Глава 2. Загрузка данных
2.0 Введение
Первым шагом в любом начинании в области машинного обучения является получение исходных данных в нашу систему. Исходные данные могут быть лог-файлом, файлом данных, базой данных или облачным хранилищем BLOB-объектов, таким как Amazon S3. Более того, часто мы захотим извлекать данные из нескольких источников.
Рецепты в этой главе рассматривают методы загрузки данных из различных источников, включая CSV-файлы и базы данных SQL. Мы также рассматриваем методы генерации смоделированных данных с желаемыми свойствами для экспериментов. Наконец, хотя существует множество способов загрузки данных в экосистеме Python, мы сосредоточимся на использовании обширного набора методов библиотеки pandas для загрузки внешних данных и использовании scikit-learn — библиотеки машинного обучения с открытым исходным кодом на Python — для генерации смоделированных данных.
2.1 Загрузка образца набора данных
Проблема
Вы хотите загрузить уже существующий образец набора данных из библиотеки scikit-learn.
Решение
Scikit-learn поставляется с рядом популярных наборов данных, которые вы можете использовать:
# Load scikit-learn's datasets
from sklearn import datasets
# Load digits dataset
digits = datasets.load_digits()
# Create features matrix
features = digits.data
# Create target vector
target = digits.target
# View first observation
features[0]array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13.,
15., 10., 15., 5., 0., 0., 3., 15., 2., 0., 11.,
8., 0., 0., 4., 12., 0., 0., 8., 8., 0., 0.,
5., 8., 0., 0., 9., 8., 0., 0., 4., 11., 0.,
1., 12., 7., 0., 0., 2., 14., 5., 10., 12., 0.,
0., 0., 0., 6., 13., 10., 0., 0., 0.])Обсуждение
Часто мы не хотим проходить через работу по загрузке, преобразованию и очистке реального набора данных, прежде чем мы сможем изучить какой-либо алгоритм или метод машинного обучения. К счастью, scikit-learn поставляется с некоторыми распространенными наборами данных, которые мы можем быстро загрузить. Эти наборы данных часто называют “игрушечными”, потому что они гораздо меньше и чище, чем наборы данных, которые мы увидели бы в реальном мире. Некоторые популярные образцы наборов данных в scikit-learn:
load_iris
Содержит 150 наблюдений измерений цветов ириса. Это хороший набор данных для изучения алгоритмов классификации.
load_digits
Содержит 1797 наблюдений изображений рукописных цифр. Это хороший набор данных для обучения классификации изображений.
Чтобы увидеть более подробную информацию о любом из вышеперечисленных наборов данных, вы можете вывести атрибут DESCR:
# Load scikit-learn's datasets
from sklearn import datasets
# Load digits dataset
digits = datasets.load_digits()
# Print the attribute
print(digits.DESCR).. _digits_dataset:
Optical recognition of handwritten digits dataset
--------------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 1797
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
...См. также
scikit-learn toy datasets
The Digit Dataset
2.2 Создание смоделированного набора данных
Проблема
Вам нужно сгенерировать набор смоделированных данных.
Решение
Scikit-learn предлагает множество методов для создания смоделированных данных. Из них три метода особенно полезны: make_regression, make_classification и make_blobs.
