Глава 8. Обработка изображений
8.0 Введение
Классификация изображений — одна из самых захватывающих областей машинного обучения. Способность компьютеров распознавать закономерности и объекты на изображениях является невероятно мощным инструментом в нашем инструментарии. Однако, прежде чем мы сможем применить машинное обучение к изображениям, нам часто сначала нужно преобразовать необработанные изображения в признаки, пригодные для использования нашими алгоритмами обучения. Как и в случае с текстовыми данными, существует также множество предварительно обученных классификаторов для изображений, которые мы можем использовать для извлечения признаков или объектов интереса для использования в качестве входных данных для наших собственных моделей.
Для работы с изображениями мы будем использовать в основном библиотеку Open Source Computer Vision Library (OpenCV). Хотя существует ряд хороших библиотек, OpenCV является наиболее популярной и документированной библиотекой для обработки изображений. Ее установка иногда может быть сложной, но если у вас возникнут проблемы, в Интернете есть множество руководств.
На протяжении этой главы мы будем использовать набор изображений в качестве примеров, которые доступны для скачивания на GitHub.
8.1 Загрузка изображений
Проблема
Вы хотите загрузить изображение для предварительной обработки.
Решение
Используйте imread OpenCV:
# Load library
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)Если мы хотим просмотреть изображение, мы можем использовать библиотеку Python для построения графиков Matplotlib:
# Show image
plt.imshow(image, cmap="gray"), plt.axis("off")
plt.show()
Обсуждение
Фундаментально, изображения — это данные, и когда мы используем imread, мы преобразуем эти данные в тип данных, с которым мы очень хорошо знакомы — массив NumPy:
# Show data type
type(image)numpy.ndarrayМы преобразовали изображение в матрицу, элементы которой соответствуют отдельным пикселям. Мы можем даже взглянуть на фактические значения матрицы:
# Show image data
imagearray([[140, 136, 146, ..., 132, 139, 134],
[144, 136, 149, ..., 142, 124, 126],
[152, 139, 144, ..., 121, 127, 134],
...,
[156, 146, 144, ..., 157, 154, 151],
[146, 150, 147, ..., 156, 158, 157],
[143, 138, 147, ..., 156, 157, 157]], dtype=uint8)Разрешение нашего изображения было 3600 × 2270, точные размеры нашей матрицы:
# Show dimensions
image.shape(2270, 3600)Что на самом деле представляет каждый элемент в матрице? В изображениях в оттенках серого значение отдельного элемента — это интенсивность пикселя. Значения интенсивности варьируются от черного (0) до белого (255). Например, интенсивность самого верхнего правого пикселя в нашем изображении имеет значение 140:
# Show first pixel
image[0,0]140В цветной матрице каждый элемент содержит три значения, соответствующие значениям синего, зеленого, красного (BGR):
# Load image in color
image_bgr = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR)
# Show pixel
image_bgr[0,0]array([195, 144, 111], dtype=uint8)Одно небольшое замечание: по умолчанию OpenCV использует BGR, но многие приложения для изображений — включая Matplotlib — используют красный, зеленый, синий (RGB), что означает, что значения красного и синего поменяны местами. Чтобы правильно отображать цветные изображения OpenCV в Matplotlib, нам нужно сначала преобразовать цвет в RGB (приносим извинения читателям печатной версии):
# Convert to RGB
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
# Show image
plt.imshow(image_rgb), plt.axis("off")
plt.show()
Рисунок 2
См. также
Difference between RGB and BGR
RGB color model
8.2 Сохранение изображений
Проблема
Вы хотите сохранить изображение для предварительной обработки.
Решение
Используйте imwrite OpenCV:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# Save image
cv2.imwrite("images/plane_new.jpg", image)TrueОбсуждение
imwrite OpenCV сохраняет изображения по указанному пути к файлу. Формат изображения определяется расширением имени файла (.jpg, .png и т. д.). Следует быть осторожным: imwrite перезапишет существующие файлы без выдачи ошибки или запроса подтверждения.
8.3 Изменение размера изображений
Проблема
Вы хотите изменить размер изображения для дальнейшей предварительной обработки.
