Глава 6. Обработка текста
6.0 Введение
Неструктурированные текстовые данные, такие как содержимое книги или твит, являются как одним из наиболее интересных источников признаков, так и одним из самых сложных в обработке. В этой главе мы рассмотрим стратегии преобразования текста в информационно насыщенные признаки и используем некоторые готовые признаки (называемые встраиваниями), которые становятся все более распространенными в задачах, связанных с обработкой естественного языка (NLP).
Это не означает, что рецепты, представленные здесь, являются всеобъемлющими. Существуют целые академические дисциплины, посвященные обработке неструктурированных данных, таких как текст. В этой главе мы рассмотрим некоторые часто используемые методы, и знание их добавит ценные инструменты в наш инструментарий предварительной обработки. В дополнение к многим общим рецептам обработки текста, мы также покажем, как импортировать и использовать некоторые предварительно обученные модели машинного обучения для генерации более богатых текстовых признаков.
6.1 Очистка текста
Проблема
У вас есть неструктурированные текстовые данные, и вы хотите выполнить базовую очистку.
Решение
В следующем примере мы рассмотрим текст трех книг и очистим его, используя основные строковые операции Python, в частности strip, replace и split:
# Create text
text_data = [" Interrobang. By Aishwarya Henriette ",
"Parking And Going. By Karl Gautier",
" Today Is The night. By Jarek Prakash "]
# Strip whitespaces
strip_whitespace = [string.strip() for string in text_data]
# Show text
strip_whitespace['Interrobang. By Aishwarya Henriette',
'Parking And Going. By Karl Gautier',
'Today Is The night. By Jarek Prakash']# Remove periods
remove_periods = [string.replace(".", "") for string in strip_whitespace]
# Show text
remove_periods['Interrobang By Aishwarya Henriette',
'Parking And Going By Karl Gautier',
'Today Is The night By Jarek Prakash']Мы также создаем и применяем пользовательскую функцию преобразования:
# Create function
def capitalizer(string: str) -> str:
return string.upper()
# Apply function
[capitalizer(string) for string in remove_periods]['INTERROBANG BY AISHWARYA HENRIETTE',
'PARKING AND GOING BY KARL GAUTIER',
'TODAY IS THE NIGHT BY JAREK PRAKASH']Наконец, мы можем использовать регулярные выражения для выполнения мощных строковых операций:
# Import library
import re
# Create function
def replace_letters_with_X(string: str) -> str:
return re.sub(r"[a-zA-Z]", "X", string)
# Apply function
[replace_letters_with_X(string) for string in remove_periods]['XXXXXXXXXXX XX XXXXXXXXX XXXXXXXXX',
'XXXXXXX XXX XXXXX XX XXXX XXXXXXX',
'XXXXX XX XXX XXXXX XX XXXXX XXXXXXX']Обсуждение
Некоторые текстовые данные нужно очистить, прежде чем мы сможем использовать их для построения признаков или предварительной обработки каким-либо образом, прежде чем они будут переданы в алгоритм. Большая часть базовой очистки текста может быть выполнена с использованием стандартных строковых операций Python. В реальном мире мы, скорее всего, определим пользовательскую функцию очистки (например, capitalizer), объединяющую некоторые задачи очистки, и применим ее к текстовым данным. Строки имеют много встроенных методов, которые полезны для очистки и обработки, дополнительные примеры можно найти ниже:
# Define a string
s = "machine learning in python cookbook"
# Find the first index of the letter "n"
find_n = s.find("n")
# Whether or not the string starts with "m"
starts_with_m = s.startswith("m")
# Whether or not the string ends with "python"
ends_with_python = s.endswith("python")
# Is the string alphanumeric
is_alnum = s.isalnum()
# Is it composed of only alphabetical characters (not including spaces)
is_alpha = s.isalpha()
# Encode as utf-8
encode_as_utf8 = s.encode("utf-8")
# Decode the same utf-8
decode = encode_as_utf8.decode("utf-8")
print(find_n, starts_with_m, ends_with_python, is_alnum, is_alpha, encode_as_utf8, decode, sep = "|")5|True|False|False|False|b'machine learning in python cookbook'|machine learning in python cookbookСм. также
Beginners Tutorial for Regular Expressions in Python
6.2 Парсинг и очистка HTML
Проблема
У вас есть текстовые данные с элементами HTML, и вы хотите извлечь только текст.
