Глава 13: Сбор и мониторинг аналитики разговоров
Думаю, мы все с этим сталкивались. Вы разговариваете с виртуальным помощником или пишете в чат-бот, а виртуальный агент не понимает, что вы имеете в виду. Он просит вас повторить, возвращает запасной вариант или, что еще хуже, дает неправильный ответ! Это паршивый клиентский опыт. Когда такое случается слишком часто, вы рискуете тем, что ваши посетители больше не вернутся; «этот бот не работает». На самом деле, часто чат- или голосовой бот работал, но его научили отвечать на другие типы вопросов.
Конечно, с хорошим дизайном UX разговора вы могли бы направить ваши диалоги к успешному результату. Например, когда вы запускаете виртуального агента, он не должен просто показывать вам приветственное сообщение. Он также должен рассказать вам, что он может для вас сделать. Так что, скорее всего, ваши посетители будут задавать правильные типы вопросов.
Вы создаете чат-бота или виртуального помощника. Какую пользу он принесет вашим посетителям? Какую проблему он решит? Как бренд или бизнес, у вас, скорее всего, есть эти данные. Это ваша первая попытка создать виртуального агента? Тогда изучите ваши данные из других каналов, чтобы лучше понять ваших клиентов. У вас есть контакт-центр и аудиозаписи? Вы отслеживаете социальные сети? Входящую электронную почту? Какой самый распространенный вопрос задают люди? Какая тема популярна? На что жалуются люди?
При создании голосовых и чат-ботов важно как можно быстрее запустить их в производство, но при этом собирать аналитику. Слишком часто я слышу от клиентов: «Аналитика чат-бота — это у нас в дорожной карте для второй версии. Мы хотим сначала усовершенствовать разговоры». Так быть не должно. Аналитика бота — это не функция «приятно иметь» для отображения на дашборде; она необходима для улучшения вашего клиентского опыта.
Не тратьте год на совершенствование разговоров, когда вы можете узнать больше всего из вашего существующего (живого) трафика. Даже если вы запуститесь всего с несколькими основными темами и будете напрямую отслеживать входящие вопросы, вы сможете со временем развивать своего чат-бота и делать его намного умнее. Вы можете реализовать другие важные темы на основе количества вхождений. Таким образом, вы можете узнать, как ваши клиенты думают о вашем бренде и как вы можете со временем улучшить своего виртуального агента.
Многие компании уже знакомы со сбором аналитики. Они полагаются на данные веб-аналитики, такие как показатели кликов, просмотры страниц и продолжительность сеансов, для получения информации о поведении клиентов, обычно собираемой с помощью таких инструментов, как Google Analytics. Вот почему аналитика разговоров намного мощнее веб-аналитики. Акцент больше не будет делаться на том, как пользователи реагируют на то, что им представлено, а скорее на том, какое «намерение» они передают через естественный язык. Фактически, рынок прогнозирует, что аналитика разговоров вырастет с 4,2 млрд долларов в 2019 году до 15,7 млрд долларов в 2024 году!
Существует четыре типа метрик, которые вы можете захотеть отслеживать или собирать.
Метрики, связанные с разговором
Метрики, связанные с разговором, дадут вам ответы на вопросы, например, что было сказано вашими конечными пользователями, когда и где (на какой платформе). Для этого вам понадобится способ хранения всех ваших разговоров. Хранилище данных, такое как BigQuery, — отличный способ собрать все ваши транскрипты чатов.
Хранилище данных — это система, используемая для отчетности и анализа данных. Подумайте о базе данных, но гораздо более обширной, куда вы можете подключить множество источников. Вы можете хранить все структурированные данные, которые вам нравятся, в вашем хранилище данных. Подумайте о данных веб-сайта, журналах веб-сайта, данных входа в систему, рекламных данных и ваших разговорах с чат-ботом Dialogflow. Чем больше у вас данных, тем лучше вы сможете понять своих клиентов.
Метрики оценки клиентов
Многие компании используют рейтинги NPS, CES и CSAT в качестве методов исследования для выяснения лояльности своих клиентов, задавая простые вопросы. Вы можете реализовать это в своем агенте.
Метрики сеанса чата и воронки
Вы можете использовать Dialogflow или Chatbase, чтобы получить поток сеанса, который покажет вам воронку чата. Он визуально суммирует пути разговора, которые прошли ваши конечные пользователи при взаимодействии с вашим агентом.
Метрики работоспособности модели бота
При работе с Dialogflow он будет использовать машинное обучение для понимания высказываний пользователя и сопоставления их с намерением (классификация намерений). С помощью метрик модели бота можно будет рассчитать качество базовой модели машинного обучения вашего агента.
Сбор метрик, связанных с разговором, для хранения в BigQuery
Инструменты, такие как Dialogflow, имеют собственную встроенную аналитику. Вы можете просматривать простую аналитику, указав дату и время. Однако вы можете захотеть создать свой собственный репозиторий в хранилище данных для сбора мощной системы аналитики. Примером хранилища данных является BigQuery. Возможно, вы уже используете его для данных своей рекламы.
BigQuery
BigQuery — это полностью управляемое бессерверное хранилище данных, которое обеспечивает масштабируемый анализ петабайтов данных. Это бессерверное программное обеспечение как услуга (SaaS), которое поддерживает запросы с использованием ANSI SQL.
Использование аналитики BigQuery по сравнению со встроенной аналитикой Dialogflow имеет несколько преимуществ, которые очень важны для предприятий, которым приходится иметь дело с соответствием требованиям (например, GDPR). Когда вы храните разговоры вашего чат-бота в BigQuery, вы можете:
- Выбирать, где хранятся данные
- Выбирать, как долго хранятся данные
- Создавать резервную копию ваших разговорных данных
- Удалять конфиденциальные данные PII из вашего набора данных перед хранением (например, согласно GDPR, вы не можете хранить данные PII)
- Создавать гораздо больше точек данных (например, переводы чатов, настроения пользователей)
- Объединять разговоры вашего чат-бота с другими ценными данными
Примечание: Если вы выбираете это решение из соображений соответствия требованиям, вы, вероятно, также захотите отключить ведение журнала данных на панели настроек Dialogflow.
Это также будет означать, что вы не увидите никаких данных на вкладках аналитики и истории в консоли Dialogflow.
Почему выгодно объединять аналитику вашего чат-бота с другими данными? Потому что вы можете создавать омниканальные впечатления и инсайты с этим. Представьте себе пользователя, посещающего ваш банковский веб-сайт. Пользователь вошел в систему и просматривает веб-страницы банка об ипотеке. Неделю спустя пользователь возвращается на веб-сайт и начинает чат с банковским чат-ботом. (Это может быть даже голосовой агент по телефону.) Пользователь объясняет, что у него мошеннические транзакции, и чат-бот предлагает их заблокировать. Прежде чем разговор закончится, чат-бот предоставляет ипотечное предложение. Поскольку данные чата плюс данные рекламы веб-сайта были сохранены в одном хранилище данных, было легко установить эту связь.
Точки сбора
Давайте рассмотрим несколько точек сбора, которые помогут собрать полезные сведения из разговоров с ботами. Мы можем использовать эти метрики для запроса наших наборов данных.
Идентификатор сеанса
Идентификатор сеанса удобен для поиска всех транскриптов определенного сеанса, для чтения полного транскрипта разговора и для определения общего числа уникальных пользователей.
Инструменты для создания ботов, такие как Dialogflow, будут поддерживать путь сеанса для каждого сеанса чата. Этот путь сеанса чата привязан к вашей учетной записи агента (поэтому никто другой не сможет подсмотреть), и он уникален, так как содержит uuid.
const sessionId = uuid.v4();
const sessionClient = new df.SessionsClient();
const sessionPath = sessionClient.sessionPath(projectId, sessionId);
При использовании BigQuery вы должны собирать каждое входящее высказывание пользователя с его идентификатором сеанса. Как только вы узнаете конкретный идентификатор сеанса, вы сможете извлечь полный транскрипт чата со всеми другими полями данных, которые были сохранены. SQL-запрос для извлечения сеанса будет выглядеть так:
SELECT * FROM `chat_msg_table` WHERE SESSION_ID = 'projects/myagent/agent/sessions/db33b345-663c-4867-8021-fecd50c5e8b1' ORDER BY DATETIME
Вернуть все из таблицы сообщений чата, где идентификатор сеанса равен некоторой строке, и он будет упорядочен по дате и времени, так что первое сообщение сеанса будет отображаться первым.
Дата/Временная метка
Вам понадобится дата/временная метка для поиска всех транскриптов на основе определенного времени и для расчета полной продолжительности сеанса.
Вы можете установить свою собственную дату/временную метку перед сохранением объекта в BigQuery. Убедитесь, что он принимает формат, который ожидает ваше хранилище данных:
const timestamp = new Date().getTime()/1000;
Каждая дата и временная метка должны храниться вместе с идентификатором сеанса и другими его метриками в BigQuery. С этим вы можете легко выполнить SQL-запрос, который вернет все из таблицы сообщений чата, где дата и время находятся между 1 августа и 10 августа, упорядоченные по убыванию даты и времени, так что самое новое будет первым:
SELECT * FROM `chat_msg_table` WHERE DATETIME > '2020-08-01 10:00:00' AND POSTED < '2020-08-10 00:00:00' ORDER BY DATETIME DESC
Оценка тональности
Вы можете использовать оценку тональности для поиска всех транскриптов на основе определенной тональности. Например, вас могут заинтересовать самые «негативные» транскрипты чатов за неделю, чтобы выяснить, почему ваши клиенты расстроены.
Инструменты, такие как Dialogflow, могут иметь включенную тональность для определенных языков. Однако, когда вы хотите использовать анализ тональности неподдерживаемых языков, таких как «голландский», вам придется сначала перевести высказывания ваших пользователей.
Это то, что вы могли бы сделать с помощью следующих инструментов:
- Cloud Translate
- Cloud Natural Language
const sentiment_score: queryTextSentiment.score;
const sentiment_magnitude: queryTextSentiment.magnitude;
Оценка тональности документа указывает на общую эмоцию документа. Величина тональности документа указывает, сколько эмоционального содержания присутствует в документе, и это значение часто пропорционально длине документа.
Каждая оценка тональности должна храниться вместе с идентификатором сеанса и другими его метриками в хранилище данных. С этим вы можете легко выполнить SQL-запрос, который вернет все из таблицы сообщений чата, где оценка тональности отрицательна (ниже 0), и он будет упорядочен по оценке тональности, по возрастанию от худшего к лучшему:
SELECT * FROM `chat_msg_table` WHERE SENTIMENT_SCORE < 0 ORDER BY SENTIMENT_SCORE ASC
Совет: Как следует работать с сарказмом? На самом деле, сарказм даже человеку иногда трудно понять. Однако у нас есть инструменты в Google Cloud для создания модели с пользовательской тональностью. Подумайте о высказывании пользователя типа «Ура! Игра Beyond Good and Evil снова отложена! Отличная работа!»
Встроенная тональность Google Cloud, вероятно, обнаружит, что это очень позитивно из-за слов «Ура!» и «Отличная работа!». Возможно, это будет даже 90% (0,9) оценка тональности. Однако мы хотим классифицировать это как очень негативное, потому что мы говорим здесь об отложенных играх, что не весело, поэтому мы ожидали бы отрицательную оценку тональности. Хорошо знать, что вы можете обучать свои собственные модели тональности с помощью AutoML Natural Language в Google Cloud. У него есть функция: анализ тональности. Модель проверяет документ и определяет преобладающее эмоциональное мнение в нем, особенно для определения отношения автора как положительного, отрицательного или нейтрального.