Решение
Используйте resize для изменения размера изображения:
# Load image
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
# Resize image to 50 pixels by 50 pixels
image_50x50 = cv2.resize(image, (50, 50))
# View image
plt.imshow(image_50x50, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 3
Обсуждение
Изменение размера изображений — распространенная задача при предварительной обработке изображений по двум причинам. Во-первых, изображения бывают всех форм и размеров, и чтобы их можно было использовать в качестве признаков, изображения должны иметь одинаковые размеры. Эта стандартизация размера изображения имеет свои издержки; изображения представляют собой матрицы информации, и когда мы уменьшаем размер изображения, мы уменьшаем размер этой матрицы и информацию, которую она содержит. Во-вторых, машинное обучение может потребовать тысячи или сотни тысяч изображений. Когда эти изображения очень большие, они могут занимать много памяти, и, изменив их размер, мы можем значительно уменьшить использование памяти. Некоторые распространенные размеры изображений для машинного обучения: 32 × 32, 64 × 64, 96 × 96 и 256 × 256. По сути, метод, который мы выбираем для изменения размера изображения, часто будет компромиссом между статистической производительностью нашей модели и вычислительными затратами на ее обучение. Библиотека Pillow предлагает множество различных опций для изменения размера изображений по этой причине.
8.4 Обрезка изображений
Проблема
Вы хотите удалить внешнюю часть изображения, чтобы изменить его размеры.
Решение
Изображение закодировано как двумерный массив NumPy, поэтому мы можем легко обрезать изображение, нарезая массив:
# Load image
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image in grayscale
image = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
# Select first half of the columns and all rows
image_cropped = image[:,:128]
# Show image
plt.imshow(image_cropped, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 4
Обсуждение
Поскольку OpenCV представляет изображения как матрицу элементов, выбирая строки и столбцы, которые мы хотим сохранить, мы можем легко обрезать изображение. Обрезка может быть особенно полезной, если мы знаем, что хотим сохранить только определенную часть каждого изображения. Например, если наши изображения получены со стационарной камеры видеонаблюдения, мы можем обрезать все изображения так, чтобы они содержали только интересующую область.
См. также
Slicing NumPy Arrays
8.5 Размытие изображений
Проблема
Вы хотите сгладить изображение.
Решение
Для размытия изображения каждый пиксель преобразуется в среднее значение его соседей. Этот сосед и выполняемая операция математически представлены как ядро (не беспокойтесь, если вы не знаете, что такое ядро). Размер этого ядра определяет степень размытия, причем более крупные ядра создают более гладкие изображения. Здесь мы размываем изображение, усредняя значения ядра размером 5 × 5 вокруг каждого пикселя:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
# Blur image
image_blurry = cv2.blur(image, (5,5))
# Show image
plt.imshow(image_blurry, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 5
Чтобы подчеркнуть эффект размера ядра, вот то же размытие с ядром 100 × 100:
# Blur image
image_very_blurry = cv2.blur(image, (100,100))
Show image
plt.imshow(image_very_blurry, cmap="gray"), plt.xticks([]), plt.yticks([])
plt.show()
Рисунок 6
Обсуждение
Ядра широко используются в обработке изображений для всего, от повышения резкости до обнаружения краев, и будут неоднократно встречаться в этой главе. Ядро размытия, которое мы использовали, выглядело так:
# Create kernel
kernel = np.ones((5,5)) / 25.0
Show kernel
kernelarray([[0.04, 0.04, 0.04, 0.04, 0.04],
[0.04, 0.04, 0.04, 0.04, 0.04],
[0.04, 0.04, 0.04, 0.04, 0.04],
[0.04, 0.04, 0.04, 0.04, 0.04],
[0.04, 0.04, 0.04, 0.04, 0.04]])Центральный элемент в ядре — это исследуемый пиксель, а остальные элементы — его соседи. Поскольку все элементы имеют одинаковое значение (нормированное так, чтобы в сумме давать 1), каждый имеет равный вклад в результирующее значение интересующего пикселя. Мы можем вручную применить ядро к изображению с помощью filter2D для получения аналогичного эффекта размытия:
# Apply kernel
image_kernel = cv2.filter2D(image, -1, kernel)
Show image
plt.imshow(image_kernel, cmap="gray"), plt.xticks([]), plt.yticks([])
plt.show()
Рисунок 7
См. также
Image Kernels Explained Visually
Common Image Kernels
8.6 Повышение резкости изображений
Проблема
Вы хотите повысить резкость изображения.
Решение
Создайте ядро, которое выделяет целевой пиксель. Затем примените его к изображению с помощью filter2D:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image as grayscale
image = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
Create kernel
kernel = np.array([[0, -1, 0],
[-1, 5,-1],
[0, -1, 0]])
Sharpen image
image_sharp = cv2.filter2D(image, -1, kernel)
Show image
plt.imshow(image_sharp, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 8
Обсуждение
Повышение резкости работает аналогично размытию, за исключением того, что вместо использования ядра для усреднения соседних значений мы построили ядро, которое выделяет сам пиксель. Результирующий эффект делает контрасты на краях более заметными на изображении.
