Глава 12: Реализация голосового агента Dialogflow на вашем веб-сайте или в приложении с использованием SDK
Когда в 2019 году началась пандемия COVID-19, многие компании осознали, что клиенты не хотят прикасаться к общедоступным клавиатурам и сенсорным интерфейсам, источникам легкого распространения бактерий. Например, люди стали предпочитать бесконтактные платежи в магазинах и не прикасаться к устройствам киосков самообслуживания, которые можно найти в аэропортах, на вокзалах или в магазинах. Поэтому это отличное решение для создания голосового ИИ в ваших аппаратных устройствах и приложениях.
Эта глава не о Google Assistant. Речь идет об интеграции вашего голосового агента Dialogflow в веб-сайт или приложение. Это требует нескольких шагов, которые разделены по разделам этой главы:
- Создание клиентского приложения и UX, которое позволяет использовать микрофон
- Создание бэкэнд-приложения, которое позволяет использовать API машинного обучения Google Cloud для понимания устной речи и возврата синтезированной речи
- Воспроизведение сгенерированных аудиопотоков в вашем (браузерном) приложении
Но прежде чем мы продолжим, давайте обратим внимание на то, почему вам не следует выбирать Google Assistant для этого конкретного случая использования.
Причины не выбирать Google Assistant
Я часто общаюсь с клиентами, и их желание — включить Google Assistant в их бизнес-веб-приложения. Если вы не являетесь производителем телевизионных приставок или наушников, я всегда отвечаю:
«Это действительно то, что вы хотите? Или вы имеете в виду расширить свое собственное приложение с помощью разговорного ИИ?»
Предположим, у вас есть одно или несколько из следующих требований. В этом случае вы, вероятно, захотите напрямую использовать API Google Cloud Speech и Dialogflow, вместо того чтобы упаковывать свой голосовой ИИ как действие в Google Assistant или оборачивать SDK Google Assistant с открытым исходным кодом в свое собственное приложение.
Причины не выбирать Google Assistant вместо создания собственного голосового ИИ:
- Это приложение не должно быть общедоступным.
- Это приложение не должно быть доступно в Google Assistant/Nest Home.
- Вы не хотите запускать свое приложение с помощью слов пробуждения: «Эй, Google, поговори с <моим приложением>».
- Приложение не должно отвечать на нативные вопросы Google Assistant, такие как «какая погода в Амстердаме».
- Приложение имеет специфические технические требования, такие как необходимость держать микрофон открытым дольше 30 секунд.
- Приложение может использовать только корпоративные условия и положения Google Cloud вместо их объединения с потребительскими условиями и положениями Google Assistant.
По сравнению с Google Assistant, расширяя ваши приложения с помощью разговорного ИИ вручную с помощью предыдущих инструментов, вы больше не являетесь частью экосистемы Google Assistant. Эта экосистема отлично подходит, если вы создаете потребительские или кампанейские приложения (голосовые действия), которые каждый может найти, вызвав их через вызов <Эй, Google, поговори с моим приложением>. Но когда вы предприятие, вся эта экосистема может быть излишней. Рисунок 12-1 покажет вам экосистему Google Assistant; как видно на картинке, экосистема содержит миллионы действий, которые нужно вызывать. Если вы хотите расширить свой пользовательский ИИ голосом, экосистема Google Assistant может быть излишней.
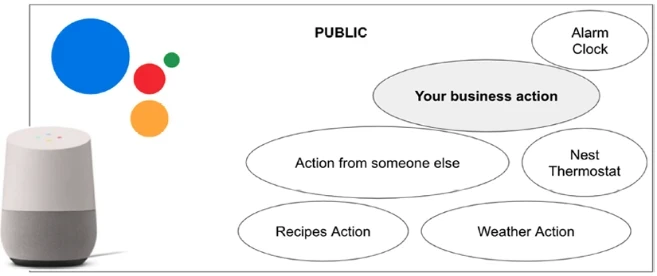
Рисунок 12-1. Экосистема Google Assistant может быть излишней
Вы убедились, что хотите расширить свое собственное (мобильное) веб-приложение, интегрировав возможности голосового ИИ? Эта глава объясняет реализацию потоковой передачи голоса из веб-приложения в Speech-to-Text, Dialogflow и Text-to-Speech.
Рисунок 12-2 покажет, как будет выглядеть архитектура этой голосовой интеграции.
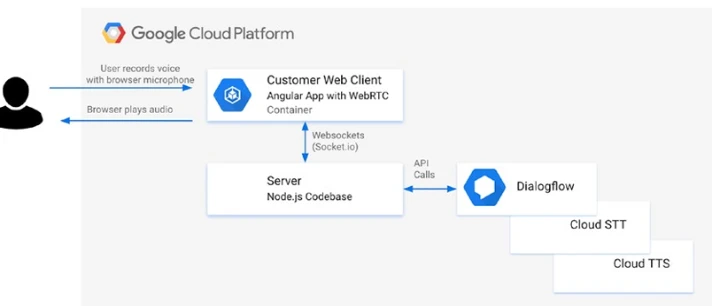
Рисунок 12-2. Пользователь будет говорить через микрофон в веб-приложении браузера. Это фронтенд-веб-приложение передаст поток на бэкэнд-сервер, который будет выполнять вызовы к Dialogflow, Speech-to-Text и Text-to-Speech
Создание клиентского веб-приложения, которое передает аудиопоток с микрофона браузера на сервер
Вы будете использовать метод JavaScript WebRTC getUserMedia() в вашем браузере для захвата аудиопотоков с микрофона.
Чтобы убедиться, что это работает во всех современных браузерах, вы можете использовать библиотеку, такую как RecordRTC. RecordRTC — это библиотека JavaScript WebRTC для записи аудио/видео, а также записи активности экрана. Она поддерживает Chrome, Firefox, Opera, Android и Microsoft Edge. Платформы: Linux, Mac и Windows.
Примечание: При запуске вашего приложения на устройствах iOS вы можете столкнуться с различными проблемами. Прежде всего, iOS не поддерживает методы JavaScript getUserMedia и WebRTC ни в одном другом мобильном браузере, кроме Safari. Вы можете показать всплывающее предупреждение, когда оно открыто в браузере iOS, отличном от мобильного Safari.