Решение
Используйте обширный набор опций Beautiful Soup для парсинга и извлечения из HTML:
# Load library
from bs4 import BeautifulSoup
# Create some HTML code
html = """
Masego Azra"
"""
# Parse html
soup = BeautifulSoup(html, "lxml")
# Find the div with the class "full_name", show text
soup.find("div", { "class" : "full_name" }).text'Masego Azra'Обсуждение
Несмотря на странное название, Beautiful Soup — мощная библиотека Python, предназначенная для парсинга HTML. Обычно Beautiful Soup используется для обработки HTML во время живого веб-скрейпинга, но мы можем так же легко использовать ее для извлечения текстовых данных, встроенных в статический HTML. Полный набор операций Beautiful Soup выходит за рамки этой книги, но даже метод, который мы используем в нашем решении, показывает, как легко парсить HTML и извлекать информацию из определенных тегов с помощью find().
См. также
Beautiful Soup
6.3 Удаление знаков препинания
Проблема
У вас есть текстовые данные, и вы хотите удалить знаки препинания.
Решение
Определите функцию, которая использует translate со словарем знаков препинания:
# Load libraries
import unicodedata
import sys
# Create text
text_data = ['Hi!!!! I. Love. This. Song....',
'10000% Agree!!!! #LoveIT',
'Right?!?!']
# Create a dictionary of punctuation characters
punctuation = dict.fromkeys(i for i in range(sys.maxunicode)
if unicodedata.category(chr(i)).startswith('P'))
# For each string, remove any punctuation characters
[string.translate(punctuation) for string in text_data]['Hi I Love This Song', '10000 Agree LoveIT', 'Right']Обсуждение
translate — это метод Python, который популярен благодаря своей скорости. В нашем решении мы сначала создали словарь punctuation со всеми знаками препинания согласно Unicode в качестве ключей и None в качестве значений. Затем мы перевели все символы в строке, которые являются знаками препинания, в None, фактически удалив их. Есть более читабельные способы удаления знаков препинания, но это несколько хакерское решение имеет преимущество в том, что оно намного быстрее альтернатив.
Важно осознавать, что знаки препинания содержат информацию (например, «Right?» против «Right!»). Удаление знаков препинания может быть необходимым злом, когда нам нужно вручную создавать признаки; однако, если знаки препинания важны, мы должны убедиться, что учтем это.
6.4 Токенизация текста
Проблема
У вас есть текстовые данные, и вы хотите разбить их на отдельные слова.
Решение
Natural Language Toolkit for Python (NLTK) имеет мощный набор операций по манипулированию текстом, включая токенизацию слов:
# Load library
from nltk.tokenize import word_tokenize
# Create text
string = "The science of today is the technology of tomorrow"
# Tokenize words
word_tokenize(string)['The', 'science', 'of', 'today', 'is', 'the', 'technology', 'of', 'tomorrow']Мы также можем токенизировать на предложения:
# Load library
from nltk.tokenize import sent_tokenize
# Create text
string = "The science of today is the technology of tomorrow. Tomorrow is today."
# Tokenize sentences
sent_tokenize(string)['The science of today is the technology of tomorrow.', 'Tomorrow is today.']Обсуждение
Токенизация, особенно токенизация слов, является распространенной задачей после очистки текстовых данных, поскольку это первый шаг в процессе превращения текста в данные, которые мы будем использовать для построения полезных признаков. Некоторые предварительно обученные модели NLP (такие как BERT от Google) используют методы токенизации, специфичные для модели, однако токенизация на уровне слов по-прежнему является довольно распространенным подходом к токенизации перед получением признаков из отдельных слов.
