Глава 8. Продвинутая практика
Эта глава содержит описание техник, которые могут быть полезны в вашей практике в некоторых контекстах. Она называется «Продвинутая практика» не потому, что представленные техники более сложны, а скорее потому, что они применяются в очень специфических контекстах. Во многих практических ситуациях вам, скорее всего, не понадобится прибегать к использованию этих техник, но иногда они очень полезны.
8.1 Работа с несбалансированными наборами данных
Часто на практике примеры некоторого класса будут недопредставлены в ваших обучающих данных. Это случай, например, когда ваш классификатор должен различать подлинные и мошеннические транзакции электронной коммерции: примеры подлинных транзакций встречаются гораздо чаще. Если вы используете SVM с мягким зазором, вы можете определить стоимость для неправильно классифицированных примеров. Поскольку шум всегда присутствует в обучающих данных, существует высокая вероятность того, что многие примеры подлинных транзакций окажутся по неправильную сторону границы принятия решений, внося свой вклад в стоимость.
См. Рисунок 1 .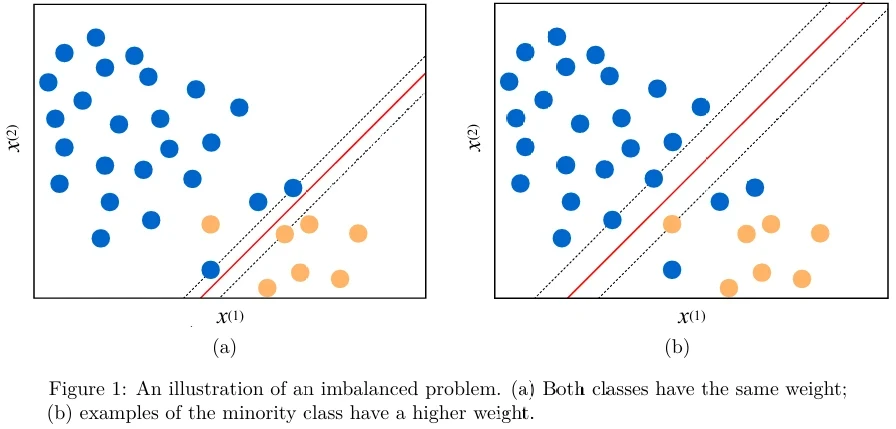
Алгоритм SVM пытается сдвинуть гиперплоскость, чтобы избежать неправильно классифицированных примеров как можно больше. «Мошеннические» примеры, которые находятся в меньшинстве, рискуют быть неправильно классифицированными, чтобы правильно классифицировать более многочисленные примеры мажоритарного класса. Эта ситуация иллюстрируется на Рисунке 1a (в pdf). Эта проблема наблюдается для большинства алгоритмов обучения, применяемых к несбалансированным наборам данных (imbalanced datasets).
Если вы установите стоимость неправильной классификации примеров миноритарного класса выше, то модель будет стараться избегать неправильной классификации этих примеров, но это приведет к стоимости неправильной классификации некоторых примеров мажоритарного класса, как показано на Рисунке 1b (в pdf).
Некоторые реализации SVM позволяют вам предоставлять веса для каждого класса. Алгоритм обучения учитывает эту информацию при поиске наилучшей гиперплоскости.
Если алгоритм обучения не позволяет взвешивать классы, вы можете попробовать технику увеличения выборки (oversampling). Она заключается в увеличении важности примеров некоторого класса путем создания нескольких копий примеров этого класса.
Противоположный подход, уменьшение выборки (undersampling), заключается в случайном удалении из обучающего набора некоторых примеров мажоритарного класса.
Вы также можете попробовать создать синтетические примеры путем случайной выборки значений признаков нескольких примеров миноритарного класса и их комбинирования для получения нового примера этого класса. Существуют два популярных алгоритма, которые увеличивают выборку миноритарного класса путем создания синтетических примеров: техника синтетического увеличения выборки миноритарного класса (SMOTE) и метод адаптивной синтетической выборки (ADASYN).
SMOTE и ADASYN работают во многом схожим образом. Для данного примера \(x_i\) миноритарного класса они выбирают \(k\) ближайших соседей этого примера (обозначим этот набор из \(k\) примеров \(\mathcal{S}_k\)), а затем создают синтетический пример \(x_{new}\) как \(x_i + \lambda(x_{zi} - x_i)\), где \(x_{zi}\) — пример миноритарного класса, выбранный случайным образом из \(\mathcal{S}_k\). Гиперпараметр интерполяции \(\lambda\) — это случайное число в диапазоне \([0, 1]\).