Чтобы использовать метод getUserMedia() WebRTC, вам нужно будет разрешить всплывающее окно разрешений, которое отображается только один раз при запуске из HTTPS.
Одно критическое ограничение остается на iOS: Web Audio фактически отключен до активации пользователем. Для воспроизведения и записи аудио в iOS требуется взаимодействие с пользователем (например, касание).
Как только мы захватим аудио, нам нужно будет отправить поток на бэкэнд-сервер. Таким образом, бэкэнд-сервер может интегрироваться с API Google, такими как Dialogflow.
Для этого вы можете использовать WebSockets или библиотеку, такую как Socket.IO. Socket.IO обеспечивает двунаправленную связь в реальном времени на основе событий. Для передачи двоичных потоков через Socket.IO я использую модуль Socket.io-Stream.
Создание фронтенда
Во-первых, вашему клиентскому приложению/HTML-странице понадобится как минимум кнопка (или две) для остановки и запуска микрофона браузера. Обратите внимание на Листинг 12-1. Вы также можете показать поле textarea для демонстрационных целей, которое позже может показывать возвращенные текстовые результаты.
Листинг 12-1. HTML-элементы, необходимые для создания пользовательского голосового ИИ
<div>
<button id="start-recording" disabled>Start Recording</button>
<button id="stop-recording" disabled>Stop Recording</button>
</div>
<textarea id="results"></textarea>Убедитесь, что вы загрузите библиотеки RecordRTC и Socket.IO на свою страницу.
Затем вам понадобится фрагмент JavaScript, который может позаботиться о записи с микрофона и передаче аудиообъекта на бэкэнд-сервер.
Листинг 12-2. Обработка записи с микрофона и потоковая передача аудиообъекта в бэкэнд-серверное приложение
//1) Получаем ссылки на кнопки
const startRecording = document.getElementById('start-recording');
const stopRecording = document.getElementById('stop-recording');
let recordAudio; // Переменная для хранения объекта RecordRTC
//2) Инициализируем Socket.IO и устанавливаем соединение
const socketio = io(); // Предполагается, что Socket.IO загружен
const socket = socketio.on('connect', function() {
startRecording.disabled = false; // Включаем кнопку Start после подключения
console.log('Socket connected');
});
//3) Обработчик клика по кнопке Start Recording
startRecording.onclick = function() {
startRecording.disabled = true; // Отключаем кнопку Start
stopRecording.disabled = false; // Включаем кнопку Stop
//4) Запрашиваем доступ к микрофону
navigator.mediaDevices.getUserMedia({ // Используем новый API mediaDevices
audio: true
}).then(function(stream) { // Успешное получение потока
//5) Создаем экземпляр RecordRTC
recordAudio = RecordRTC(stream, {
type: 'audio',
//6) Настройки записи
mimeType: 'audio/webm', // Или 'audio/wav' если нужно
sampleRate: 44100, // Исходная частота дискретизации
// desiredSampRate: 16000, // Установка желаемой частоты дискретизации (если поддерживается библиотекой)
// recorderType: StereoAudioRecorder, // Можно указать тип рекордера
numberOfAudioChannels: 1, // Запись моно для Dialogflow / STT
timeSlice: 4000, // Создавать чанки каждые 4000 мс (4 секунды) для потоковой передачи
ondataavailable: function(blob) {
// Этот обработчик вызывается для каждого чанка данных (при использовании timeSlice)
console.log('Data available:', blob);
// Отправка чанка на сервер (для потоковой передачи)
// Используем socket.io-stream для потоковой передачи blob
var stream = ss.createStream();
ss(socket).emit('stream', stream, { name: 'stream.wav', size: blob.size });
ss.createBlobReadStream(blob).pipe(stream);
}
});
recordAudio.startRecording(); // Начинаем запись
}).catch(function(error) { // Ошибка при получении доступа к микрофону
console.error('Error accessing microphone:', error);
startRecording.disabled = false; // Включаем кнопку Start обратно
stopRecording.disabled = true;
});
};
// Обработчик клика по кнопке Stop Recording (для записи одного высказывания)
stopRecording.onclick = function() {
startRecording.disabled = false;
stopRecording.disabled = true;
recordAudio.stopRecording(function() { // Останавливаем запись
let blob = recordAudio.getBlob(); // Получаем записанный Blob
// Преобразуем Blob в Data URL для отправки всего файла
let reader = new FileReader();
reader.onload = function(event) {
const audioDataURL = event.target.result;
var files = {
audio: {
type: blob.type || 'audio/webm', // Указываем тип MIME
dataURL: audioDataURL
}
};
// Отправляем весь аудиофайл на сервер
socketio.emit('message', files);
};
reader.readAsDataURL(blob);
// Очистка потока (если нужно)
// let stream = recordAudio.stream;
// stream.getAudioTracks().forEach(track => track.stop());
});
};
// Обработчик события 'results' от сервера (для отображения текста)
const resultpreview = document.getElementById('results');
socketio.on('results', function (data) {
console.log('Results from server:', data);
// Отображаем результаты в textarea
if(data && data[0] && data[0].queryResult){
resultpreview.value += "\nAgent: " + data[0].queryResult.fulfillmentText;
}
});
// Необходимо также подключить библиотеку socket.io-stream
// <script src="/socket.io-stream/socket.io-stream.js"></script>
// const ss = require('socket.io-stream'); // На клиенте это обычно не require, а глобальный объект ss- Сначала я создам несколько указателей на кнопки старт и стоп.
- Затем я создаю экземпляр Socket.IO и открываю соединение.
- Я создал два слушателя событий для начала и остановки записи. Событие onclick кнопки старт отключит кнопку старт, чтобы вы не могли нажать кнопку дважды и, следовательно, записать аудио дважды.
navigator.mediaDevices.getUserMedia()— важная часть кода. Это часть набора API WebRTC, который предоставляет средства для доступа к локальному потоку камеры/микрофона пользователя. В нашем случае мы используем только микрофон (audio: true). Это дает нам доступ к потоку.- Теперь я использую библиотеку RecordRTC. Я мог бы написать эту часть кода сам. Но RecordRTC решает много сложных задач, таких как преобразование буферов (из Float32 в Int16), кросс-браузерная поддержка и так далее.