8.7 Увеличение контрастности
Проблема
Мы хотим увеличить контраст между пикселями на изображении.
Решение
Выравнивание гистограммы — инструмент для обработки изображений, который позволяет выделять объекты и формы. Когда у нас есть изображение в оттенках серого, мы можем применить equalizeHist OpenCV непосредственно к изображению:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image
image = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
Enhance image
image_enhanced = cv2.equalizeHist(image)
Show image
plt.imshow(image_enhanced, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 9
Однако, когда у нас есть цветное изображение, нам сначала нужно преобразовать его в формат YUV. Y — это яркость (luma), а U и V обозначают цвет. После преобразования мы можем применить equalizeHist к изображению, а затем преобразовать его обратно в BGR или RGB:
# Load image
image_bgr = cv2.imread("images/plane.jpg")
Convert to YUV
image_yuv = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2YUV)
Apply histogram equalization
image_yuv[:, :, 0] = cv2.equalizeHist(image_yuv[:, :, 0])
Convert to RGB
image_rgb = cv2.cvtColor(image_yuv, cv2.COLOR_YUV2RGB)
Show image
plt.imshow(image_rgb), plt.axis("off")
plt.show()
Рисунок 10
Обсуждение
Хотя подробное объяснение принципов работы выравнивания гистограммы выходит за рамки этой книги, краткое объяснение заключается в том, что оно преобразует гистограмму так, чтобы она использовала более широкий диапазон интенсивностей пикселей.
Хотя результирующее изображение часто не выглядит «реалистичным», мы должны помнить, что изображение — это просто визуальное представление основных данных. Если выравнивание гистограммы способно сделать интересующие объекты более отличимыми от других объектов или фонов (что не всегда так), то это может стать ценным дополнением к нашему конвейеру предварительной обработки изображений.
8.8 Изоляция цветов
Проблема
Вы хотите выделить цвет на изображении.
Решение
Определите диапазон цветов, а затем примените маску к изображению:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image
image_bgr = cv2.imread('images/plane_256x256.jpg')
Convert BGR to HSV
image_hsv = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2HSV)
Define range of blue values in HSV
lower_blue = np.array([50,100,50])
upper_blue = np.array([130,255,255])
Create mask
mask = cv2.inRange(image_hsv, lower_blue, upper_blue)
Mask image
image_bgr_masked = cv2.bitwise_and(image_bgr, image_bgr, mask=mask)
Convert BGR to RGB
image_rgb = cv2.cvtColor(image_bgr_masked, cv2.COLOR_BGR2RGB)
Show image
plt.imshow(image_rgb), plt.axis("off")
plt.show()
Рисунок 11
Обсуждение
Изоляция цветов в OpenCV проста. Сначала мы преобразуем изображение в HSV (оттенок, насыщенность и значение). Во-вторых, мы определяем диапазон значений, которые мы хотим выделить, что, вероятно, является самой сложной и трудоемкой частью. В-третьих, мы создаем маску для изображения (мы будем сохранять только белые области):
# Show mask
plt.imshow(mask, cmap='gray'), plt.axis("off")
plt.show()
Рисунок 12
Наконец, мы применяем маску к изображению с помощью bitwise_and и преобразуем в желаемый выходной формат.
8.9 Бинаризация изображений
Проблема
Имея изображение, вы хотите получить упрощенную версию.
Решение
Пороговая обработка (Thresholding) — это процесс установки пикселей с интенсивностью больше некоторого значения в белый цвет, а с интенсивностью меньше этого значения — в черный. Более продвинутая техника — адаптивная пороговая обработка, при которой пороговое значение для пикселя определяется интенсивностью его соседей. Это может быть полезно, когда условия освещения меняются в разных областях изображения:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image as grayscale
image_grey = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
Apply adaptive thresholding
max_output_value = 255
neighborhood_size = 99
subtract_from_mean = 10
image_binarized = cv2.adaptiveThreshold(image_grey,
max_output_value,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,
neighborhood_size,
subtract_from_mean)
Show image
plt.imshow(image_binarized, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 13
Обсуждение
Наше решение имеет четыре важных аргумента в adaptiveThreshold. max_output_value просто определяет максимальную интенсивность выходных пикселей. cv2.ADAPTIVE_THRESH_GAUSSIAN_C устанавливает порог пикселя как взвешенную сумму интенсивностей соседних пикселей. Веса определяются гауссовым окном. Альтернативно, мы могли бы установить порог равным просто среднему значению соседних пикселей с cv2.ADAPTIVE_THRESH_MEAN_C:
# Apply cv2.ADAPTIVE_THRESH_MEAN_C
image_mean_threshold = cv2.adaptiveThreshold(image_grey,
max_output_value,
cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY,
neighborhood_size,
subtract_from_mean)
Show image
plt.imshow(image_mean_threshold, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 14
Последние два параметра — это размер блока (размер окрестности, используемой для определения порога пикселя) и константа, вычитаемая из вычисленного порога (используется для ручной тонкой настройки порога).