Язык и ключевое слово
Вы можете использовать язык диалога для поиска всех транскриптов для определенного языка. Например, вас может заинтересовать поиск транскрипта на основе его языка. Возможно, вы захотите объединить это с определенным ключевым словом.
В Dialogflow вы можете извлечь languageCode в queryResult из detectIntentResponse:
queryResult.languageCode
Вам не нужно хранить отдельные ключевые слова; вы можете извлечь это из высказывания пользователя. Позже в этом разделе мы обсудим майнинг тем. С помощью этой техники вы можете хранить ключевые слова в отдельном столбце BigQuery.
Каждая языковая метрика должна храниться вместе с идентификатором сеанса, высказыванием пользователя и другими метриками в хранилище данных. С этим вы можете легко выполнить SQL-запрос, который вернет все из таблицы сообщений чата, где код языка равен «NL», и слово, которое вы ищете, — «мошенничество».
SELECT * FROM `chat_msg_table` WHERE LANGUAGE = "en-us" AND USER_UTTERANCE LIKE '%my keyword%'
Платформа
Вы можете использовать настройку платформы для поиска всех транскриптов для определенной платформы. Например, вас могут заинтересовать последние разговоры в Google Assistant.
Вам нужно будет установить метрику платформы самостоятельно на основе используемой реализации. Некоторые реализации могут иметь свои собственные настройки, такие как Google Assistant, который имеет конфигурации для каждой поверхности устройства: Surface Capabilities.
Когда вы создаете свой собственный веб-интерфейс с интегрированным чатом, вам нужно будет установить имя платформы самостоятельно.
const platform = 'web';
Каждая метрика платформы должна храниться вместе с идентификатором сеанса и другими его метриками в BigQuery. С этим вы можете легко выполнить SQL-запрос, который вернет все из таблицы сообщений чата, где платформа равна «web»:
SELECT * FROM `chat_msg_table` WHERE PLATFORM = "web"
Обнаружение намерения
Когда Dialogflow обнаруживает ваше намерение, он может содержать различную ценную информацию, которую вы хотели бы хранить в своем хранилище данных. Например, это поможет вам выяснить в транскрипте, вернул ли бот неправильный ответ.
Следующие точки данных вы можете захотеть хранить: имя обнаруженного намерения, порог уверенности (уровень уверенности, на котором Dialogflow основывал свое совпадение намерения), является ли это резервным вариантом, и является ли это концом взаимодействия (чтобы определить, является ли это концом потока).
В Dialogflow вы можете извлечь имя обнаруженного намерения в queryResult.intent из detectIntentResponse:
queryResult.intent.displayName
В Dialogflow вы можете извлечь логическое значение, если это резервный вариант, в queryResult.intent из detectIntentResponse:
queryResult.intent.isFallback
В Dialogflow вы можете извлечь логическое значение, если это конец взаимодействия, в queryResult.intent из detectIntentResponse:
queryResult.intent.endInteraction
В Dialogflow вы можете извлечь порог уверенности в queryResult из detectIntentResponse:
queryResult.intentDetectionConfidence
Решения
В этом разделе я представлю три популярных решения для сбора метрик.
Создание платформы для сбора метрик, связанных с разговором, и редактирования конфиденциальной информации
Для создания решения для сбора метрик, связанных с разговором, вам нужно будет использовать следующие сервисы Google Cloud:
- Dialogflow Essentials (уровень с оплатой по мере использования)
- BigQuery
- Pub/Sub (канал обмена сообщениями)
- DLP API (для редактирования информации перед ее сохранением)
- Cloud Functions (код, который будет запускаться по событиям)
Давайте рассмотрим архитектуру, показанную на Рисунке 13-1.
Когда клиент пишет текст в чат-бот или разговаривает с голосовым агентом, агент Dialogflow сопоставляет ответ (с помощью метода detectIntent). Сюда входит информация, такая как высказывание пользователя, ответ Dialogflow, сопоставленное намерение и так далее, но более критично также идентификатор сеанса. В реальном времени мы можем отправить данные в канал обмена сообщениями (Pub/Sub), чтобы другие программные части могли регистрироваться и слушать входящие данные (через Cloud Function на основе событий).
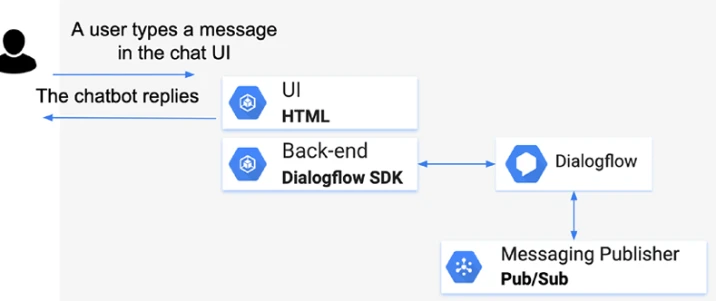
Рисунок 13-1. Использование архитектуры с Pub/Sub для создания конвейера данных (часть 1)
Облачная функция имеет подписку на канал Pub/Sub. Обратите внимание на Рисунок 13-2; каждый раз, когда приходит сообщение, оно будет передано в DLP API для удаления конфиденциальной информации перед сохранением данных в BigQuery.
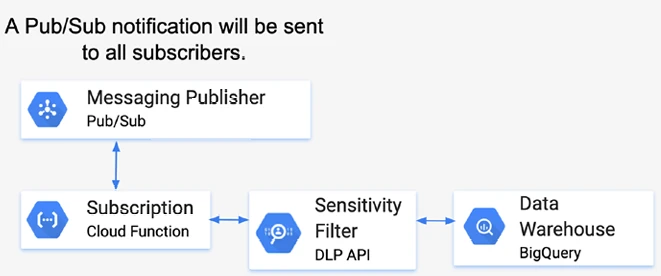
Рисунок 13-2. Использование архитектуры с Pub/Sub для создания конвейера данных (часть 2)
Как только данные будут сохранены в BigQuery, вы сможете выполнять запросы, чтобы получить, например, топ-10 высказываний пользователя, которые вернулись в резервный вариант или где настроение пользователя было негативным. Вы также можете выполнить запрос, чтобы выяснить, какое намерение было самым популярным. Или, если у вас есть идентификатор сеанса, вы можете запросить для извлечения полного транскрипта чата.
Во-первых, нам нужно будет включить следующие API. Мы можем сделать это из командной строки:
gcloud services enable bigquery-json.googleapis.com \
cloudfunctions.googleapis.com \
dlp.googleapis.comПосле этого нам нужно будет убедиться, что у нас есть правильные разрешения. Мы запустим скрипт, который может создавать наборы данных и таблицы в BigQuery; нам нужно будет изменить права доступа пользователя на панели IAM & Admin. Перейдите на страницу IAM.
Найдите сервисный аккаунт Dialogflow, который используется Dialogflow. (Вы можете найти сервисный аккаунт (адрес электронной почты) на странице Dialogflow ➤ Настройки ➤ Общие.) На странице IAM отредактируйте сервисный аккаунт, который использует Dialogflow (см. Рисунок 13-3).
Предоставьте вашему сервисному аккаунту следующие разрешения:
- Владелец данных BigQuery
- Пользователь задания BigQuery
- Администратор Pub/Sub
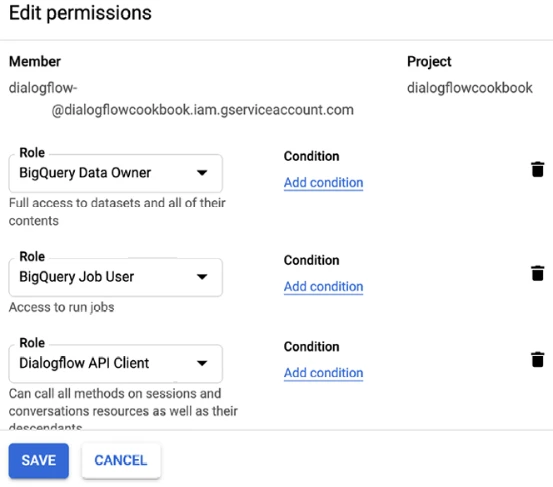
Рисунок 13-3. Назначение правильных ролей вашему аккаунту IAM
Затем нам нужно будет создать Cloud Function, которая будет слушать канал обмена сообщениями. Нажмите Cloud Functions ➤ Создать функцию.
Укажите следующие настройки; вместо [project_id] используйте свой собственный идентификатор проекта Google Cloud, как показано на Рисунке 13-4.
- Имя: chatanalytics
- Выделенная память: 256 МБ
- Триггер: Cloud Pub/Sub
- Тема Pub/Sub: projects/[project_id]/topics/chatbotanalytics
- Функция для выполнения: subscribe
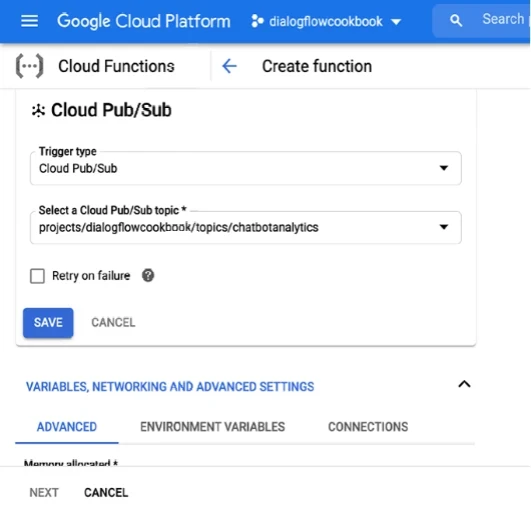
Рисунок 13-4. Подготовка Cloud Function в конвейере данных
Щелкните вкладку переменных среды, чтобы добавить следующую переменную среды (см. Рисунок 13-5):
- Переменные среды: GCLOUD_PROJECT - [project_id]
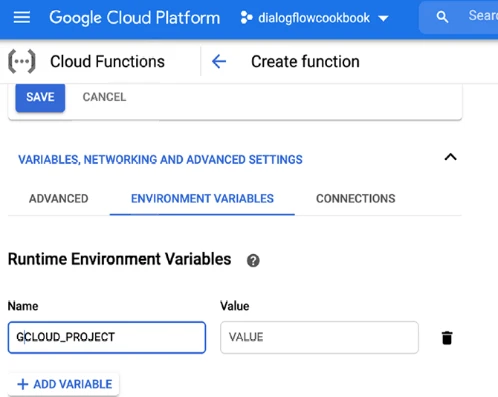
Рисунок 13-5. Установка переменных среды в Cloud Function
Листинг 13-1 показывает содержимое package.json для импорта библиотек BigQuery и DLP.
Листинг 13-1. package.json
{
"name": "chatanalytics",
"version": "1.0.2",
"dependencies": {
"@google-cloud/bigquery": "^5.0.0",
"@google-cloud/dlp": "^1.2.0" // Используйте совместимую версию
}
}Код Cloud Function index.js будет выглядеть как Листинг 13-2.