И SMOTE, и ADASYN случайным образом выбирают все возможные \(x_i\) в наборе данных. В ADASYN количество синтетических примеров, сгенерированных для каждого \(x_i\), пропорционально количеству примеров в \(\mathcal{S}_k\), которые не принадлежат к миноритарному классу. Следовательно, больше синтетических примеров генерируется в области, где примеры миноритарного класса редки.
Некоторые алгоритмы менее чувствительны к проблеме несбалансированного набора данных. Деревья решений, а также случайный лес и градиентный бустинг, часто хорошо работают на несбалансированных наборах данных.
8.2 Комбинирование моделей
Ансамблевые алгоритмы, такие как случайный лес, обычно комбинируют модели одного типа. Они повышают производительность, комбинируя сотни слабых моделей. На практике мы иногда можем получить дополнительный прирост производительности, комбинируя сильные модели, созданные с использованием разных алгоритмов обучения. В этом случае мы обычно используем только две или три модели.
Три типичных способа комбинирования моделей: 1) усреднение (averaging), 2) голосование большинством (majority vote) и 3) стекинг (stacking).
Усреднение работает для регрессии, а также для тех моделей классификации, которые возвращают оценки классификации. Вы просто применяете все ваши модели — назовем их базовыми моделями (base models) — к входу \(x\), а затем усредняете предсказания. Чтобы увидеть, работает ли усредненная модель лучше, чем каждый отдельный алгоритм, вы тестируете ее на валидационном наборе, используя выбранную вами метрику.
Голосование большинством работает для моделей классификации. Вы применяете все свои базовые модели к входу \(x\), а затем возвращаете класс большинства среди всех предсказаний. В случае ничьей вы либо случайным образом выбираете один из классов, либо возвращаете сообщение об ошибке (если факт неправильной классификации повлечет за собой значительные издержки).
Стекинг заключается в построении метамодели (meta-model), которая принимает выходные данные базовых моделей в качестве входа. Допустим, вы хотите скомбинировать классификаторы \(f_1\) и \(f_2\), оба предсказывающие один и тот же набор классов. Чтобы создать обучающий пример \((\hat{\mathbf{x}}_i, \hat{y}_i)\) для стекированной модели, установите \(\hat{\mathbf{x}}_i = [f_1(\mathbf{x}), f_2(\mathbf{x})]\) и \(\hat{y}_i = y_i\).
Если некоторые из ваших базовых моделей возвращают не только класс, но и оценку для каждого класса, вы также можете использовать эти значения в качестве признаков.
Для обучения стекированной модели рекомендуется использовать примеры из обучающего набора и настраивать гиперпараметры стекированной модели с использованием перекрестной проверки.
Очевидно, вы должны убедиться, что ваша стекированная модель работает лучше на валидационном наборе, чем каждая из базовых моделей, которые вы стекировали.
Причина, по которой комбинирование нескольких моделей может привести к лучшей производительности, заключается в том, что когда несколько некоррелированных (uncorrelated) сильных моделей согласны, они с большей вероятностью согласятся на правильном результате. Ключевое слово здесь — «некоррелированные». В идеале базовые модели должны быть получены с использованием разных признаков или с использованием алгоритмов разной природы — например, SVM и случайного леса. Комбинирование различных версий алгоритма обучения деревьев решений или нескольких SVM с разными гиперпараметрами может не привести к значительному повышению производительности.
8.3 Обучение нейронных сетей
При обучении нейронных сетей одним сложным аспектом является преобразование ваших данных во входные данные, с которыми может работать сеть. Если ваш вход — это изображения, прежде всего, вы должны изменить размер всех изображений так, чтобы они имели одинаковые размеры. После этого пиксели обычно сначала стандартизируются, а затем нормализуются в диапазон \([0, 1]\).
Тексты должны быть токенизированы (tokenized) (то есть разделены на части, такие как слова, знаки препинания и другие символы). Для CNN и RNN каждый токен преобразуется в вектор с использованием one-hot кодирования (one-hot encoding), так что текст становится списком one-hot векторов. Другой, часто лучший способ представления токенов — использование вложений слов (word embeddings). Для многослойного перцептрона, чтобы преобразовать тексты в векторы, подход мешка слов (bag of words) может хорошо работать, особенно для больших текстов (больше, чем SMS-сообщения и твиты).