Основное преимущество пороговой обработки — это удаление шума с изображения — сохранение только наиболее важных элементов. Например, пороговая обработка часто применяется к фотографиям печатного текста для выделения букв со страницы.
8.10 Удаление фонов
Проблема
Вы хотите выделить передний план изображения.
Решение
Отметьте прямоугольник вокруг желаемого переднего плана, затем запустите алгоритм GrabCut:
# Load library
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image and convert to RGB
image_bgr = cv2.imread('images/plane_256x256.jpg')
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
Rectangle values: start x, start y, width, height
rectangle = (0, 56, 256, 150)
Create initial mask
mask = np.zeros(image_rgb.shape[:2], np.uint8)
Create temporary arrays used by grabCut
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
Run grabCut
cv2.grabCut(image_rgb, # Our image
mask, # The Mask
rectangle, # Our rectangle
bgdModel, # Temporary array for background
fgdModel, # Temporary array for background
5, # Number of iterations
cv2.GC_INIT_WITH_RECT) # Initiative using our rectangle
Create mask where sure and likely backgrounds set to 0, otherwise 1
mask_2 = np.where((mask==2) | (mask==0), 0, 1).astype('uint8')
Multiply image with new mask to subtract background
image_rgb_nobg = image_rgb * mask_2[:, :, np.newaxis]
Show image
plt.imshow(image_rgb_nobg), plt.axis("off")
plt.show()
Рисунок 15
Обсуждение
Первое, что мы замечаем, это то, что, хотя GrabCut справился довольно хорошо, на изображении все еще остались области фона. Мы могли бы вернуться и вручную пометить эти области как фон, но в реальном мире у нас тысячи изображений, и ручное исправление каждого из них нецелесообразно. Поэтому лучше просто принять, что данные изображения все равно будут содержать некоторый фоновый шум.
В нашем решении мы начинаем с отметки прямоугольника вокруг области, содержащей передний план. GrabCut предполагает, что все за пределами этого прямоугольника является фоном, и использует эту информацию для выяснения того, что, вероятно, является фоном внутри квадрата (чтобы узнать, как работает алгоритм, проверьте внешние ресурсы, такие как
http://bit.ly/2wgbPIS). Затем создается маска, которая обозначает различные области определенно/вероятно фона/переднего плана:
# Show mask
plt.imshow(mask, cmap='gray'), plt.axis("off")
plt.show()
Рисунок 16
Черная область — это область за пределами нашего прямоугольника, которая считается определенно фоном. Серая область — это то, что GrabCut посчитал вероятным фоном, а белая область — вероятным передним планом.
Затем эта маска используется для создания второй маски, которая объединяет черную и серую области:
# Show mask
plt.imshow(mask_2, cmap='gray'), plt.axis("off")
plt.show()
Рисунок 17
Затем вторая маска применяется к изображению, так что остается только передний план.
8.11 Обнаружение углов
Проблема
Вы хотите найти углы на изображении.