Когда нам нужен набор данных, предназначенный для использования с линейной регрессией, make_regression — хороший выбор:
# Load library
from sklearn.datasets import make_regression
# Generate features matrix, target vector, and the true coefficients
features, target, coefficients = make_regression(n_samples = 100,
n_features = 3,
n_informative = 3,
n_targets = 1,
noise = 0.0,
coef = True,
random_state = 1)
# View feature matrix and target vector
print('Feature Matrix\n', features[:3])
print('Target Vector\n', target[:3])Feature Matrix
[[ 1.29322588 -0.61736206 -0.11044703]
[-2.793085 0.36633201 1.93752881]
[ 0.80186103 -0.18656977 0.0465673 ]]
Target Vector
[-10.37865986 25.5124503 19.67705609]Если мы заинтересованы в создании смоделированного набора данных для классификации, мы можем использовать make_classification:
# Load library
from sklearn.datasets import make_classification
# Generate features matrix and target vector
features, target = make_classification(n_samples = 100,
n_features = 3,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
weights = [.25, .75],
random_state = 1)
# View feature matrix and target vector
print('Feature Matrix\n', features[:3])
print('Target Vector\n', target[:3])Feature Matrix
[[ 1.06354768 -1.42632219 1.02163151]
[ 0.23156977 1.49535261 0.33251578]
[ 0.15972951 0.83533515 -0.40869554]]
Target Vector
[1 0 0]Наконец, если мы хотим получить набор данных, предназначенный для хорошей работы с методами кластеризации, scikit-learn предлагает make_blobs:
# Load library
from sklearn.datasets import make_blobs
# Generate feature matrix and target vector
features, target = make_blobs(n_samples = 100,
n_features = 2,
centers = 3,
cluster_std = 0.5,
shuffle = True,
random_state = 1)
# View feature matrix and target vector
print('Feature Matrix\n', features[:3])
print('Target Vector\n', target[:3])Feature Matrix
[[ -1.22685609 3.25572052]
[ -9.57463218 -4.38310652]
[-10.71976941 -4.20558148]]
Target Vector
[0 1 1]Обсуждение
Как видно из решений, make_regression возвращает матрицу признаков из значений с плавающей точкой и целевой вектор из значений с плавающей точкой, тогда как make_classification и make_blobs возвращают матрицу признаков из значений с плавающей точкой и целевой вектор из целых чисел, представляющих принадлежность к классу.
Смоделированные наборы данных scikit-learn предлагают широкие возможности для контроля типа генерируемых данных. Документация scikit-learn содержит полное описание всех параметров, но некоторые из них стоит отметить.
В make_regression и make_classification параметр n_informative определяет количество признаков, которые используются для генерации целевого вектора. Если n_informative меньше общего количества признаков (n_features), результирующий набор данных будет иметь избыточные признаки, которые могут быть идентифицированы с помощью методов выбора признаков.
Кроме того, make_classification содержит параметр weights, который позволяет моделировать наборы данных с несбалансированными классами. Например, weights = [.25, .75] вернет набор данных с 25% наблюдений, принадлежащих к одному классу, и 75% наблюдений, принадлежащих ко второму классу.
Для make_blobs параметр centers определяет количество сгенерированных кластеров. Используя библиотеку визуализации matplotlib, мы можем визуализировать кластеры, сгенерированные make_blobs:
# Load library
import matplotlib.pyplot as plt
# View scatterplot
plt.scatter(features[:,0], features[:,1], c=target)
plt.show()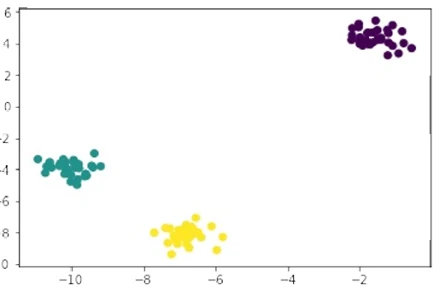
Рисунок 1
См. также
make_regression documentation
make_classification documentation
make_blobs documentation
2.3 Загрузка CSV-файла
Проблема
Вам нужно импортировать файл значений, разделенных запятыми (CSV).
Решение
Используйте read_csv библиотеки pandas для загрузки локального или размещенного CSV-файла в Pandas DataFrame:
# Load library
import pandas as pd
# Create URL
url = 'https://raw.githubusercontent.com/chrisalbon/sim_data/master/data.csv'
# Load dataset
dataframe = pd.read_csv(url)
# View first two rows
dataframe.head(2)| integer | datetime | category | |
|---|---|---|---|
| 0 | 5 | 2015-01-01 00:00:00 | 0 |
| 1 | 5 | 2015-01-01 00:00:01 | 0 |
Обсуждение
При загрузке CSV-файлов следует отметить две вещи. Во-первых, часто полезно быстро просмотреть содержимое файла перед загрузкой. Это может быть очень полезно, чтобы увидеть, как структурирован набор данных, и какие параметры нам нужно установить для загрузки файла. Во-вторых, у read_csv более 30 параметров, и поэтому документация может показаться сложной. К счастью, эти параметры в основном позволяют обрабатывать широкий спектр форматов CSV.