Листинг 13-2. index.js
//1) Импорт библиотек BigQuery и DLP
const { BigQuery } = require('@google-cloud/bigquery');
const DLP = require('@google-cloud/dlp');
//2) Установка констант для указания на набор данных, имя таблицы
const projectId = process.env.GCLOUD_PROJECT; // Получаем ID проекта из переменных среды
const bqDataSetName = 'chatanalytics'
const bqTableName = 'chatmessages';
const bq = new BigQuery(); // Инициализируем BigQuery
const dlp = new DLP.DlpServiceClient(); // Инициализируем DLP
// Использование набора данных: chatanalytics
const dataset = bq.dataset(bqDataSetName);
// Использование таблицы BigQuery: chatmessages
const table = dataset.table(bqTableName);
//3) Функция detectPIIData для обнаружения и редактирования PII
var detectPIIData = async function(text, callback) {
// Минимальная вероятность, необходимая для возврата совпадения
const minLikelihood = 'LIKELIHOOD_UNSPECIFIED';
//4) Типы информации для сопоставления
const infoTypes = [
{name: 'PERSON_NAME'}, {name: 'FIRST_NAME'}, {name: 'LAST_NAME'},
{name: 'MALE_NAME'}, {name: 'FEMALE_NAME'}, {name: 'IBAN_CODE'},
{name: 'IP_ADDRESS'}, {name: 'LOCATION'}, {name: 'SWIFT_CODE'},
{name: 'PASSPORT'}, {name: 'PHONE_NUMBER'},
{name: 'NETHERLANDS_BSN_NUMBER'}, {name: 'NETHERLANDS_PASSPORT'} // Пример дополнительных типов
];
// Конфигурация трансформации, заменяющая конфиденциальную информацию типом информации
const replaceWithInfoTypeTransformation = {
primitiveTransformation: {
replaceWithInfoTypeConfig: {},
},
};
// Запрос на деидентификацию
const request = {
parent: dlp.projectPath(projectId),
item: { value: text },
deidentifyConfig: {
infoTypeTransformations: {
transformations: [replaceWithInfoTypeTransformation],
},
},
inspectConfig: {
minLikelihood: minLikelihood,
infoTypes: infoTypes,
},
};
// Запуск редактирования строки
try {
//5) Вызов API DLP для деидентификации
const [response] = await dlp.deidentifyContent(request);
const resultString = response.item.value;
console.log(`REDACTED TEXT: ${resultString}`);
if (resultString) {
callback(resultString); // Вызов колбэка с отредактированным текстом
} else {
callback(text); // Если редактирование не произошло, вернуть оригинал
}
} catch (err) {
console.error(`Error in deidentifyContent: ${err.message || err}`);
callback(text); // В случае ошибки вернуть оригинальный текст
}
};
//6) Функция для вставки строк в BigQuery
var insertInBq = function(row){
console.log("Inserting row:", row);
table.insert(row, function(err, apiResponse){ // Используем метод insert
if (!err) {
console.log("[BIGQUERY] - Saved.");
} else {
console.error("BigQuery Insert Error:", err);
}
});
};
//7) Экспортируемая функция 'subscribe', которая будет триггером Pub/Sub
exports.subscribe = (pubSubMessage, context) => { // Принимаем pubSubMessage и context
console.log("Received Pub/Sub message:", Buffer.from(pubSubMessage.data, 'base64').toString());
const buffer = Buffer.from(pubSubMessage.data, 'base64').toString(); // Декодируем данные из Base64
var buf = JSON.parse(buffer); // Парсим JSON
// Создаем объект строки для BigQuery
var bqRow = {
BOT_NAME: buf.botName,
POSTED: buf.posted ? new Date(buf.posted).toISOString() : null, // Преобразуем временную метку в ISO строку
INTENT_RESPONSE: buf.intentResponse ? JSON.stringify(buf.intentResponse) : null, // Преобразуем массив сообщений в строку
INTENT_NAME: buf.intentName,
IS_FALLBACK: buf.isFallback,
IS_END_INTERACTION: buf.isEndInteraction,
CONFIDENCE: buf.confidence,
PLATFORM: buf.platform,
SESSION: buf.session,
SCORE: buf.score,
MAGNITUDE: buf.magnitude,
// Добавляем поле TEXT позже, после редактирования
};
//8) Вызываем detectPIIData для редактирования текста и затем вставляем в BigQuery
detectPIIData(buf.text, function(formattedText) { // Передаем текст пользователя и колбэк
bqRow['TEXT'] = formattedText; // Добавляем отредактированный текст
insertInBq(bqRow); // Вставляем строку в BigQuery
});
};Этот фрагмент кода делает следующее:
- Импортирует библиотеки BigQuery и DLP.
- Устанавливает константы для указания набора данных, имени таблицы.
- Метод detectPIIData устанавливает типы информации для поиска, такие как номер паспорта, номера телефонов или имена людей.
- Список типов информации для поиска.
- Фактический запрос DLP dlp.deidentifyContent(request) для начала редактирования.
- Метод insertInBQ() запускает метод BigQuery, table.insert(), который запустит задание в фоновом режиме для вставки строки в хранилище данных.
- exports.subscribe = (data, context) => {} — это метод подписки Pub/Sub, который слушает входящие сообщения. Он извлекает данные из буфера и подготавливает объект, который может быть вставлен в BigQuery.
- Последняя часть вызывает функцию detectPIIData и связывает обратный вызов с методом insertInBQ.
Как мы помним из архитектуры, показанной на Рисунке 13-1, нам понадобится бэкэнд-скрипт, который интегрируется с SDK Dialogflow. В Листинге 13-3 вы увидите полный бэкэнд-скрипт: app.js.
Листинг 13-3. app.js
//1) Подключаем скрипты аналитики и конвертера protobuf
const analytics = require('../back-end/analytics'); // Путь может отличаться
const structJson = require('../back-end/structToJson'); // Путь может отличаться
// Получаем переменные среды
const projectId = process.env.npm_config_PROJECT_ID;
const port = ( process.env.npm_config_PORT || 3000 );
const languageCode = (process.env.npm_config_LANGUAGE || 'en-US');
// Подключаем необходимые библиотеки
const socketIo = require('socket.io');
const http = require('http');
const cors = require('cors');
const express = require('express');
const path = require('path');
const uuid = require('uuid');
const df = require('dialogflow').v2beta1;
//2) Глобальные переменные для Dialogflow сессии
let sessionClient;
let sessionPath;
let requestBase = {}; // Базовый объект запроса
// Настройка Dialogflow сессии
function setupDialogflow(){
const sessionId = uuid.v4();
sessionClient = new df.SessionsClient();
sessionPath = sessionClient.sessionPath(projectId, sessionId);
requestBase = {
session: sessionPath,
queryInput: {}
};
}
// Асинхронные функции для вызова Dialogflow (detectIntent и detectIntentByEventName как в Листинге 11-3)
async function detectIntent(text){
let request = {...requestBase}; // Копируем базовый запрос
request.queryInput.text = { languageCode: languageCode, text: text };
const responses = await sessionClient.detectIntent(request);
return responses;
}
async function detectIntentByEventName(eventName){
let request = {...requestBase}; // Копируем базовый запрос
request.queryInput.event = { languageCode: languageCode, name: eventName };
const responses = await sessionClient.detectIntent(request);
delete request.queryInput.event; // Удаляем событие после использования
return responses;
}
// Настройка Express приложения
const app = express();
app.use(cors());
app.use(express.static(path.join(__dirname, '/../ui/'))); // Статические файлы
app.get('/', function(req, res) { // Корневой маршрут для HTML
res.sendFile(path.join(__dirname, '/../ui/index.html'));
});
// Создание HTTP сервера и Socket.IO
const server = http.createServer(app);
const io = socketIo(server);
// Обработка подключений Socket.IO
io.on('connect', (client) => {
console.log(`Client connected [id=${client.id}]`);
client.emit('server_setup', `Server connected [id=${client.id}]`);
client.on('welcome', async function() {
const welcomeResults = await detectIntentByEventName('WELCOME');
client.emit('returnResults', welcomeResults);
});
//3) Обработка сообщений от клиента
client.on('message', async function(msg) {
const results = await detectIntent(msg); // Получаем результат от Dialogflow
const result = results[0].queryResult; // Извлекаем queryResult
// Готовим данные для аналитики
const timestamp = Date.now(); // Используем Date.now() для временной метки в мс
const platform = "web"; // Пример платформы
const botName = "agent"; // Пример имени бота
// Собираем сообщения ответа
var messages = [];
if(result.fulfillmentMessages && result.fulfillmentMessages.length > 0) {
messages = result.fulfillmentMessages.map(m => {
if (m.payload) {
return structJson.structProtoToJson(m.payload); // Конвертируем payload
} else if (m.text && m.text.text) {
return m.text.text[0]; // Берем первый текстовый ответ
}
return null; // Возвращаем null, если сообщение пустое или не того типа
}).filter(m => m !== null); // Удаляем null элементы
}
// Создаем объект для отправки в аналитику
var obj = {
text: result.queryText,
posted: timestamp,
platform: platform,
botName: botName,
intentResponse: messages, // Отправляем массив сообщений
language: result.languageCode,
intentName: result.intent ? result.intent.displayName : null,
isFallback: result.intent ? result.intent.isFallback : null,
isEndInteraction: result.intent ? result.intent.endInteraction : null,
confidence: result.intentDetectionConfidence,
session: sessionPath, // Отправляем путь сессии
score: result.sentimentAnalysisResult ? result.sentimentAnalysisResult.queryTextSentiment.score : null,
magnitude: result.sentimentAnalysisResult ? result.sentimentAnalysisResult.queryTextSentiment.magnitude : null,
// Добавляем другие необходимые поля, если они есть
};
console.log("Data to Analytics:", obj);
try {
analytics.pushToChannel(obj); // Отправляем данные в Pub/Sub через модуль аналитики
} catch (error) {
console.error("Error pushing to analytics channel:", error);
}
client.emit('returnResults', results); // Отправляем результат Dialogflow обратно клиенту
});
});
// Запускаем настройку Dialogflow и сервер
setupDialogflow();
server.listen(port, () => {
console.log('Running server on port %s', port);
});Позвольте мне объяснить, что делает Листинг 13-3. Во-первых, он включает скрипт аналитики (который мы рассмотрим далее) и скрипт-конвертер для преобразования protobuf в JSON.
//1)
const analytics = require('../back-end/analytics');
const structJson = require('../back-end/structToJson');
sessionId должен быть глобальной константной переменной и получит сгенерированный уникальный идентификатор из пакета npm под названием uuid:
//2)
const sessionId = uuid.v4();
Магия начинается с комментария //3, слушателя client.on('message', async function(msg) { }.
Эта часть будет проходить по всем результатам Dialogflow и добавлять их в новый объект, облегчая облачной функции сбор данных. Затем она вызывает скрипт аналитики, передавая объект:
analytics.pushToChannel(obj);
Скрипт аналитики, который мы использовали, можно найти в Листинге 13-4. Этот скрипт будет записывать объекты в BigQuery.