- RecordRTC принимает два аргумента. Первый аргумент — это MediaStream из вызова getUserMedia(). Второй аргумент — это объект конфигурации с настройками для оптимизации потока. Есть пара необходимых настроек, которые я делаю, которые должны соответствовать вашим настройкам позже в серверном коде (документация для InputAudioConfig в Dialogflow или RecognitionConfig в STT):
- Тип MIME установлен на
audio/webm— что было бы правильной настройкой при использованииAUDIO_ENCODING_LINEAR_16илиLINEAR16в качестве конфигурации AudioEncoding в Dialogflow или STT. - sampleRate — это входная частота дискретизации в герцах. Я передискретизирую ее до 16000 Гц (desiredSampRate), чтобы размер сообщений по сети был меньше и соответствовал настройке частоты дискретизации в моих вызовах Dialogflow или STT.
- Кроме того, Dialogflow и STT требуют монофонический звук, что означает, что я должен установить numberOfAudioChannels на 1. RecorderType StereoAudioRecorder позволяет мне изменить количество аудиоканалов с 2 до 1.
timeSlice: Устанавливает интервалы для создания аудиочанков (в миллисекундах). Это используется для потоковой передачи.ondataavailable: Обработчик событий, который вызывается для каждого доступного чанка аудиоданных, когда используетсяtimeSlice. Здесь мы отправляем чанки на сервер.
- Тип MIME установлен на
Короткое высказывание против потоковой передачи
Обычно существует два подхода к интеграции голоса в ваше приложение:
- Короткие высказывания/обнаружение намерения: Это означает, что ваш конечный пользователь нажимает кнопку записи и говорит, и когда он нажимает стоп, мы собираем аудиопоток для возврата результатов. В вашем коде это означает, что как только клиентское веб-приложение соберет полную аудиозапись, оно отправит ее на сервер для выполнения вызова к Dialogflow или API Speech-to-Text.
- Потоковая передача длинных высказываний/обнаружение намерений в потоке: Это означает, что ваш конечный пользователь нажимает кнопку записи, говорит и будет видеть результаты на лету. При обнаружении намерений это может означать, что он будет обнаруживать лучшие совпадения, как только вы поговорите дольше. В вашем коде это означает, что клиент начинает устанавливать двунаправленный поток и передает чанки на сервер для выполнения вызова с помощью слушателей событий по входящим данным, и, таким образом, это происходит в реальном времени. Когда есть совпадение намерения, мы можем либо показать результаты на экране, представив текст, либо синтезировать (прочитать вслух) результаты, передавая аудио буфер обратно клиенту, который будет воспроизведен через WebRTC AudioBufferSourceNode (или аудиоплеер).
Запись одного высказывания
Короткие высказывания означают, что ваш конечный пользователь нажимает кнопку записи и говорит, и когда он нажимает стоп, мы собираем аудиопоток для возврата результатов. В вашем коде это означает, что как только клиентское веб-приложение соберет полную аудиозапись, оно отправит ее на сервер для выполнения вызова к Dialogflow или API Speech-to-Text. Для этого случая использования магия будет в слушателе события onclick кнопки стоп.
Листинг 12-3. Запись одного высказывания на фронтенде
// 1) Обработчик клика по кнопке Stop Recording
stopRecording.onclick = function() {
// Сброс кнопок
startRecording.disabled = false;
stopRecording.disabled = true;
// Остановить аудиорекордер
recordAudio.stopRecording(function() {
// После остановки аудио получить аудиоданные
recordAudio.getDataURL(function(audioDataURL) { // Получаем Data URL
//2) Создаем объект с данными аудио
var files = {
audio: {
type: recordAudio.getBlob().type || 'audio/wav', // Получаем тип MIME
dataURL: audioDataURL // Передаем Data URL
}
};
// Отправляем аудиофайл на сервер
socketio.emit('message', files);
});
});
};
// 3) Когда сервер найдет результаты, отправить
// их обратно клиенту
const resultpreview = document.getElementById('results');
socketio.on('results', function (data) {
console.log(data);
// Показать результаты на экране
if(data[0].queryResult){
resultpreview.innerHTML += "" + data[0].queryResult.fulfillmentText;
}
});- Когда вы нажимаете стоп, он сначала сбросит кнопки, затем остановит запись. И во время остановки записи он запросит audioDataURL, который является частью API RecordRTC, в функции обратного вызова. Он вернет строку dataURL с строкой Base64, содержащей ваш аудиопоток. Эта длинная строка выглядит так:
data:audio/wav;base64,UklGRiRgAgBXQVZFZm10IBAAAAABAAEARKwAA - Мы можем создать из нее объект, который также устанавливает тип аудио, а затем мы отправляем его на сервер с помощью Socket.IO:
socketio.emit('message', files);. Мы установим имя. Как только сервер установит соединение с этим сокетом, он будет искать имя события ‘message’ для ответа. И он получит объект files. - Последняя часть этого скрипта запустится, как только сервер сделает вызов к API Dialogflow/Speech и сделает обратный вызов WebSockets на сервер, чтобы вернуть результаты. В этом примере я просто печатаю результаты в поле textarea. Для Dialogflow fulfillmentText является частью queryResult.
Запись аудиопотоков
Запись потоков означает, что ваш конечный пользователь нажимает кнопку записи, говорит и будет видеть результаты на лету. При обнаружении намерений с помощью Dialogflow это может означать, что он будет обнаруживать лучшие совпадения, как только вы поговорите дольше или соберете несколько результатов. В вашем коде это означает, что клиент начинает устанавливать двунаправленный поток и передает чанки на сервер для выполнения вызова с помощью слушателей событий по входящим данным, и, таким образом, это происходит в реальном времени.
Вы можете выбрать этот подход, потому что ожидаемое аудио длинное. Или, в случае Dialogflow, вы можете захотеть показывать промежуточные результаты на экране в реальном времени во время разговора. В этом случае вам не нужна функция обратного вызова stopRecording, которая отправляет строку URL base64 на сервер. Вместо этого он будет отправлять поток на сервер в реальном времени!