CSV-файлы получили свое название от того, что значения буквально разделены запятыми (например, одна строка может быть 2,"2015-01-01 00:00:00",0
); однако для «CSV»-файлов часто используются другие разделители (называемые «TSVs»). Параметр sep pandas позволяет нам определить разделитель, используемый в файле. Хотя это не всегда так, распространенная проблема форматирования с CSV-файлами заключается в том, что первая строка файла используется для определения заголовков столбцов (например, integer, datetime, category в нашем решении). Параметр header позволяет нам указать, есть ли строка заголовка и где она находится. Если строки заголовка нет, мы устанавливаем
header=None.
Функция read_csv возвращает Pandas DataFrame: распространенный и полезный объект для работы с табличными данными, который мы более подробно рассмотрим в этой книге.
2.4 Загрузка файла Excel
Проблема
Вам нужно импортировать электронную таблицу Excel.
Решение
Используйте read_excel библиотеки pandas для загрузки электронной таблицы Excel:
# Load library
import pandas as pd
# Create URL
url = 'https://raw.githubusercontent.com/chrisalbon/sim_data/master/data.xlsx'
# Load data
dataframe = pd.read_excel(url, sheet_name=0, header=1)
# View the first two rows
dataframe.head(2)| 5 | 2015-01-01 00:00:00 | 0 | |
|---|---|---|---|
| 0 | 5 | 2015-01-01 00:00:01 | 0 |
| 1 | 9 | 2015-01-01 00:00:02 | 0 |
Обсуждение
Это решение аналогично нашему решению для чтения CSV-файлов. Основное отличие — дополнительный параметр sheetname, который указывает, какой лист в файле Excel мы хотим загрузить. sheetname может принимать как строки, содержащие название листа, так и целые числа, указывающие на позиции листов (начиная с нуля). Если нам нужно загрузить несколько листов, включите их в виде списка. Например,
sheetname=[0,1,2, "Monthly Sales"]вернет словарь фреймов данных pandas, содержащий первый, второй и третий листы и лист с названием Monthly Sales.
2.5 Загрузка JSON-файла
Проблема
Вам нужно загрузить JSON-файл для предварительной обработки данных.
Решение
Библиотека pandas предоставляет read_json для преобразования JSON-файла в объект pandas:
# Load library
import pandas as pd
# Create URL
url = 'https://raw.githubusercontent.com/chrisalbon/sim_data/master/data.json'
# Load data
dataframe = pd.read_json(url, orient='columns')
# View the first two rows
dataframe.head(2)| category | datetime | integer | |
|---|---|---|---|
| 0 | 0 | 2015-01-01 00:00:00 | 5 |
| 1 | 0 | 2015-01-01 00:00:01 | 5 |
Обсуждение
Импорт JSON-файлов в pandas аналогичен нескольким предыдущим рецептам, которые мы видели. Ключевое отличие — параметр orient, который указывает pandas, как структурирован JSON-файл. Однако для выяснения того, какой аргумент (split, records, index, columns и values) является правильным, может потребоваться некоторое экспериментирование. Еще один полезный инструмент, предлагаемый pandas, — это json_normalize, который может помочь преобразовать полуструктурированные JSON-данные в pandas DataFrame.
См. также
json_normalize documentation
2.6 Загрузка файла parquet
Проблема
Вам нужно загрузить файл parquet.
Решение
Функция read_parquet pandas позволяет нам читать файлы parquet:
# Load library
import pandas as pd
# Create URL
url = 'https://machine-learning-python-cookbook.s3.amazonaws.com/data.parquet'
# Load data
dataframe = pd.read_parquet(url)
# View the first two rows
dataframe.head(2)| category | datetime | integer | |
|---|---|---|---|
| 0 | 0 | 2015-01-01 00:00:00 | 5 |
| 1 | 0 | 2015-01-01 00:00:01 | 5 |
Обсуждение
Parquet — популярный формат хранения данных в области больших данных. Он часто используется с инструментами для больших данных, такими как hadoop и spark. Хотя Pyspark выходит за рамки этой книги, очень вероятно, что компании, работающие в большом масштабе, будут использовать эффективный формат хранения данных, такой как parquet, и полезно знать, как читать его в DataFrame и манипулировать им.
См. также
Apache Parquet Documentation
2.7 Загрузка файла avro
Проблема
Вам нужно загрузить файл avro в pandas dataframe.