Решение
Используйте реализацию детектора углов Харриса в OpenCV, cornerHarris:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image as grayscale
image_bgr = cv2.imread("images/plane_256x256.jpg")
image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
image_gray = np.float32(image_gray)
Set corner detector parameters
block_size = 2
aperture = 29
free_parameter = 0.04
Detect corners
detector_responses = cv2.cornerHarris(image_gray,
block_size,
aperture,
free_parameter)
Large corner markers
detector_responses = cv2.dilate(detector_responses, None)
Only keep detector responses greater than threshold, mark as white
threshold = 0.02
image_bgr[detector_responses >
threshold *
detector_responses.max()] = [255,255,255]
Convert to grayscale
image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
Show image
plt.imshow(image_gray, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 18
Обсуждение
Детектор углов Харриса — широко используемый метод для обнаружения пересечения двух ребер. Наш интерес к обнаружению углов мотивирован той же причиной, что и для удаления ребер: углы — это точки высокой информации. Полное объяснение детектора углов Харриса доступно во внешних ресурсах в конце этого рецепта, но упрощенное объяснение заключается в том, что он ищет окна (также называемые neighborhoods или patches), где небольшие перемещения окна (представьте, что вы трясете окно) вызывают большие изменения в содержимом пикселей внутри окна. cornerHarris содержит три важных параметра, которые мы можем использовать для управления обнаруженными ребрами. Во-первых, block_size — это размер окрестности вокруг каждого пикселя, используемого для обнаружения углов. Во-вторых, aperture — это размер ядра Собеля (не беспокойтесь, если вы не знаете, что это такое), и, наконец, есть свободный параметр, где большие значения соответствуют идентификации более мягких углов.
Вывод представляет собой изображение в градациях серого, изображающее потенциальные углы:
# Show potential corners
plt.imshow(detector_responses, cmap='gray'), plt.axis("off")
plt.show()
Рисунок 19
Затем мы применяем пороговую обработку, чтобы оставить только наиболее вероятные углы. Альтернативно, мы можем использовать аналогичный детектор, детектор углов Ши-Томаси, который работает аналогично детектору Харриса (goodFeaturesToTrack), чтобы идентифицировать фиксированное количество сильных углов. goodFeaturesToTrack принимает три основных параметра — количество углов для обнаружения, минимальное качество угла (от 0 до 1) и минимальное евклидово расстояние между углами:
# Load images
image_bgr = cv2.imread('images/plane_256x256.jpg')
image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
Number of corners to detect
corners_to_detect = 10
minimum_quality_score = 0.05
minimum_distance = 25
Detect corners
corners = cv2.goodFeaturesToTrack(image_gray,
corners_to_detect,
minimum_quality_score,
minimum_distance)
corners = np.int16(corners)
Draw white circle at each corner
for corner in corners:
x, y = corner[0]
cv2.circle(image_bgr, (x,y), 10, (255,255,255), -1)
Convert to grayscale
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
Show image
plt.imshow(image_rgb, cmap='gray'), plt.axis("off")
plt.show()
Рисунок 20
См. также
OpenCV’s cornerHarris
OpenCV’s goodFeaturesToTrack
8.13 Создание признаков для машинного обучения
Проблема
Вы хотите преобразовать изображение в наблюдение для машинного обучения.
Решение
Используйте flatten NumPy для преобразования многомерного массива, содержащего данные изображения, в вектор, содержащий значения наблюдения:
# Load image
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image as grayscale
image = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
Resize image to 10 pixels by 10 pixels
image_10x10 = cv2.resize(image, (10, 10))
Convert image data to one-dimensional vector
image_10x10.flatten()array([133, 130, 130, 129, 130, 129, 129, 128, 128, 127, 135, 131, 131,
131, 130, 130, 129, 128, 128, 128, 134, 132, 131, 131, 130, 129,
129, 128, 130, 133, 132, 158, 130, 133, 130, 46, 97, 26, 132,
143, 141, 36, 54, 91, 9, 9, 49, 144, 179, 41, 142, 95,
32, 36, 29, 43, 113, 141, 179, 187, 141, 124, 26, 25, 132,
135, 151, 175, 174, 184, 143, 151, 38, 133, 134, 139, 174, 177,
169, 174, 155, 141, 135, 137, 137, 152, 169, 168, 168, 179, 152,
139, 136, 135, 137, 143, 159, 166, 171, 175], dtype=uint8)Обсуждение
Изображения представлены в виде сетки пикселей. Если изображение в оттенках серого, каждый пиксель представлен одним значением (т.е. интенсивность пикселя: 1, если белый, 0, если черный). Например, представьте, что у нас есть изображение 10 × 10 пикселей:
plt.imshow(image_10x10, cmap="gray"), plt.axis("off")
plt.show()
Рисунок 21
В этом случае размеры данных изображения будут 10 × 10:
image_10x10.shape(10, 10)И если мы сгладим массив, мы получим вектор длиной 100 (10 умножить на 10):
image_10x10.flatten().shape(100,)Это данные признаков для нашего изображения, которые можно объединить с векторами других изображений для создания данных, которые мы будем подавать в наши алгоритмы машинного обучения.