Выбор конкретной архитектуры нейронной сети — сложная задача. Для одной и той же проблемы, такой как обучение seq2seq, существует множество архитектур, и новые предлагаются почти каждый год. Я рекомендую исследовать современные решения для вашей проблемы с использованием поисковых систем Google Scholar или Microsoft Academic, которые позволяют искать научные публикации по ключевым словам и временному диапазону. Если вы не против работать с менее современными архитектурами, я рекомендую искать реализованные архитектуры на GitHub и находить ту, которая может быть применена к вашим данным с незначительными модификациями.
На практике преимущество современной архитектуры перед более старой становится менее значительным по мере того, как вы предварительно обрабатываете, очищаете и нормализуете свои данные и создаете больший обучающий набор. Современные архитектуры нейронных сетей являются результатом сотрудничества ученых из нескольких лабораторий и компаний; такие модели могут быть очень сложными для реализации самостоятельно и обычно требуют большой вычислительной мощности для обучения. Время, потраченное на попытку воспроизвести результаты из недавней научной статьи, может не стоить того. Это время лучше потратить на построение решения на основе менее современной, но стабильной модели и получение большего количества обучающих данных.
Как только вы определились с архитектурой вашей сети, вы должны решить количество слоев, их тип и размер. Рекомендуется начать с одного или двух слоев, обучить модель и посмотреть, хорошо ли она подходит к обучающим данным (имеет низкое смещение). Если нет, постепенно увеличивайте размер каждого слоя и количество слоев, пока модель не будет идеально подходить к обучающим данным. Как только это произойдет, если модель плохо работает на валидационных данных (имеет высокую дисперсию), вы должны добавить регуляризацию к вашей модели. Если после добавления регуляризации модель больше не подходит к обучающим данным, немного увеличьте размер сети. Продолжайте итеративно, пока модель не будет достаточно хорошо подходить как к обучающим, так и к валидационным данным согласно вашей метрике.
8.4 Продвинутая регуляризация
В нейронных сетях, помимо L1 и L2 регуляризации, вы можете использовать специфические для нейронных сетей регуляризаторы: dropout, раннюю остановку (early stopping) и пакетную нормализацию (batch-normalization). Последняя технически не является техникой регуляризации, но часто оказывает регуляризующий эффект на модель.
Концепция dropout очень проста. Каждый раз, когда вы пропускаете обучающий пример через сеть, вы временно исключаете случайным образом некоторые блоки из вычислений. Чем выше процент исключенных блоков, тем выше эффект регуляризации. Библиотеки нейронных сетей позволяют вам добавить слой dropout между двумя последовательными слоями, или вы можете указать параметр dropout для слоя. Параметр dropout находится в диапазоне \([0, 1]\) и должен быть найден экспериментально путем настройки на валидационных данных.
Ранняя остановка — это способ обучения нейронной сети путем сохранения предварительной модели после каждой эпохи и оценки производительности предварительной модели на валидационном наборе. Как вы помните из раздела о градиентном спуске в Главе 4, по мере увеличения числа эпох стоимость уменьшается. Уменьшенная стоимость означает, что модель хорошо подходит к обучающим данным. Однако в какой-то момент, после некоторой эпохи \(e\), модель может начать переобучаться: стоимость продолжает уменьшаться, но производительность модели на валидационных данных ухудшается. Если вы храните в файле версию модели после каждой эпохи, вы можете остановить обучение, как только начнете наблюдать снижение производительности на валидационном наборе. В качестве альтернативы вы можете продолжать запускать процесс обучения на фиксированное количество эпох, а затем, в конце, выбрать лучшую модель. Модели, сохраненные после каждой эпохи, называются контрольными точками (checkpoints). Некоторые практики машинного обучения очень часто полагаются на эту технику; другие пытаются правильно регуляризовать модель, чтобы избежать такого нежелательного поведения.
Пакетная нормализация (которую скорее следует называть пакетной стандартизацией) — это техника, которая заключается в стандартизации выходов каждого слоя перед тем, как блоки последующего
слоя получат их на вход. На практике пакетная нормализация приводит к более быстрому и стабильному обучению, а также к некоторому эффекту регуляризации. Так что всегда хорошая идея попробовать использовать пакетную нормализацию. В библиотеках нейронных сетей часто можно вставить слой пакетной нормализации между двумя слоями.