Решение
Используйте метод read_avro библиотеки pandavro:
# Load library
import pandavro as pdx
# Create URL
url = 'https://machine-learning-python-cookbook.s3.amazonaws.com/data.avro'
# Load data
dataframe = pdx.read_avro(url)
# View the first two rows
dataframe.head(2)| category | datetime | integer | |
|---|---|---|---|
| 0 | 0 | 2015-01-01 00:00:00 | 5 |
| 1 | 0 | 2015-01-01 00:00:01 | 5 |
Обсуждение
Apache Avro — это бинарный формат данных с открытым исходным кодом, который основан на схемах для структуры данных. На момент написания он не так распространен, как parquet. Однако большие бинарные форматы данных, такие как avro, thrift и protocol buffers, набирают популярность благодаря эффективной природе этих форматов. Если вы работаете с большими системами данных, вы, вероятно, столкнетесь с одним из этих форматов (например, avro) в ближайшем будущем.
См. также
Apache Avro Docs
2.8 Загрузка файла TFRecord
Проблема
Вам нужно загрузить файл TFRecord в pandas dataframe.
Решение
| category | datetime | integer | |
|---|---|---|---|
| 0 | 0 | 2015-01-01 00:00:00 | 5 |
| 1 | 0 | 2015-01-01 00:00:01 | 5 |
Обсуждение
Подобно avro, TFRecord — это бинарный формат данных (в данном случае основанный на protocol buffers) - однако он специфичен для TensorFlow.
См. также
TFRecord Docs
2.9 Запрос к базе данных SQLite
Проблема
Вам нужно загрузить данные из базы данных, используя язык структурированных запросов (SQL).
Решение
read_sql_query pandas позволяет нам сделать SQL-запрос к базе данных и загрузить его:
# Load libraries
import pandas as pd
from sqlalchemy import create_engine
# Create a connection to the database
database_connection = create_engine('sqlite:///sample.db')
# Load data
dataframe = pd.read_sql_query('SELECT * FROM data', database_connection)
# View first two rows
dataframe.head(2)| first_name | last_name | age | preTestScore | postTestScore | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | 4 | 25 |
| 1 | Molly | Jacobson | 52 | 24 | 94 |
Обсуждение
SQL — это lingua franca для извлечения данных из баз данных. В этом рецепте мы сначала используем create_engine для определения соединения с механизмом базы данных SQL под названием SQLite. Затем мы используем read_sql_query pandas для запроса к этой базе данных с использованием SQL и помещения результатов в DataFrame.
SQL — это самостоятельный язык, и, хотя он выходит за рамки этой книги, его, безусловно, стоит знать любому, кто хочет изучать машинное обучение. Наш SQL-запрос,
SELECT * FROM data, просит базу данных предоставить нам все столбцы (*) из таблицы с названием data.
Обратите внимание, что это один из немногих рецептов в этой книге, который не будет работать без дополнительного кода. В частности,
create_engine('sqlite:///sample.db') предполагает, что база данных SQLite уже существует.
См. также
SQLite
W3Schools SQL Tutorial
2.10 Запрос к удаленной базе данных SQL
Проблема
Вам нужно подключиться к удаленной базе данных SQL и прочитать из нее.
Решение
Создайте соединение с pymysql и прочитайте его в DataFrame с помощью pandas:
# Import libraries
import pymysql
import pandas as pd
# Create a DB connection
# Use the example below to start a DB instance
# https://github.com/kylegallatin/mysql-db-example
conn = pymysql.connect(
host='localhost',
user='root',
password = "",
db='db',
)
# Read the SQL query into a dataframe
dataframe = pd.read_sql("select * from data", conn)
# View the first 2 rows
dataframe.head(2)| integer | datetime | category | |
|---|---|---|---|
| 0 | 5 | 2015-01-01 00:00:00 | 0 |
| 1 | 5 | 2015-01-01 00:00:01 | 0 |
Обсуждение
Из всех рецептов, представленных в этой главе, этот, вероятно, будет наиболее часто использоваться в реальном мире. Хотя подключение и чтение из примера базы данных sqlite полезно, оно, скорее всего, не отражает таблицы, к которым вам потребуется подключиться в корпоративной среде. Большинство экземпляров SQL, к которым вы будете подключаться, потребуют подключения к хосту и порту удаленной машины, указания имени пользователя и пароля для аутентификации. В этом примере требуется запустить работающий экземпляр SQL локально, который имитирует удаленный сервер (хост 127.0.0.1 на самом деле является вашим localhost), чтобы вы могли получить представление о рабочем процессе.