Листинг 13-4. analytics.js
//1) Подключаем библиотеки BigQuery и PubSub
const { BigQuery } = require('@google-cloud/bigquery');
const { PubSub } = require('@google-cloud/pubsub');
//2) Инстанцируем клиенты PubSub и BigQuery
const projectId = process.env.npm_config_PROJECT_ID || process.env.GCLOUD_PROJECT; // Получаем ID проекта
const pubsub = new PubSub({ projectId });
const bigquery = new BigQuery({ projectId });
//3) Устанавливаем константы для имен набора данных, таблицы и темы
const dataLocation = 'US'; // Пример местоположения данных
const datasetChatMessages = 'chatanalytics';
const tableChatMessages = 'chatmessages';
const topicChatbotMessages = 'chatbotanalytics'; // Имя темы Pub/Sub
//4) Определяем схему таблицы BigQuery
const schemaChatMessages = 'BOT_NAME:STRING,TEXT:STRING,POSTED:TIMESTAMP,SCORE:FLOAT,MAGNITUDE:FLOAT,INTENT_RESPONSE:STRING,INTENT_NAME:STRING,CONFIDENCE:FLOAT,IS_FALLBACK:BOOLEAN,IS_END_INTERACTION:BOOLEAN,PLATFORM:STRING,SESSION:STRING';
//5) Определяем класс Analytics
class Analytics {
//6) Конструктор для настройки BigQuery и PubSub при инициализации
constructor() {
this.setupBigQuery(datasetChatMessages, tableChatMessages, dataLocation, schemaChatMessages);
this.setupPubSub(topicChatbotMessages);
}
//7) Функция для проверки/создания набора данных и таблицы BigQuery
async setupBigQuery(bqDataSetName, bqTableName, bqLocation, schema) {
const dataset = bigquery.dataset(bqDataSetName);
const table = dataset.table(bqTableName);
try {
const [datasetExists] = await dataset.exists();
if (!datasetExists) {
console.log(`Dataset ${bqDataSetName} does not exist. Creating...`);
await dataset.create({ location: bqLocation });
console.log(`Dataset ${bqDataSetName} created.`);
} else {
console.log(`Dataset ${bqDataSetName} already exists.`);
}
const [tableExists] = await table.exists();
if (!tableExists) {
console.log(`Table ${bqTableName} does not exist. Creating...`);
const options = {
schema: schema,
location: bqLocation, // Указываем местоположение и для таблицы
};
await table.create(options);
console.log(`Table ${bqTableName} created.`);
} else {
console.log(`Table ${bqTableName} already exists.`);
}
} catch (err) {
console.error('ERROR setting up BigQuery:', err);
}
}
//8) Функция для проверки/создания темы Pub/Sub
async setupPubSub(topicName) {
const topic = pubsub.topic(`projects/${projectId}/topics/${topicName}`); // Используем projectId
try {
const [exists] = await topic.exists();
if (!exists) {
console.log(`Topic ${topicName} does not exist. Creating...`);
await pubsub.createTopic(topicName);
console.log(`Topic ${topicName} created.`);
} else {
console.log(`Topic ${topicName} already exists.`);
}
} catch (err) {
console.error('ERROR setting up PubSub:', err);
}
}
//9) Функция для выполнения запроса в BigQuery (если потребуется)
async queryBQ(sql) {
if (!sql) {
console.error("ERROR: Missing SQL query");
return Promise.reject("ERROR: Missing SQL query");
}
try {
const options = { query: sql };
const [rows] = await bigquery.query(options);
return rows;
} catch (err) {
console.error('ERROR executing BigQuery query:', err);
return Promise.reject(err);
}
}
//10) Функция для отправки сообщения в канал Pub/Sub
async pushToChannel(json) {
const topic = pubsub.topic(`projects/${projectId}/topics/${topicChatbotMessages}`); // Используем projectId и константу имени темы
const dataBuffer = Buffer.from(JSON.stringify(json)); // Преобразуем JSON в буфер
try {
const messageId = await topic.publishMessage({ data: dataBuffer }); // Используем новый формат publishMessage
console.log(`Message ${messageId} published to topic: ${topicChatbotMessages}`);
return messageId; // Возвращаем ID сообщения для подтверждения
} catch (error) {
console.error(`Received error while publishing: ${error.message}`);
// process.exitCode = 1; // Установка кода выхода при ошибке, если это критично
return null; // Возвращаем null или выбрасываем ошибку
}
}
}
// Экспортируем экземпляр класса Analytics
module.exports = new Analytics();- Во-первых, подключите библиотеки BigQuery и Pub/Sub.
- Создайте экземпляры объектов PubSub и BigQuery.
- Установите константы. Эти имена должны совпадать с теми, что установлены в
cloudfunctions/index.js. - Создайте схему SQL BigQuery для хранения всех данных.
- Здесь начинается пользовательский класс Analytics.
- В конструкторе мы настроим BigQuery и PubSub при первом запуске этого скрипта.
setupBigQueryсоздаст набор данных, если он не существует, и создаст таблицу, если она не существует. Он примет предопределенную схему SQL.setupPubSubсоздаст тему Pub/Sub; облачная функция будет иметь подписку на эту тему. Каждый раз, когда Pub/Sub имеет подписку (входящее сообщение чата в нашем случае), облачная функция будет запускаться.- Метод
queryBQ(SQL)выполнит запрос BigQuery. Вы можете захотеть использовать это, если создаете свои собственные дашборды, показывающие, например, топ-10 самых негативных сообщений чат-бота. Это демо не использует пользовательский дашборд. Оно запускает запросы непосредственно в консоли BigQuery. Такой дашборд можно создать в веб-приложении или использовать Google Data Studio для этого. - Метод
pushToChannel()принимает объект результатов Dialogflow для отправки его в подписку Pub/Sub. Мы вызвали этот метод в файлеapp.js.
Чтобы проверить, правильно ли мы собрали все данные, мы можем проверить это сами в BigQuery, прежде чем создавать дашборд пользовательского интерфейса на нашем веб-сайте.
Перейдите в BigQuery: https://console.cloud.google.com/bigquery.
Щелкните (под ресурсами) проект ➤ chatanalytics ➤ chatmessages.
Щелкните Предварительный просмотр, и из одной из строк предварительного просмотра скопируйте идентификатор сеанса, который вы можете использовать позже в SQL-запросе.
Используйте этот запрос для запроса транскрипта и замените [project_id] вашим идентификатором проекта Google Cloud и [session_id] идентификатором сеанса, который хранится в вашей таблице BigQuery. Обратите внимание на Рисунок 13-6.
SELECT * FROM `[project_id].chatanalytics.chatmessages` WHERE SESSION='[session_id]' ORDER BY POSTED LIMIT 1000
Вы можете запустить примеры в моем репозитории GitHub, чтобы поиграть с этим.
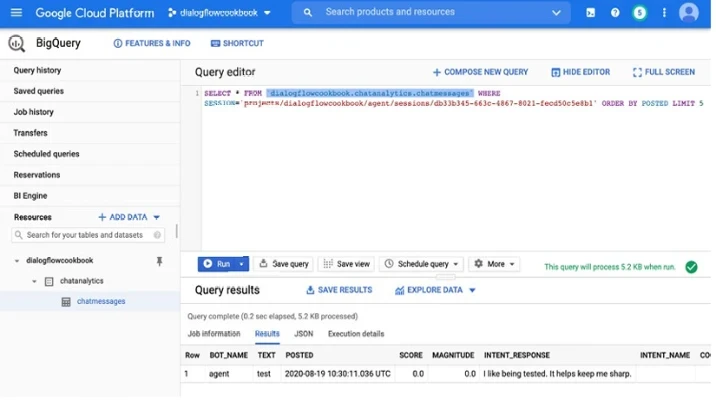
Рисунок 13-6. Сбор данных в BigQuery
Обнаружение настроения пользователя
Вы можете захотеть определить настроение, чтобы выяснить, имеют ли ваши пользователи хороший или плохой опыт работы с вашим агентом.
Для создания решения для определения настроения вам понадобятся следующие сервисы Google Cloud:
- Dialogflow (уровень с оплатой по мере использования)
- (Опционально) Cloud Translation API
- (Опционально) Cloud Natural Language API
Анализ настроения проверяет ввод пользователя и определяет отношение пользователя как положительное, отрицательное или нейтральное. При выполнении запроса на обнаружение намерения вы можете указать, что анализ настроения должен быть выполнен, и ответ будет содержать значения анализа настроения.
Когда возвращается очень негативное настроение, может быть идеей передать неудовлетворенных пользователей живым агентам.
Примечание: Эта функция в настоящее время доступна только пользователям Dialogflow Essentials с оплатой по мере использования.
Анализ настроения поддерживается только для этих языков:
- Китайский (упрощенный и традиционный)
- Английский
- Французский
- Немецкий
- Итальянский
- Японский
- Корейский
- Португальский
- Испанский
Под капотом API Natural Language используется Dialogflow для выполнения этого анализа.
Чтобы включить анализ настроения для всех запросов:
- Нажмите кнопку настроек рядом с именем агента.
- Выберите вкладку Дополнительно (см. Рисунок 13-7).
- Переключите Включить анализ настроения для текущего запроса.
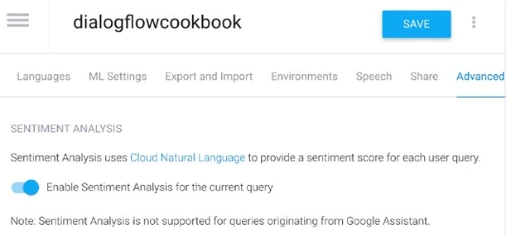
Рисунок 13-7. Включение анализа настроения в Dialogflow
Вы можете взаимодействовать с агентом и получать результаты анализа настроения через симулятор Dialogflow.
Введите «Спасибо за помощь».
См. раздел настроения внизу симулятора. Он должен показать положительную оценку настроения, 0,9, как показано на Рисунке 13-8.
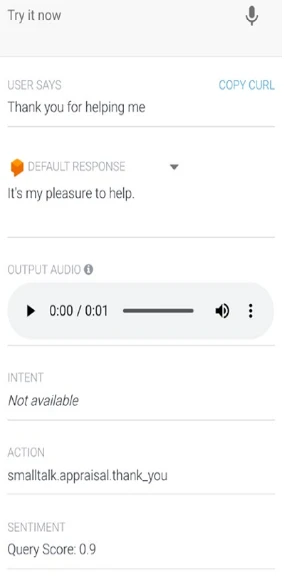
Рисунок 13-8. Положительная оценка настроения в симуляторе
Затем введите «Это совсем не сработало». в симуляторе.
См. раздел настроения внизу симулятора. Он должен показать отрицательную оценку настроения, –0,8, как показано на Рисунке 13-9.
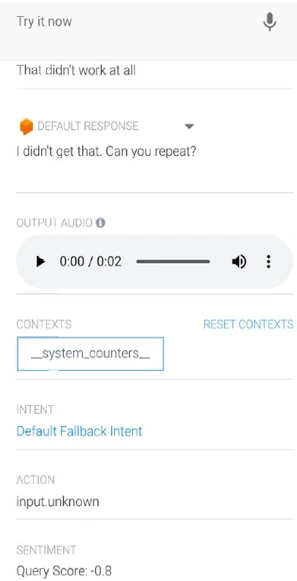
Рисунок 13-9. Отрицательная оценка настроения в симуляторе
Если вы хотите проводить анализ настроения для ваших чат-ботов, но Dialogflow не поддерживает настроение для этого конкретного языка (фактически, этот язык не поддерживается API Google Cloud Natural Language), то вы можете создать пользовательское решение, вызвав API Translate параллельно для обнаружения настроения вручную с помощью API Google Cloud NLP. Этот подход также может быть удобен для случаев использования чат-ботов, которым необходимо поддерживать гораздо больше языков, чем поддерживается в Dialogflow, или для ведения журнала разговоров пользователей на разных языках.
Хотя использование службы перевода, предоставляемой API машинного обучения, может возвращать переводы, которые не на 100% правильно переведены, для анализа настроения этот подход часто работает хорошо. Да, у вас будут некоторые потери при переводе вашего сообщения на другой язык, но часто вы все еще можете выяснить, было ли сообщение положительным или отрицательным. Рисунок 13-10 показывает, как может выглядеть такая архитектура.
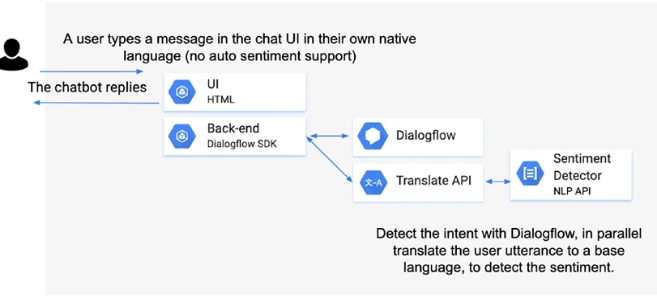
Рисунок 13-10. Архитектура для пользовательского определения настроения
Майнинг тем
Другим популярным решением является майнинг тем. Идея заключается в том, что вы будете собирать из каждого разговора общие ключевые слова/темы. Например, говорит ли пользователь о «покупке видеоигр», «прохождениях» или «данных о релизе»? Как только это будет сохранено в отдельном столбце в BigQuery, вы сможете запросить все последние разговоры с положительным настроением, которые касаются «покупки видеоигр».
