preferences"
# >> value {
# >> string_value: "катание на лыжах"
# >> }
# >> }
# >> fields {
# >> key: "cities"
# >> value {
# >> list_value {
# >> values { string_value: "Аспен" }
# >> values { string_value: "Парк Сити" }
# >> values { string_value: "Уистлер" }
# >> }
# >> }
# >> }
# >> }
# >> }
# Обычно вы смотрите на response.text после того, как SDK вызвал функцию
print(response.text) # Покажет ответ модели после вызова функции
# Если вы хотите вручную обработать вызов функции (enable_automatic_function_calling=False):
# function_call = response.candidates[0].content.parts[0].function_call
# print(f"Имя функции: {function_call.name}")
# print(f"Аргументы функции: {type(function_call).to_dict(function_call.args)}")
# >> Имя функции: display_cities
# >> Аргументы функции: {'preferences': 'катание на лыжах', 'cities': ['Аспен', 'Парк Сити', 'Уистлер']}
Сниппет 7. Создание Инструмента, отправка его модели с запросом пользователя и разрешение вызова функции.
В заключение, функции предлагают простой фреймворк, который предоставляет разработчикам приложений детальный контроль над потоком данных и выполнением системы, эффективно используя при этом агент/модель для генерации критически важных входных данных. Разработчики могут выборочно решать, оставлять ли агента "в курсе" (in the loop), возвращая внешние данные, или опускать их в зависимости от конкретных требований архитектуры приложения.
Хранилища данных (Data stores)
Представьте языковую модель как обширную библиотеку книг, содержащую ее обучающие данные. Но в отличие от библиотеки, которая постоянно пополняется новыми томами, эта остается статичной, храня только те знания, на которых она была изначально обучена. Это представляет собой проблему, поскольку знания реального мира постоянно развиваются. Хранилища данных решают это ограничение, предоставляя доступ к более динамичной и актуальной информации, а также гарантируя, что ответы модели остаются основанными на фактах и релевантными.
Рассмотрим распространенный сценарий, когда разработчику может потребоваться предоставить модели небольшой объем дополнительных данных, возможно, в виде электронных таблиц или PDF-файлов.
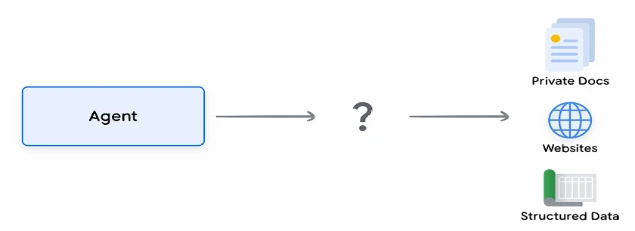
Рисунок 10. Как Агенты могут взаимодействовать со структурированными и неструктурированными данными?
Хранилища данных (Data Stores) позволяют разработчикам предоставлять агенту дополнительные данные в их исходном формате, устраняя необходимость в трудоемких преобразованиях данных, переобучении модели или дообучении (fine-tuning). Хранилище данных преобразует входящий документ в набор векторных представлений (embeddings) в векторной базе данных, которые агент может использовать для извлечения необходимой информации для дополнения своего следующего действия или ответа пользователю.
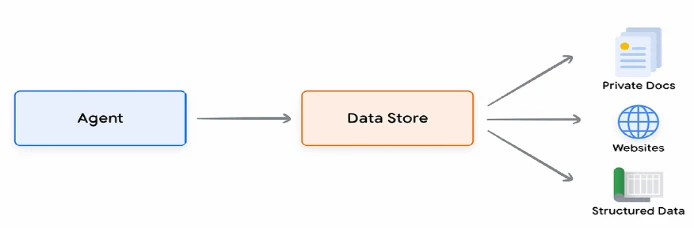
Рисунок 11. Хранилища данных соединяют Агентов с новыми источниками данных реального времени различных типов.