См. также
Pymysql Documentation
Pandas Read SQL
2.11 Загрузка данных из Google Sheet
Проблема
Вам нужно прочитать данные напрямую из Google Sheet.
Решение
Используйте read_csv Pandas и URL, который экспортирует Google Sheet как CSV:
# Import libraries
import pandas as pd
# Google Sheet URL that downloads the sheet as a CSV
url = "https://docs.google.com/spreadsheets/d/1ehC-9otcAuitqnmWksqt1mOrTRCL38dv0K9UjhwzTOA/export?
format=csv"
# Read the CSV into a dataframe
dataframe = pd.read_csv(url)
# View the first 2 rows
dataframe.head(2)| integer | datetime | category | |
|---|---|---|---|
| 0 | 5 | 2015-01-01 00:00:00 | 0 |
| 1 | 5 | 2015-01-01 00:00:01 | 0 |
Обсуждение
Хотя Google Sheets также можно легко загрузить, иногда полезно иметь возможность читать их непосредственно в Python без каких-либо промежуточных шагов. Параметр запроса
/export?format=csvв конце URL выше создает конечную точку, из которой мы можем либо скачать файл, либо прочитать его напрямую в pandas.
См. также
Google Sheets API
2.12 Загрузка данных из S3 Bucket
Проблема
Вам нужно прочитать CSV-файл из S3-корзины, к которой у вас есть доступ.
Решение
Добавьте опции хранения в pandas, предоставив ему доступ к объекту S3:
# Import libraries
import pandas as pd
# S3 path to csv
s3_uri = "s3://machine-learning-python-cookbook.s3.amazonaws.com/data.csv"
# Set AWS credentails (replace with your own)
ACCESS_KEY_ID = "xxxxxxxxxxxxx"
SECRET_ACCESS_KEY = "xxxxxxxxxxxxxxxx"
# Read the csv into a dataframe
dataframe = pd.read_csv(s3_uri,storage_options={
"key": ACCESS_KEY_ID,
"secret": SECRET_ACCESS_KEY,
}
)
# View first two rows
dataframe.head(2)| integer | datetime | category | |
|---|---|---|---|
| 0 | 5 | 2015-01-01 00:00:00 | 0 |
| 1 | 5 | 2015-01-01 00:00:01 | 0 |
Обсуждение
В современную эпоху многие предприятия хранят данные в облачных хранилищах BLOB-объектов, таких как Amazon S3 или Google Cloud Storage (GCS). Специалистам по машинному обучению часто приходится подключаться к этим источникам для получения данных. Хотя URI S3 выше (
s3://machine-learning-python-cookbook/data.csv) является публичным, он все равно требует от вас предоставления ваших собственных учетных данных AWS для доступа к нему. Стоит отметить, что публичные объекты также имеют http-адреса, с которых можно скачивать файлы, например, этот для приведенного выше CSV-файла.
См. также
Amazon S3
Setting up AWS access credentials
2.13 Загрузка неструктурированных данных
Проблема
Вам нужно загрузить неструктурированные данные, такие как текст или изображения.
Решение
Используйте базовую функцию Python open для загрузки информации:
# import libraries
import requests
# URL to download the txt file from
txt_url = "https://machine-learning-python-cookbook.s3.amazonaws.com/text.txt"
# Get the txt file
r = requests.get(txt_url)
# Write it to text.txt locally
with open('text.txt', 'wb') as f:
f.write(r.content)
# Read in the file
with open('text.txt', 'r') as f:
text = f.read()
# Print the content
print(text)Hello there!Обсуждение
В то время как структурированные данные легко читаются из CSV, JSON или различных баз данных, неструктурированные данные могут быть более сложными и могут потребовать специальной обработки в дальнейшем. Иногда полезно открывать и читать файлы, используя базовую функцию Python open. Это позволяет нам открывать файлы, а затем читать содержимое этого файла.
См. также
Python’s open function
Context managers in Python
Другие статьи по этой теме:
- Маленькая книга о глубоком обучении
- 100 Страниц о машинном обучении
- Математика для нейронного обучения