Для создания решения для майнинга тем вам понадобятся следующие сервисы Google Cloud:
- BigQuery
- AutoML Natural Language
У Google Cloud есть инструмент, который можно использовать для майнинга тем. Он называется AutoML Natural Language. Способ его работы заключается в обучении вашей собственной пользовательской модели NLP путем загрузки большого количества данных, помеченных (например, «покупка видеоигр», «прохождения», «данные о релизе» или «другое»).
Инструмент обучит себя сам и вернет модель машинного обучения, которую можно вызвать через API. Как только этот API будет готов, вы сможете запрашивать темы и сохранять их вместе с разговором в BigQuery.
Сбор метрик оценки клиентов
Предыдущий раздел мог ответить на все ваши вопросы о том, что сказали ваши клиенты, когда и где. Этот раздел посвящен тому, что думают ваши клиенты, сбору оценок и мнений. Обычно вы спрашиваете своих конечных пользователей об этом в опросе. Вместо того чтобы отправлять электронные письма вашим клиентам после связи с вашим брендом, вы можете задавать эти типы вопросов непосредственно в вашем сеансе чата. Таким образом, вы, скорее всего, получите больше ответов (хотя ответы могут быть более экстремальными).
Внимание: Имейте в виду, что ответы иногда могут быть несколько искаженными. Часто, когда вы собираете отзывы о том, насколько хорошо (виртуальный) агент помог вам, люди также могут быть расстроены решением. Например, когда кто-то взаимодействует с вашей службой поддержки клиентов по поводу скидочной кампании, которая только что закончилась накануне, он может плохо оценить опыт работы с вашим чатом (ботом). Это ничего не говорит о том, насколько хорошо работал чат-бот. Кроме того, люди, которые расстроены, скорее всего, дадут более экстремальную оценку, тогда как люди, которые были довольны обслуживанием, могут даже не ответить на опрос. Вот почему сбор оценок настроения с помощью инструментов машинного обучения может быть более эффективным, чем метрики оценки.
Вот три метрики, которые вы можете включить.
Net Promoter Score (NPS)
Net Promoter Score — это управленческая оценка для расчета лояльности клиентов. Она рассчитывается на основе ответов на один вопрос: Насколько вероятно, что вы порекомендуете нашу компанию/продукт/услугу другу или коллеге? Прежде чем завершить свой поток/сеанс в Dialogflow, вы можете создать этот уточняющий вопрос. Оценка для этого ответа чаще всего основана на шкале от 0 до 10. Вы можете хранить это в BigQuery.
Те, кто отвечает оценкой от 9 до 10, называются Промоутерами и считаются склонными к поведению, создающему ценность, такому как покупка большего количества, дольше оставаясь клиентами и делая больше положительных рекомендаций другим потенциальным клиентам. Те, кто отвечает оценкой от 0 до 6, помечаются как Детракторы, и считается, что они менее склонны к поведению, создающему ценность. Ответы 7 и 8 помечаются как Пассивы, и их поведение находится между Промоутерами и Детракторами. NPS рассчитывается следующим образом:
NPS = % промоутеров – % детракторов
Результат — это не процент, а просто оценка. Например, 10% – 60% = –50 NPS. Зависит от отрасли, чтобы понять, выше или ниже среднего балла.
Внимание: В контакт-центре опрос отправляется после завершения звонка. Опрос включает вопросы об общем опыте клиента. Если NPS повышается после внедрения виртуального агента, все еще очень трудно количественно оценить это, так как это кумулятивный эффект множества инициатив, которые были реализованы в контакт-центре.
Удовлетворенность клиентов (CSAT)
Оценка удовлетворенности клиентов (CSAT) — это базовая мера счастья клиента с продуктом или услугами бренда. Обычно она основана на коротком опросе, который клиенты заполняют, как правило, после завершения разговора или решения проблемы, перед завершением вашего сеанса Dialogflow. Этот опрос может принимать разные формы, но по своей сути просит клиента оценить свой опыт по шкале от хорошего/отличного до плохого.
Например, вы можете спросить: «Как бы вы оценили свой опыт работы с нами?» с последующей шкалой от 1 до 5, где 1 — очень плохо, а 5 — очень хорошо. CSAT рассчитывается следующим образом:
CSAT = количество положительных ответов, проголосовавших 4 или 5 / общее количество ответов × 100%
CSAT отличается от NPS, так как CSAT измеряет удовлетворенность клиентов продуктом или услугой, тогда как NPS измеряет лояльность клиентов к организации.
Оценка усилий клиента (CES)
Оценка усилий клиента (CES) — это метрика обслуживания клиентов, которая измеряет пользовательский опыт с продуктом или услугой. Клиенты оценивают свой опыт по семибалльной шкале от «Очень сложно» до «Очень легко».
Например, прежде чем завершить свой поток/сеанс в Dialogflow, вы можете создать этот уточняющий вопрос: «По шкале 1–7, где 1 — очень сложно, а 7 — очень легко, сколько усилий вам стоило купить эту видеоигру?» Вы можете хранить значение в BigQuery.
CES рассчитывается следующим образом:
CES = общее количество пользователей, проголосовавших: 5, 6 или 7 / общее количество всех пользователей * 100%
Окончательного отраслевого стандарта для оценки усилий клиента не существует. Однако оценка усилий клиента записывается по числовой шкале, поэтому более высокая оценка будет представлять лучший пользовательский опыт. Для стандартной семибалльной шкалы ответы пять или выше будут считаться хорошими оценками.
Мониторинг метрик сеанса чата и воронки с помощью Dialogflow, Chatbase или Actions on Google
Воронка — это набор шагов, которые конечный пользователь должен пройти, прежде чем достичь конверсии. Подумайте о воронке интернет-магазина. Посетителю нужно пройти несколько шагов, прежде чем он сможет приобрести продукт. Ему нужно посетить интернет-магазин, просмотреть все товары, добавить товар в корзину и так далее. Говоря о чат-ботах, воронка чата может быть шагами/сменами реплик перед завершением потока или полного сеанса чата.
Сеансы представляют каждый раз, когда пользователь взаимодействует с вашим агентом. Как полные, так и неполные (когда пользователи просто перестали отвечать) разговоры регистрируются и учитываются в метриках, связанных с сеансами.
Поток сеанса — это визуализация, которая отображает наиболее распространенные пути пользователей через вашего бота.
Метрики для мониторинга
Вот некоторые метрики, специфичные для воронки чата и потока сеанса, которые вы можете захотеть отслеживать.
Общее использование
Сколько людей использовали вашего виртуального агента?
Процент пользователей, которые соответствуют намерению
Представьте, что вы страховая компания, и у вас есть виртуальный помощник для голоса или чат-бот на вашем веб-сайте. Основная функция этого чат-бота — предоставление помощи в заполнении формы декларации. Он также может отвечать на другие общие вопросы о страховой компании.
Вас может заинтересовать, сколько людей взаимодействовало с вашим виртуальным агентом и сколько из них вошли в поток сеанса «декларация» и попали в нужные намерения.
Коэффициент завершения
Рассмотрим предыдущий сценарий использования страхования. Ваши пользователи вошли в поток сеанса «декларация». Вас может заинтересовать, завершили ли они полный поток. Коэффициент завершения — это процент конечных пользователей, завершивших полный поток со всеми его уточняющими вопросами.
Коэффициент отказов/Место отказа
Когда ваши конечные пользователи не завершили поток, вас интересует, где они отказались (место отказа) и процент конечных пользователей, которые отказались (коэффициент отказов). Это может дать вам некоторую информацию о вашем виртуальном агенте. Вы неправильно отвечаете на вопросы, или виртуальный агент неправильно принимает входящие вопросы? Это требует некоторого расследования!
Метрики, специфичные для канала, для мониторинга
Следующие метрики специфичны для каналов, с которыми вы интегрируетесь. Например, когда вы переносите своего чат-бота в Google Assistant, операционная система Google Assistant точно знает, как часто вы открывали действие и что вы делали перед открытием действия. Для веб-сайта этот тип информации можно, например, получить из Google Search Console, когда люди взаимодействуют с вашим чат-ботом после первого поиска вашей страницы в поисковой системе Google.
Удержание пользователей
Удержание — это акт привлечения ваших участников к использованию вашего продукта, чтобы это стало привычным. Вот почему мы называем их пользователями на этом этапе. Если вы их удерживаете, значит, они буквально часто используют ваш продукт.
Информацию об удержании пользователей можно найти в Google Analytics, Google Search Console или консоли Actions on Google.
Примечание: Когда вы хотите экспериментировать с голосом и разрабатывать действие Google Assistant для вашего бренда, подумайте об удержании пользователей. Вы можете представить, что голосовое действие, обрабатывающее страховое требование, не будет использоваться так часто по сравнению с действием Google Assistant для розничного продавца, которое может добавлять продукты в корзину. Вы бы использовали действие продуктового магазина гораздо чаще.
Работоспособность конечной точки
Например, когда вы интегрируетесь с веб-сервисом или базой данных для получения информации, и сервер возвращает ошибку или очень медленно возвращает информацию, это может привести к сбою вашего виртуального агента или, по крайней мере, дать не очень приятный пользовательский опыт.
Информацию о работоспособности конечной точки можно найти в журналах вашего веб-сайта; когда ваш чат-бот развернут в Google Cloud, вы можете найти ее в Cloud Logging (ранее известном как Stackdriver); когда ваш агент работает в Google Assistant, вы можете найти ее в консоли Actions on Google.
Обнаружение
Как ваши пользователи нашли вашего агента и как они туда попали?
Что касается Google Assistant, вас может заинтересовать, как ваши пользователи обнаружили ваше Действие и как они его вызвали. Когда пользователи произносят фразу, связанную с вашим Действием, Google иногда рекомендует пользователю попробовать ваше Действие, даже если пользователь явно не указал имя вызова вашего Действия.
Для чат-ботов на веб-сайтах вас интересует, какие веб-сайты ссылаются на ваш. И какие поисковые запросы использовали ваши пользователи. Эту информацию можно найти в Google Analytics или Google Search Console.
Встроенная аналитика Dialogflow
Dialogflow может предоставить вам метрики из вкладки Аналитика из коробки.
Щелкните Устаревшее ➤ Исследовать.
Эта страница показывает информацию об использовании и данных NLU.
Сеансы (Рисунок 13-11) представляют каждый раз, когда пользователь взаимодействует с вашим агентом. Как полные, так и неполные (когда пользователи просто перестали отвечать) разговоры регистрируются и учитываются в метриках, связанных с сеансами.
Это покажет вам общее количество последних сеансов. Вы можете фильтровать по «вчера», «последние 7 дней» или «последние 30 дней».