Если изображение цветное, вместо того чтобы каждый пиксель был представлен одним значением, он представлен несколькими значениями (чаще всего тремя), представляющими каналы (красный, зеленый, синий и т. д.), которые смешиваются, образуя конечный цвет этого пикселя. По этой причине, если наше изображение 10 × 10 цветное, у нас будет 300 значений признаков для каждого наблюдения:
# Load image in color
image_color = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_COLOR)
Resize image to 10 pixels by 10 pixels
image_color_10x10 = cv2.resize(image_color, (10, 10))
Convert image data to one-dimensional vector, show dimensions
image_color_10x10.flatten().shape(300,)Одной из основных проблем обработки изображений и компьютерного зрения является то, что поскольку каждая позиция пикселя в наборе изображений является признаком, по мере увеличения изображений количество признаков взрывается:
# Load image in grayscale
image_256x256_gray = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_GRAYSCALE)
Convert image data to one-dimensional vector, show dimensions
image_256x256_gray.flatten().shape(65536,)И количество признаков только увеличивается, когда изображение цветное:
# Load image in color
image_256x256_color = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_COLOR)
Convert image data to one-dimensional vector, show dimensions
image_256x256_color.flatten().shape(196608,)Как показывает вывод, даже небольшое цветное изображение имеет почти 200 000 признаков, что может вызвать проблемы при обучении наших моделей, поскольку количество признаков может значительно превышать количество наблюдений.
Эта проблема мотивирует стратегии уменьшения размерности, обсуждаемые в более поздней главе, которые направлены на уменьшение количества признаков, не теряя при этом чрезмерного количества информации, содержащейся в данных.
8.14 Кодирование сверток как признака
Проблема
Вы хотите использовать свертки в качестве входных данных для вашей модели машинного обучения.
8.15 Кодирование цветовых гистограмм как признаков
Проблема
Вы хотите создать набор признаков, представляющих цвета, появляющиеся на изображении.
Решение
Вычислите гистограммы для каждого цветового канала:
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
Load image
image_bgr = cv2.imread("images/plane_256x256.jpg", cv2.IMREAD_COLOR)
Convert to RGB
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
Create a list for feature values
features = []
Calculate the histogram for each color channel
colors = ("r","g","b")
For each channel: calculate histogram and add to feature value list
for i, channel in enumerate(colors):
histogram = cv2.calcHist([image_rgb], # Image
[i], # Index of channel
None, # No mask
[256], # Histogram size
[0,256]) # Range
features.extend(histogram)
Create a vector for an observation's feature values
observation = np.array(features).flatten()
Show the observation's value for the first five features
observation[0:5]array([ 1008., 217., 184., 165., 116.], dtype=float32)Обсуждение
В цветовой модели RGB каждый цвет представляет собой комбинацию трех цветовых каналов (т.е. красного, зеленого, синего). В свою очередь, каждый канал может принимать одно из 256 значений (представленных целым числом от 0 до 255). Например, самый верхний левый пиксель в нашем изображении имеет следующие значения каналов:
# Show RGB channel values
image_rgb[0,0]array([107, 163, 212], dtype=uint8)Гистограмма — это представление распределения значений в данных. Вот простой пример:
# Import pandas
import pandas as pd
Create some data
data = pd.Series([1, 1, 2, 2, 3, 3, 3, 4, 5])
Show the histogram
data.hist(grid=False)
plt.show()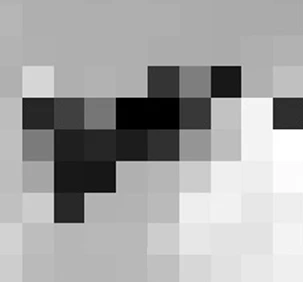
Рисунок 22
В этом примере у нас есть некоторые данные с двумя 1, двумя 2, тремя 3, одной 4 и одной 5. На гистограмме каждый столбец представляет количество раз, когда каждое значение (1, 2 и т.д.) появляется в наших данных.