6.5 Удаление стоп-слов
Проблема
Имея токенизированные текстовые данные, вы хотите удалить чрезвычайно распространенные слова (например, a, is, of, on), которые содержат мало информативной ценности.
Решение
Используйте stopwords NLTK:
# Load library
from nltk.corpus import stopwords
# You will have to download the set of stop words the first time
# import nltk
# nltk.download('stopwords')
# Create word tokens
tokenized_words = ['i',
'am',
'going',
'to',
'go',
'to',
'the',
'store',
'and',
'park']
# Load stop words
stop_words = stopwords.words('english')
# Remove stop words
[word for word in tokenized_words if word not in stop_words]['going', 'go', 'store', 'park']Обсуждение
Хотя «стоп-слова» могут относиться к любому набору слов, которые мы хотим удалить перед обработкой, чаще всего этот термин относится к чрезвычайно распространенным словам, которые сами по себе содержат мало информативной ценности. Выбор того, следует ли удалять стоп-слова, будет зависеть от вашего индивидуального случая использования. NLTK имеет список распространенных стоп-слов, которые мы можем использовать для поиска и удаления стоп-слов в наших токенизированных словах:
# Show stop words
stop_words[:5]['i', 'me', 'my', 'myself', 'we']Обратите внимание, что stopwords NLTK предполагает, что токенизированные слова полностью приведены к нижнему регистру.
6.6 Стемминг слов
Проблема
Вы токенизировали слова и хотите преобразовать их в корневые формы.
Решение
Используйте PorterStemmer NLTK:
# Load library
from nltk.stem.porter import PorterStemmer
# Create word tokens
tokenized_words = ['i', 'am', 'humbled', 'by', 'this', 'traditional', 'meeting']
# Create stemmer
porter = PorterStemmer()
# Apply stemmer
[porter.stem(word) for word in tokenized_words]['i', 'am', 'humbl', 'by', 'thi', 'tradit', 'meet']Обсуждение
Стемминг сокращает слово до его основы путем идентификации и удаления аффиксов (например, герундиев), сохраняя при этом корневое значение слова. Например, и «традиция», и «традиционный» имеют основу «tradit», указывая на то, что, хотя это разные слова, они представляют одно и то же общее понятие. Стеммируя наши текстовые данные, мы преобразуем их в нечто менее читаемое, но более близкое к их базовому значению и, таким образом, более подходящее для сравнения между наблюдениями. PorterStemmer NLTK реализует широко используемый алгоритм стемминга Портера для удаления или замены распространенных суффиксов для получения основы слова.
См. также
Porter Stemming Algorithm
6.7 Тегирование частей речи
Проблема
У вас есть текстовые данные, и вы хотите пометить каждое слово или символ его частью речи.
Решение
Используйте предварительно обученный теггер частей речи NLTK:
# Load libraries
from nltk import pos_tag
from nltk import word_tokenize
# Create text
text_data = "Chris loved outdoor running"
# Use pre-trained part of speech tagger
text_tagged = pos_tag(word_tokenize(text_data))
# Show parts of speech
text_tagged[('Chris', 'NNP'), ('loved', 'VBD'), ('outdoor', 'RP'), ('running', 'VBG')]Вывод представляет собой список кортежей, содержащих слово и тег части речи. NLTK использует теги частей речи Penn Treebank. Некоторые примеры тегов Penn Treebank:
| Tag | Part of speech |
|---|---|
| NNP | Proper noun, singular |
| NN | Noun, singular or mass |
| RB | Adverb |
| VBD | Verb, past tense |
| VBG | Verb, gerund or present participle |
| JJ | Adjective |
| PRP | Personal pronoun |
После того как текст был помечен, мы можем использовать теги для поиска определенных частей речи. Например, вот все существительные:
# Filter words
[word for word, tag in text_tagged if tag in ['NN','NNS','NNP','NNPS'] ]['Chris']Более реалистичная ситуация заключалась бы в том, что у нас есть данные, где каждое наблюдение содержит твит, и мы хотим преобразовать эти предложения в признаки для отдельных частей речи (например, признак с 1, если присутствует собственное имя, и 0 в противном случае):
# Import libraries
from sklearn.preprocessing import MultiLabelBinarizer
# Create text
tweets = ["I am eating a burrito for breakfast",