Другая техника регуляризации, которая может быть применена не только к нейронным сетям, но и практически к любому алгоритму обучения, называется аугментацией данных (data augmentation). Эта техника часто используется для регуляризации моделей, работающих с изображениями. Как только у вас есть исходный размеченный обучающий набор, вы можете создать синтетический пример из исходного примера, применяя различные преобразования к исходному изображению: немного увеличивая его масштаб, поворачивая, отражая, затемняя и так далее. Вы сохраняете исходную метку в этих синтетических примерах. На практике это часто приводит к повышению производительности модели.
8.5 Обработка нескольких входов
Часто на практике вы будете работать с мультимодальными данными (multimodal data). Например, ваш вход может быть изображением и текстом, а бинарный выход может указывать, описывает ли текст это изображение.
Трудно адаптировать поверхностные алгоритмы обучения для работы с мультимодальными данными. Однако это не невозможно. Вы могли бы обучить одну поверхностную модель на изображении, а другую — на тексте. Затем вы можете использовать технику комбинирования моделей, которую мы обсуждали выше.
Если вы не можете разделить свою проблему на две независимые подзадачи, вы можете попытаться векторизовать каждый вход (применив соответствующий метод инженерии признаков), а затем просто объединить два вектора признаков вместе, чтобы сформировать один более широкий вектор признаков. Например, если ваше изображение имеет признаки \([i^{(1)}, i^{(2)}, i^{(3)}]\), а ваш текст имеет признаки \([t^{(1)}, t^{(2)}, t^{(3)}, t^{(4)}]\), ваш объединенный вектор признаков будет \([i^{(1)}, i^{(2)}, i^{(3)}, t^{(1)}, t^{(2)}, t^{(3)}, t^{(4)}]\).
С нейронными сетями у вас больше гибкости. Вы можете построить две подсети, по одной для каждого типа входа. Например, подсеть CNN будет читать изображение, а подсеть RNN — текст. Обе подсети имеют в качестве последнего слоя вложение: CNN имеет вложение изображения, а RNN — вложение текста. Теперь вы можете объединить два вложения, а затем добавить слой классификации, такой как softmax или sigmoid, поверх объединенных вложений. Библиотеки нейронных сетей предоставляют простые в использовании инструменты, которые позволяют объединять или усреднять слои из нескольких подсетей.
8.6 Обработка нескольких выходов
В некоторых задачах вы хотели бы предсказать несколько выходов для одного входа. Мы рассматривали многометочную классификацию в предыдущей главе. Некоторые задачи с несколькими выходами могут быть эффективно преобразованы в задачу многометочной классификации. Особенно те, которые имеют метки одного типа (например, теги) или поддельные метки могут быть созданы как полное перечисление комбинаций исходных меток.
Однако в некоторых случаях выходы являются мультимодальными, и их комбинации не могут быть эффективно перечислены. Рассмотрим следующий пример: вы хотите построить модель, которая обнаруживает объект на изображении и возвращает его координаты. Кроме того, модель должна возвращать тег, описывающий объект, например, «человек», «кошка» или «хомяк». Ваш обучающий пример будет вектором признаков, представляющим изображение. Метка будет представлена как вектор координат объекта и другой вектор с one-hot кодированным тегом.
Чтобы справиться с такой ситуацией, вы можете создать одну подсеть, которая будет работать как кодировщик. Она будет считывать входное изображение, используя, например, один или несколько сверточных слоев. Последним слоем кодировщика будет вложение изображения. Затем вы добавляете две другие подсети поверх слоя вложения: одна принимает вектор вложения на вход и предсказывает координаты объекта. Эта первая подсеть может иметь ReLU в качестве последнего слоя, что является хорошим выбором для предсказания положительных вещественных чисел, таких как координаты; эта подсеть может использовать стоимость среднеквадратичной ошибки \(C_1\). Вторая подсеть будет принимать тот же вектор вложения на вход и предсказывать вероятности для каждого тега. Эта вторая подсеть может иметь softmax в качестве последнего слоя, что подходит для вероятностного вывода, и использовать усредненную стоимость отрицательного логарифма правдоподобия \(C_2\) (также называемую стоимостью перекрестной энтропии (cross-entropy cost)).