Реализация и применение
В контексте агентов генеративного ИИ, Хранилища данных обычно реализуются как векторная база данных, к которой разработчик хочет предоставить агенту доступ во время выполнения. Хотя мы не будем здесь подробно рассматривать векторные базы данных, ключевым моментом для понимания является то, что они хранят данные в виде векторных представлений (embeddings) — типа многомерного вектора или математического представления предоставленных данных. Одним из наиболее распространенных примеров использования Хранилищ данных с языковыми моделями в последнее время стала реализация приложений на основе Генерации с дополнением извлеченными данными (Retrieval Augmented Generation - RAG).
Эти приложения стремятся расширить широту и глубину знаний модели за пределы фундаментальных обучающих данных, предоставляя модели доступ к данным в различных форматах, таких как:
- Контент веб-сайтов
- Структурированные данные в форматах PDF, Word Docs, CSV, электронных таблиц и т.д.
- Неструктурированные данные в форматах HTML, PDF, TXT и т.д.

Рисунок 12. Отношение 1-ко-многим между агентами и хранилищами данных, которые могут представлять различные типы предварительно проиндексированных данных
Основной процесс для каждого цикла запроса пользователя и ответа агента обычно моделируется так, как показано на Рисунке 13.
- Запрос пользователя отправляется в модель эмбеддингов для генерации эмбеддингов для запроса.
- Эмбеддинги запроса затем сопоставляются с содержимым векторной базы данных с использованием алгоритма сопоставления, такого как ScaNN.
- Соответствующий контент извлекается из векторной базы данных в текстовом формате и отправляется обратно агенту.
- Агент получает как запрос пользователя, так и извлеченный контент, а затем формулирует ответ или действие.
- Окончательный ответ отправляется пользователю.
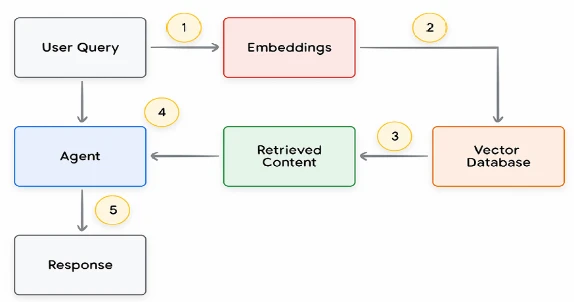
Рисунок 13. Жизненный цикл запроса пользователя и ответа агента в приложении на основе RAG
Конечным результатом является приложение, которое позволяет агенту сопоставить запрос пользователя с известным хранилищем данных с помощью векторного поиска, извлечь исходный контент и предоставить его слою оркестрации и модели для дальнейшей обработки. Следующим действием может быть предоставление окончательного ответа пользователю или выполнение дополнительного векторного поиска для дальнейшего уточнения результатов.
Пример взаимодействия с агентом, реализующим RAG с рассуждением/планированием ReAct, можно увидеть на Рисунке 14.

Рисунок 14. Пример RAG-приложения с рассуждением/планированием ReAct
Итоги по инструментам
Подводя итог, расширения (extensions), функции (functions) и хранилища данных (data stores) составляют несколько различных типов инструментов, доступных для использования агентами во время выполнения. Каждый из них имеет свое назначение, и они могут использоваться вместе или независимо по усмотрению разработчика агента.
| Расширения (Extensions) | Вызов Функций (Function Calling) | Хранилища данных (Data Stores) | |
|---|---|---|---|
| Выполнение | На стороне Агента (Agent-Side) | На стороне Клиента (Client-Side) | На стороне Агента (Agent-Side) |
| Сценарий использования |
|
|
Разработчик хочет реализовать Генерацию с дополнением извлеченными данными (RAG) с любым из следующих типов данных:
|
Улучшение производительности модели с помощью целевого обучения
Ключевым аспектом эффективного использования моделей является их способность выбирать правильные инструменты при генерации вывода, особенно при использовании инструментов в производственных масштабах. Хотя общее обучение помогает моделям развить этот навык, реальные сценарии часто требуют знаний, выходящих за рамки обучающих данных. Представьте себе разницу между базовыми кулинарными навыками и мастерством в определенной кухне. И то, и другое требует фундаментальных кулинарных знаний, но последнее требует целевого обучения для получения более тонких результатов.