"Political science is an amazing field",
"San Francisco is an awesome city"]
# Create list
tagged_tweets = []
# Tag each word and each tweet
for tweet in tweets:
tweet_tag = nltk.pos_tag(word_tokenize(tweet))
tagged_tweets.append([tag for word, tag in tweet_tag])
# Use one-hot encoding to convert the tags into features
one_hot_multi = MultiLabelBinarizer()
one_hot_multi.fit_transform(tagged_tweets)array([[1, 1, 0, 1, 0, 1, 1, 1, 0],
[1, 0, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 1]])Используя classes_, мы можем увидеть, что каждый признак является тегом части речи:
# Show feature names
one_hot_multi.classes_array(['DT', 'IN', 'JJ', 'NN', 'NNP', 'PRP', 'VBG', 'VBP', 'VBZ'], dtype=object)Обсуждение
Если наш текст на английском языке и не относится к специализированной теме (например, медицине), самое простое решение — использовать предварительно обученный теггер частей речи NLTK. Однако, если pos_tag не очень точен, NLTK также дает нам возможность обучить свой собственный теггер. Основным недостатком обучения теггера является то, что нам нужен большой корпус текста, где известна метка каждого слова. Составление такого помеченного корпуса, очевидно, является трудоемким и, вероятно, будет использоваться в крайнем случае.
При всем вышесказанном, если у нас был размеченный корпус и мы хотели обучить теггер, ниже приведен пример того, как мы могли бы это сделать. Мы используем корпус Brown, один из самых популярных источников размеченного текста. Здесь мы используем теггер n-грамм с откатом, где n — это количество предыдущих слов, которые мы учитываем при предсказании части речи слова. Сначала мы учитываем два предыдущих слова с помощью TrigramTagger; если два слова отсутствуют, мы «отступаем» и учитываем тег предыдущего слова с помощью BigramTagger, и, наконец, если это не удается, мы смотрим только на само слово с помощью UnigramTagger. Чтобы проверить точность нашего теггера, мы разбиваем наши текстовые данные на две части, обучаем теггер на одной части и проверяем, насколько хорошо он предсказывает теги второй части:
# Load library
from nltk.corpus import brown
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
# Get some text from the Brown Corpus, broken into sentences
sentences = brown.tagged_sents(categories='news')
# Split into 4000 sentences for training and 623 for testing
train = sentences[:4000]
test = sentences[4000:]
# Create backoff tagger
unigram = UnigramTagger(train)
bigram = BigramTagger(train, backoff=unigram)
trigram = TrigramTagger(train, backoff=bigram)
# Show accuracy
trigram.accuracy(test)0.8174734002697437См. также
Penn Treebank
Brown Corpus
6.8 Распознавание именованных сущностей
Проблема
Вы хотите выполнить распознавание именованных сущностей в свободном тексте (таких как «Человек», «Штат» и т.д.).
Решение
Используйте конвейер распознавания именованных сущностей по умолчанию spaCy и модели для извлечения сущностей из текста:
# Import libraries
import spacy
# Load the spaCy package and use it to parse the text (make sure you have run "python -m spacy download en")
nlp = spacy.load("en_core_web_sm")
doc = nlp("Elon Musk offered to buy Twitter using $21B of his own money.")
# Print each entity
print(doc.ents)
# For each entity print the text and the entity label
for entity in doc.ents:
print(entity.text, entity.label_, sep=",")(Elon Musk, Twitter, 21B)
Elon Musk,PERSON
Twitter,ORG
21B,MONEYОбсуждение
Распознавание именованных сущностей — это процесс распознавания конкретных сущностей из текста. Инструменты, такие как spaCy, предлагают предварительно настроенные конвейеры и предварительно обученные модели машинного обучения, которые могут легко идентифицировать эти сущности. В данном случае мы используем spaCy для идентификации человека («Илон Маск»), организации («Twitter») и денежного значения («21B») из необработанного текста. Используя эту информацию, мы можем извлекать структурированную информацию из неструктурированных текстовых данных. Эта информация затем может быть использована в последующих моделях машинного обучения или для анализа данных.