Мы можем применить ту же технику к каждому из цветовых каналов, но вместо пяти возможных значений у нас есть 256 (диапазон возможных значений для значения канала). Ось X представляет 256 возможных значений каналов, а ось Y представляет количество раз, когда определенное значение канала появляется на всех пикселях изображения:
# Calculate the histogram for each color channel
colors = ("r","g","b")
For each channel: calculate histogram, make plot
for i, channel in enumerate(colors):
histogram = cv2.calcHist([image_rgb], # Image
[i], # Index of channel
None, # No mask
[256], # Histogram size
[0,256]) # Range
plt.plot(histogram, color = channel)
plt.xlim([0,256])
Show plot
plt.show()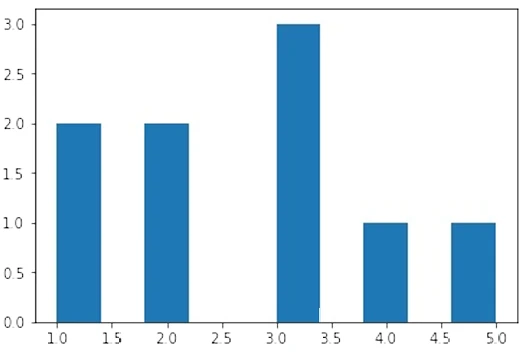
Рисунок 23
Как видно на гистограмме, очень мало пикселей содержат значения синего канала между 0 и ~180, в то время как многие пиксели содержат значения синего канала между ~190 и ~210. Это распределение значений каналов показано для всех трех каналов. Гистограмма, однако, не просто визуализация; это 256 признаков для каждого цветового канала, что в сумме составляет 768 признаков, представляющих распределение цветов на изображении.
См. также
Histogram
pandas Histogram documentation
OpenCV Histogram tutorial
8.16 Использование предварительно обученных встраиваний как признака
Проблема
Вы хотите загрузить предварительно обученные встраивания из существующей модели в Pytorch и использовать их в качестве входных данных для своих собственных моделей.
Решение
Используйте torchvision.models, чтобы выбрать модель, а затем получить из нее встраивание для данного изображения:
import cv2
import json
import numpy as np
import torch
from torchvision import transforms
from torchvision.models import resnet18
import urllib.request
Get imagenet classes
with urllib.request.urlopen("https://raw.githubusercontent.com/raghakot/keras-vis/master/resources/imagenet_class_index.json") as url:
imagenet_class_index = json.load(url)
Instantiate pretrained model
model = resnet18(pretrained=True)
Load image
image_bgr = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
Convert to pytorch data type
convert_tensor = transforms.ToTensor()
pytorch_image = convert_tensor(np.array(image_rgb))
Set model to evaluation mode
model.eval()
Infer the embedding with the no_grad option
with torch.no_grad():
embedding = model(pytorch_image.unsqueeze(0))
print(embedding.shape)torch.Size([1, 1000])Обсуждение
В области машинного обучения перенос обучения (transfer learning) часто определяется как использование информации, полученной при решении одной задачи, в качестве входных данных для другой задачи. Вместо того чтобы начинать с «0», мы можем использовать представления, уже изученные на больших предварительно обученных моделях изображений (таких как Resnet), чтобы получить «начальный толчок» для наших собственных моделей машинного обучения. Более интуитивно, мы можем понять, как мы могли бы использовать веса модели, обученной распознавать кошек, в качестве хорошего «старта» для модели, которую мы хотим обучить распознавать собак. Разделяя информацию из одной модели в другую, мы можем использовать информацию, полученную из других наборов данных и архитектур моделей, без необходимости обучения модели с нуля.
Полное применение переноса обучения в компьютерном зрении выходит за рамки этой книги, однако существует множество различных способов извлечения представлений изображений на основе встраиваний вне Pytorch. В TensorFlow, другой распространенной библиотеке для глубокого обучения, мы можем использовать tensorflow_hub.
import cv2
import tensorflow as tf
import tensorflow_hub as hub
Load image
image_bgr = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
Convert to tensorflow data type
tf_image = tf.image.convert_image_dtype([image_rgb], tf.float32)
Create the model and get embeddings using the inception V1 model
embedding_model = hub.KerasLayer("https://tfhub.dev/google/imagenet/inception_v1/feature_vector/5")
embeddings = embedding_model(tf_image)
Print the shape of the embedding
print(embeddings.shape)(1, 1024)См. также
Transfer learning with Pytorch
Tensorflow Hub
8.17 Обнаружение объектов с помощью OpenCV
Проблема
Вы хотите обнаружить объекты на изображениях с помощью предварительно обученных каскадных классификаторов в OpenCV.