Листинг 12-4. Запись полных аудиопотоков на фронтенде
// 1) Устанавливаем интервал для создания чанков
recordAudio = RecordRTC(stream, {
// ... другие настройки ...
timeSlice: 4000, // Создавать чанк каждые 4000 мс
// 2) Обработчик события ondataavailable
// как только поток будет доступен
ondataavailable: function(blob) {
// 3) Используем socket.io-stream для двунаправленной
// потоковой передачи, создаем поток
var stream = ss.createStream();
// Потоковая передача напрямую на сервер
// он будет временно сохранен локально (на сервере)
ss(socket).emit('stream', stream, {
name: 'stream.wav', // Имя файла для сохранения на сервере
size: blob.size // Размер чанка
});
// Передаем аудио blob в поток для чтения
ss.createBlobReadStream(blob).pipe(stream);
}
// 4 ... (остальные настройки RecordRTC)
});Магия, в данном случае, заключается в объекте RecordRTC и слушателе события ondataavailable:
- Сначала вам нужно будет установить timeSlice — timeSlice устанавливает интервалы для создания аудио чанков. В случае Dialogflow вы, вероятно, не захотите обнаруживать намерения каждую секунду (так как вы можете не закончить говорить предложение) и вместо этого встроите таймер. timeSlice устанавливается в миллисекундах, поэтому я использую 4000 (4 секунды).
- Затем есть слушатель события ondataavailable, который срабатывает, как только появляются данные, и будет содержать чанки блобов (аудио буферы), в моем случае, каждые 4 секунды.
- Именно здесь вступает в игру socketio-stream. Я использую двунаправленные потоки (я отправляю поток с чанками каждые 4 секунды, но я также могу захотеть получать результаты от сервера между ними). Поэтому я создаю поток, который будет временно сохранен на моем локальном диске (на сервере), с помощью
ss(socket).emit(). Я передаю его на сервер, и пока я это делаю, я передаю аудио буфер в поток. Цельstream.pipe()— ограничить буферизацию данных до приемлемых уровней, чтобы источники и приемники с разной скоростью не перегружали доступную память.
Если вы хотите увидеть сквозной пример, пожалуйста, посмотрите демо-версию киоска самообслуживания в аэропорту; вы можете найти ссылку в разделе «Дополнительные материалы».
Примечание: Я видел решения онлайн, где микрофон напрямую передается в Dialogflow без сервера между ними. Вызовы REST выполнялись непосредственно в веб-клиенте с помощью JavaScript. Я бы счел это антипаттерном. Вы, скорее всего, раскроете свой сервисный аккаунт/приватный ключ в своем клиентском коде. Любой, кто умеет пользоваться инструментами разработчика Chrome, может украсть ваш ключ и делать (платные) вызовы API через ваш аккаунт. Лучший подход — позволить серверу обрабатывать аутентификацию Google Cloud. Таким образом, сервисный аккаунт не будет раскрыт общественности.
Создание веб-сервера, который получает поток с микрофона браузера для обнаружения намерений
Вот шаги для создания приложения Node.js Express, которое интегрирует SDK Dialogflow. Как описано в предыдущем разделе, вам понадобится работающее фронтенд-приложение для получения AudioBuffers в реальном времени с микрофона HTML5.
Обычно серверный код будет состоять из следующих частей:
- Импорт всех необходимых библиотек
- Загрузка переменных среды
- Настройка сервера Express со слушателями Socket.IO
- Вызовы API Google Cloud: Dialogflow Audio DetectIntent и DetectStream
В этом разделе будет использоваться сервер Node.js, который будет обслуживать статический контент (например, HTML-страницу) и подключаться к SDK Dialogflow. Вы можете использовать любой другой язык программирования. Все сервисы Google Cloud имеют различные клиентские SDK (например, Node.js, Java, Python, Go и т. д.) и библиотеки REST и gRPC.
Агент Dialogflow, к которому я подключаюсь, должен содержать некоторые примеры намерений, сущностей или баз знаний FAQ.
При желании вы также можете включить вызовы Google Cloud Speech-to-Text StreamingRecognize и Google Cloud Text-to-Speech synthesize. Это может быть удобно, если вы хотите изменить входящую речь перед отправкой ее в Dialogflow, например, для перевода входящих речевых вызовов, вызовы синтеза Text-to-Speech (для произнесения результатов). Рисунок 12-3 — это архитектурная картина общего решения.
Чтобы увидеть этот пример в действии, посмотрите раздел «Дополнительные материалы» и используйте ссылки на демо-версию SelfServiceKiosk.
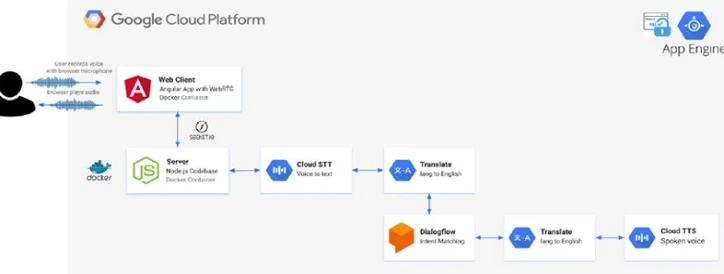
Рисунок 12-3. Пример архитектуры для создания собственного голосового ИИ с популярными инструментами Cloud AI, такими как Speech-to-Text AI, Translate API, Dialogflow и Text-to-Speech API
API Dialogflow против API Text-to-Speech против API Speech-to-Text
Хотя многие из нас будут использовать Dialogflow с текстовым вводом для веб- или социальных чат-ботов, также возможно выполнять сопоставление намерений с вашим голосом в качестве аудиовхода. Он может даже возвращать устный текст (TTS) в качестве аудиорезультата.
Обнаружение и вывод речи Dialogflow будут пересекаться с API Google Cloud Speech-to-Text (STT) и Google Cloud Text-to-Speech (TTS). Вызовы API выглядят похожими, и это потому, что Dialogflow использует Google Cloud Speech-to-Text под капотом.
Однако эти сервисы различаются и используются в разных сценариях. Например, Dialogflow используется в разговорах, когда вы ожидаете ответы/результаты, тогда как Google Cloud Text-to-Speech часто используется для целей транскрипции. (Подумайте о генерации субтитров или ведении заметок.)