Обучение пользовательской модели распознавания именованных сущностей выходит за рамки этого примера, однако часто выполняется с использованием глубокого обучения и других методов NLP.
См. также
spaCy named-entity recognition docs
Named-entity recognition on Wikipedia
6.9 Кодирование текста как мешка слов
Проблема
У вас есть текстовые данные, и вы хотите создать набор признаков, указывающих количество раз, когда текст наблюдения содержит определенное слово.
Решение
Используйте CountVectorizer scikit-learn:
# Load library
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
# Create text
text_data = np.array(['I love Brazil. Brazil!',
'Sweden is best',
'Germany beats both'])
# Create the bag of words feature matrix
count = CountVectorizer()
bag_of_words = count.fit_transform(text_data)
# Show feature matrix
bag_of_words<3x8 sparse matrix of type ''
with 8 stored elements in Compressed Sparse Row format> Этот вывод представляет собой разреженную матрицу, что часто необходимо при работе с большим объемом текста. Однако в нашем игрушечном примере мы можем использовать toarray для просмотра матрицы счетчиков слов для каждого наблюдения:
bag_of_words.toarray()array([[0, 0, 0, 2, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 1, 0, 1, 0, 0, 0]], dtype=int64)Мы можем использовать метод get_feature_names для просмотра слова, связанного с каждым признаком:
# Show feature names
count.get_feature_names_out()array(['beats', 'best', 'both', 'brazil', 'germany', 'is', 'love',
'sweden'], dtype=object)Это может сбивать с толку, поэтому для ясности вот как выглядит матрица признаков со словами в качестве имен столбцов (каждая строка — одно наблюдение):
| beats | best | both | brazil | germany | is | love | sweden | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 2 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 2 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
Обсуждение
Одним из наиболее распространенных методов преобразования текста в признаки в реальном мире является использование модели «мешка слов» (bag-of-words). Модели bag-of-words выводят признак для каждого уникального слова в текстовых данных, причем каждый признак содержит счетчик вхождений в наблюдениях. Например, в нашем решении предложение I love Brazil. Brazil! имеет значение 2 в признаке «brazil», потому что слово brazil появляется дважды.
Текстовые данные в нашем решении были намеренно небольшими. В реальном мире одно наблюдение текстовых данных могло бы быть содержанием целой книги! Поскольку наша модель bag-of-words создает признак для каждого уникального слова в данных, результирующая матрица может содержать тысячи признаков. Это означает, что размер матрицы иногда может стать очень большим в памяти. Однако, к счастью, мы можем использовать общую характеристику матриц признаков bag-of-words для уменьшения объема данных, которые нам нужно хранить.
Большинство слов, вероятно, не встречаются в большинстве наблюдений, и поэтому матрицы признаков bag-of-words будут содержать в основном 0 в качестве значений. Мы называем такие типы матриц «разреженными». Вместо хранения всех значений матрицы мы можем хранить только ненулевые значения и затем предполагать, что все остальные значения равны 0. Это сэкономит нам память, когда у нас есть большие матрицы признаков. Одной из приятных особенностей CountVectorizer является то, что выходные данные по умолчанию являются разреженной матрицей.