Чтобы помочь модели получить доступ к этому типу специфических знаний, существует несколько подходов:
- Обучение в контексте (In-context learning): Этот метод предоставляет обобщенной модели промпт, инструменты и несколько примеров (few-shot examples) во время вывода (inference time), что позволяет ей обучаться 'на лету', как и когда использовать эти инструменты для конкретной задачи. Фреймворк ReAct является примером такого подхода на естественном языке.
- Обучение в контексте на основе извлечения (Retrieval-based in-context learning): Этот метод динамически наполняет промпт модели наиболее релевантной информацией, инструментами и связанными с ними примерами, извлекая их из внешней памяти. Примером этого может служить 'Хранилище примеров' (Example Store) в расширениях Vertex AI или архитектура на основе RAG с хранилищами данных, упомянутая ранее.
- Обучение на основе дообучения (Fine-tuning based learning): Этот метод включает обучение модели с использованием большего набора конкретных примеров перед выводом. Это помогает модели понять, когда и как применять определенные инструменты до получения каких-либо запросов пользователя.
Чтобы предоставить дополнительные сведения о каждом из подходов целевого обучения, давайте вернемся к нашей кулинарной аналогии.
- Представьте, что шеф-повар получил конкретный рецепт (промпт), несколько ключевых ингредиентов (релевантные инструменты) и несколько примеров блюд (few-shot examples) от клиента. Основываясь на этой ограниченной информации и общих кулинарных знаниях шеф-повара, ему нужно будет придумать, как приготовить блюдо 'на лету', которое наиболее точно соответствует рецепту и предпочтениям клиента. Это обучение в контексте (in-context learning).
- Теперь представим нашего шеф-повара на кухне с хорошо укомплектованной кладовой (внешние хранилища данных), заполненной различными ингредиентами и кулинарными книгами (примеры и инструменты). Шеф-повар теперь может динамически выбирать ингредиенты и кулинарные книги из кладовой и лучше соответствовать рецепту и предпочтениям клиента. Это позволяет шеф-повару создать более информированное и изысканное блюдо, используя как существующие, так и новые знания. Это обучение в контексте на основе извлечения (retrieval-based in-context learning).
- Наконец, представим, что мы отправили нашего шеф-повара обратно в школу, чтобы изучить новую кухню или набор кухонь (предварительное обучение на большем наборе конкретных примеров). Это позволяет шеф-повару подходить к будущим невиданным рецептам клиентов с более глубоким пониманием. Этот подход идеален, если мы хотим, чтобы шеф-повар преуспел в определенных кухнях (областях знаний). Это обучение на основе дообучения (fine-tuning based learning).
Каждый из этих подходов предлагает уникальные преимущества и недостатки с точки зрения скорости, стоимости и задержки. Однако, комбинируя эти методы в рамках фреймворка агента, мы можем использовать различные сильные стороны и минимизировать их слабые стороны, что позволяет создать более надежное и адаптируемое решение.
Быстрый старт с агентом на LangChain
Чтобы предоставить реальный исполняемый пример агента в действии, мы создадим быстрый прототип с использованием библиотек LangChain и LangGraph. Эти популярные библиотеки с открытым исходным кодом позволяют пользователям создавать клиентских агентов путем "связывания" последовательностей логики, рассуждений и вызовов инструментов для ответа на запрос пользователя. Мы будем использовать нашу модель gemini-1.5-flash-latest (или аналогичную актуальную) и несколько простых инструментов для ответа на многоэтапный запрос пользователя, как показано в Сниппете 8.
Инструменты, которые мы используем, — это SerpAPI (для Google Search) и Google Places API. После выполнения нашей программы в Сниппете 8 вы можете увидеть пример вывода в Сниппете 9.