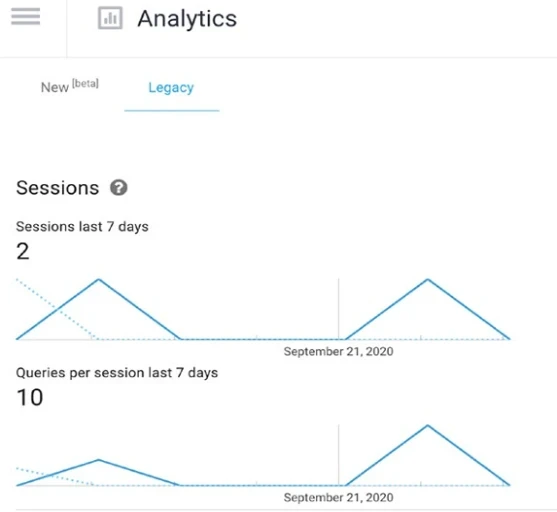
Рисунок 13-11. Встроенная аналитика Dialogflow
Обзор намерений покажет вам обзор наиболее часто используемых намерений. Он отобразит имя намерения, количество сеансов, в которых было сопоставлено намерение, количество раз, когда намерение использовалось во всех сеансах, и процент выхода, который покажет вам процент сеансов, в которых пользователь покинул разговор, находясь в определенном намерении (взято из общего числа сеансов, в которых было сопоставлено то же намерение).
Когда вы прокрутите вниз, вы увидите поток сеанса (Рисунок 13-12). Вы можете щелкнуть каждое намерение, чтобы развернуть намерения, которые следовали бы за ним.
Вы можете навести курсор на имена намерений (синие поля), чтобы увидеть следующую информацию:
- Имя намерения
- Процент всех пользователей, которые сопоставили намерение
- Количество запросов, которым было сопоставлено намерение
- Коэффициент отказов при нахождении в этом намерении
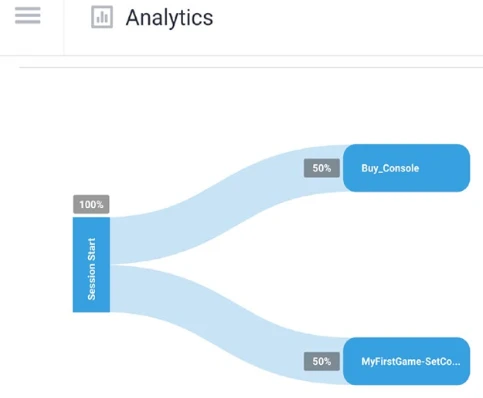
Рисунок 13-12. Встроенная аналитика Dialogflow, поток сеанса
Страница История (Рисунок 13-13) показывает упрощенную версию разговоров, которые вел ваш агент. Вы можете щелкнуть событие или высказывание пользователя, чтобы увидеть хронологический журнал транскрипта.
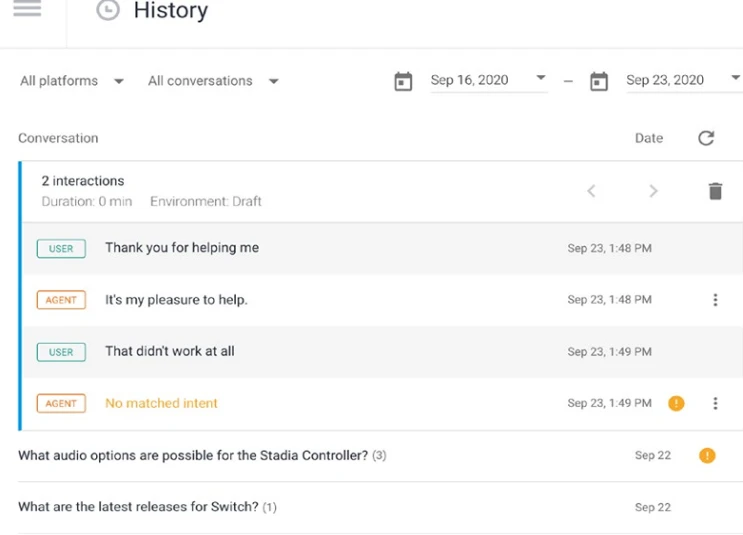
Рисунок 13-13. Транскрипты истории Dialogflow
Вы можете щелкнуть меню опций ответа агента (Рисунок 13-14). Это позволит вам перейти в Cloud Logging для расширенного ведения журнала в консоли Google Cloud или напрямую перейти к намерению (это удобно, когда вам нужно что-то исправить). Или вы можете увидеть необработанный ответ API.
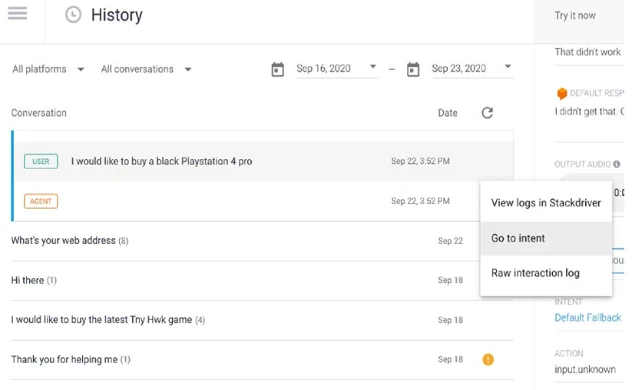
Рисунок 13-14. Транскрипт истории Dialogflow, перейти к намерению
Примечание: На странице История отображаются только ответы по умолчанию. Другие ответы, такие как расширенные сообщения или простые ответы Actions on Google, не видны. Посмотрите на предыдущий скриншот. Ваш URL вызвал пользовательскую полезную нагрузку и поэтому не виден в журнале.
Если вы хотите захватить и эти вещи, вам нужно будет вручную создать решение для ведения журнала, например, с BigQuery.
Мониторинг метрик с помощью Chatbase
В качестве альтернативы вы также можете отслеживать сеанс и воронку из инструмента Google: Chatbase (Рисунок 13-15); он даст вам немного более подробный обзор, и помимо фильтров по «вчера», «последние 7 дней» или «последние 30 дней», он также может фильтровать по «сегодня» или «квартал на дату».
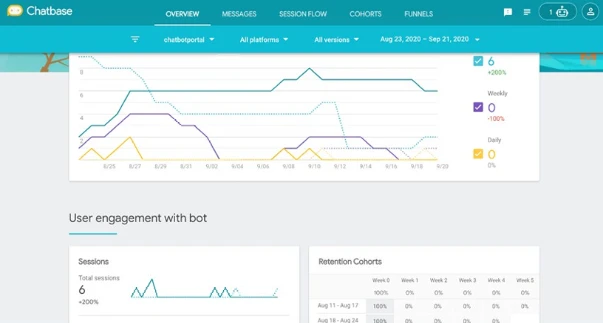
Рисунок 13-15. Аналитика в Chatbase
На самом деле Dialogflow использует Chatbase под капотом.
Блок Когорты удержания покажет вам удержание пользователей с течением времени.
Используйте вкладку Поток сеанса, чтобы увидеть Поток сеанса (Рисунок 13-16); точно так же, как в Dialogflow, вы можете детализировать, чтобы увидеть каждое намерение с:
- Именем намерения
- Процентом всех пользователей, которые сопоставили намерение
- Количеством запросов, которым было сопоставлено намерение
- Коэффициентом отказов при нахождении в этом намерении
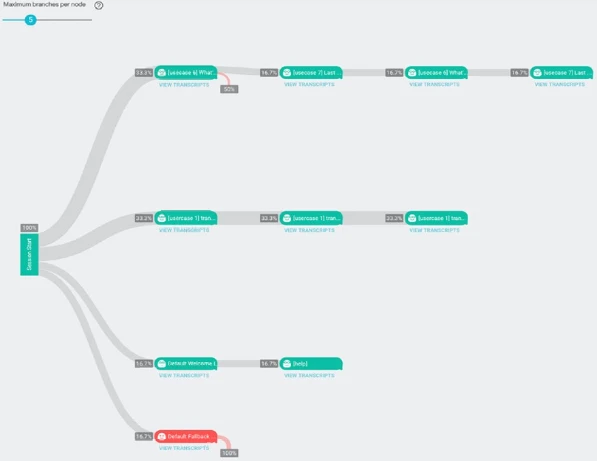
Рисунок 13-16. Поток сеанса в Chatbase
У Chatbase есть инструмент отчетности по воронкам, который предлагает способ отслеживания успеха клиентов путем создания ваших собственных пользовательских рабочих процессов для до шести последующих намерений. Щелкните вкладку Воронки (Рисунок 13-17). Вы можете создать новую воронку для записи и назначения намерений шагам смены реплик. Как только вы создали воронку, вы получите лучшую визуализацию воронки, коэффициента отказов, а также коэффициента завершения.
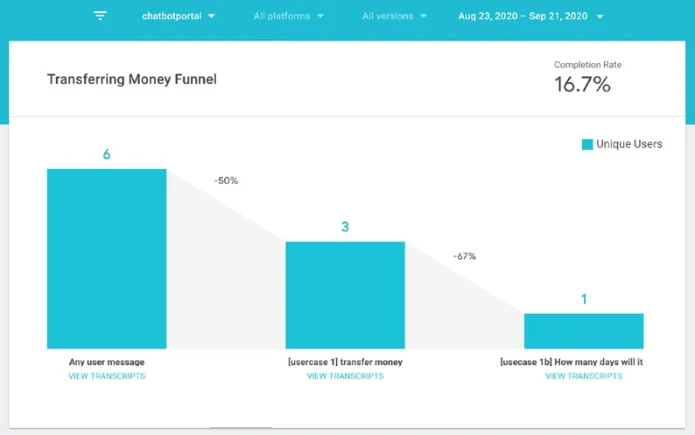
Рисунок 13-17. Воронки Chatbase
Аналитика в Actions on Google
При создании голосового бота, например, для Google Assistant, вы также можете отслеживать некоторые метрики. Войдите в свою консоль Actions on Google.
Приятным дополнением является то, что вы даже можете экспортировать эти метрики в BigQuery, чтобы вы могли захватывать их за более длительный период времени.
Щелкните Аналитика ➤ Использование.
Страница Использование (Рисунок 13-18) отображает три графика, которые относятся к данным использования вашего Действия с течением времени.
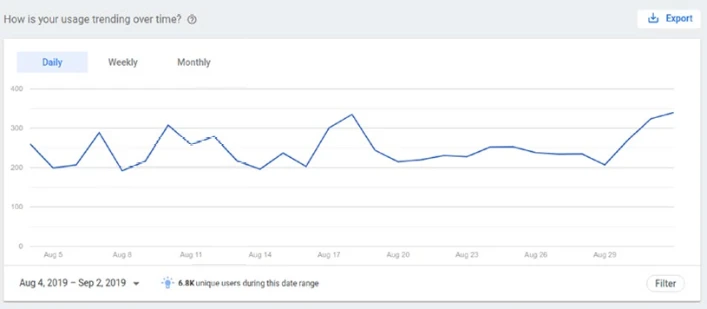
Рисунок 13-18. Использование Actions on Google
И он также может показать вам удержание пользователей (Рисунок 13-19).
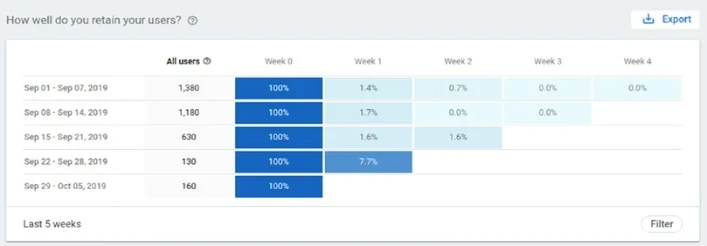
Рисунок 13-19. Удержание пользователей Actions on Google
Приятным дополнением, которое Actions on Google может показать вам (потому что он также знает инсайты вашей интеграции с Google Assistant), является информация о работоспособности (Рисунок 13-20).