Решение
Скачайте и запустите один из каскадных классификаторов Хаара OpenCV. В данном случае мы используем предварительно обученную модель детекции лиц, чтобы обнаружить и нарисовать прямоугольник вокруг лица на изображении:
# Import libraries
import cv2
from matplotlib import pyplot as plt
first run : mkdir models && cd models
`wget
https://raw.githubusercontent.com/opencv/opencv/4.x/data/haarcascades/haarcascade_frontalface_default.xml`
face_cascade = cv2.CascadeClassifier()
face_cascade.load(cv2.samples.findFile("models/haarcascade_frontalface_default.xml"))
Load image
image_bgr = cv2.imread("images/kyle_pic.jpg", cv2.IMREAD_COLOR)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
Detect faces and draw a rectangle
faces = face_cascade.detectMultiScale(image_rgb)
for (x,y,w,h) in faces:
cv2.rectangle(image_rgb, (x, y),
(x + h, y + w),
(0, 255, 0), 5)
Show the image
plt.subplot(1, 1, 1)
plt.imshow(image_rgb)
plt.show()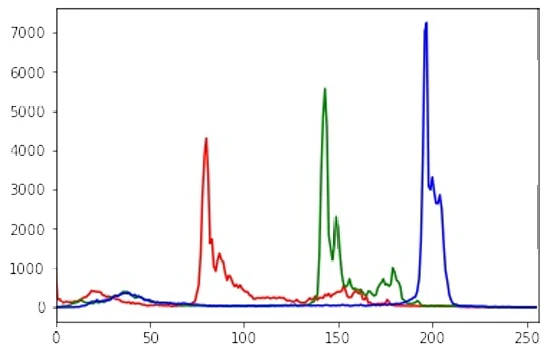
Рисунок 24
Обсуждение
Каскадные классификаторы Хаара — это модели машинного обучения, используемые для изучения набора признаков изображения (в частности, признаков Хаара), которые могут быть использованы для обнаружения объектов на изображениях. Сами признаки представляют собой простые прямоугольные признаки, которые определяются путем вычисления разницы сумм в прямоугольных областях. Впоследствии применяется алгоритм градиентного бустинга для изучения наиболее важных признаков и, наконец, создания относительно сильной модели с использованием каскадных классификаторов.
Хотя детали этого процесса выходят за рамки этой книги, стоит отметить, что эти предварительно обученные модели могут быть легко загружены из таких мест, как OpenCV Github, в виде XML-файлов и применены к изображениям без самостоятельного обучения модели. Это полезно в случаях, когда вы хотите добавить простые бинарные признаки изображения, такие как наличие лица (или любого другого объекта) в ваши данные.
См. также
OpenCV cascade classifier tutorial
8.18 Классификация изображений с помощью Pytorch
Проблема
Вы хотите классифицировать изображения с помощью предварительно обученных моделей глубокого обучения в Pytorch.
Решение
Используйте torchvision.models, чтобы выбрать предварительно обученную модель классификации изображений и подать изображение через нее.
import cv2
import json
import numpy as np
import torch
from torchvision import transforms
from torchvision.models import resnet18
import urllib.request
Get imagenet classes
with urllib.request.urlopen("https://raw.githubusercontent.com/raghakot/keras-vis/master/resources/imagenet_class_index.json") as url:
imagenet_class_index = json.load(url)
Instantiate pretrained model
model = resnet18(pretrained=True)
Load image
image_bgr = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
Convert to pytorch data type
convert_tensor = transforms.ToTensor()
pytorch_image = convert_tensor(np.array(image_rgb))
Set model to evaluation mode
model.eval()
Infer the embedding with the no_grad option
with torch.no_grad():
embedding = model(pytorch_image.unsqueeze(0))
print(embedding.shape)torch.Size([1, 1000])Обсуждение
Многие предварительно обученные модели глубокого обучения для классификации изображений легко доступны как через Pytorch, так и через TensorFlow. В приведенном выше примере мы использовали ResNet18, архитектуру глубокой нейронной сети, состоящую из 18 слоев. Более глубокие модели ResNet, такие как ResNet101 и ResNet152, также доступны в Pytorch - и помимо этого существует множество других моделей изображений на выбор. Модели, обученные на наборе данных ImageNet, способны выводить предсказанные вероятности для всех классов, определенных в переменной imagenet_class_index выше, которую мы скачиваем с Github.
Подобно примеру распознавания лиц в OpenCV, мы можем использовать предсказанные классы изображений в качестве последующих признаков для будущих моделей машинного обучения или удобных тегов метаданных, которые добавляют больше информации к нашим изображениям.
См. также
Pytorch models and pretrained weights
Другие статьи по этой теме:
- Маленькая книга о глубоком обучении
- 100 Страниц о машинном обучении
- Математика для нейронного обучения