API Speech-to-Text
Google Cloud Speech-to-Text (STT) транскрибирует произнесенные слова в письменный текст. Это отлично подходит, когда вы хотите сгенерировать субтитры в видео, сгенерировать текстовые транскрипции встреч и так далее. Вы также можете комбинировать его с чат-ботами Dialogflow (обнаруживать намерение из текстовых транскрипций) для синтеза ответов чат-бота. Однако STT не выполняет обнаружение намерений, как это делает Dialogflow. STT очень мощный, так как ответ на вызов API вернет письменную транскрипцию с наивысшей оценкой уверенности, и он вернет массив с альтернативными вариантами транскрипции.
Примечание: Входящие аудиопотоки Speech-to-Text StreamingDetectIntent оплачиваются с интервалом в 15 секунд. Через 15 секунд распознаватель речи истечет по времени, если будет тишина. В идеале, если есть тишина, он не должен ждать все 15 секунд.
API Text-to-Speech
С помощью Google Cloud Text-to-Speech (TTS) вы можете отправить текст или ввод SSML (текст с голосовой разметкой), и он вернет аудио байты, которые вы можете использовать для создания mp3-файла или напрямую передать в аудиоплеер (в вашем браузере).
К настоящему моменту вы видели, как создать веб-приложение, которое передает аудио с микрофона на вашем локальном устройстве через ваш браузер в бэкэнд-приложение, получает результаты от Dialogflow и отображает их в пользовательском интерфейсе. Было бы еще лучше, если бы браузер мог воспроизводить аудиопотоки. Именно об этом следующая глава!
Создание бэкэнда
Поскольку мое примерное приложение использует Node.js и npm, мне нужно будет загрузить внешние библиотеки Node. Пакет npm, который необходим для этой главы, называется dialogflow. И он будет использоваться для взаимодействия с Dialogflow и выполнения сопоставления намерений (по речи).
В демонстрационных целях я не буду обсуждать, как настроить приложение Node.js с сервером Express. Но в качестве справки вы можете посмотреть мой простой серверный код, который использовался для простых клиентских примеров, а также вы можете посмотреть код сквозного примера киоска самообслуживания в аэропорту. Ссылки можно найти в разделе «Дополнительные материалы» этой главы.
Когда вы просмотрите эти списки кода, вы сможете увидеть сервер Express. Все они общаются через Socket.IO, как Листинг 12-5.
Листинг 12-5. Использование Socket.IO для отправки аудиопотоков с фронтенда на бэкэнд
//1) Обработчик события 'connect' от Socket.IO
io.on('connect', (client) => {
//2) Обработчик события 'message' от клиента (для одиночных высказываний)
client.on('message', async function(data) {
// Извлекаем Data URL и преобразуем в буфер
const dataURL = data.audio.dataURL.split(',').pop();
let fileBuffer = Buffer.from(dataURL, 'base64');
//3) Вызываем функцию обнаружения намерения с буфером
const results = await detectIntent(fileBuffer); // Передаем fileBuffer
client.emit('results', results); // Отправляем результаты клиенту
});
//4) Обработчик события 'stream' от клиента (для потоковой передачи)
ss(client).on('stream', function(stream, data) { // Используем socket.io-stream
const filename = path.basename(data.name); // Получаем имя файла
// Сохраняем поток во временный файл на сервере
const filePath = path.join(__dirname, 'temp_audio', filename); // Указываем путь для сохранения
const writeStream = fs.createWriteStream(filePath);
stream.pipe(writeStream); // Перенаправляем поток в файл
stream.on('end', async () => {
console.log(`File ${filename} saved.`);
//5) После сохранения файла вызываем функцию потокового обнаружения
// Передаем путь к файлу или сам поток, если библиотека поддерживает
// В этом примере, предположим, detectIntentStream работает с потоком чтения
const readStream = fs.createReadStream(filePath);
detectIntentStream(readStream, function(results) { // Передаем поток и колбэк
client.emit('results', results); // Отправляем результаты клиенту
// Удаляем временный файл после обработки
fs.unlink(filePath, (err) => {
if (err) console.error("Error deleting temp file:", err);
});
});
});
stream.on('error', (err) => {
console.error('Stream error:', err);
// Обработка ошибок потока
});
});
});- С созданным экземпляром Socket.IO я могу слушать событие connect emit. Как только клиент Socket.IO подключится к серверу, этот код будет выполнен.
- При подключении к сокету и срабатывании события ‘message’ от клиента выполните этот код. Он получит данные, которые были установлены при остановке рекордера WebRTC. Чтобы напомнить из моей предыдущей главы, я создал объект с дочерним объектом, который содержит тип mime (audio/webm) и audioDataURL, который является строкой Base64, содержащей аудиозапись. Давайте возьмем эту строку Base64 и преобразуем ее в буфер файла Node.js.
- С этим fileBuffer я могу вызвать свою пользовательскую реализацию Dialogflow DetectIntent, которая будет объяснена позже в этой главе.
const results = await detectIntent(fileBuffer);
client.emit('results', results);
Это будет асинхронный вызов и вернет обещание с результатами. Эти результаты будут отправлены клиентскому приложению. Клиент может слушать сокет emit следующим образом:socketio.on('results', function (data) { console.log(data); }); - Вот пример второго события, вызванного клиентом, в данном случае потокового события. Теперь я получу данные, когда рекордер WebRTC передает чанки аудиоданных в слушателе ondataavailable. Обратите внимание, что клиентский сокет обернут socket.io-stream для потоковой передачи двоичных данных.
Я получаю аудио чанки плюс дополнительные данные, такие как имя потока (строка). Это можно использовать для хранения временного аудиофайла на сервере, в который я могу передать входящий аудиопоток. Он используется как держатель для активации моей пользовательской реализации Dialogflow. - Как и реализация DetectIntentStreaming, объясненная позже в этой главе:
detectIntentStream(stream, function(results){ client.emit('results', results); });
В этом вызове я передаю поток и функцию обратного вызова для выполнения, как только результаты будут получены. Эти результаты будут отправлены клиентскому приложению.