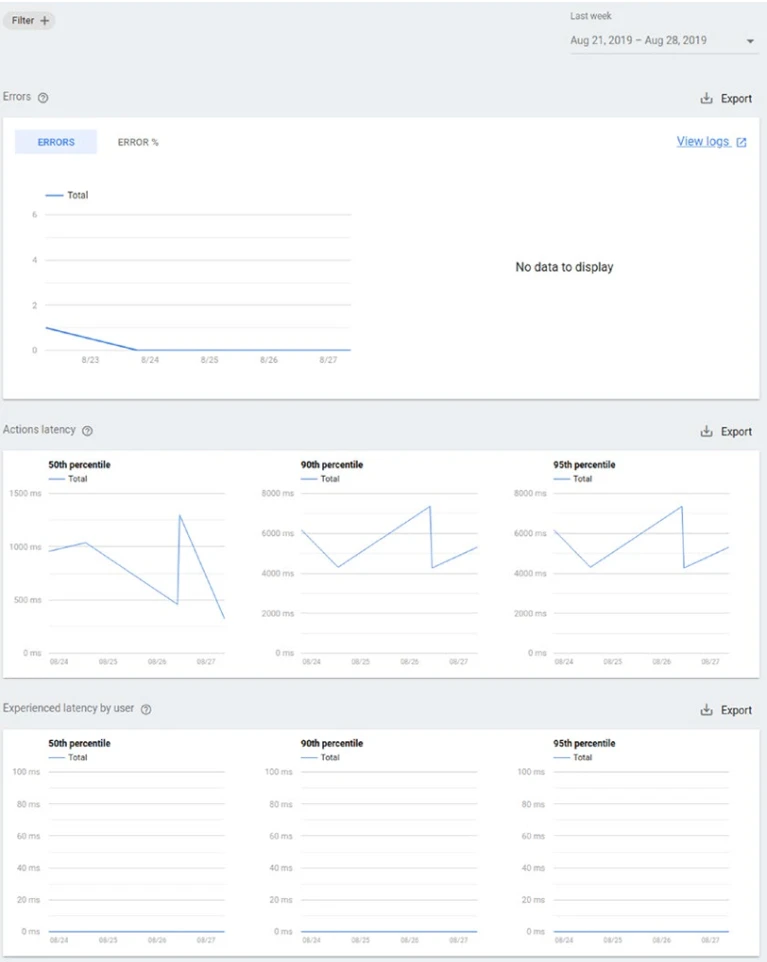
Рисунок 13-20. Информация о работоспособности Actions on Google
- Ошибки: Количество ошибок, возвращенных конечной точкой вашего Действия в облаке за данный день. Если у вас большое количество ошибок, вы можете захотеть посмотреть свои журналы, чтобы определить, что вызывает сбой или неожиданное поведение вашей конечной точки.
- Задержка действий: Задержка конечной точки вашего Действия. Если задержка очень высока или регулярно скачет, ваши пользователи могут испытывать задержки при взаимодействии с вашим Действием.
- Испытанная задержка пользователем: Задержка, ощущаемая пользователем при каждом запросе к вашему Действию. Эта метрика иллюстрирует, что испытывают пользователи при взаимодействии с вашим Действием.
Щелкните Аналитика ➤ Обнаружение.
Страница обнаружения отображает таблицу того, какие фразы привели к тому, что Google порекомендовал ваше Действие (Рисунок 13-21).
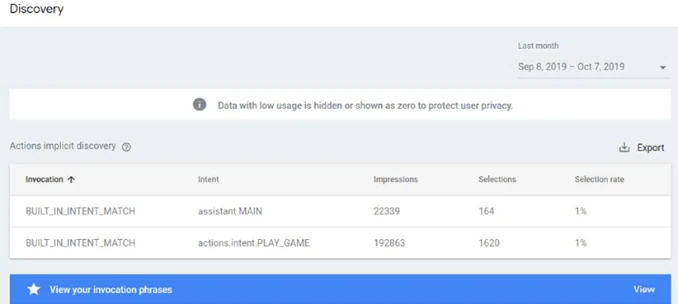
Рисунок 13-21. Обнаружение аналитики Actions on Google
Столбцы в таблице обнаружения следующие:
- Вызов: Запрос пользователя, который привел к тому, что Google порекомендовал ваше Действие. Помимо фактических запросов пользователей, этот список включает следующие значения:
- BUILT_IN_INTENT: Этот список указывает, что ваше Действие было вызвано через встроенное намерение.
- AUTO_MATCHED_BY_GOOGLE: Этот список указывает, когда использовался неявный вызов.
- ACTION_LINK: Этот список указывает, когда ваше Действие было вызвано через ссылку Действия.
- Намерение: Намерение, которому соответствовал запрос пользователя.
- Показ: Количество раз, когда эта фраза привела к тому, что Google порекомендовал ваше Действие.
- Выбор: Количество раз, когда пользователь вызвал ваше Действие после того, как Google его порекомендовал. Это число не может превышать количество показов этой фразы.
- Коэффициент выбора: Процент показов, которые привели к выбору. Низкий процент указывает на то, что многие пользователи предпочитают использовать другие Действия для этого конкретного запроса, тогда как высокий показатель предполагает, что ваше Действие популярно для этого запроса.
Сбор метрик работоспособности модели чат-бота для тестирования качества базовой модели NLU
В то время как метрики разговоров и метрики воронки чата сосредоточены на сборе данных от вашего конечного пользователя для мониторинга и улучшения опыта, метрики модели бота сосредоточены на процессе создания бота и могут использовать тестовые данные проверки (на основе живых данных) для улучшения качества базовой модели NLU.
Современные инструменты для создания чат-ботов/виртуальных помощников, такие как Dialogflow, используют машинное обучение. Для каждого виртуального агента вы, как UX-дизайнер (моделировщик агента) или разработчик, можете определить много намерений. Намерение категоризирует намерение пользователя. Ваши объединенные намерения могут обрабатывать полный разговор. Это обучит базовую модель машинного обучения.
Когда конечный пользователь пишет или говорит что-то в чат-боте или виртуальном помощнике, мы называем это выражением пользователя или высказыванием. Dialogflow сопоставляет выражение с наиболее подходящим намерением в вашем конструкторе ботов на основе встроенного NLU (Понимания естественного языка) и обучающих фраз (примеров), на которых была обучена базовая модель машинного обучения. Сопоставление намерения также известно как классификация намерений или сопоставление намерений.
Как только вы создали своего виртуального агента, возникает самый важный вопрос: насколько хороша ваша модель машинного обучения, которую использует ваш виртуальный агент под капотом?
Существует множество метрик, которые вы можете использовать для проверки качества вашего виртуального агента.
Обычно при работе с тестовыми данными UX-дизайнеры или контент-райтеры создают набор данных для проверки. Они используют это для обучения модели агента Dialogflow, вводя это как пользовательские фразы. Чтобы создать тестовые наборы данных, которые не являются предвзятыми, используйте журналы из чатов/контакт-центров/виртуальных помощников и отделите их от обучающих фраз намерения, используемых для обучения модели. Когда пользовательские данные содержат конфиденциальные данные PII, вы должны анонимизировать или маскировать их.
Как вы видели, это отличные метрики для проверки вашей базовой модели машинного обучения. Как только вы сохраните все эти переменные в хранилище данных, вы сможете легко создавать дашборды для предварительного просмотра этих инсайтов. Разработчики могут создавать модульные тесты, которые передают данные проверки как пользовательские высказывания и тестируют их с помощью API конструктора ботов (в Dialogflow это будет метод detectIntent()). Обнаруженное намерение и оценка уверенности могут быть оценены с вашим набором данных проверки.
Истинно положительный результат — правильно сопоставленное намерение
Истинно положительный результат — это результат, когда чат-бот правильно обнаруживает правильное (положительное) намерение. Например, когда у вашего виртуального агента есть намерение под названием «Намерение зарплаты», и он был обучен на обучающей фразе:
«Моя зарплата пришла?»
А высказывание пользователя:
«Я получил свою зарплату?»
Dialogflow должен обнаружить следующее Намерение: «Намерение зарплаты».
Я мог бы написать модульный тест, подобный тому, как вы бы писали модульные тесты в разработке программного обеспечения. Я мог бы создать тестовые данные по предыдущему сценарию с высказыванием пользователя: «Моя зарплата, когда я ее получу?»
Я ожидаю, что это будет Намерение зарплаты. Вы можете использовать API Dialogflow, и Dialogflow также обнаружит Намерение зарплаты. Так что это истинно положительный результат. Совпадение было правильным.
Вы можете хранить это в BigQuery, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента с помощью API Dialogflow. Поля данных, которые вам нужно будет собрать: «Высказывание пользователя», «Ожидаемое имя намерения», «Обнаруженное имя намерения» и «Результат», который равен TP.
Истинно отрицательный результат — неподдерживаемый запрос
Истинно отрицательный результат — это результат, когда чат-бот правильно сопоставил высказывание пользователя с резервным вариантом. Ошибки неподдерживаемых запросов возникают, когда пользователи задают вопросы, на которые ваш бот не был разработан для ответа. Но вместо того, чтобы возвращать неправильный ответ или системную ошибку, он возвращает дружелюбное резервное сообщение.
Например, когда у вашего виртуального агента есть намерение под названием «Глобальный резервный вариант», которое становится активным каждый раз, когда намерение не может быть сопоставлено.
Я мог бы создать тестовые данные по предыдущему сценарию с высказыванием пользователя: «Могу ли я купить фишки казино?»
Это банковский чат-бот, а не чат-бот казино. Я ожидаю, что это будет намерение «Глобальный резервный вариант», и Dialogflow вернул намерение «Глобальный резервный вариант».
Так что это истинно отрицательный результат. Он ведет себя именно так, как был разработан.
Вы можете хранить тестовый пример, подобный предыдущему, в вашем хранилище данных, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента с помощью API Dialogflow. Поля данных, которые вам нужно будет собрать: «Высказывание пользователя», «Ожидаемое имя намерения», «Обнаруженное имя намерения» и «Результат», который равен TN.
Ложноположительный результат — неправильно понятый запрос
Ложноположительный результат — это результат, когда чат-бот сопоставляет неправильное намерение. Это должно было быть другое намерение или, если его не существовало, резервное намерение, но он неправильно понял высказывание пользователя, поэтому результат неверен. Ошибки неправильно понятых запросов возникают, когда ваш бот не может определить правильное намерение пользователя. Эта ошибка может быть вызвана тем, что ваш бот не учитывает контекст вопроса или отвечает на немного другой вопрос, чем тот, который задается.
Например, когда у вашего виртуального агента есть намерение под названием «Заблокировать кредитную карту», и он был обучен на обучающей фразе:
«Я хочу заблокировать свою кредитную карту».
У вашего виртуального агента есть другое намерение под названием «Продлить кредитную карту», и он был обучен на обучающей фразе:
«Я хочу продлить свою кредитную карту».
Я мог бы создать тестовые данные по предыдущему сценарию с высказыванием пользователя: «Мой счет заблокирован, могу ли я получить новую кредитную карту?»
Я ожидаю, что это будет намерение «Продлить кредитную карту»; однако Dialogflow обнаружил намерение «Заблокировать кредитную карту». Так что это ложноположительный результат. Совпадение было, но оно неверное!
Вы можете хранить тестовый пример, подобный предыдущему, в BigQuery, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента с помощью API Dialogflow. Поля данных, которые вам нужно будет собрать: «Высказывание пользователя», «Ожидаемое имя намерения», «Обнаруженное имя намерения» и «Результат», который равен FP.
Ложноотрицательный результат — пропущенный запрос
Ложноотрицательный результат — это результат, когда намерение существует, но чат-бот его не обнаружил, и поэтому был вызван резервный вариант. Ошибки пропущенных запросов возникают, когда у вашего бота уже есть определенное намерение, но он не может распознать альтернативные формулировки или терминологию.