CountVectorizer имеет ряд полезных параметров для упрощения создания матриц признаков bag-of-words. Во-первых, хотя по умолчанию каждый признак — это слово, это не обязательно. Вместо этого мы можем установить каждый признак как комбинацию двух слов (называемых 2-граммой) или даже трех слов (3-граммой). ngram_range устанавливает минимальный и максимальный размер наших n-грамм. Например, (2,3) вернет все 2-граммы и 3-граммы. Во-вторых, мы можем легко удалить малоинформативные слова-заполнители, используя stop_words либо со встроенным списком, либо с пользовательским списком. Наконец, мы можем ограничить слова или фразы, которые мы хотим рассмотреть, определенным списком слов, используя vocabulary. Например, мы могли бы создать матрицу признаков bag-of-words только для вхождений названий стран:
# Create feature matrix with arguments
count_2gram = CountVectorizer(ngram_range=(1,2),
stop_words="english",
vocabulary=['brazil'])
bag = count_2gram.fit_transform(text_data)
# View feature matrix
bag.toarray()array([[2],
[0],
[0]])# View the 1-grams and 2-grams
count_2gram.vocabulary_{'brazil': 0}См. также
n-gram
Bag of Words Meets Bags of Popcorn
6.10 Взвешивание важности слов
Проблема
Вам нужен мешок слов, но с весами слов, соответствующими их важности для наблюдения.
Решение
Сравните частоту слова в документе (твит, рецензия на фильм, стенограмма речи и т.д.) с частотой слова во всех остальных документах, используя частоту термина-обратную частоту документа (tf-idf). scikit-learn делает это легко с помощью TfidfVectorizer:
# Load libraries
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
# Create text
text_data = np.array(['I love Brazil. Brazil!',
'Sweden is best',
'Germany beats both'])
# Create the tf-idf feature matrix
tfidf = TfidfVectorizer()
feature_matrix = tfidf.fit_transform(text_data)
# Show tf-idf feature matrix
feature_matrix<3x8 sparse matrix of type ''
with 8 stored elements in Compressed Sparse Row format> Как и в Рецепте 6.9, вывод представляет собой разреженную матрицу. Однако, если мы хотим просмотреть вывод в виде плотной матрицы, мы можем использовать .toarray:
# Show tf-idf feature matrix as dense matrix
feature_matrix.toarray()array([[ 0. , 0. , 0. , 0.89442719, 0. ,
0. , 0.4472136 , 0. ],
[ 0. , 0.57735027, 0. , 0. , 0. ,
0.57735027, 0. , 0.57735027],
[ 0.57735027, 0. , 0.57735027, 0. , 0.57735027,
0. , 0. , 0. ]])vocabulary_ показывает нам слово для каждого признака:
# Show feature names
tfidf.vocabulary_{'love': 6,
'brazil': 3,
'sweden': 7,
'is': 5,
'best': 1,
'germany': 4,
'beats': 0,
'both': 2}Обсуждение
Чем чаще слово появляется в документе, тем более вероятно, что это слово важно для данного документа. Например, если слово economy часто появляется, это свидетельствует о том, что документ может быть посвящен экономике. Мы называем это частотой термина (tf).
Напротив, если слово появляется во многих документах, оно, вероятно, менее важно для любого отдельного документа. Например, если каждый документ в некоторых текстовых данных содержит слово after, то это, вероятно, неважное слово. Мы называем это частотой документа (df).
Объединяя эти две статистики, мы можем присвоить каждому слову оценку, представляющую, насколько важно это слово в документе. В частности, мы умножаем tf на обратную частоту документа (idf):
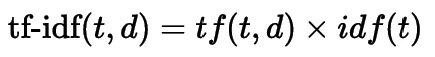
Рисунок: Формула tf-idf
где t — слово, а d — документ. Существует несколько вариантов вычисления tf и idf. В scikit-learn tf — это просто количество раз, которое слово появляется в документе, а idf вычисляется как:
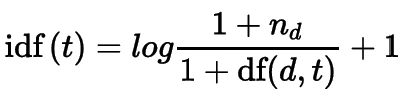
Рисунок: Формула idf
где nd — количество документов, а df(d,t) — частота термина t в документе (т.е. количество документов, в которых встречается термин).
По умолчанию scikit-learn затем нормализует tf-idf векторы, используя Евклидову норму (L2 норму). Чем выше результирующее значение, тем важнее слово для документа.