# Python
import os
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from langchain_community.utilities import SerpAPIWrapper
from langchain_community.tools import GooglePlacesTool
# Замените на актуальный импорт для Gemini через LangChain
# Пример: from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_google_vertexai import ChatVertexAI # Или ChatGoogleGenerativeAI
# Установите ваши API ключи как переменные окружения
# os.environ["SERPAPI_API_KEY"] = "XXXXX"
# os.environ["GPLACES_API_KEY"] = "XXXXX"
# os.environ["GOOGLE_API_KEY"] = "YOUR_GOOGLE_API_KEY" # Для ChatGoogleGenerativeAI
# Или настройте аутентификацию для Vertex AI
@tool
def search(query: str):
"""Используйте SerpAPI для выполнения поиска Google."""
search_wrapper = SerpAPIWrapper()
return search_wrapper.run(query)
@tool
def places(query: str):
"""Используйте Google Places API для выполнения запроса Google Places."""
places_tool = GooglePlacesTool()
return places_tool.run(query)
# Используйте актуальную модель Gemini
# model = ChatGoogleGenerativeAI(model="gemini-1.5-flash-latest")
model = ChatVertexAI(model_name="gemini-1.5-flash-latest") # Для Vertex AI
tools = [search, places]
query = "С кем играли Texas Longhorns в футбол на прошлой неделе? Какой адрес стадиона другой команды?"
# Создаем ReAct агента
agent_executor = create_react_agent(model, tools)
# Запускаем агента (пример использования .stream для LangGraph >= 0.1.0)
# Входной формат может немного отличаться в зависимости от версии
inputs = {"messages": [("human", query)]}
for s in agent_executor.stream(inputs, stream_mode="values"):
message = s["messages"][-1]
if isinstance(message, tuple):
# В LangGraph это обычно не кортеж, а объект BaseMessage
# Этот блок может не понадобиться или потребовать адаптации
print(message)
else:
# Используем встроенный метод pretty_print для сообщений LangChain/LangGraph
message.pretty_print()
Сниппет 8. Пример агента на основе LangChain и LangGraph с инструментами
================================ Human Message =================================
С кем играли Texas Longhorns в футбол на прошлой неделе? Какой адрес стадиона другой команды?
================================== Ai Message ==================================
Invoking: `search` with `{'query': 'Texas Longhorns football game last week'}`
responded: [{'tool_call_id': '...', 'tool_name': 'search', 'tool_args': {'query': 'Texas Longhorns football game last week'}, 'log': "\nInvoking: `search` with `{'query': 'Texas Longhorns football game last week'}`\n"}]
================================= Tool Message =================================
Name: search
Texas Longhorns played against the Georgia Bulldogs last week. {Results may vary based on actual search}
================================== Ai Message ==================================
Texas Longhorns играли против Georgia Bulldogs на прошлой неделе.
Invoking: `places` with `{'query': 'Georgia Bulldogs stadium address'}`
responded: [{'tool_call_id': '...', 'tool_name': 'places', 'tool_args': {'query': 'Georgia Bulldogs stadium address'}, 'log': "\nInvoking: `places` with `{'query': 'Georgia Bulldogs stadium address'}`\n"}]
================================= Tool Message =================================
Name: places
Sanford Stadium Address: 100 Sanford Dr, Athens, GA 30602, USA {Results may vary based on actual search}
================================== Ai Message ==================================
Адрес стадиона Georgia Bulldogs: 100 Sanford Dr, Athens, GA 30602, USA.
Сниппет 9. Вывод нашей программы из Сниппета 8 (примерный, может отличаться)
Хотя это довольно простой пример агента, он демонстрирует работу основополагающих компонентов — Модели, Оркестрации и инструментов — для достижения конкретной цели. В заключительном разделе мы рассмотрим, как эти компоненты объединяются в управляемых продуктах Google масштаба, таких как агенты Vertex AI и Generative Playbooks.