Клиент может слушать сокет emit следующим образом:socketio.on('results', function (data) { console.log(data); });
Вызовы API к Dialogflow
Я буду использовать клиентский SDK Dialogflow Node.js для ручного обнаружения намерения на основе завершенных аудио буферов и входящих аудиопотоков.
const df = require('dialogflow');
Давайте сначала подготовим клиента и запрос. Позже я смогу изменить запрос, добавив аудиовход:
Листинг 12-6. Подготовка запроса речи
// 1) Генерируем уникальный ID сеанса
const sessionId = uuid.v4();
// 2) Создаем клиент сеанса Dialogflow и путь сеанса
const sessionClient = new df.SessionsClient(); // Предполагаем, что аутентификация настроена
const sessionPath = sessionClient.sessionPath(projectId, sessionId); // Используем projectId
// 3) Формируем базовый объект запроса
const request = {
session: sessionPath,
queryInput: {
// 4) Настраиваем конфигурацию аудио
audioConfig: {
sampleRateHertz: sampleRateHertz, // Частота дискретизации из настроек
encoding: encoding, // Кодировка аудио из настроек
languageCode: languageCode // Код языка из настроек
},
singleUtterance: singleUtterance // true для одиночных, false для потока
}
};- Dialogflow понадобится идентификатор сеанса. Давайте используем UUID для генерации случайного идентификатора https://www.ietf.org/rfc/rfc4122.txt RFC4122 в формате ‘1b9d6bcd-bbfd-4b2d-9b5d-ab8dfbbd4bed’.
- Затем давайте создадим путь сеанса Dialogflow. Путь сеанса можно создать из объекта клиента сеанса Dialogflow. Ему нужен идентификатор сеанса, чтобы сделать сеанс Dialogflow уникальным. И ему нужен идентификатор проекта Google Cloud, который указывает на проект Google Cloud с рабочим агентом Dialogflow.
- Давайте уже настроим объект запроса, который будет использоваться для каждого вызова API Dialogflow. В случае, если этот запрос используется при потоковой передаче аудио, этот запрос будет использоваться как начальный запрос. Это означает, что он сначала подключается к SDK без аудиопотока, но подготавливает API с конфигурациями аудио, которые он может использовать. Впоследствии чанки аудио будут поступать. Ему нужен sessionPath (который теперь будет указывать на клиентский сеанс и конкретного агента Dialogflow). Даже без аудиовхода я уже могу настроить queryInput.
- Поскольку это приложение работает с речью, мне нужно будет установить объект audioConfig. Объект audioConfig требует частоту дискретизации в герцах (это число должно быть таким же, как desiredSampleRateHertz из вашего клиентского кода). Он требует languageCode, который содержит язык произнесенного текста, и это должен быть язык, установленный в Dialogflow. Ему нужна кодировка, которая также должна быть такой же, как кодировка, используемая в клиенте. В моих демонстрациях кода Self Service Kiosk я использую конфигурации из файла .env.
Теперь давайте рассмотрим оба вызова, DetectIntent и StreamingDetectIntent.
DetectIntent
После того, как Dialogflow обнаружил намерение, бэкэнд-приложение получает результаты сопоставления намерений после отправки и обработки всего аудио. Я создаю асинхронную функцию, которая принимает AudioBuffer и добавляет его к запросу. Затем я вызываю detectIntent, передавая запрос. Он возвращает обещание, которое можно цепочкой.
Листинг 12-7. Использование Socket.IO для отправки аудиопотоков с фронтенда на бэкэнд
async function detectIntent(audioBuffer){ // Принимаем буфер аудио
request.inputAudio = audioBuffer; // Добавляем аудио в запрос
const responses = await sessionClient.detectIntent(request); // Вызываем detectIntent
return responses; // Возвращаем результат
};Это вернет DetectIntentResponse. Он содержит queryResult. Если вы передали в DetectIntentRequest конфигурацию выходного аудио, вы сможете извлечь байты аудиоданных, сгенерированные на основе значений текстовых ответов платформы по умолчанию, найденных в поле queryResult.fulfillmentMessages. Если существует несколько текстовых ответов платформы по умолчанию, они будут объединены при генерации аудио. Если текстовых ответов платформы по умолчанию не существует, сгенерированное аудиосодержимое будет пустым.
StreamingDetectIntent
StreamingDetectIntent выполняет двунаправленное потоковое обнаружение намерений: получает результаты во время отправки аудио. Этот метод доступен только через API gRPC (не REST).
Листинг 12-8. Обнаружение намерения на основе аудиопотока
// 1) Асинхронная функция для потокового обнаружения
async function detectIntentStream(audioStream, callback) { // Принимает аудиопоток и колбэк
// 2) Создаем поток для обнаружения намерений
const stream = sessionClient.streamingDetectIntent()
.on('data', function(data){ // Слушаем событие 'data'
// 3) Обрабатываем полученные данные
if (data.recognitionResult) { // Если есть промежуточный результат распознавания
console.log(
`Промежуточная транскрипция: ${data.recognitionResult.transcript}`
);
} else if (data.queryResult) { // Если обнаружено намерение
console.log(`Обнаружено намерение:`);
callback(data); // Вызываем колбэк с полным результатом
}
})
// 4) Обрабатываем ошибки
.on('error', (e) => {
console.log('Ошибка потока:', e);
callback(null, e); // Передаем ошибку в колбэк
})
// Обрабатываем завершение потока
.on('end', () => {
console.log('Поток завершен');
});
// 5) Отправляем начальный запрос с конфигурацией аудио
stream.write(request);
// 6) Передаем аудиопоток в поток Dialogflow
// Используем pump для управления потоками (требует 'pump' npm пакет)
// await pump(audioStream, stream); // Раскомментируйте, если используете pump
// Альтернативно, если pump не используется, можно передавать вручную
// Важно обрабатывать 'end' и 'error' для audioStream
audioStream.on('data', (chunk) => {
stream.write({ inputAudio: chunk });
});
audioStream.on('end', () => {
stream.end(); // Завершаем поток Dialogflow, когда аудио закончилось
});
audioStream.on('error', (err) => {
console.error('Ошибка чтения аудиопотока:', err);
stream.end(); // Завершаем поток Dialogflow при ошибке
});
// 7) Здесь мы не можем напрямую вернуть 'await', так как поток асинхронный.