Например, когда у вашего виртуального агента есть намерение под названием «Заблокировать кредитную карту», и он был обучен на обучающей фразе:
«Я хочу заблокировать свою кредитную карту».
Я мог бы создать тестовые данные по предыдущему сценарию с высказыванием пользователя: «Остановите кредитную карту прямо сейчас».
Я ожидаю, что это будет намерение «Заблокировать кредитную карту»; однако виртуальный агент обнаружил резервное намерение. Так что это ложноотрицательный результат. Намерение есть, но он не смог его сопоставить.
Вы можете хранить тестовый пример, подобный предыдущему, в BigQuery, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента с помощью API Dialogflow. Поля данных, которые вам нужно будет собрать: «Высказывание пользователя», «Ожидаемое имя намерения», «Обнаруженное имя намерения» и «Результат», который равен FN.
Истинно положительный показатель (True Positive Rate)
Истинно положительный показатель (TPR или полнота) — это коэффициент чувствительности для определения того, слишком ли узко определены намерения и пропущены запросы. Когда он выше 0,5, его можно считать хорошим.
TPR = общее количество TP / (общее количество TP + общее количество FN)
Ложноположительный показатель (False Positive Rate)
Ложноположительный показатель (FPS или Fallout) — это коэффициент ложной тревоги. Ложноположительный показатель рассчитывается как отношение между количеством отрицательных событий, когда чат-бот сопоставил неправильное намерение (ложноположительные результаты), и общим количеством фактических отрицательных событий (независимо от классификации).
FPR = общее количество FP / (общее количество FP + общее количество TN)
Вы можете хранить тестовый пример, подобный предыдущему, в BigQuery, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента. Вам нужно будет запросить общее количество TP, FP, FN и TN из вашего хранилища данных. И вы бы сохранили TPR и FPR, чтобы вы могли извлечь их позже в своих отчетах.
Кривая ROC
Кривая ROC (Receiver Operating Characteristic — рабочая характеристика приемника) — это графическое представление, которое показывает нам, насколько хорошо модель различает заданные намерения с точки зрения обнаруженной вероятности. Используя эту информацию, вы можете решить, как вы хотите установить пороги уверенности вашего агента Dialogflow, чтобы определить оценку классификации, необходимую для совпадения намерения.
Вам нужно будет рассчитать истинно положительный показатель и ложноположительный показатель, чтобы построить это на графике. Вы бы сделали это на основе различных порогов настроек ML Dialogflow.
Например, мы установили в Dialogflow порог уверенности 0,80, который сопоставляет высказывания пользователя с двумя вариантами: совпадение или отсутствие совпадения намерения. Мы предполагаем, что любая вероятность больше или равная 0,80 будет совпадением намерения, иначе — резервным вариантом.
Кривая ROC строит два параметра:
- Истинно положительный показатель (коэффициент полноты/чувствительности)
- Ложноположительный показатель (коэффициент выпадения/ложной тревоги)
Синяя диагональная линия на Рисунке 13-22 отражает случайное угадывание с площадью под кривой 0,5. Это означает, что виртуальные агенты правильно определили половину ожидаемых намерений. В целом, цель состоит в том, чтобы максимизировать чувствительность и минимизировать ложную тревогу. Другими словами, чем круче линия ROC (желтая), тем лучше.
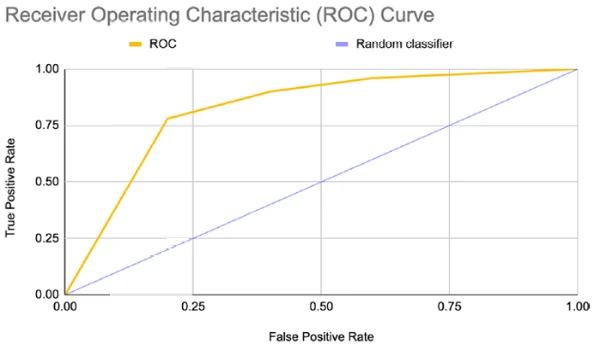
Рисунок 13-22. Кривая ROC
Точность (Accuracy)
Точность — это отношение правильно предсказанных наблюдений к общему количеству наблюдений — отношение всех правильно обработанных намерений. Вы можете рассчитать ее следующим образом:
общее количество правильных = общее количество TP + общее количество TN
общее количество неправильных = общее количество FP + общее количество FN
точность = правильные / (правильные + неправильные)
Вы можете хранить тестовый пример, подобный предыдущему, в вашем хранилище данных, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента. Вам нужно будет запросить общее количество TP, TN, FP и FN из BigQuery. И вы бы сохранили точность, чтобы вы могли извлечь ее позже в своих отчетах.
Точность (Precision)
Точность — это отношение положительных прогнозируемых значений для определения того, есть ли проблемы с ложноположительными/неправильно понятыми запросами. Чем выше точность, тем ниже частота ложноположительных результатов.
точность = общее количество TP / (общее количество TP + общее количество FP)
Вы можете хранить тестовый пример, подобный предыдущему, в BigQuery, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента. Вам нужно будет запросить общее количество TP и FP из вашего хранилища данных. И вы бы сохранили точность, чтобы вы могли извлечь ее позже в своих отчетах.
F1-мера (F1 Score)
F1-мера — это взвешенное среднее значение точности и полноты (TPR).
Поэтому эта оценка учитывает как ложноположительные, так и ложноотрицательные результаты. Интуитивно ее не так легко понять, как точность, но F1 обычно более полезна, чем точность, особенно если у вас несбалансированное распределение классов. Точность лучше всего работает, если стоимость ложноположительных и ложноотрицательных результатов схожа. Если стоимость ложноположительных и ложноотрицательных результатов сильно различается, лучше смотреть на точность и полноту.
F1-мера = 2*(TPR * Точность) / (TPR + Точность)
Вы можете хранить тестовый пример, подобный предыдущему, в BigQuery, чтобы вы могли повторно запускать сценарий каждый раз, когда вносите изменения в своего агента. Вам нужно будет запросить общую полноту и точность из вашего хранилища данных. И вы бы сохранили F1-меру, чтобы вы могли извлечь ее позже в своих отчетах.
Матрица ошибок (Confusion Matrix)
В области машинного обучения матрица ошибок, также известная как матрица ошибок, представляет собой специфическую табличную компоновку, которая позволяет визуализировать производительность алгоритма (в нашем случае, базовой модели машинного обучения для виртуального агента). Каждая строка матрицы представляет ожидаемые намерения, тогда как каждый столбец представляет фактическое сопоставленное намерение API Dialogflow.
Название происходит от того факта, что легко увидеть, путает ли агент два класса (обычно неправильно маркируя один как другой).
Когда у вас много тестовых случаев, вы можете отобразить все оценки в одной большой матрице.
Как вы можете видеть на Рисунке 13-23, каждое намерение содержит сумму всех TP. Это должно дать вам диагональную (оранжевую) линию сверху вниз. Красные квадраты — это сумма всех FP; например, в следующей матрице вы можете видеть, что есть тестовый случай (высказывание пользователя), который должен был быть сопоставлен с намерением get_price, но он был сопоставлен с намерением collect_current_playing_game.
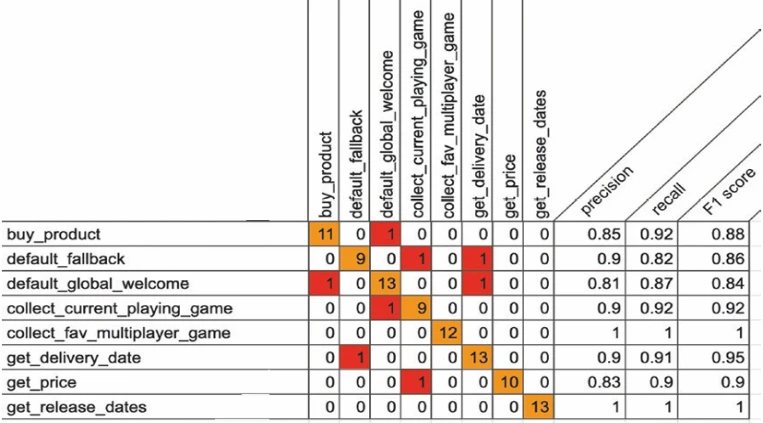
Рисунок 13-23. Матрица ошибок в действии
Резюме
Эта глава содержит информацию о сборе и мониторинге инсайтов и аналитики агента. Она разделена на следующие категории:
- Метрики, связанные с разговором
Что сказали ваши пользователи, когда и где? Вы можете собирать метрики, связанные с разговором, и хранить их в хранилище данных, таком как BigQuery. - Метрики оценки клиентов
Что ваши пользователи думают о вашем бренде? Как вы можете собирать оценки с помощью Dialogflow? - Метрики сеанса чата и воронки
Пути, которые прошли ваши пользователи для взаимодействия с вашим агентом. Как отслеживать сеансы чата и метрики воронки с помощью Dialogflow и Chatbase. - Метрики работоспособности модели бота
Как собирать метрики работоспособности модели чат-бота для тестирования качества базовой модели машинного обучения, чтобы настроить порог машинного обучения Dialogflow.
Если вы хотите создать этот пример, исходный код для этой книги доступен на GitHub через страницу продукта книги, расположенную по адресу www.apress.com/978-1-4842-7013-4. Ищите папку advanced-agent-insights.
Дополнительные материалы
- Документация Dialogflow по истории
https://cloud.google.com/dialogflow/es/docs/history - Документация Dialogflow по аналитике
https://cloud.google.com/dialogflow/es/docs/analytics - Документация Dialogflow по обучению агентов
https://cloud.google.com/dialogflow/es/docs/training - Документация Google Cloud по BigQuery
https://cloud.google.com/bigquery/docs - Документация Google Cloud по Pub/Sub
https://cloud.google.com/pubsub/docs/ - Документация Google Cloud по Cloud Functions
https://cloud.google.com/functions/docs/ - Языки, поддерживающие встроенный анализ настроения
https://cloud.google.com/dialogflow/es/docs/reference/language - Пример реального подхода к чат-боту, интегрированному в веб-сайт
https://github.com/savelee/kube-django-ng - Документация Dialogflow по анализу настроения в Dialogflow
https://cloud.google.com/dialogflow/es/docs/how/sentiment - AutoML Natural Language
https://cloud.google.com/automl?hl=en - Документация Google Cloud по анализу настроения AutoML
https://cloud.google.com/natural-language/automl/docs/features - Пример кода, как построить передачу человеку
https://github.com/dialogflow/agent-human-handoff-nodejs - queryResult.languageCode
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2beta1#google.cloud.dialogflow.v2beta1.QueryResult - queryResult.intent.displayName
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2beta1#google.cloud.dialogflow.v2beta1.Intent - queryResult.intent.isFallback
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2beta1#google.cloud.dialogflow.v2beta1.Intent - queryResult.intent.endInteraction
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2beta1#google.cloud.dialogflow.v2beta1.Intent - queryResult.intentDetectionConfidence
https://cloud.google.com/dialogflow/es/docs/reference/rpc/google.cloud.dialogflow.v2beta1#google.cloud.dialogflow.v2beta1.QueryResult - Google Data Studio для создания интерактивных дашбордов
https://datastudio.google.com/c/u/0/navigation/reporting - Google Analytics
https://analytics.google.com - Google Search Console
https://search.google.com
Другие статьи по этой теме:
- Практическое руководство по созданию агентов ИИ
- Выявление и масштабирование сценариев использования ИИ
- Агенты ИИ