Производственные приложения с агентами Vertex AI
Хотя в этом документе были рассмотрены основные компоненты агентов, создание приложений производственного уровня требует их интеграции с дополнительными инструментами, такими как пользовательские интерфейсы, фреймворки оценки и механизмы непрерывного улучшения. Платформа Google Vertex AI упрощает этот процесс, предлагая полностью управляемую среду со всеми фундаментальными элементами, рассмотренными ранее. Используя интерфейс на естественном языке, разработчики могут быстро определить ключевые элементы своих агентов — цели, инструкции по задачам, инструменты, подагентов для делегирования задач и примеры — чтобы легко построить желаемое поведение системы. Кроме того, платформа поставляется с набором инструментов разработки, которые позволяют тестировать, оценивать, измерять производительность агента, отлаживать и улучшать общее качество разработанных агентов. Это позволяет разработчикам сосредоточиться на создании и уточнении своих агентов, в то время как сложности инфраструктуры, развертывания и обслуживания управляются самой платформой.
На Рисунке 15 мы предоставили пример архитектуры агента, который был построен на платформе Vertex AI с использованием различных функций, таких как Vertex AI Agent Builder, Vertex AI Extensions, Vertex AI Function Calling и Vertex AI Example Store, и это лишь некоторые из них. Архитектура включает многие из различных компонентов, необходимых для готового к производству приложения.
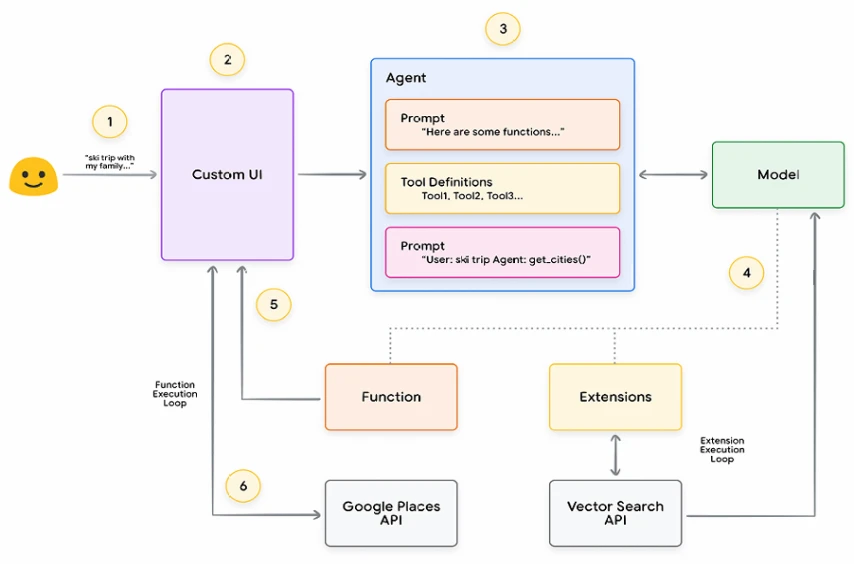
Рисунок 15. Пример сквозной архитектуры агента, построенной на платформе Vertex AI
Вы можете попробовать пример этой готовой архитектуры агента из нашей официальной документации.
Резюме
В этом документе мы обсудили основополагающие строительные блоки агентов генеративного ИИ, их состав и эффективные способы их реализации в виде когнитивных архитектур. Некоторые ключевые выводы из этого документа включают:
- Агенты расширяют возможности языковых моделей, используя инструменты для доступа к информации в реальном времени, предложения действий в реальном мире, а также автономного планирования и выполнения сложных задач. Агенты могут использовать одну или несколько языковых моделей для принятия решений о том, когда и как переходить между состояниями, и использовать внешние инструменты для выполнения любого количества сложных задач, которые было бы трудно или невозможно выполнить модели самостоятельно.
- В основе работы агента лежит слой оркестрации, когнитивная архитектура, которая структурирует рассуждения, планирование, принятие решений и направляет его действия. Различные методы рассуждения, такие как ReAct, Chain-of-Thought и Tree-of-Thoughts, предоставляют фреймворк для слоя оркестрации для приема информации, выполнения внутренних рассуждений и генерации обоснованных решений или ответов.