// Результаты будут возвращены через колбэк.
};- Я создаю асинхронную функцию, которая принимает AudioBuffer и добавляет его к запросу, а имя функции обратного вызова будет выполняться с результатами, как только API получит результаты.
- Выполните вызов streamingDetectIntent().
- Существует слушатель события on('data'), который выполняется, как только аудио чанки передаются. Вы можете создать некоторую условную логику здесь; если в ответе есть data.recognitionResult, то распознается промежуточная транскрипция. В противном случае, вероятно, было обнаружено намерение (или было вызвано резервное намерение, если совпадения не было). Я возвращаю результаты, выполняя функцию обратного вызова.
- Вы также можете слушать события error, когда что-то пошло не так с запросом. Или вы можете слушать события end, когда потоковая передача в Dialogflow остановилась.
- Как это работает: мы сообщим API Dialogflow, что будет вызов streamingDetectIntent со всеми queryInput и audioConfigs, которые можно получить из запросов. Впоследствии все остальные сообщения, которые придут, будут содержать аудиопоток через inputAudio.
- Давайте используем небольшой модуль node под названием pump, который соединяет потоки вместе и уничтожает их все, если один закрывается.
- Здесь я преобразую поток, так что запрос теперь также будет содержать inputAudio с потоковой передачей audioBuffer.
Это вернет StreamingIntentResponse. Он содержит queryResult.
Если вы передали в StreamingDetectIntentRequest и конфигурацию выходного аудио, вы сможете извлечь байты аудиоданных, сгенерированные на основе значений текстовых ответов платформы по умолчанию, найденных в поле queryResult.fulfillmentMessages. Если существует несколько текстовых ответов платформы по умолчанию, они будут объединены при генерации аудио. Если текстовых ответов платформы по умолчанию не существует, сгенерированное аудиосодержимое будет пустым.
Извлечение аудиорезультатов из Dialogflow и их воспроизведение в вашем браузере
Когда вы делаете вызов Text to Speech, либо с помощью API Google Cloud Text-to-Speech, либо используя встроенный возврат речи из Dialogflow, он вернет байтовые данные аудио. И Cloud TTS, и Dialogflow могут быть вызваны из серверного кода. Чтобы передать и воспроизвести это в браузере, вы можете использовать WebSockets. Как только AudioBuffer (ArrayBuffer в коде JavaScript браузера) будет возвращен клиенту, он может быть воспроизведен с помощью методов WebRTC.
Рисунок 12-4 — это пример потока браузера с использованием Dialogflow. В этом примере пользователь говорит в микрофон (аналогично предыдущим примерам), но Dialogflow возвращает AudioBuffer в качестве результата.

Рисунок 12-4. Пользователь передает свой голос из клиентского приложения на серверное приложение, подключенное к Dialogflow. Как только Dialogflow сопоставит намерение, результирующий аудиопоток будет отправлен обратно в клиентское приложение для воспроизведения в браузере
Теперь пора сосредоточиться на последней части, убедившись, что мы получаем аудио буфер как обнаруженный результат из Dialogflow, передавая его обратно клиенту через Socket.IO и убедившись, что он будет автоматически воспроизводиться.
Dialogflow также может возвращать AudioBuffers, как только он обнаружит намерение. Вам нужно будет только указать outputAudioConfig в Dialogflow DetectIntentRequest, чтобы также получить AudioBuffer как часть ответа:
outputAudioConfig: {
audioEncoding: `OUTPUT_AUDIO_ENCODING_LINEAR_16`,
},Ответ на запрос detect intent имеет тип DetectIntentResponse. Обычно, когда вы обнаруживаете намерения с текстовым содержимым, он заполняет поле fulfillmentMessages в queryResult. Но когда вы предоставляете устное аудио в качестве содержимого, поле DetectIntentResponse.outputAudio заполняется аудио на основе значений текстовых ответов платформы по умолчанию, найденных в поле DetectIntentResponse.queryResult.fulfillmentMessages.
Если существует несколько текстовых ответов платформы по умолчанию, они будут объединены при генерации аудио. Если текстовых ответов платформы по умолчанию не существует, сгенерированное аудиосодержимое будет пустым.
Клиентский код для воспроизведения аудио
В вашем клиентском приложении вам нужно будет убедиться, что вы снова загружаете socket.io и socket.io-stream. Socket.IO — это библиотека связи в реальном времени, двунаправленная, основанная на событиях. Одним из транспортов, который она использует, являются WebSockets, но она также предоставляет другие транспорты (XHR/JSONP), не только как резервный вариант, но и для ситуаций, когда WebSockets не поддерживаются/не требуются/не желательны.
Вы можете загрузить это из CDN.
Листинг 12-9. Загрузка Socket.IO из CDN
<script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/2.3.0/socket.io.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io-stream/0.9.1/socket.io-stream.js"></script>Как только клиент подключится к серверу, я могу начать слушать событие, которое было вызвано с сервера. В моем случае это событие 'results'. Оно запустится, как только данные со стороны сервера будут получены в браузере. Это вызовет мой пользовательский метод playOutput, который я покажу позже.
Листинг 12-10. Как только результаты будут отправлены обратно клиенту, воспроизведите аудио
const socketio = io();
const socket = socketio.on('connect', function() {}); // Устанавливаем соединение
socketio.on('results', function (data) { // Слушаем событие 'results'
console.log(data);
playOutput(data); // Вызываем функцию воспроизведения
});Листинг 12-11 показывает код для воспроизведения вывода в вашем браузере с динамиков вашего устройства.