См. также
scikit-learn documentation: tf–idf term weighting
6.11 Использование векторов слов для вычисления сходства текста в поисковом запросе
Проблема
Вы хотите использовать векторы tf-idf для реализации функции текстового поиска на Python.
Решение
Вычислите косинусное сходство между векторами tf-idf, используя scikit-learn.
# Load libraries
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
# Create searchable text data
text_data = np.array(['I love Brazil. Brazil!',
'Sweden is best',
'Germany beats both'])
# Create the tf-idf feature matrix
tfidf = TfidfVectorizer()
feature_matrix = tfidf.fit_transform(text_data)
# Create a search query and transform it into a tf-idf vector
text = "Brazil is the best"
vector = tfidf.transform([text])
# Calculate the cosine similarities between the input vector and all other vectors
cosine_similarities = linear_kernel(vector, feature_matrix).flatten()
# Get the index of the most relevent items in order
related_doc_indicies = cosine_similarities.argsort()[:-10:-1]
# Print the most similar texts to the search query along with the cosine similarity
print([(text_data[i], cosine_similarities[i]) for i in related_doc_indicies])[('Sweden is best', 0.6666666666666666), ('I love Brazil. Brazil!', 0.5163977794943222), ('Germany beats
both', 0.0)]Обсуждение
Векторы слов невероятно полезны для сценариев использования NLP, таких как поисковые системы. После вычисления tf-idf векторов набора предложений или документов мы можем использовать тот же объект tfidf для векторизации будущих наборов текста. Затем мы можем вычислить косинусное сходство между нашим входным вектором и матрицей других векторов и отсортировать по наиболее релевантным документам.
Косинусное сходство принимает значения в диапазоне [0, 1.0], где 0 означает наименее сходство, а 1 — наибольшее сходство. Поскольку мы используем tf-idf векторы для вычисления сходства между векторами, частота появления слова также учитывается. Однако при небольшом корпусе (наборе документов) даже «часто встречающиеся» слова могут встречаться нечасто. В приведенном выше примере «Sweden is best» является наиболее релевантным текстом для нашего поискового запроса «Brazil is the best». Поскольку запрос упоминает Brazil, мы можем ожидать, что он будет наиболее релевантным - однако «Sweden is best» наиболее похож благодаря словам «is» и «best». По мере увеличения количества документов, добавляемых в наш корпус, менее важные слова будут взвешиваться меньше и оказывать меньшее влияние на расчет косинусного сходства.
См. также
Geeks for geeks cosine similarity
Building a pubmed search engine in Python
6.12 Использование классификатора анализа тональности
Проблема
Вы хотите классифицировать тональность некоторого текста для использования в качестве признака или в последующем анализе данных.
Решение
Используйте классификатор тональности библиотеки transformers.
# Import libraries
from transformers import pipeline
# Create an NLP pipeline that runs sentiment analysis
classifier = pipeline("sentiment-analysis")
# Classify some text (this may download some data and models the first time you run it)
sentiment_1 = classifier("I hate machine learning! It's the absolute worst.")
sentiment_2 = classifier("Machine learning is the absolute bees knees I love it so much!")
# Print sentiment output
print(sentiment_1, sentiment_2)[{'label': 'NEGATIVE', 'score': 0.9998020529747009}] [{'label': 'POSITIVE', 'score': 0.9990628957748413}]Обсуждение
Библиотека transformers является чрезвычайно популярной библиотекой для задач NLP и содержит ряд простых в использовании API для обучения моделей или использования предварительно обученных моделей. Мы подробнее поговорим о NLP и этой библиотеке в главе о NLP, но приведенный выше пример служит высоким уровнем введения в возможности использования предварительно обученных классификаторов в ваших конвейерах машинного обучения для генерации признаков, классификации текста или анализа неструктурированных данных.
См. также
Huggingface transformers quick tour
Другие статьи по этой теме:
- Маленькая книга о глубоком обучении
- 100 Страниц о машинном обучении
- Математика для нейронного обучения