Очевидно, вы заинтересованы как в точно предсказанных координатах, так и в тегах. Однако невозможно оптимизировать две функции стоимости одновременно. Пытаясь оптимизировать одну, вы рискуете ухудшить вторую, и наоборот. Что вы можете сделать, это добавить еще один гиперпараметр \(\gamma\) в диапазоне \((0, 1)\) и определить комбинированную функцию стоимости как \(\gamma C_1 + (1-\gamma)C_2\). Затем вы настраиваете значение \(\gamma\) на валидационных данных так же, как любой другой гиперпараметр.
8.7 Перенос обучения
Перенос обучения (Transfer learning) — это, вероятно, то, где нейронные сети имеют уникальное преимущество перед поверхностными моделями. При переносе обучения вы выбираете существующую модель, обученную на некотором наборе данных, и адаптируете эту модель для предсказания примеров из другого набора данных, отличного от того, на котором была построена модель. Этот второй набор данных не похож на отложенные наборы, которые вы используете для валидации и тестирования. Он может представлять какое-то другое явление, или, как говорят ученые в области машинного обучения, он может происходить из другого статистического распределения.
Например, представьте, что вы обучили свою модель распознавать (и размечать) диких животных на большом размеченном наборе данных. Через некоторое время у вас возникает другая проблема: вам нужно построить модель, которая распознавала бы домашних животных. С поверхностными алгоритмами обучения у вас не так много вариантов: вам нужно построить еще один большой размеченный набор данных, теперь для домашних животных.
С нейронными сетями ситуация гораздо более благоприятная. Перенос обучения в нейронных сетях работает так:
- Вы строите глубокую модель на исходном большом наборе данных (дикие животные).
- Вы собираете гораздо меньший размеченный набор данных для вашей второй модели (домашние животные).
- Вы удаляете последний один или несколько слоев из первой модели. Обычно это слои, отвечающие за классификацию или регрессию; они обычно следуют за слоем вложения.
- Вы заменяете удаленные слои новыми слоями, адаптированными для вашей новой проблемы.
- Вы «замораживаете» параметры слоев, оставшихся от первой модели.
- Вы используете свой меньший размеченный набор данных и градиентный спуск для обучения параметров только новых слоев.
Обычно в сети имеется множество глубоких моделей для визуальных задач, доступных онлайн. Вы можете найти ту, которая имеет высокие шансы быть полезной для вашей проблемы, загрузить эту модель, удалить несколько последних слоев (количество слоев для удаления является гиперпараметром), добавить свои собственные слои предсказания и обучить свою модель.
Даже если у вас нет существующей модели, перенос обучения все равно может помочь вам в ситуациях, когда ваша проблема требует размеченного набора данных, который очень дорого получить, но вы можете получить другой набор данных, для которого метки более легко доступны. Допустим, вы строите модель классификации документов. Вы получили таксономию меток от своего работодателя, и она содержит тысячу категорий. В этом случае вам нужно будет заплатить кому-то, чтобы а) прочитать, понять и запомнить различия между категориями и б) прочитать до миллиона документов и аннотировать их.
Чтобы сэкономить на разметке такого большого количества примеров, вы могли бы рассмотреть возможность использования страниц Википедии в качестве набора данных для построения вашей первой модели. Метки для страницы Википедии можно получить автоматически, взяв категорию, к которой принадлежит страница Википедии. Как только ваша первая модель научится предсказывать категории Википедии, вы можете «дообучить» (fine tune) эту модель для предсказания категорий таксономии вашего работодателя. Вам понадобится гораздо меньше аннотированных примеров для проблемы вашего работодателя, чем вам понадобилось бы, если бы вы начали решать свою исходную проблему с нуля.
8.8 Алгоритмическая эффективность
Не все алгоритмы, способные решить проблему, практичны. Некоторые могут быть слишком медленными. Некоторые проблемы могут быть решены быстрым алгоритмом; для других быстрых алгоритмов может не существовать.
Подраздел компьютерных наук, называемый анализом алгоритмов (analysis of algorithms), занимается определением и сравнением сложности (complexity) алгоритмов. О-нотация (Big O notation) используется для классификации алгоритмов в соответствии с тем, как их время выполнения или требования к пространству растут по мере роста размера входа.