Листинг 12-11. Как воспроизвести аудиопоток в браузере
// 1) Функция для воспроизведения аудио буфера
function playOutput(arrayBuffer){
let audioContext = new AudioContext(); // Создаем аудио контекст
let outputSource;
try {
if(arrayBuffer.byteLength > 0){ // Проверяем, что буфер не пустой
// 2) Декодируем ArrayBuffer в AudioBuffer
audioContext.decodeAudioData(arrayBuffer,
function(buffer){ // Успешное декодирование
// 3) Возобновляем аудио контекст (для автовоспроизведения) и воспроизводим
audioContext.resume().then(() => { // Используем Promise для resume()
outputSource = audioContext.createBufferSource(); // Создаем источник буфера
outputSource.connect(audioContext.destination); // Подключаем к выходу (динамикам)
outputSource.buffer = buffer; // Устанавливаем декодированный буфер
outputSource.start(0); // Начинаем воспроизведение немедленно
// Добавляем обработчик 'onended' для очистки после воспроизведения
outputSource.onended = () => {
console.log('Audio playback finished.');
// audioContext.close(); // Можно закрыть контекст, если он больше не нужен
};
}).catch(e => console.error("Error resuming audio context:", e));
},
function(e){ // Ошибка декодирования
console.log('Error decoding audio data', e);
}
);
}
} catch(e) {
console.log('Error playing audio:', e);
}
}- Вот функция playOutput, которая принимает arrayBuffer, полученный мной из бэкэнд-кода. Здесь я могу создать новый объект AudioContext. Интерфейс AudioContext представляет собой граф обработки аудио, построенный из аудиомодулей, связанных вместе, представленных AudioNode. Аудиоконтекст управляет как созданием содержащихся в нем аудиоузлов, так и выполнением обработки или декодирования аудио.
- Теперь давайте создадим аудиоисточник для Web Audio API из ArrayBuffer. Декодированный AudioBuffer передискретизируется до частоты дискретизации AudioContext, а затем передается в обратный вызов.
- Пользовательский агент может блокировать автовоспроизведение, поэтому я сначала запускаю audioContext.resume как трюк. Затем создайте новый AudioBufferSourceNode для подключения к месту назначения audioContext, которым в нашем случае являются динамики устройства. Свойство buffer интерфейса AudioBufferSourceNode предоставляет возможность воспроизводить аудио с использованием AudioBuffer в качестве источника звуковых данных. Наконец, давайте воспроизведем аудио.
Внимание: Будьте осторожны при использовании Dialogflow detectIntent для потокового аудио. Когда вы используете простые вызовы detectIntent без потоковой передачи, вы останавливаете микрофон и будете воспроизводить аудио буфер TTS. Однако, когда вы выполняете потоковую передачу, вы держите микрофон открытым. Вы не хотите попасть в бесконечный цикл, когда синтезатор речи записывает новые потоки на основе ответа TTS через ваш микрофон. :-)
AudioBufferSourceNode имеет обработчик события onended, который запустится, как только AudioBufferSourceNode перестанет воспроизводить аудио. Если вы хотите решить предыдущую проблему, вы можете установить логический флаг isPlaying, который должен блокировать рекордер от отправки потока на бэкэнд, когда он установлен в true.
Поздравляю! Прочитав эту главу, вы теперь знаете, как создать сквозное решение для потоковой передачи аудио с микрофона на сервер, а также передавать и воспроизводить аудиорезультаты обратно в браузере!
Резюме
Эта глава содержит информацию о создании вашего собственного голосового ИИ на вашем веб-сайте или в приложении по сравнению с использованием виртуального помощника, такого как Google Assistant.
Она рассматривает следующие задачи:
- Вы хотите создать голосовой ИИ на своем собственном веб-сайте или в приложении путем потоковой передачи аудио с микрофона браузера на веб-сервер.
- Вы хотите интегрировать голосовой ИИ в свой собственный веб-сервер и обнаруживать намерения по аудиопотоку, полученному с микрофона браузера.
- Вы хотите встроить голосовой ИИ в свой собственный веб-сайт и воспроизводить аудиорезультаты в вашем браузере.
Полный рабочий пример, относящийся к разделам книги, можно найти здесь:
https://github.com/dialogflow/selfservicekiosk-audio-streaming
Вы можете запустить демо и поиграть с ним по этому URL:
http://selfservicedesk.appspot.com/
Дополнительные материалы
- Библиотека RecordRTC
https://github.com/muaz-khan/RecordRTC - Библиотека Socket.IO
https://www.npmjs.com/package/socket.io - Модуль Socket.io-Stream
https://www.npmjs.com/package/socket.io-stream - Моя запись в блоге о том, как создать SelfServiceKiosk
https://medium.com/google-cloud/building-your-own-conversational-voice-ai-with-dialogflow-speech-to-text-in-web-apps-part-i-b92770bd8b47 - Кодовая база демо SelfServiceKiosk (клиент)
https://github.com/dialogflow/selfservicekiosk-audio-streaming/blob/master/client/src/app/microphone/microphone.component.ts - Кодовая база демо Self Service Kiosk (сервер)
https://github.com/dialogflow/selfservicekiosk-audio-streaming/blob/master/server/server.js - Пример файла package.json, который можно использовать для этой главы
https://github.com/dialogflow/selfservicekiosk-audio-streaming/blob/master/examples/package.json - Поиграйте и протестируйте демо Service Kiosk
http://selfservicedesk.appspot.com/ - Пакет npm Dialogflow
https://www.npmjs.com/package/dialogflow - Пример SimpleServer
https://github.com/dialogflow/selfservicekiosk-audio-streaming/blob/master/examples/simpleserver.js - Примеры клиентской стороны
https://github.com/dialogflow/selfservicekiosk-audio-streaming/tree/master/examples - Документация по AudioConfig
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2#google.cloud.dialogflow.v2.InputAudioConfig - Документация по DetectIntentResponse
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2#google.cloud.dialogflow.v2.DetectIntentResponse - Документация по StreamingDetectResponse (для Speech-to-Text, так как Dialogflow использует его)
https://cloud.google.com/speech-to-text/docs/reference/rpc/google.cloud.speech.v1#google.cloud.speech.v1.StreamingRecognizeResponse - Документация по DetectIntentRequest в Dialogflow
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2#detectintentrequest - Руководство по обнаружению намерений с аудио
https://cloud.google.com/dialogflow/es/docs/how/detect-intent-tts - Документация по AudioBufferSourceNode
https://developer.mozilla.org/en-US/docs/Web/API/AudioBufferSourceNode
Другие статьи по этой теме:
- Практическое руководство по созданию агентов ИИ
- Выявление и масштабирование сценариев использования ИИ
- Агенты ИИ