- Инструменты, такие как Расширения (Extensions), Функции (Functions) и Хранилища данных (Data Stores), служат ключами к внешнему миру для агентов, позволяя им взаимодействовать с внешними системами и получать доступ к знаниям за пределами их обучающих данных. Расширения обеспечивают мост между агентами и внешними API, позволяя выполнять вызовы API и извлекать информацию в реальном времени. Функции обеспечивают более тонкий контроль для разработчика за счет разделения труда, позволяя агентам генерировать параметры Функций, которые могут выполняться на стороне клиента. Хранилища данных предоставляют агентам доступ к структурированным или неструктурированным данным, обеспечивая создание приложений, управляемых данными (data-driven applications).
Будущее агентов таит в себе захватывающие достижения, и мы только начали царапать поверхность того, что возможно. По мере того как инструменты становятся более сложными, а возможности рассуждения улучшаются, агенты будут уполномочены решать все более сложные проблемы. Кроме того, стратегический подход 'связывания агентов' (agent chaining) будет продолжать набирать обороты.
Комбинируя специализированных агентов — каждый из которых преуспевает в определенной области или задаче — мы можем создать подход 'смеси экспертов-агентов' (mixture of agent experts), способный достигать исключительных результатов в различных отраслях и проблемных областях.
Важно помнить, что создание сложных архитектур агентов требует итеративного подхода. Экспериментирование и уточнение являются ключом к поиску решений для конкретных бизнес-кейсов и организационных потребностей. Не существует двух одинаковых агентов из-за генеративной природы фундаментальных моделей, лежащих в основе их архитектуры. Однако, используя сильные стороны каждого из этих основополагающих компонентов, мы можем создавать впечатляющие приложения, которые расширяют возможности языковых моделей и приносят реальную пользу.
Примечания
- Shafran, I., Cao, Y. et al., 2022, 'ReAct: Synergizing Reasoning and Acting in Language Models'. Доступно по адресу: https://arxiv.org/abs/2210.03629
- Wei, J., Wang, X. et al., 2023, 'Chain-of-Thought Prompting Elicits Reasoning in Large Language Models'. Доступно по адресу: https://arxiv.org/pdf/2201.11903.pdf.
- Wang, X. et al., 2022, 'Self-Consistency Improves Chain of Thought Reasoning in Language Models'. Доступно по адресу: https://arxiv.org/abs/2203.11171.
- Diao, S. et al., 2023, 'Active Prompting with Chain-of-Thought for Large Language Models'. Доступно по адресу: https://arxiv.org/pdf/2302.12246.pdf.
- Zhang, H. et al., 2023, 'Multimodal Chain-of-Thought Reasoning in Language Models'. Доступно по адресу: https://arxiv.org/abs/2302.00923.
- Yao, S. et al., 2023, 'Tree of Thoughts: Deliberate Problem Solving with Large Language Models'. Доступно по адресу: https://arxiv.org/abs/2305.10601.
- Long, X., 2023, 'Large Language Model Guided Tree-of-Thought'. Доступно по адресу: https://arxiv.org/abs/2305.08291.
- Google. 'Приложение Google Gemini'. Доступно по адресу: http://gemini.google.com.
- Swagger. 'Спецификация OpenAPI'. Доступно по адресу: https://swagger.io/specification/.
- Xie, M., 2022, 'Как работает обучение в контексте? Фреймворк для понимания отличий от традиционного контролируемого обучения'. Доступно по адресу: https://ai.stanford.edu/blog/understanding-incontext/.
- Google Research. 'ScaNN (Scalable Nearest Neighbors)'. Доступно по адресу: https://github.com/google-research/google-research/tree/master/scann.
- LangChain. 'LangChain'. Доступно по адресу: https://python.langchain.com/v0.2/docs/introduction/.
Другие статьи по этой теме:
- Полное руководство по разговорному ИИ с Dialogflow и Google Cloud
- Практическое руководство по созданию агентов ИИ
- Выявление и масштабирование сценариев использования ИИ