Например, допустим, у нас есть проблема нахождения двух наиболее удаленных одномерных примеров в множестве примеров \(\mathcal{S}\) размера \(N\). Один алгоритм, который мы могли бы разработать для решения этой проблемы, выглядел бы так (здесь и ниже, на Python):
1 def find_max_distance(S):
2 result = None
3 max_distance = 0
4 for x1 in S:
5 for x2 in S:
6 if abs(x1 - x2) >= max_distance:
7 max_distance = abs(x1 - x2)
8 result = (x1, x2)
9 return result
В приведенном выше алгоритме мы проходим по всем значениям в \(\mathcal{S}\), и на каждой итерации первого цикла мы снова проходим по всем значениям в \(\mathcal{S}\). Следовательно, приведенный выше алгоритм выполняет \(N^2\) сравнений чисел. Если мы возьмем за единицу времени время, которое занимают операции сравнения, abs и присваивания, то временная сложность (или просто сложность) этого алгоритма составляет не более \(5N^2\). (На каждой итерации у нас есть одно сравнение, два abs и две операции присваивания.) Когда сложность алгоритма измеряется в худшем случае, используется О-нотация. Для приведенного выше алгоритма, используя О-нотацию, мы пишем, что сложность алгоритма составляет \(O(N^2)\); константы, такие как 5, игнорируются.
Для той же проблемы мы можем разработать другой алгоритм, например:
1 def find_max_distance(S):
2 result = None
3 min_x = float("inf")
4 max_x = float("-inf")
5 for x in S:
6 if x < min_x:
7 min_x = x
8 if x > max_x:
9 max_x = x
10 result = (max_x, min_x)
11 return result
В приведенном выше алгоритме мы проходим по всем значениям в \(\mathcal{S}\) только один раз, поэтому сложность алгоритма составляет \(O(N)\). В этом случае мы говорим, что последний алгоритм более эффективен (more efficient), чем первый.
Алгоритм называется эффективным, если его сложность полиномиальна от размера входа. Следовательно, и \(O(N)\), и \(O(N^2)\) эффективны, потому что \(N\) — это полином степени 1, а \(N^2\) — полином степени 2. Однако для очень больших входов алгоритм \(O(N^2)\) может быть медленным. В эпоху больших данных ученые часто ищут алгоритмы \(O(\log N)\).
С практической точки зрения, при реализации вашего алгоритма вы должны избегать использования циклов, когда это возможно. Например, вы должны использовать операции над матрицами и векторами вместо циклов. В Python для вычисления \(wx\) следует писать,
1 import numpy
2 wx = numpy.dot(w,x)
а не,
1 wx = 0
2 for i in range(N):
3 wx += w[i]*x[i]
Используйте подходящие структуры данных. Если порядок элементов в коллекции не имеет значения, используйте set вместо list. В Python операция проверки принадлежности конкретного примера \(x\) к \(\mathcal{S}\) эффективна, когда \(\mathcal{S}\) объявлено как set, и неэффективна, когда \(\mathcal{S}\) объявлено как list.
Другая важная структура данных, которую вы можете использовать, чтобы сделать ваш код на Python более эффективным, — это dict. В других языках она называется словарем или хэш-картой. Она позволяет вам определять коллекцию пар ключ-значение с очень быстрыми поисками по ключам.
Использование библиотек, как правило, наиболее надежно — вы должны писать свой собственный код только если вы исследователь или это действительно необходимо. Научные пакеты Python, такие как numpy, scipy и scikit-learn, были созданы опытными учеными и инженерами с учетом эффективности. У них много методов, реализованных на языке программирования C для максимальной эффективности.
Если вам нужно итерировать по огромной коллекции элементов, используйте генераторы (generators), которые создают функцию, возвращающую по одному элементу за раз, а не все элементы сразу.
Используйте пакет cProfile в Python для поиска неэффективностей в вашем коде.
Наконец, когда ничего нельзя улучшить в вашем коде с алгоритмической точки зрения, вы можете дополнительно повысить скорость вашего кода, используя:
- пакет
multiprocessingдля запуска вычислений параллельно, и PyPy,Numbaили аналогичные инструменты для компиляции вашего кода на Python в быстрый, оптимизированный машинный код.
Другие статьи по этой теме:
- Маленькая книга о глубоком обучении
- Машинное обучение с помощью Python
- Математика для нейронного обучения